") 為什么使用ROC曲線?
為什么使用ROC曲線?
1.ROC曲線
ROC曲線全稱為受試者工作特征曲線(Receiver Operating Characteristic)。提到ROC曲線就要先說明一下兩個(gè)概念:FPR(偽正類率),TPR(真正類率),它們都是分類任務(wù)的評(píng)測(cè)指標(biāo)。
1.1 TPR 、FPR
對(duì)于一個(gè)二分類任務(wù)(假定為1表示正類, 0表示負(fù)類),對(duì)于一個(gè)樣本,分類的結(jié)果總共有四種:
類別實(shí)際為1,被預(yù)測(cè)為0,F(xiàn)N(False Negative)
類別實(shí)際為1,被預(yù)測(cè)為1,TP(True Positive)
類別實(shí)際為0,被預(yù)測(cè)為1,F(xiàn)P(False Positive)
類別實(shí)際為0,被預(yù)測(cè)為0,TN(True Negative)
FPR(False Positive Rate)= FP /(FP + TN),即負(fù)類數(shù)據(jù)被預(yù)測(cè)為正類的比例;
TPR(True Positive Rate)= TP /(TP + FN),即正類數(shù)據(jù)被預(yù)測(cè)為正類的比例。
1.2 ROC曲線
那什么是ROC曲線呢?我們看一下ROC曲線的圖示:
對(duì)于樣本數(shù)據(jù),我們使用分類器對(duì)其進(jìn)行分類,分類器會(huì)給出每個(gè)數(shù)據(jù)為正例的概率。我們可以針對(duì)此來設(shè)定一個(gè)閾值,當(dāng)某個(gè)樣本被預(yù)測(cè)為正例的概率大于這個(gè)閾值時(shí),認(rèn)為該樣本為正例,小于則為負(fù)例。
