") Intel Sapphire Rapids CPU,吹響反攻DPU的號(hào)角
Intel Sapphire Rapids CPU,吹響反攻DPU的號(hào)角
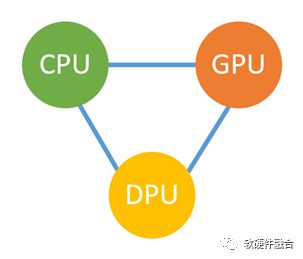
CPU、GPU和DPU是數(shù)據(jù)中心的三大芯片,通常情況下:CPU主要用于業(yè)務(wù)應(yīng)用的處理,GPU用于性能敏感業(yè)務(wù)的彈性加速,而DPU則是基礎(chǔ)設(shè)施加速。站在CPU的視角:一開始所有事情都是我的,然后GPU從我這“搶”過(guò)去了一部分工作,現(xiàn)在又出現(xiàn)個(gè)DPU來(lái)跟我“搶食”。是可忍孰不可忍,必須堅(jiān)決反擊!
01CPU視角看硬件加速
站在CPU視角,最開始,一切處理都通過(guò)處理器CPU的常規(guī)指令集完成。隨著CPU性能瓶頸,需要硬件加速的方式來(lái)提升性能。硬件加速大致有如下幾種方式:
方式1:實(shí)現(xiàn)支持?jǐn)U展指令集的協(xié)處理器,實(shí)現(xiàn)一定程度的加速能力。比如Intel集成的AVX和AMX指令集,ARM的NEON指令集等。
方式2:獨(dú)立的單一架構(gòu)的加速器。比如GPU、AI芯片。
方式3:獨(dú)立的多架構(gòu)集成加速器。比如DPU。
方式4:即將開始的一種方式,集成單個(gè)或多個(gè)加速器。
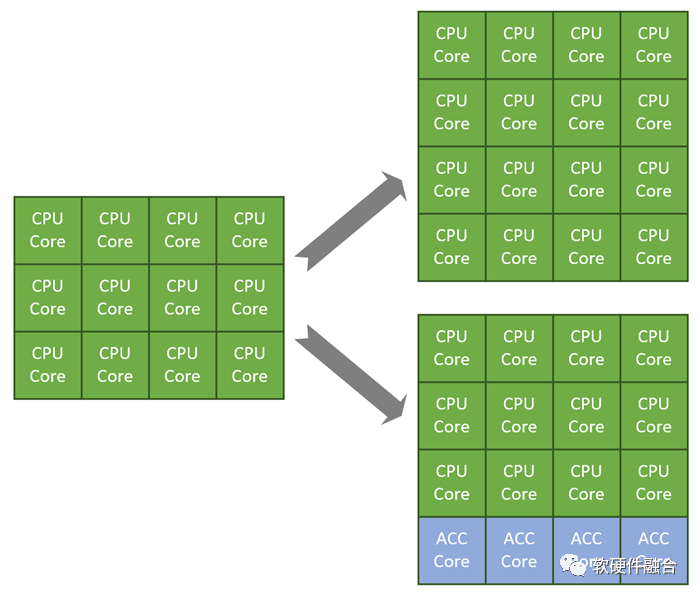
這里需要大家區(qū)分兩個(gè)概念:處理器核和處理器芯片。處理器芯片是由同構(gòu)或異構(gòu)的處理器核組成的。
CPU已經(jīng)到了性能瓶頸,這是大家的共識(shí);當(dāng)CPU遇到性能瓶頸的時(shí)候,通過(guò)加速的方式進(jìn)一步提升性能,也是大家的共識(shí)。但是,加速的實(shí)現(xiàn)形態(tài),是分立的多個(gè)芯片,還是集成的單個(gè)芯片,就是“仁者見仁智者見智”的事情了。獨(dú)立的DPU公司會(huì)認(rèn)為,獨(dú)立的DPU有很多的優(yōu)勢(shì);但是在CPU廠家而言,通過(guò)CPU集成加速器核,使得CPU成為某種程度上的類SOC芯片,也是完全可行的。
02獨(dú)立DPU的價(jià)值基礎(chǔ)并不牢靠
DPU作為獨(dú)立的集成加速平臺(tái),其價(jià)值可以從四個(gè)方面進(jìn)行闡述:
價(jià)值一:為了進(jìn)一步提升性能,DPU實(shí)現(xiàn)CPU工作任務(wù)的卸載和加速;
