 使用FastDeploy在英特爾CPU和獨立顯卡上端到端高效部署AI模型
使用FastDeploy在英特爾CPU和獨立顯卡上端到端高效部署AI模型
1.1產業實踐中部署 AI 模型的痛點
1.1.1部署 AI 模型的典型流程
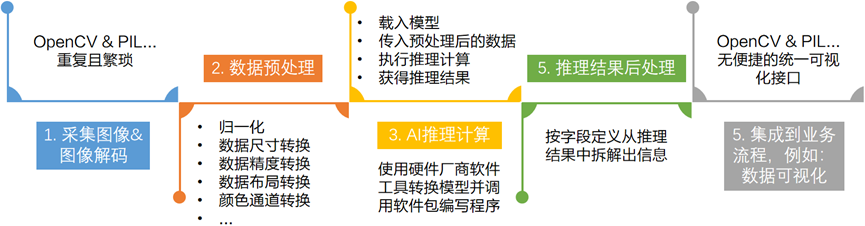
對于來自于千行百業,打算將 AI 模型集成到自己的主線產品中,解決本行痛點的 AI 開發者來說,部署 AI 模型,或者說將 AI 模型集成到自己產品中去的典型步驟(以計算機視覺應用為例)有:
采集圖像&圖像解碼
數據預處理
執行 AI 推理計算
推理結果后處理
將后處理結果集成到業務流程
1.1.2端到端的 AI 性能
當 AI 開發者將 AI 模型集成到業務流程后,不太關心 AI 模型在 AI 推理硬件上單純的推理速度,而是關心包含圖像解碼、數據預處理和后處理的端到端的 AI 性能。
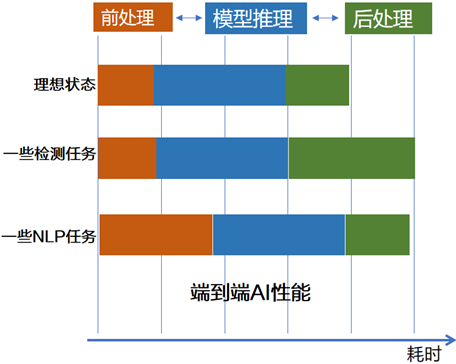
在產業實踐中,我們發現不僅 AI 推理硬件和對應推理引擎(例如:OpenVINO Runtime)對于端到端的性能影響大,數據預處理和后處理代碼是否高效對于端到端的性能影響也大。
以 CPU 上預處理操作融合優化為例,經過優化后的前處理代碼,可以使得 AI 端到端性能得到較大提升。
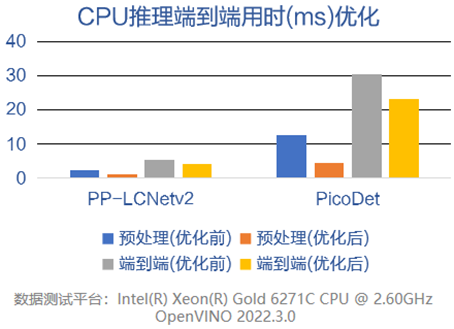
數據來源:感謝 FastDeploy 團隊完成測試并提供數據
結論:優秀且高效的前后處理代碼,可以明顯提高端到端的 AI 性能!