通過計(jì)算我們就可以得到一個(gè)(TPR , FPR)對(duì),即圖像上的一個(gè)點(diǎn)。通過不斷調(diào)整這個(gè)閾值,就得到若干個(gè)點(diǎn),從而畫出一條曲線。
可以看出,當(dāng)這個(gè)閾值越大時(shí),會(huì)有越多的樣本被預(yù)測(cè)為負(fù)例,而這些樣本中其實(shí)也有正例的存在。這樣一來,TPR下降(正例數(shù)據(jù)被預(yù)測(cè)為負(fù)例了),F(xiàn)PR下降(負(fù)類數(shù)據(jù)更不會(huì)被預(yù)測(cè)為正例,但是影響要比TPR小,所以斜率呈上升趨勢(shì))。
當(dāng)閾值越小時(shí),越多的樣本被預(yù)測(cè)為正例,而這些樣本中可能包含是正例,卻被預(yù)測(cè)為負(fù)例的樣本以及是負(fù)例卻被預(yù)測(cè)為正例的樣本,這樣一來TPR上升(更多的正例樣本被預(yù)測(cè)為正例),F(xiàn)PR上升(更多的負(fù)例樣本預(yù)測(cè)為正例,影響更大,所以斜率呈下降趨勢(shì))。
1.3 閾值調(diào)整
那么該如何調(diào)整這個(gè)閾值呢?一般來說,分類器會(huì)對(duì)一批數(shù)據(jù)的每個(gè)樣本給出一個(gè)是正例的概率,如下圖示,共20個(gè)樣本,class為實(shí)際標(biāo)簽,score為分類器判斷樣本為正例的概率:
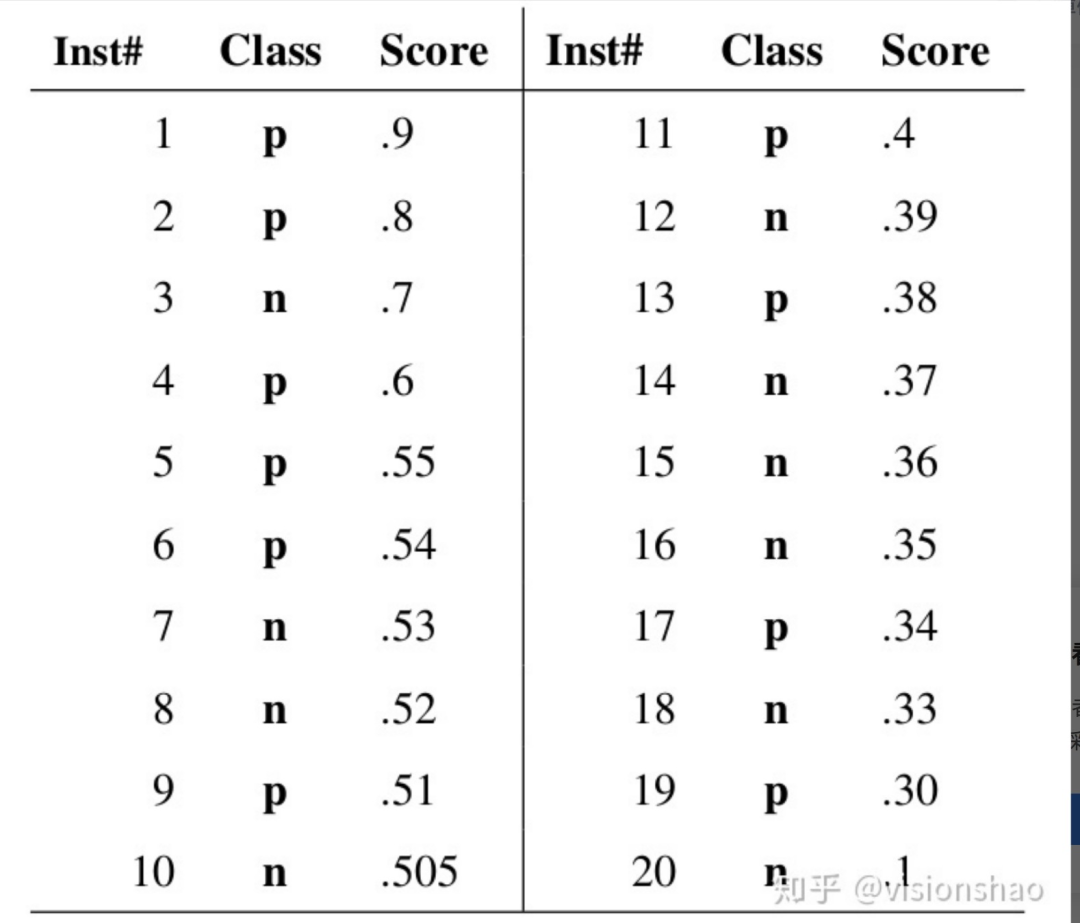
