") 分庫分表的15道經(jīng)典面試題
分庫分表的15道經(jīng)典面試題
我們?nèi)ッ嬖嚨臅r(shí)候,幾乎都會被問到分庫分表。
在這里整理了分庫分表的15道經(jīng)典面試題,大家看完肯定會有幫助的。
1. 我們?yōu)槭裁葱枰謳旆直?/span>
在分庫分表之前,就需要考慮為什么需要拆分。我們做一件事,肯定是有充分理由的。所以得想好分庫分表的理由是什么。我們現(xiàn)在就從兩個(gè)維度去思考它,為什么要分庫?為什么要分表?
1.1 為什么要分庫
如果業(yè)務(wù)量劇增,數(shù)據(jù)庫可能會出現(xiàn)性能瓶頸,這時(shí)候我們就需要考慮拆分?jǐn)?shù)據(jù)庫。從這兩方面來看:
- 磁盤存儲
業(yè)務(wù)量劇增,MySQL單機(jī)磁盤容量會撐爆,拆成多個(gè)數(shù)據(jù)庫,磁盤使用率大大降低。
- 并發(fā)連接支撐
我們知道數(shù)據(jù)庫連接數(shù)是有限的。在高并發(fā)的場景下,大量請求訪問數(shù)據(jù)庫,MySQL單機(jī)是扛不住的!高并發(fā)場景下,會出現(xiàn)too many connections報(bào)錯(cuò)。
當(dāng)前非常火的微服務(wù)架構(gòu)出現(xiàn),就是為了應(yīng)對高并發(fā)。它把訂單、用戶、商品等不同模塊,拆分成多個(gè)應(yīng)用,并且把單個(gè)數(shù)據(jù)庫也拆分成多個(gè)不同功能模塊的數(shù)據(jù)庫(訂單庫、用戶庫、商品庫),以分擔(dān)讀寫壓力。
1.2 為什么要分表
假如你的單表數(shù)據(jù)量非常大,存儲和查詢的性能就會遇到瓶頸了,如果你做了很多優(yōu)化之后還是無法提升效率的時(shí)候,就需要考慮做分表了。一般千萬級別數(shù)據(jù)量,就需要分表。
這是因?yàn)榧词?code style="font-size:14px;padding:2px 4px;margin-right:2px;margin-left:2px;background-color:rgba(27,31,35,.05);font-family:'Operator Mono', Consolas, Monaco, Menlo, monospace;color:rgb(100,149,237);">SQL命中了索引,如果表的數(shù)據(jù)量超過一千萬的話,查詢也是會明顯變慢的。這是因?yàn)樗饕话闶?code style="font-size:14px;padding:2px 4px;margin-right:2px;margin-left:2px;background-color:rgba(27,31,35,.05);font-family:'Operator Mono', Consolas, Monaco, Menlo, monospace;color:rgb(100,149,237);">B+樹結(jié)構(gòu),數(shù)據(jù)千萬級別的話,B+樹的高度會增高,查詢就變慢啦。MySQL的B+樹的高度怎么計(jì)算的呢?跟大家復(fù)習(xí)一下:
InnoDB存儲引擎最小儲存單元是頁,一頁大小就是16k。B+樹葉子存的是數(shù)據(jù),內(nèi)部節(jié)點(diǎn)存的是鍵值+指針。索引組織表通過非葉子節(jié)點(diǎn)的二分查找法以及指針確定數(shù)據(jù)在哪個(gè)頁中,進(jìn)而再去數(shù)據(jù)頁中找到需要的數(shù)據(jù),B+樹結(jié)構(gòu)圖如下:
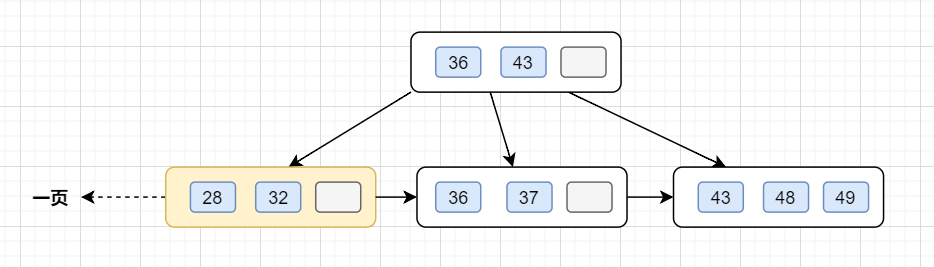
假設(shè)B+樹的高度為2的話,即有一個(gè)根結(jié)點(diǎn)和若干個(gè)葉子結(jié)點(diǎn)。這棵B+樹的存放總記錄數(shù)為=根結(jié)點(diǎn)指針數(shù)*單個(gè)葉子節(jié)點(diǎn)記錄行數(shù)。
如果一行記錄的數(shù)據(jù)大小為1k,那么單個(gè)葉子節(jié)點(diǎn)可以存的記錄數(shù) =16k/1k =16. 非葉子節(jié)點(diǎn)內(nèi)存放多少指針呢?我們假設(shè)主鍵ID為bigint類型,長度為8字節(jié)(面試官問你int類型,一個(gè)int就是32位,4字節(jié)),而指針大小在InnoDB源碼中設(shè)置為6字節(jié),所以就是 8+6=14 字節(jié),16k/14B =16*1024B/14B = 1170
因此,一棵高度為2的B+樹,能存放1170 * 16=18720條這樣的數(shù)據(jù)記錄。同理一棵高度為3的B+樹,能存放1170 *1170 *16 =21902400,大概可以存放兩千萬左右的記錄。B+樹高度一般為1-3層,如果B+到了4層,查詢的時(shí)候會多查磁盤的次數(shù),SQL就會變慢。
因此單表數(shù)據(jù)量太大,SQL查詢會變慢,所以就需要考慮分表啦。
2. 什么時(shí)候考慮分庫分表?
