 高工年會演講回顧:超級算力,賦能整車中央計算
高工年會演講回顧:超級算力,賦能整車中央計算
當下的智能電動汽車時代,已經進入智能網聯決勝的下半場,高算力芯片成為衡量汽車企業產品水平高低的重要指標之一,算力配置也成為了車企在車型規劃中的關鍵要素。此外,隨著芯片算力的提升,以及汽車應用復雜化,各功能域互相滲透,域集中式的控制架構成為一個演進趨勢。
在上周舉行的 2022(第六屆)高工智能汽車年會暨年度金球獎評選頒獎典禮上,NVIDIA 中國區軟件解決方案總監卓睿分享了以“超級算力,賦能整車中央計算”為題的演講,介紹 NVIDIA 在這個背景下如何布局并做出了哪些探索。以下為內容概要。

智駕和智艙融合趨勢突顯
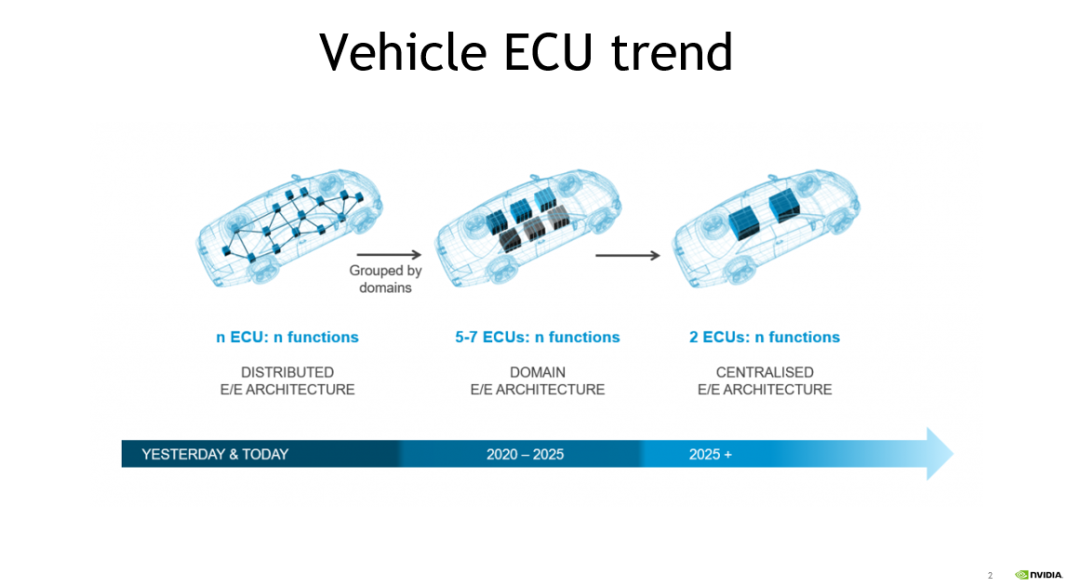
近年來,隨著汽車電子電氣架構由傳統的分布式架構向中央集成式架構演進,車內電子控制單元(ECU)數量逐漸減少。隨著芯片算力的不斷提升,自動泊車以及高級駕駛輔助系統(ADAS)等功能得以整合。
當前,汽車制造商和一級供應商希望能夠將智駕和智艙功能進行進一步融合。目前已經有客戶將基于 DRIVE Orin 的智駕芯片與相關廠商的座艙芯片集成至一塊 PCB 中或同一 ECU 中的不同 PCB 上。這種不同的技術趨勢的出現,意味著在不遠的將來,汽車內部與智能功能相關的域控制器數量將會進一步減少,芯片將大放異彩。
DRIVE Orin 踏浪爭先
強勁賦能自動駕駛
從去年開始,很多中國車企都采用了NVIDIA DRIVE Orin SoC。DRIVE Orin Soc 的算力達到 254 TOPS,內存帶寬被設定在 205GB/s,可以支持各種傳感器和 4 個 10G bps 的網絡接口,以及 H.265/HEVC/VP9 格式的 4K@60Hz 視頻編碼或者 8K@30Hz 視頻解碼。
DRIVE Orin 集成了新一代 GPU 體系架構,GPU 憑借其靈活性,可支持無人駕駛領域的算法團隊開發新的算法。另外,GPU 雖然非常靈活,但本身從能耗比來說表現還不是最好,所以 NVIDIA 又加入了 DLA(Deep Learning Accelerator,深度學習加速器)。NVIDIA 將 GPU 與 DLA 相結合,幫助客戶能夠更加靈活地將不同算法部署在不同引擎上,以達到更好的功耗比和性能表現。
除 AI 計算能力之外,對芯片而言,CPU 也至關重要。目前,NVIDIA 軟件團隊正在持續優化 CPU 算力,將需要并行的算力從 CPU 遷移到 GPU 和 DLA。此外,DRIVE Orin 芯片屬于異構的計算架構,配置了許多性能卓越的加速引擎,如適用于傳統的 CV 算法的 PVA 引擎,可用于深度學習的前處理和后處理的加速。