對(duì)給出的分?jǐn)?shù)進(jìn)行排序,然后依次使用score作為閾值,這樣就得到了20組(FPR, TPR),做出ROC曲線如下:
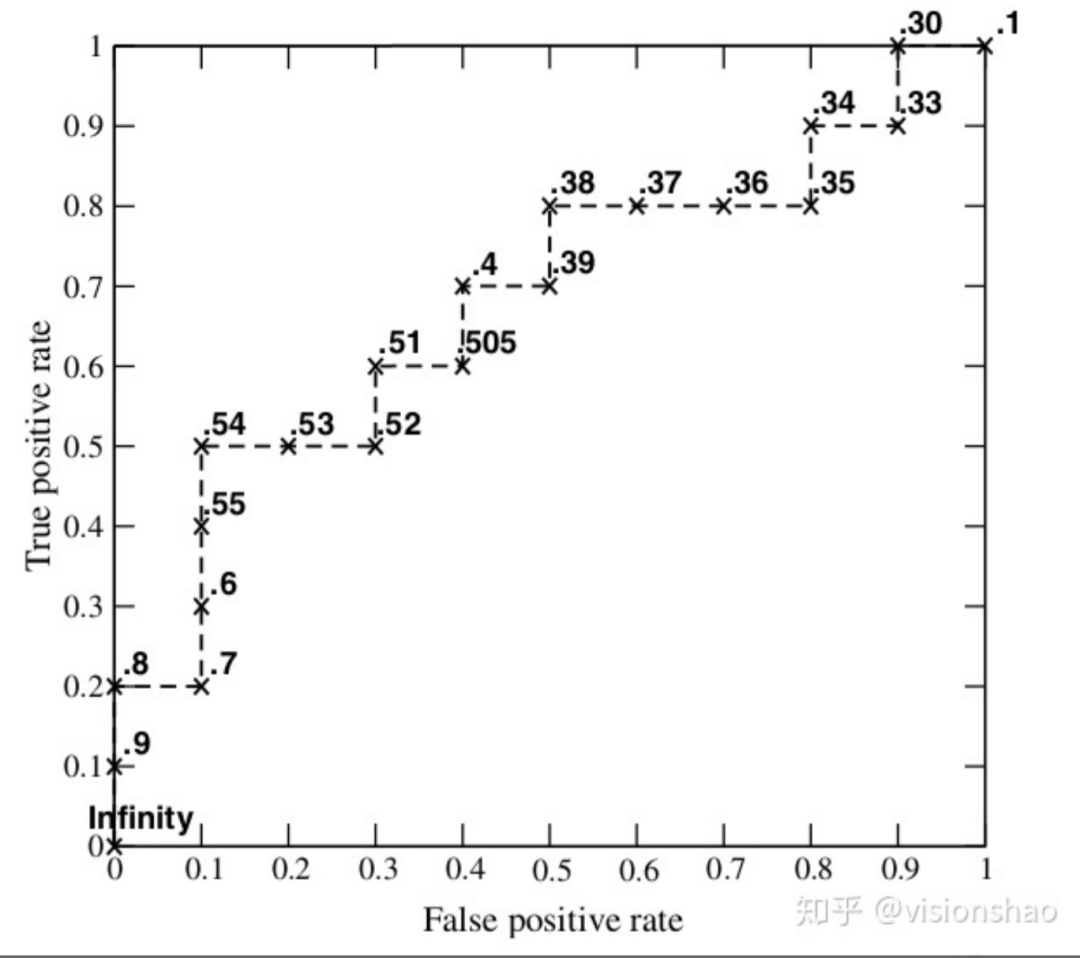
當(dāng)閾值為1時(shí)就可以到達(dá)ROC曲線上(0, 0)點(diǎn),當(dāng)閾值為0時(shí)就可以到達(dá)ROC曲線上(1, 1) 點(diǎn)。當(dāng)然也不一定就必須使用概率值,也可以使用未經(jīng)過softmax(或其他類似處理)的結(jié)果,使用方法相同,畢竟我們只需要一個(gè)次序。
2.AUC
說完ROC,再來說一下AUC。AUC被定義為ROC曲線下的面積(Area Under Curve),顯然這個(gè)面積小于1。又因?yàn)镽OC曲線一般都處于y=x這條直線的上方,所以AUC一般在0.5到1之間。
2.1 AUC優(yōu)點(diǎn)與含義
使用AUC值作為評(píng)價(jià)標(biāo)準(zhǔn)是因?yàn)楹芏鄷r(shí)候ROC曲線并不能清晰的說明哪個(gè)分類器的效果更好,而作為一個(gè)數(shù)值,對(duì)應(yīng)AUC更大的分類器效果更好。
AUC的含義為,當(dāng)隨機(jī)挑選一個(gè)正樣本和一個(gè)負(fù)樣本,根據(jù)當(dāng)前的分類器計(jì)算得到的score將這個(gè)正樣本排在負(fù)樣本前面的概率。
2.2AUC與分類器優(yōu)劣
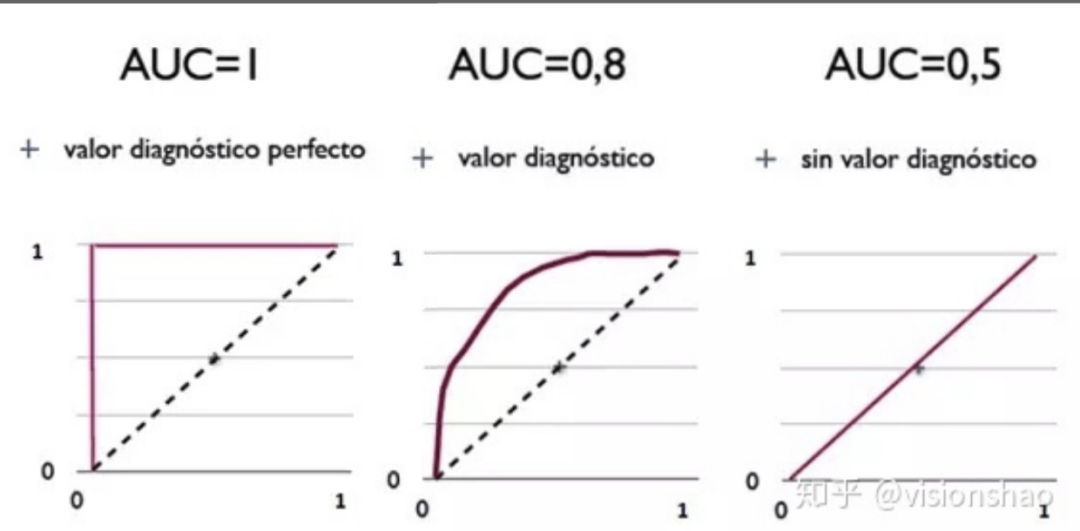
從AUC判斷分類器(預(yù)測(cè)模型)優(yōu)劣的標(biāo)準(zhǔn):