對于MySQL,InnoDB存儲引擎的話,單表最多可以存儲10億級數(shù)據(jù)。但是的話,如果真的存儲這么多,性能就會非常差。一般數(shù)據(jù)量千萬級別,B+樹索引高度就會到3層以上了,查詢的時(shí)候會多查磁盤的次數(shù),SQL就會變慢。
阿里巴巴的《Java開發(fā)手冊》提出:
單表行數(shù)超過
500萬行或者單表容量超過2GB,才推薦進(jìn)行分庫分表。
那我們是不是等到數(shù)據(jù)量到達(dá)五百萬,才開始分庫分表呢?
不是這樣的,我們應(yīng)該提前規(guī)劃分庫分表,如果估算
3年后,你的表都不會到達(dá)這個(gè)五百萬,則不需要分庫分表。
MySQL服務(wù)器如果配置更好,是不是可以超過這個(gè)500萬這個(gè)量級,才考慮分庫分表?
雖然配置更好,可能數(shù)據(jù)量大之后,性能還是不錯(cuò),但是如果持續(xù)發(fā)展的話,還是要考慮分庫分表
一般什么類型業(yè)務(wù)表需要才分庫分表?
通用是一些流水表、用戶表等才考慮分庫分表,如果是一些配置類的表,則完全不用考慮,因?yàn)椴惶赡艿竭_(dá)這個(gè)量級。
3. 如何選擇分表鍵
分表鍵,即用來分庫/分表的字段,換種說法就是,你以哪個(gè)維度來分庫分表的。比如你按用戶ID分表、按時(shí)間分表、按地區(qū)分表,這些用戶ID、時(shí)間、地區(qū)就是分表鍵。
一般數(shù)據(jù)庫表拆分的原則,需要先找到業(yè)務(wù)的主題。比如你的數(shù)據(jù)庫表是一張企業(yè)客戶信息表,就可以考慮用了客戶號做為分表鍵。
為什么考慮用客戶號做分表鍵呢?