價(jià)值二:從I/O的硬件虛擬化(也可以看做是I/O模擬的硬件卸載)開始,DPU實(shí)現(xiàn)I/O模擬、I/O Workload以及整個(gè)虛擬化和基礎(chǔ)設(shè)施層的全量卸載和加速;
價(jià)值三:從運(yùn)維和管理視角,DPU重要的價(jià)值在于實(shí)現(xiàn)了業(yè)務(wù)和基礎(chǔ)設(shè)施分離,實(shí)現(xiàn)了業(yè)務(wù)主機(jī)的安全訪問(wèn);
價(jià)值四:面向更大計(jì)算量和數(shù)據(jù)吞吐量,DPU實(shí)現(xiàn)從“以計(jì)算為中心”到“以數(shù)據(jù)為中心”。
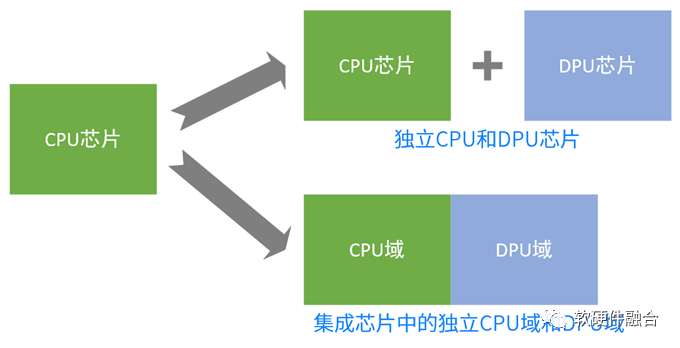
DPU的前三個(gè)價(jià)值,其實(shí)現(xiàn):可以是獨(dú)立的DPU芯片實(shí)現(xiàn),也可以是集成的DPU域?qū)崿F(xiàn)。這對(duì)功能和特征沒(méi)有任何影響,甚至集成的方式,還有一些優(yōu)勢(shì):優(yōu)化訪問(wèn)效率,提升性能;集成芯片進(jìn)一步降低成本和功耗。
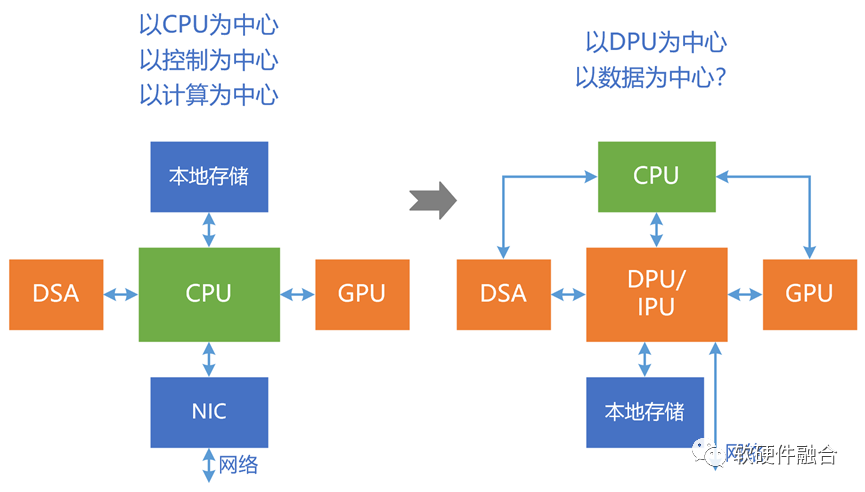
DPU的第四個(gè)價(jià)值,一方面,和獨(dú)立或集成無(wú)關(guān),也就是說(shuō)獨(dú)立或集成都可以;另一方面,DPU并不一定能夠?qū)崿F(xiàn)以數(shù)據(jù)為中心的價(jià)值。
上面這張圖,通常把左邊的稱為“以計(jì)算為中心”,右邊的稱為“以數(shù)據(jù)為中心”。然而,這種表述是有問(wèn)題的。嚴(yán)格來(lái)說(shuō),左邊稱為“以CPU為中心”、“以控制為中心”或者“以計(jì)算為中心”是可以的,右邊這張圖稱為“以DPU為中心”是合適的,但如果稱為“以數(shù)據(jù)為中心”則是不準(zhǔn)確的。“以DPU為中心”并不一定等于“以數(shù)據(jù)為中心”,“以DPU為中心”,完全可能是“以‘CPU’為中心”,或者說(shuō)是“以計(jì)算為中心”。
最終的結(jié)論是:很多DPU其實(shí)并非嚴(yán)格意義上的數(shù)據(jù)驅(qū)動(dòng)處理器,并且即使DPU是數(shù)據(jù)驅(qū)動(dòng)的,依然無(wú)法保證整個(gè)計(jì)算機(jī)系統(tǒng)是完全數(shù)據(jù)驅(qū)動(dòng)的。
03Intel Sapphire Rapids CPU介紹