AUC = 1,是完美分類器,采用這個(gè)預(yù)測(cè)模型時(shí),存在至少一個(gè)閾值能得出完美預(yù)測(cè)。絕大多數(shù)預(yù)測(cè)的場(chǎng)合,不存在完美分類器。
0.5 < AUC < 1,優(yōu)于隨機(jī)猜測(cè)。這個(gè)分類器(模型)妥善設(shè)定閾值的話,能有預(yù)測(cè)價(jià)值。
AUC = 0.5,跟隨機(jī)猜測(cè)一樣(例:丟銅板),模型沒有預(yù)測(cè)價(jià)值。
AUC < 0.5,比隨機(jī)猜測(cè)還差;但只要總是反預(yù)測(cè)而行,就優(yōu)于隨機(jī)猜測(cè)。
3. 為什么使用ROC曲線?
既然已經(jīng)這么多評(píng)價(jià)標(biāo)準(zhǔn),為什么還要使用ROC和AUC呢?因?yàn)镽OC曲線有個(gè)很好的特性:當(dāng)測(cè)試集中的正負(fù)樣本的分布變化的時(shí)候,ROC曲線能夠保持不變。
在實(shí)際的數(shù)據(jù)集中經(jīng)常會(huì)出現(xiàn)類不平衡(class imbalance)現(xiàn)象,即負(fù)樣本比正樣本多很多(或者相反),而且測(cè)試數(shù)據(jù)中的正負(fù)樣本的分布也可能隨著時(shí)間變化。
下圖中,(a)和(c)為ROC曲線,(b)和(d)為Precision-Recal[1]曲線。(a)和(b)展示的是分類其在原始測(cè)試集(正負(fù)樣本分布平衡)的結(jié)果,(c)和(d)是將測(cè)試集中負(fù)樣本的數(shù)量增加到原來的10倍后,分類器的結(jié)果。
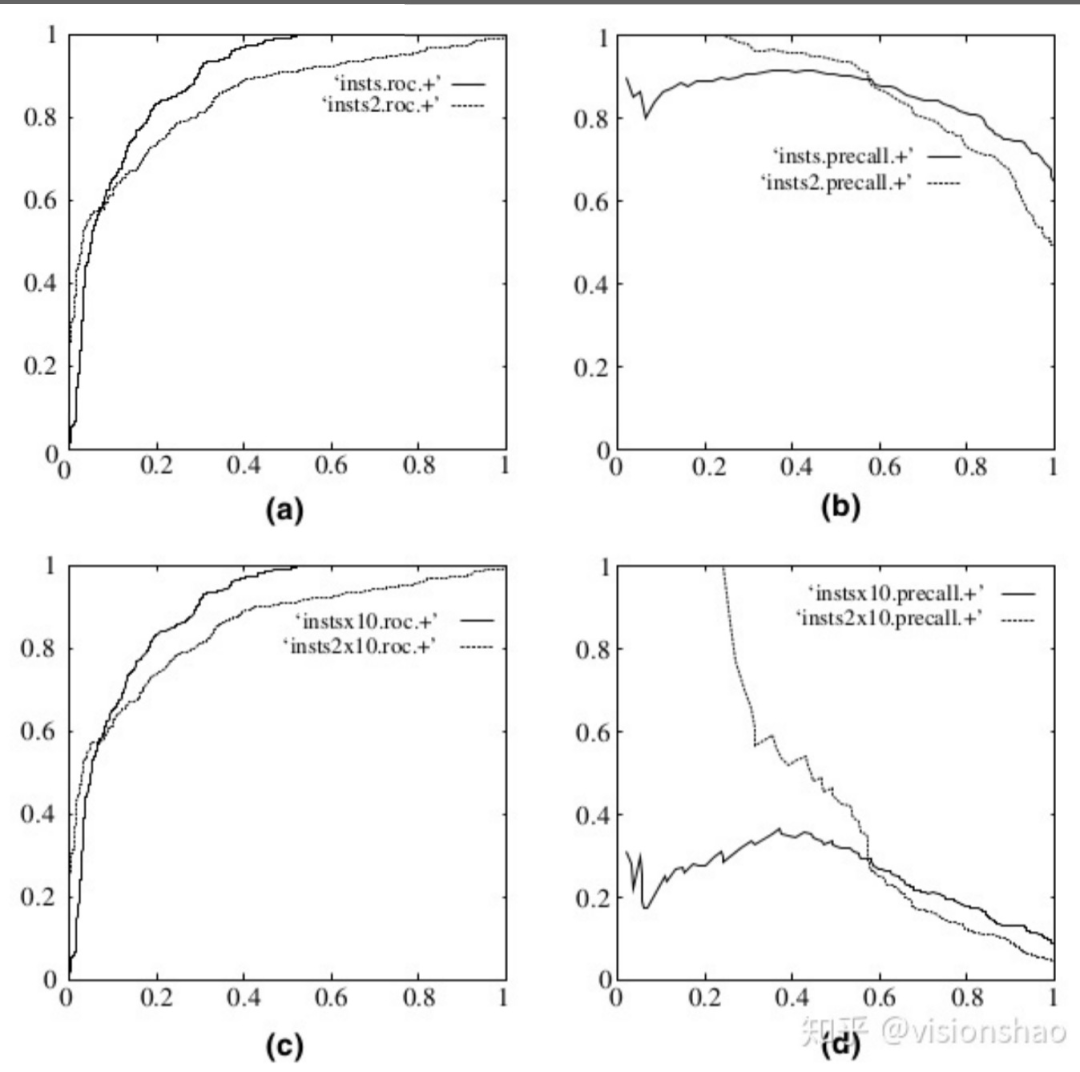