這是因?yàn)楸硎腔诳蛻粜畔⒌模裕枰獙⑼粋€(gè)客戶信息的數(shù)據(jù),落到一個(gè)表中,避免觸發(fā)全表路由。
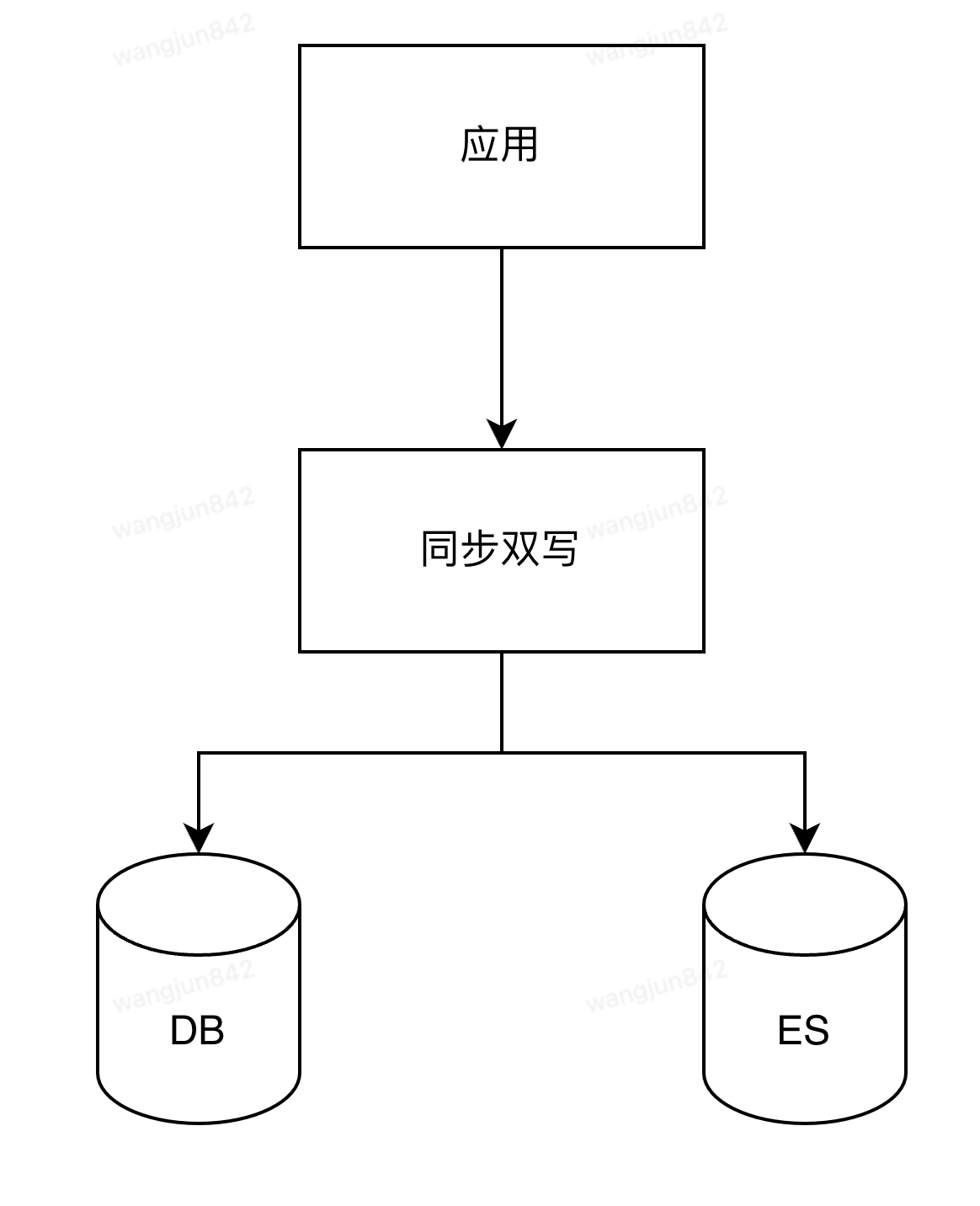
4.非分表鍵如何查詢
分庫分表后,有時(shí)候無法避免一些業(yè)務(wù)場景,需要通過非分表鍵來查詢。
假設(shè)一張用戶表,根據(jù)userId做分表鍵,來分庫分表。但是用戶登錄時(shí),需要根據(jù)用戶手機(jī)號來登陸。這時(shí)候,就需要通過手機(jī)號查詢用戶信息。而手機(jī)號是非分表鍵。
非分表鍵查詢,一般有這幾種方案:
- 遍歷:最粗暴的方法,就是遍歷所有的表,找出符合條件的手機(jī)號記錄(不建議)
- 將用戶信息冗余同步到ES,同步發(fā)送到ES,然后通過ES來查詢(推薦)
其實(shí)還有基因法:比如非分表鍵可以解析出分表鍵出來,比如常見的,訂單號生成時(shí),可以包含客戶號進(jìn)去,通過訂單號查詢,就可以解析出客戶號。但是這個(gè)場景除外,手機(jī)號似乎不適合冗余userId。
5. 分表策略如何選擇
5.1 range范圍
range,即范圍策略劃分表。比如我們可以將表的主鍵order_id,按照從0~300萬的劃分為一個(gè)表,300萬~600萬劃分到另外一個(gè)表。如下圖:
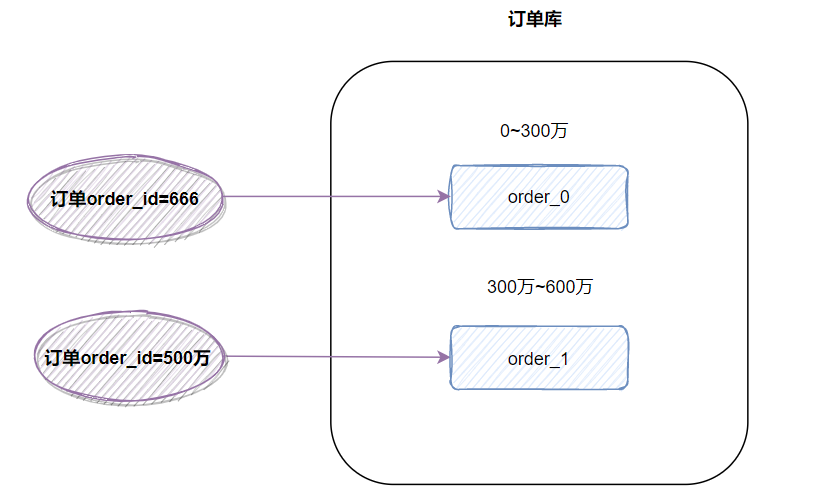
有時(shí)候我們也可以按時(shí)間范圍來劃分,如不同年月的訂單放到不同的表,它也是一種range的劃分策略。
-
優(yōu)點(diǎn):
range范圍分表,有利于擴(kuò)容。 -
缺點(diǎn):可能會有熱點(diǎn)問題。因?yàn)?code style="font-size:14px;padding:2px 4px;margin-right:2px;margin-left:2px;background-color:rgba(27,31,35,.05);font-family:'Operator Mono', Consolas, Monaco, Menlo, monospace;color:rgb(100,149,237);">訂單id是一直在增大的,也就是說最近一段時(shí)間都是匯聚在一張表里面的。比如最近一個(gè)月的訂單都在