Sapphire Rapids是Intel新一代的數(shù)據(jù)中心CPU,用于接替Ice Lake。Sapphire Rapids相比Ice lake,從單個(gè)TILE變成了4個(gè)TILE的Chiplet集成。
Sapphire Rapids可以提供更高的單節(jié)點(diǎn)性能:
處理器方面,如更高性能的微架構(gòu)實(shí)現(xiàn)、更多的內(nèi)核數(shù)量、AMX擴(kuò)展、多個(gè)集成的加速引擎等;
存儲(chǔ)方面,如更大的私有/共享緩存、DDR5/HBM等;
I/O方面,如采用PCIe 5.0、UPI2.0、支持新一代Optane等;
Chiplet封裝:EMIB總線實(shí)現(xiàn)多TILE集成。
除了單芯片的性能提升之外,Sapphire Rapids還提供更高的數(shù)據(jù)中心整體性能,例如快速VM遷移、更強(qiáng)的遙測(cè)能力、更強(qiáng)的I/O虛擬化、緩存和內(nèi)存性能一致性、新一代QoS、CXL1.1、更加的彈性,以及提升資源利用率等等。
而Sapphire Rapids的最大創(chuàng)新則是:AIA。通過(guò)AIA集成多種加速引擎,包括數(shù)據(jù)流加速器DSA(Data Stream Accelerator,不是Domain Specific Architecture)、QAT等。我們將在接下來(lái)的一節(jié)對(duì)AIA詳細(xì)介紹。
04Intel里程碑:AIA
4.1 背景知識(shí):加速器接口/架構(gòu)
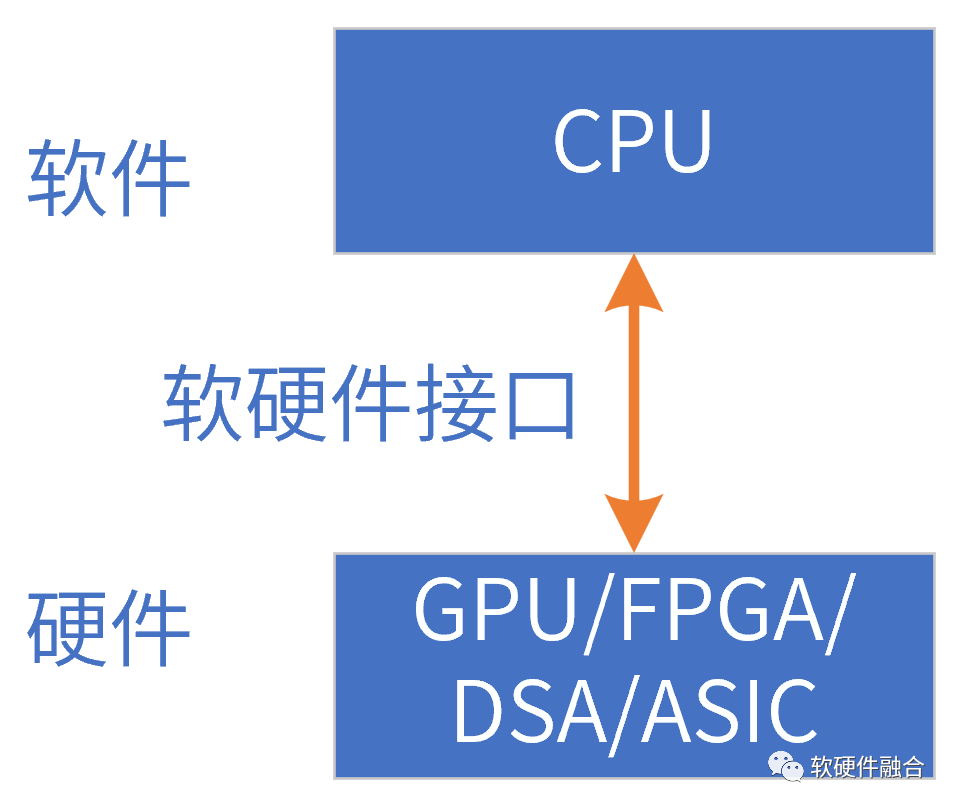
相對(duì)于CPU,其他類型的處理器,都可以稱為加速處理器,如:GPU、DSA和ASIC等(FPGA需要具體的處理器實(shí)現(xiàn))。這些加速器都是非圖靈完備的,因此都需要和CPU組合成Host CPU+xPU的異構(gòu)計(jì)算方式工作。
加速器接口,也即加速器呈現(xiàn)給Host CPU的軟件訪問(wèn)接口,也可以稱為加速器架構(gòu)。在這里,架構(gòu)和接口的概念是等同的。
4.2 AIA技術(shù)介紹
AIA(Accelerator interfacing Architecture,加速器接口架構(gòu))不是一個(gè)簡(jiǎn)單的功能或特征實(shí)現(xiàn),而是一組相關(guān)技術(shù)能力的組合(類比Intel的VT-x和VT-d技術(shù))。從Intel新一代Xeon處理器Sapphire Rapids開始,提供加速接口技術(shù)AIA,其技術(shù)點(diǎn)包括如下:
任務(wù)分配指令(MOVDIRI、MOVDIR64B、ENQCMD/S)用于優(yōu)化任務(wù)卸載,ENQCMD/S支持共享任務(wù)隊(duì)列;
用戶態(tài)等待指令(UMONITOR、UMWAIT、TPAUSE),用于高效同步;
低延遲用戶態(tài)中斷;
共享虛擬內(nèi)存;
輕量的可擴(kuò)展I/O虛擬化S-IOV。
AIA目前支持的加速類型有:數(shù)據(jù)流處理DSA、加解密和數(shù)據(jù)壓縮QAT等。
4.3 Intel AIA的戰(zhàn)略意圖分析
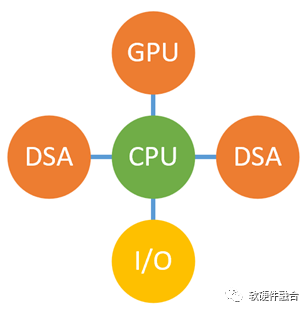
作為全能型的處理器,通吃整個(gè)計(jì)算市場(chǎng)幾十年的CPU,面臨性能瓶頸的巨大挑戰(zhàn)。于是,各種加速處理器,如GPU、DPU等,都在拼命地“挖CPU的墻角”。
作為CPU的霸主,Intel肯定不會(huì)“坐以待斃”,一定會(huì)“奮起反擊”。AIA就是Intel準(zhǔn)備的“核彈”級(jí)的武器,AIA是Intel CPU的重要里程碑,其戰(zhàn)略意圖(可能)是:
捍衛(wèi)CPU的核心地位,所有的一切加速器都需要圍繞著CPU技術(shù)生態(tài)展開;
Intel試圖通過(guò)AIA統(tǒng)一加速器接口、架構(gòu)和生態(tài)。以GPU作為案例:一方面GPU是獨(dú)立的架構(gòu)和生態(tài),與CPU架構(gòu)是解耦的,可以基于x86架構(gòu),也可以遷移到ARM或RISCv架構(gòu);另一方面,GPU架構(gòu)是各自封閉的,NVIDIA有自己的架構(gòu)和生態(tài),AMD有自己的架構(gòu)和生態(tài)。AIA也許無(wú)法把所有的不同加速器類型都統(tǒng)一到一個(gè)標(biāo)準(zhǔn)的AIA,但是把GPU統(tǒng)一一個(gè),各種領(lǐng)域加速器DSA各統(tǒng)一一個(gè),是完全可能并且技術(shù)上可行的。
一些常見的、關(guān)鍵的加速器,就自己搞定,集成到CPU中,比如Sapphire Rapids集成了數(shù)據(jù)流處理DSA(DSA可以把很多數(shù)據(jù)處理類的加速統(tǒng)一進(jìn)來(lái),如網(wǎng)絡(luò)和存儲(chǔ)等)和QAT,未來(lái)再集成AI、網(wǎng)絡(luò)、存儲(chǔ)、虛擬化卸載、安全等基礎(chǔ)設(shè)施層處理(也即DPU覆蓋的范疇)功能或加速器,其可能性也是非常的高。
05Intel CPU的未來(lái)發(fā)展分析
CPU發(fā)展的幾個(gè)重要里程碑:
里程碑0:CPU的出現(xiàn)。基于簡(jiǎn)單運(yùn)算指令的通用處理器,實(shí)現(xiàn)軟件和硬件的完全解耦。從此后,軟件作為獨(dú)立的工作領(lǐng)域而存在,軟件開發(fā)人員不用關(guān)心硬件細(xì)節(jié)。
里程碑1:多核CPU,從串行計(jì)算走向并行計(jì)算。
里程碑2:VT-x和VT-d等CPU硬件虛擬化技術(shù),實(shí)現(xiàn)無(wú)性能損耗的多租戶多系統(tǒng)的獨(dú)立運(yùn)行;
里程碑3:AIA技術(shù)的出現(xiàn),通過(guò)AIA,支持獨(dú)立或集成加速器,并且規(guī)范加速器的接口/架構(gòu)和生態(tài)。
Sapphire Rapids的出現(xiàn),第一次從CPU的視角,試圖統(tǒng)一各種加速器和CPU的控制和數(shù)據(jù)交互方式,也即加速器呈現(xiàn)給Host CPU的架構(gòu)。未來(lái),AIA的方式能否成功,大家拭目以待。
硬件加速,不管是獨(dú)立或集成的加速引擎/芯片,都是可行的路徑。但拋開具體的芯片實(shí)現(xiàn),在架構(gòu)上,硬件加速的形態(tài)會(huì)再往何處發(fā)展?這里我們拋磚引玉:
標(biāo)準(zhǔn)的交互(Host CPU和加速器的接口或稱為架構(gòu)),統(tǒng)一加速器架構(gòu)。可能無(wú)法把不同類型的加速器統(tǒng)一,但同類型的架構(gòu)走向統(tǒng)一。
標(biāo)準(zhǔn)交互的同時(shí),需要開放,需要跟CPU架構(gòu)解耦,可以跨不同的CPU架構(gòu)實(shí)現(xiàn)同樣的交互協(xié)議;
基于標(biāo)準(zhǔn)的交互,基于一定的機(jī)制,要實(shí)現(xiàn)業(yè)務(wù)應(yīng)用的跨處理器類型運(yùn)行。
Intel Sapphire Rapids,代表著CPU的一個(gè)重要的發(fā)展趨勢(shì)是:CPU芯片不斷融合各類加速器核,使得自己成為更加綜合和均衡的新型處理器。
06CPU、GPU、DPU,
從競(jìng)爭(zhēng)/協(xié)同到混戰(zhàn)/融合
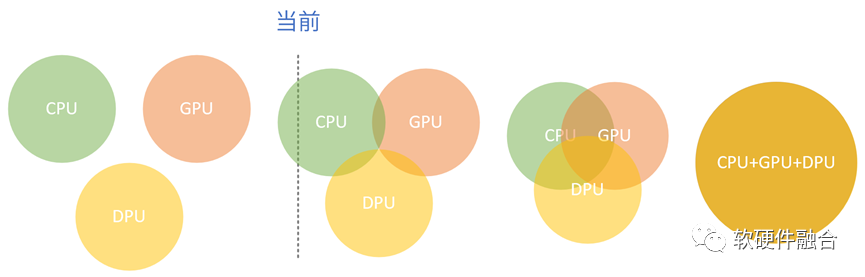
目前,CPU、GPU和DPU,數(shù)據(jù)中心的三大芯片,從“井水不犯河水”,走向“跨越邊界,侵入對(duì)方領(lǐng)地”的混戰(zhàn)階段。