此外,DRIVE Orin 的帶寬也值得一提,其高達 254 TOPS 的算力都需要通過內存加載,如果帶寬速度相對較慢,就意味著帶寬才是真正的算法瓶頸。DRIVE Orin 可支持 205 GB/s 的帶寬,可避免由于帶寬不足造成的瓶頸。
現階段,通過單個或兩個 DRIVE Orin,不僅可以將標準的 ADAS 功能提升,應用于高速公路或城市道路等場景,還可以將 360 度環視、編碼、自動駕駛監測以及泊車功能集成至 DRIVE Orin 中,而這個集成的實現得益于算力的提升和芯片功能的逐步強大。
DRIVE Thor 蓄勢待發
推動實現艙駕一體融合
DRIVE Orin 是 NVIDIA 推出的第三代無人駕駛車載芯片。NVIDIA 發布的第一代 Parker 更多是基于 Linux 打通數據鏈路,例如攝像頭獲取數據后的前處理和推理等,但欠缺真正的功能安全。因而雖然被大量廠商作為開發板,但 Parker 并沒有在無人駕駛領域實現量產。NVIDIA 在 Parker 之后帶來了下一代產品—DRIVE Xavier,該產品在國內已有量產。DRIVE Xavier 有超過 90 億個晶體管,是全球第一個達到 ISO 26262 安全認證的復雜 SoC。DRIVE Orin 相比于第二代產品 DRIVE Xavier,算力水平有了進一步提升,同時架構和軟件也擁有延續性,在國內自動駕駛行業占據主流。
今年 GTC 秋季大會上發布的可實現 2000 TFLOPS 浮點算力的 DRIVE Thor,相比前三代產品而言變化較大。前三代產品主要用于解決智能駕駛的應用場景,而 DRIVE Thor 在此基礎上,還將推動實現智能座艙。在硬件層面,DRIVE Thor 利用 MIG 技術,實現 GPU 硬件在智駕域和智艙域的隔離;在軟件層面,DRIVE Thor 通過虛擬化的技術,保證渲染與 AI 功能在智艙域的并行,“軟硬共進”,實現艙駕一體融合。

DRIVE Thor 內含 780 億個晶體管,主要有三項優勢(如上圖)。
FP8 的支持
DRIVE Thor 的優勢之一是具有 8 位浮點(FP8)精度。FP8 是 NVIDIA 積極推動的一種新型的數據處理方式,其目的在于貫通軟件和硬件提供一個通用、可維持準確性的交換格式,以加速 AI 的訓練、推理。傳統意義上講,開發人員在從 32 位浮點轉換成 8 位整數(8-int)的數據格式時,往往會損失神經網絡的準確性。DRIVE Thor 在 FP8 精度下 2000 TFLOPS 的浮點算力,讓開發人員在不犧牲精度和準確性的情況下進行數據傳輸。事實上,FP8 的主要目的是支持推理 Transformer 引擎的自動駕駛汽車平臺,該引擎是 NVIDIA GPU 中 Tensor Core 的新組件。借助該引擎,DRIVE Thor 可將 Transformer 深度神經網絡的推理性能提升高達 9 倍,這對于支持與自動駕駛相關的、龐大且復雜的 AI 工作負載至關重要。