300萬~600萬之間,平時(shí)用戶一般都查最近一個(gè)月的訂單比較多,請求都打到order_1表啦。
5.2 hash取模
hash取模策略:
指定的路由key(一般是
user_id、order_id、customer_no作為key)對分表總數(shù)進(jìn)行取模,把數(shù)據(jù)分散到各個(gè)表中。
比如原始訂單表信息,我們把它分成4張分表:
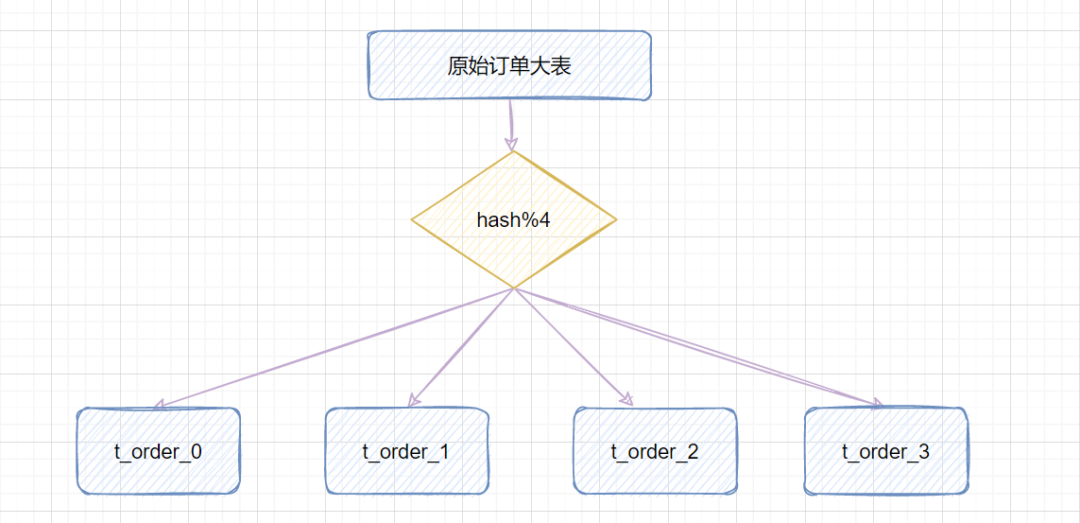
-
比如id=1,對4取模,就會得到1,就把它放到
t_order_1; -
id=3,對4取模,就會得到3,就把它放到
t_order_3;
一般,我們會取哈希值,再做取余:
Math.abs(orderId.hashCode())%table_number
- 優(yōu)點(diǎn):hash取模的方式,不會存在明顯的熱點(diǎn)問題。
- 缺點(diǎn):如果未來某個(gè)時(shí)候,表數(shù)據(jù)量又到瓶頸了,需要擴(kuò)容,就比較麻煩。所以一般建議提前規(guī)劃好,一次性分夠。(可以考慮一致性哈希)
5.3 一致性Hash
如果用hash方式分表,前期規(guī)劃不好,需要擴(kuò)容二次分表,表的數(shù)量需要增加,所以hash值需要重新計(jì)算,這時(shí)候需要遷移數(shù)據(jù)了。
比如我們開始分了
10張表,之后業(yè)務(wù)擴(kuò)展需要,增加到20張表。那問題就來了,之前根據(jù)orderId取模10后的數(shù)據(jù)分散在了各個(gè)表中,現(xiàn)在需要重新對所有數(shù)據(jù)重新取模20來分配數(shù)據(jù)
為了解決這個(gè)擴(kuò)容遷移問題,可以使用一致性hash思想來解決。
一致性哈希:在移除或者添加一個(gè)服務(wù)器時(shí),能夠盡可能小地改變已存在的服務(wù)請求與處理請求服務(wù)器之間的映射關(guān)系。一致性哈希解決了簡單哈希算法在分布式哈希表存在的動(dòng)態(tài)伸縮等問題