CPU、GPU和DPU,既是協(xié)同的關(guān)系,又是競(jìng)爭(zhēng)的關(guān)系。三者處于一個(gè)動(dòng)態(tài)平衡的狀態(tài),在協(xié)同中競(jìng)爭(zhēng),在競(jìng)爭(zhēng)中協(xié)同。這個(gè)趨勢(shì)不斷發(fā)展,走向更加深度地協(xié)同甚至融合。
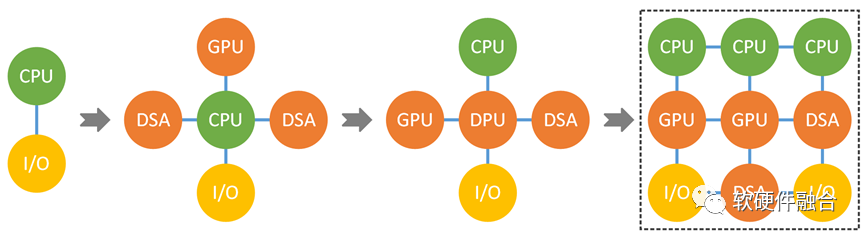
從CPU單個(gè)處理器的“合”,走向眾多加速器的“分”,再“從分到合”,逐步融合成一個(gè)新型的超級(jí)處理器。
審核編輯 :李倩
-
cpu
+關(guān)注
關(guān)注
68文章
10858瀏覽量
211645 -
SoC芯片
+關(guān)注
關(guān)注
1文章
610瀏覽量
34912 -
DPU
+關(guān)注
關(guān)注
0文章
358瀏覽量
24170
原文標(biāo)題:Intel Sapphire Rapids CPU,吹響反攻DPU的號(hào)角
文章出處:【微信號(hào):算力基建,微信公眾號(hào):算力基建】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
九聯(lián)科技與海思移動(dòng)機(jī)頂盒集采落地開工宴
RAPIDS cuDF將pandas提速近150倍

【「算力芯片 | 高性能 CPU/GPU/NPU 微架構(gòu)分析」閱讀體驗(yàn)】--全書概覽
數(shù)據(jù)中心應(yīng)用中適用于Intel Xeon Sapphire Rapids可擴(kuò)展處理器的負(fù)載點(diǎn)解決方案

數(shù)據(jù)中心應(yīng)用中適用于Intel? Xeon? Sapphire Rapids可擴(kuò)展處理器的負(fù)載點(diǎn)解決方案
Intel預(yù)告下一代至強(qiáng)處理器:Diamond Rapids攜LGA9324接口震撼登場(chǎng)
中科馭數(shù)分析DPU在云原生網(wǎng)絡(luò)與智算網(wǎng)絡(luò)中的實(shí)際應(yīng)用
IaaS+on+DPU(IoD)+下一代高性能算力底座技術(shù)白皮書
SAPPHIRE SF NX 簡(jiǎn)介
熱壓一體成型電感異響會(huì)影響使用嗎
明天線上見!DPU構(gòu)建高性能云算力底座——DPU技術(shù)開放日最新議程公布!
拓維信息吹響龍年沖鋒第一聲號(hào)角

數(shù)據(jù)中心CPU市場(chǎng):國(guó)內(nèi)廠商面臨巨大挑戰(zhàn)
Intel酷睿Ultra CPU IPC性能實(shí)測(cè)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論