多域計算
DRIVE Thor 支持多域計算,可隔離用于自動駕駛和車載信息娛樂的功能。車輛中通常會分布數十個 ECU 來為各個功能提供支持,借助 DRIVE Thor,汽車制造商可以在單個系統級芯片(SoC)上高效整合多種功能,可滿足智能座艙和智能駕駛對 GPU 不同的安全性和穩定性的需求,能夠緩解算力供應緊張并簡化車輛設計開發,從而進一步顯著降低運行能耗、減輕重量并減少布線。
NVLink-C2C 芯片互聯技術
DRIVE Thor 還采用了最新的 NVLink-C2C 芯片互聯技術,可同時運行多個操作系統。用戶可以單獨使用 DRIVE Thor 芯片,也可以通過最新的 NVLink-C2C 芯片互連技術同時連接兩個 Thor 芯片,使兩個芯片作為單一操作系統的統一平臺。
NVLink-C2C 的優勢在于它能夠以最小的開銷在超高速數據傳輸鏈路中共享、調度和分發任務。在軟件定義汽車的發展趨勢下,這為汽車制造商帶來足夠大的算力冗余和靈活性,支持軟件定義車輛的開發,這些車輛可通過安全的 OTA 更新持續升級。
軟件賦能“行穩致遠”
那么如何讓中央域控制的芯片更富競爭力呢?除了硬件的支持外,軟件賦能也必不可少。無論是 DRIVE Orin 還是 DRIVE Thor,都是 SOA 架構,該架構擁有很強的延續性。該部分著重介紹以下幾點:
-
DRIVE Orin 和 DRIVE Thor 的 API,也就是所謂的中間件,以及底層的大部分架構非常相似,可支持有 DRIVE Orin 開發經驗的開發人員,將其開發的代碼輕松遷移至 DRIVE Thor。
-
基于 NVIDIA DRIVE OS 的經驗。DRIVE Orin 和 DRIVE Thor 均支持基于 Hypervisor 的 Guest OS 架構。客戶可根據場景的需要,靈活地配置一個或者多個 Guest OS 作為操作系統。
-
安全標準受重視程度逐漸提高,廠商也更加關注安全需求。NVIDIA 在軟硬件方面都進行了功能安全性的提升。
-
隨著芯片逐漸開始支持多域計算,虛擬化的重要程度也不斷提升。當前,NVIDIA 可利用自有的 Hypervisor 實現虛擬化,避免不同模塊之間產生干擾,實現資源隔離。
DRIVE Orin 是利用了相同的 Hypervisor,其 ADAS 功能可根據客戶需求選擇 Linux 或 QNX 作為操作系統。當前國內主流選擇是 QNX 系統,但仍有不少數客戶選擇使用 Linux。NVIDIA 與黑莓(BlackBerry)進行了深度合作,通過 QOS 版本滿足 ASIL-D 級別的功能安全。
在 DRIVE Thor 中,用戶可整合儀表盤、車載信息娛樂(IVI)等功能。因此,可以支持三個 Guest OS 來滿足不同域的需求。