6. 如何避免熱點(diǎn)問題數(shù)據(jù)傾斜(熱點(diǎn)數(shù)據(jù))
如果我們根據(jù)時(shí)間范圍分片,某電商公司11月搞營銷活動(dòng),那么大部分的數(shù)據(jù)都落在11月份的表里面了,其他分片表可能很少被查詢,即數(shù)據(jù)傾斜了,有熱點(diǎn)數(shù)據(jù)問題了。
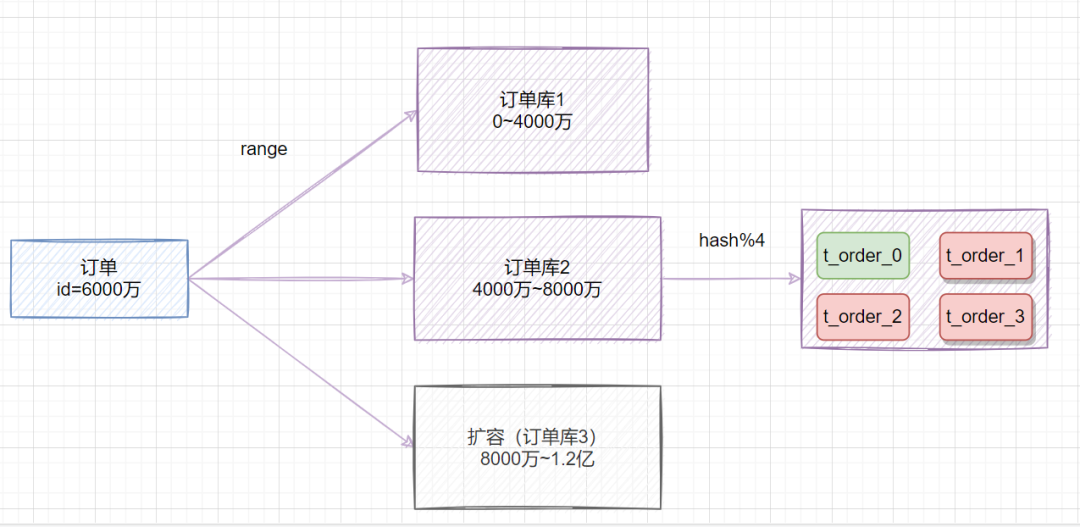
我們可以使用range范圍+ hash哈希取模結(jié)合的分表策略,簡單的做法就是:
在拆分庫的時(shí)候,我們可以先用range范圍方案,比如訂單id在
0~4000萬的區(qū)間,劃分為訂單庫1;id在4000萬~8000萬的數(shù)據(jù),劃分到訂單庫2,將來要擴(kuò)容時(shí),id在8000萬~1.2億的數(shù)據(jù),劃分到訂單庫3。然后訂單庫內(nèi),再用hash取模的策略,把不同訂單劃分到不同的表。
7.分庫后,事務(wù)問題如何解決
分庫分表后,假設(shè)兩個(gè)表在不同的數(shù)據(jù)庫,那么本地事務(wù)已經(jīng)無效啦,需要使用分布式事務(wù)了。
常用的分布式事務(wù)解決方案有:
- 兩階段提交
- 三階段提交
- TCC
- 本地消息表
- 最大努力通知
- saga
8. 跨節(jié)點(diǎn)Join關(guān)聯(lián)問題
在單庫未拆分表之前,我們?nèi)绻褂?code style="font-size:14px;padding:2px 4px;margin-right:2px;margin-left:2px;background-color:rgba(27,31,35,.05);font-family:'Operator Mono', Consolas, Monaco, Menlo, monospace;color:rgb(100,149,237);">join關(guān)聯(lián)多張表操作的話,簡直so easy啦。但是分庫分表之后,兩張表可能都不在同一個(gè)數(shù)據(jù)庫中了,那么如何跨庫join操作呢?