可以明顯的看出,ROC曲線基本保持原貌,而Precision-Recall曲線則變化較大。
審核編輯 :李倩
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7067瀏覽量
89107 -
曲線
+關(guān)注
關(guān)注
1文章
82瀏覽量
20864
原文標(biāo)題:3. 為什么使用ROC曲線?
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
伏安特性曲線
參考曲線狀態(tài)評(píng)估指南

繼電器的機(jī)械特性曲線說明什么?它有何作用?
在設(shè)計(jì)中使用MOSFET安全工作區(qū)曲線

在設(shè)計(jì)中使用MOSFET瞬態(tài)熱阻抗曲線
變壓器的外特性曲線是怎樣的?
直流伺服電動(dòng)機(jī)的機(jī)械特性曲線是什么
二極管的輸出特性曲線分析
雷達(dá)檢測(cè)概率曲線的影響因素
【smt工藝】無(wú)鉛錫膏爐溫曲線怎樣設(shè)定?

如何理解ABB低壓斷路器的保護(hù)曲線
示波器探頭的降額曲線指標(biāo)對(duì)測(cè)量結(jié)果有什么影響?
為什么電壓探頭會(huì)有降額曲線指標(biāo),它的意義是什么呢?
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無(wú)線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 社區(qū)
- 小組
- 論壇
- 問答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論