NVIDIA 對于深度學習領域關注的不僅僅是 TOPS 算力本身。如圖所示是 NVIDIA 每一代芯片產品最高可達的算力水平,在此基礎上還需考慮帶寬以及可編程性等。對于可編程性而言,NVIDIA CUDA 架構可支持業界流行的 TensorFlow、PythonTorch 等典型訓練框架,擁有良好的可編程性。
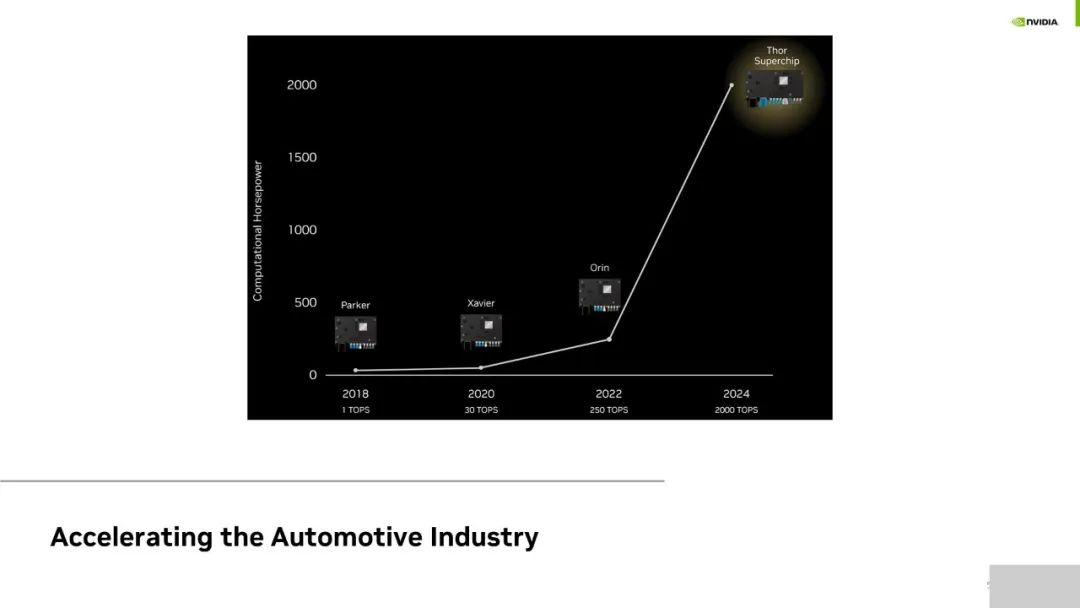
而編譯器實際上是一個推理架構,能夠優化以 Python 或 Tensorflow 輸入的網絡架構,包括對 Layer 的融合,精度的優化等,能夠在保證準確性的同時大幅提升性能。NVIDIA 支持不同的網絡,包括檢測、分類、Transformer 和對話式 AI 等。因為目前智能座艙的對話式 AI 部署很多是基于云上進行的,希望未來客戶能夠借助 NVIDIA 提供的算力支持,將他們部署在云端的算法部署在 DRIVE Thor 中。
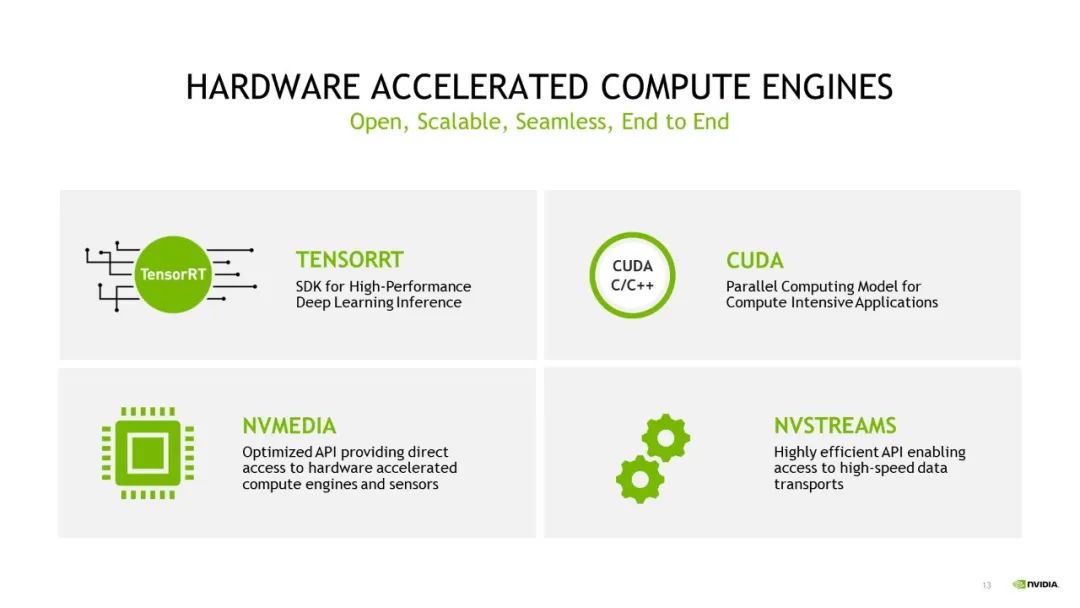
除上文提到的 DRIVE OS 以外,NVIDIA 還將在 DRIVE Orin 和 DRIVE Thor 等產品中延續使用 NVIDIA DRIVE SDK 和 CUDA 架構。SDK 的延續,可賦能應用遷移,如將基于 DRIVE Orin 開發的應用輕松遷移至 DRIVE Thor 平臺。如 NvMedia 可用于收集傳感器數據并無縫傳輸至 GPU 引擎和 DLA 引擎中,而 NvStreams 則相當于一個用于內存管理和傳輸的 SDK,可以實現不同應用場景之間的數據傳輸,包括跨線程、跨進程和跨 VM 之間的傳輸。
原文標題:高工年會演講回顧:超級算力,賦能整車中央計算
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3791瀏覽量
91290
原文標題:高工年會演講回顧:超級算力,賦能整車中央計算
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
算家計算 開啟貴州人工智能算力服務新篇章

燧原科技入選先進計算賦能新質生產力典型應用案例
億緯鋰能受邀出席2024高工鋰電年會
本源“量超融合先進計算平臺”入選2024算力中國·年度重大成果

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
穩定、高效、低成本,儲能與算力正在相互賦能
算力的分類與現代生活
算能亮相第七屆數字中國建設峰會,以算力賦能千行百業

馬斯克欲建xAI超級算力工廠
中科創達全球首發面向中央計算的AI原生整車操作系統—滴水OS
DPU技術賦能下一代AI算力基礎設施
中國移動發布基于飛騰CPU自主研發的賦能AI算力時代的新產品







 工商網監
工商網監
評論