跨庫Join的幾種解決思路:
-
字段冗余:把需要關(guān)聯(lián)的字段放入主表中,避免關(guān)聯(lián)操作;比如訂單表保存了賣家ID(
sellerId),你把賣家名字sellerName也保存到訂單表,這就不用去關(guān)聯(lián)賣家表了。這是一種空間換時(shí)間的思想。 - 全局表:比如系統(tǒng)中所有模塊都可能會依賴到的一些基礎(chǔ)表(即全局表),在每個(gè)數(shù)據(jù)庫中均保存一份。
-
數(shù)據(jù)抽象同步:比如A庫中的a表和B庫中的b表有關(guān)聯(lián),可以定時(shí)將指定的表做同步,將數(shù)據(jù)匯合聚集,生成新的表。一般可以借助
ETL工具。 - 應(yīng)用層代碼組裝:分開多次查詢,調(diào)用不同模塊服務(wù),獲取到數(shù)據(jù)后,代碼層進(jìn)行字段計(jì)算拼裝。
9. order by,group by等聚合函數(shù)問題
跨節(jié)點(diǎn)的count,order by,group by以及聚合函數(shù)等問題,都是一類的問題,它們一般都需要基于全部數(shù)據(jù)集合進(jìn)行計(jì)算。可以分別在各個(gè)節(jié)點(diǎn)上得到結(jié)果后,再在應(yīng)用程序端進(jìn)行合并。
10. 分庫分表后的分頁問題
- 方案1(全局視野法):在各個(gè)數(shù)據(jù)庫節(jié)點(diǎn)查到對應(yīng)結(jié)果后,在代碼端匯聚再分頁。這樣優(yōu)點(diǎn)是業(yè)務(wù)無損,精準(zhǔn)返回所需數(shù)據(jù);缺點(diǎn)則是會返回過多數(shù)據(jù),增大網(wǎng)絡(luò)傳輸
比如分庫分表前,你是根據(jù)創(chuàng)建時(shí)間排序,然后獲取第2頁數(shù)據(jù)。如果你是分了兩個(gè)庫,那你就可以每個(gè)庫都根據(jù)時(shí)間排序,然后都返回2頁數(shù)據(jù),然后把兩個(gè)數(shù)據(jù)庫查詢回來的數(shù)據(jù)匯總,再根據(jù)創(chuàng)建時(shí)間進(jìn)行內(nèi)存排序,最后再取第2頁的數(shù)據(jù)。
- 方案2(業(yè)務(wù)折衷法-禁止跳頁查詢):這種方案需要業(yè)務(wù)妥協(xié)一下,只有上一頁和下一頁,不允許跳頁查詢了。
這種方案,查詢第一頁時(shí),是跟全局視野法一樣的。但是下一頁時(shí),需要把當(dāng)前最大的創(chuàng)建時(shí)間傳過來,然后每個(gè)節(jié)點(diǎn),都查詢大于創(chuàng)建時(shí)間的一頁數(shù)據(jù),接著匯總,內(nèi)存排序返回。
11. 分布式ID
數(shù)據(jù)庫被切分后,不能再依賴數(shù)據(jù)庫自身的主鍵生成機(jī)制啦,最簡單可以考慮UUID,或者使用雪花算法生成分布式ID。
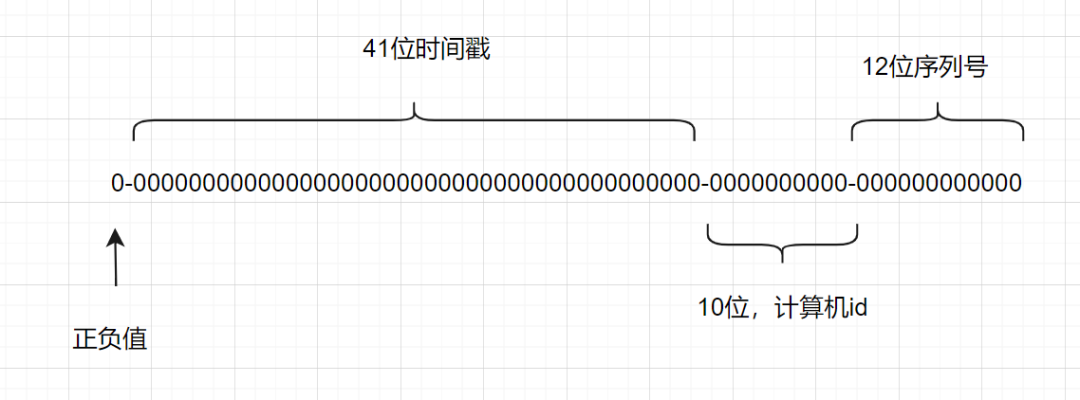
雪花算法是一種生成分布式全局唯一ID的算法,生成的ID稱為
Snowflake IDs。這種算法由
一個(gè)Snowflake ID有64位。
-
第
1位:Java中l(wèi)ong的最高位是符號位代表正負(fù),正數(shù)是0,負(fù)數(shù)是1,一般生成ID都為正數(shù),所以默認(rèn)為0。 -
接下來前
41位是時(shí)間戳,表示了自選定的時(shí)期以來的毫秒數(shù)。 -
接下來的
10位代表計(jì)算機(jī)ID,防止沖突。 -
其余
12位代表每臺機(jī)器上生成ID的序列號,這允許在同一毫秒內(nèi)創(chuàng)建多個(gè)Snowflake ID。
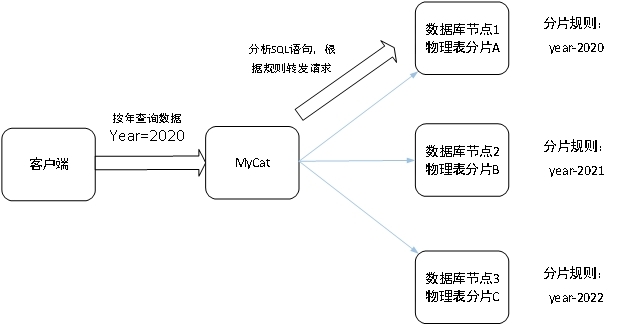
12. 分庫分表選擇哪種中間件
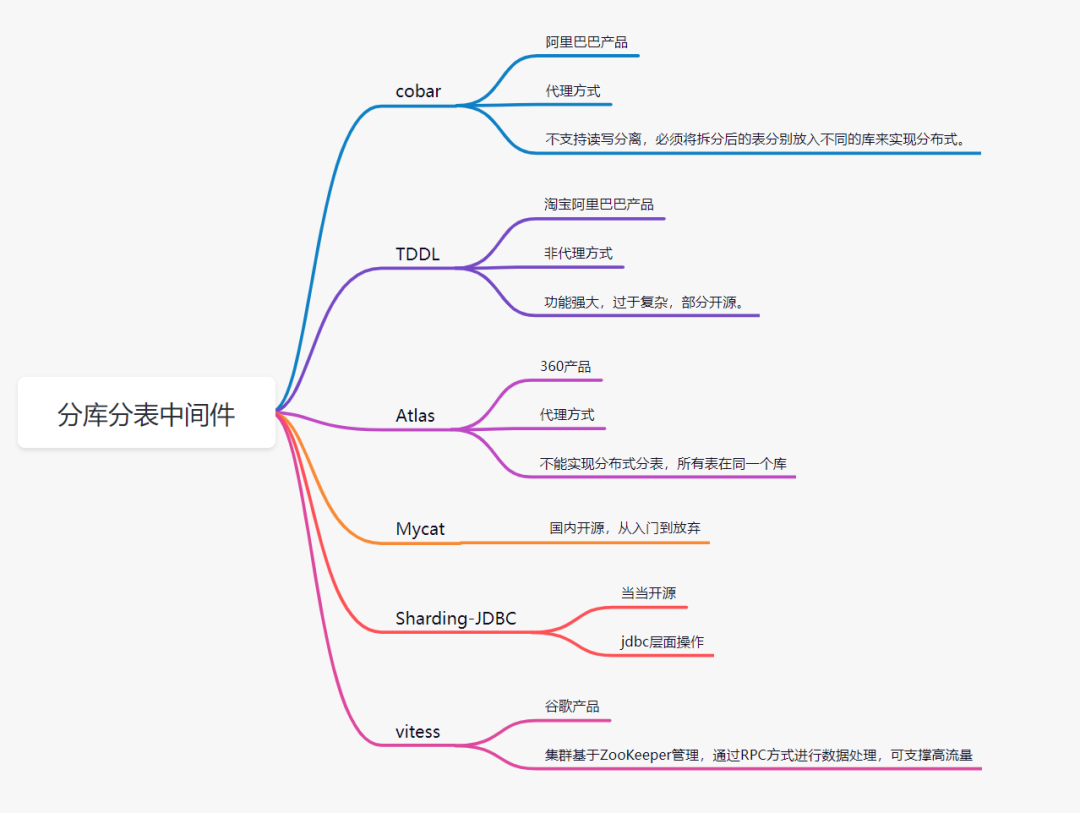
目前流行的分庫分表中間件比較多:
- Sharding-JDBC
- cobar
- Mycat
- Atlas
- TDDL(淘寶)
- vitess
我們項(xiàng)目當(dāng)前就是使用Sharding-JDBC實(shí)現(xiàn)的分庫分表。
13.如何評估分庫數(shù)量
-
對于MySQL來說的話,一般單庫超過
5千萬記錄,DB的壓力就非常大了。所以分庫數(shù)量多少,需要看單庫處理記錄能力。 -
如果分庫數(shù)量少,達(dá)不到分散存儲和減輕
DB性能壓力的目的;如果分庫的數(shù)量多,對于跨多個(gè)庫的訪問,應(yīng)用程序需要訪問多個(gè)庫。 -
一般是建議分
4~10個(gè)庫,我們公司的企業(yè)客戶信息,就分了10個(gè)庫。
14.垂直分庫、水平分庫、垂直分表、水平分表的區(qū)別
- 水平分庫:以字段為依據(jù),按照一定策略(hash、range等),將一個(gè)庫中的數(shù)據(jù)拆分到多個(gè)庫中。
- 水平分表:以字段為依據(jù),按照一定策略(hash、range等),將一個(gè)表中的數(shù)據(jù)拆分到多個(gè)表中。
- 垂直分庫:以表為依據(jù),按照業(yè)務(wù)歸屬不同,將不同的表拆分到不同的庫中。
- 垂直分表:以字段為依據(jù),按照字段的活躍性,將表中字段拆到不同的表(主表和擴(kuò)展表)中。
15.分表要停服嘛?不停服怎么做?
不用停服。不停服的時(shí)候,應(yīng)該怎么做呢,主要分五個(gè)步驟:
-
編寫代理層,加個(gè)開關(guān)(控制訪問新的
DAO還是老的DAO,或者是都訪問),灰度期間,還是訪問老的DAO。 -
發(fā)版全量后,開啟雙寫,既在舊表新增和修改,也在新表新增和修改。日志或者臨時(shí)表記下新表
ID起始值,舊表中小于這個(gè)值的數(shù)據(jù)就是存量數(shù)據(jù),這批數(shù)據(jù)就是要遷移的。 - 通過腳本把舊表的存量數(shù)據(jù)寫入新表。
- 停讀舊表改讀新表,此時(shí)新表已經(jīng)承載了所有讀寫業(yè)務(wù),但是這時(shí)候不要立刻停寫舊表,需要保持雙寫一段時(shí)間。
- 當(dāng)讀寫新表一段時(shí)間之后,如果沒有業(yè)務(wù)問題,就可以停寫舊表啦
審核編輯 :李倩
-
SQL
+關(guān)注
關(guān)注
1文章
762瀏覽量
44117 -
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3794瀏覽量
64362 -
微服務(wù)
+關(guān)注
關(guān)注
0文章
137瀏覽量
7339
原文標(biāo)題:分庫分表 15 連問,你抗的住嗎?
文章出處:【微信號:小林coding,微信公眾號:小林coding】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Redis使用重要的兩個(gè)機(jī)制:Reids持久化和主從復(fù)制

【面試題】人工智能工程師高頻面試題匯總:機(jī)器學(xué)習(xí)深化篇(題目+答案)
【面試題】人工智能工程師高頻面試題匯總:Transformer篇(題目+答案)
人工智能工程師高頻面試題匯總——機(jī)器學(xué)習(xí)篇

電子產(chǎn)品方案開發(fā)公司常用的15個(gè)單片機(jī)經(jīng)典電路分享!
軟件系統(tǒng)數(shù)據(jù)庫的分庫分表設(shè)計(jì)
面試嵌入式工作,會被問什么問題?

DS15BA101輸出電壓可調(diào)的1.5 Gbps差分緩沖器數(shù)據(jù)表

SN65C116xE 具有 ±15kV ESD 保護(hù)的雙路差分驅(qū)動(dòng)器和接收器數(shù)據(jù)表
分庫分表后復(fù)雜查詢的應(yīng)對之道:基于DTS實(shí)時(shí)性ES寬表構(gòu)建技術(shù)實(shí)踐
占道經(jīng)營監(jiān)測識別攝像機(jī)


什么是守護(hù)線程?守護(hù)線程的底層原理和使用示例





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論