1.1.3部署 AI 模型的難點和痛點
在產業實踐中,在某個任務上當前最優的 SOTA 模型的很有可能與部署相關的文檔和范例代碼不完整,AI 開發者需要通過閱讀 SOTA 模型源代碼來手動編寫模型的前后處理代碼,這導致:
01耗時耗力
閱讀 SOTA 模型源代碼來理解模型的前后處理,提高了部署模型的技術門檻。另外,手動編寫前后處理代碼,也需要更多的測試工作來消除 bug。
02精度隱患
手動或借助網上開源但未經過實踐驗證過的前后處理代碼,會有精度隱患,即當前對于某些圖片精度很好,但對于另外的圖片精度就下降。筆者就遇到過類似問題,原因在于調用了一個 GitHub 上下載的 NMS()函數,這個函數對代碼倉提供的范例模型有效,但對于筆者使用的模型恰恰就出現丟失檢測對象的問題。
03優化困難
解決了精度問題后,下一步就是通過多線程、模型壓縮、Batch 優化等軟件技術進一步提升端到端的 AI 性能,節約硬件采購成本。這些軟件技術對于計算機專業的工程師不算挑戰,但對于千行百業中非計算機專業的工程師,卻無形中建立起了一道極高的門檻。
為了賦能千行百業的工程師,高效便捷的將 AI 模型集成到自己的產品中去,急需一個專門面向 AI 模型部署的軟件工具。
1.2FastDeploy 簡介
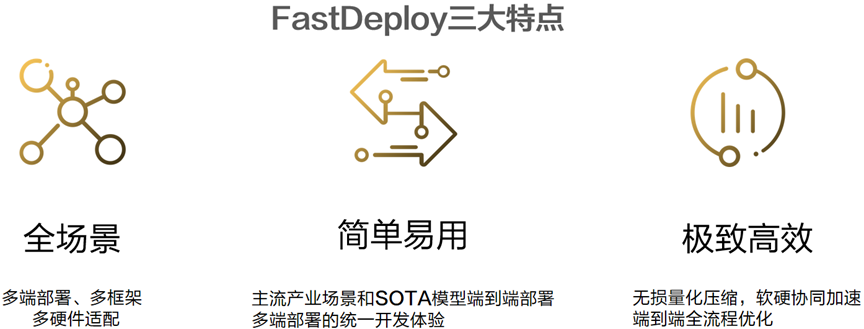
FastDeploy是一款全場景、易用靈活、極致高效的 AI 推理部署工具。提供開箱即用的云邊端部署體驗, 支持超過150+Text,Vision,Speech 和跨模態模型,并實現端到端的推理性能優化。包括圖像分類、物體檢測、圖像分割、人臉檢測、人臉識別、關鍵點檢測、摳圖、OCR、NLP、TTS 等任務,滿足開發者多場景、多硬件、多平臺的產業部署需求。
FastDeploy 項目鏈接:
https://github.com/PaddlePaddle/FastDeploy
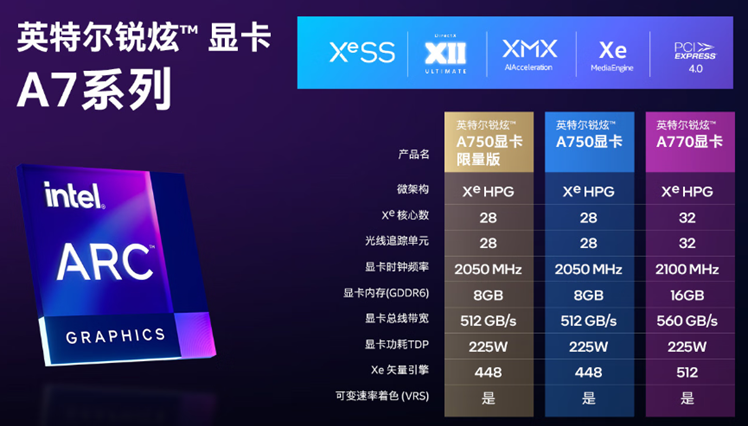
1.3英特爾獨立顯卡簡介
英特爾在2021年的構架日上發布了獨立顯卡產品路線圖,OpenVINO 從2022.2版本開始支持 AI 模型在英特爾獨立顯卡上做 AI 推理計算。

當前已經可以購買的消費類獨立顯卡是英特爾銳炫獨立顯卡A7系列,并已發布在獨立顯卡上做 AI 推理計算的范例程序。
1.4使用 FastDeploy
在英特爾 CPU 和獨立顯卡上
部署模型的步驟
1.4.1搭建 FastDeploy 開發環境
當前 FastDeploy 最新的 Release 版本是1.0.1,一行命令即可完成 FastDeploy 的安裝:
pip install fastdeploy-python –f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
向右滑動查看完整代碼
1.4.2下載模型和測試圖片
FastDeploy 支持的 PaddleSeg 預訓練模型下載地址:
https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/vision/segmentation/paddleseg
測試圖片下載地址:
https://paddleseg.bj.bcebos.com/dygraph/demo/cityscapes_demo.png
使用命令,下載模型和測試圖片:
圖片: wget https://paddleseg.bj.bcebos.com/dygraph/demo/cityscapes_demo.png 模型: wget https://github.com/PaddlePaddle/FastDeploy/tree/develop/examples/vision/segmentation/paddleseg
向右滑動查看完整代碼
1.4.3三行代碼完成在英特爾 CPU 上的模型部署
基于 FastDeploy,只需三行代碼即可完成在英特爾 CPU上的模型部署,并獲得經過后處理的推理結果。
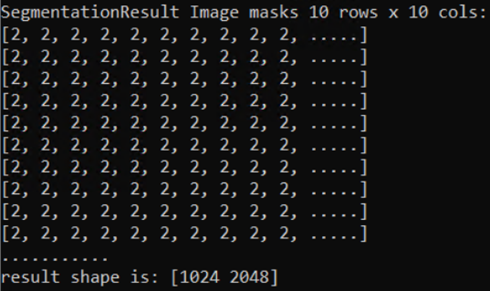
import fastdeploy as fd import cv2 # 讀取圖片 im = cv2.imread("cityscapes_demo.png") # 加載飛槳PaddleSeg模型 model = fd.vision.segmentation.PaddleSegModel(“model.pdmodel”, “model.pdiparams”,“deploy.yaml”) # 預測結果 result = model.predict(im) print(result)
向右滑動查看完整代碼
將推理結果 print 出來,如下圖所示,經過 FastDeploy 完成的 AI 推理計算,拿到的是經過后處理的結果,可以直接將該結果傳給業務處理流程。
1.4.4
使用 RuntimeOption 將 AI 推理硬件
切換英特爾獨立顯卡
在上述三行代碼的基礎上,只需要使用RuntimeOption將AI推理硬件切換為英特爾獨立顯卡,完成代碼如下所示:
import fastdeploy as fd
import cv2
# 讀取圖片
im = cv2.imread("cityscapes_demo.png")
h, w, c = im.shape
# 通過RuntimeOption配置后端
option = fd.RuntimeOption()
option.use_openvino_backend()
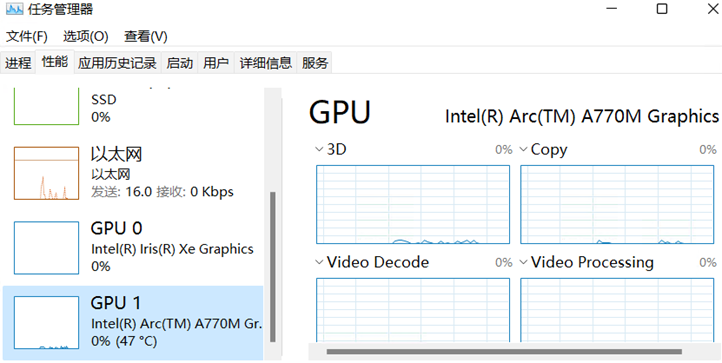
option.set_openvino_device("GPU.1")
# 固定模型的輸入形狀
option.set_openvino_shape_info({"x": [1,c,h,w]})
# 加載飛槳PaddleSeg模型
model = fd.vision.segmentation.PaddleSegModel(“model.pdmodel”, “model.pdiparams”,“deploy.yaml”,
runtime_option=option)
# 預測結果
result = model.predict(im)
向右滑動查看完整代碼
set_openvino_device()中字符串填寫“GPU.1”是根據英特爾獨立顯卡在操作系統的中設備名稱,如下圖所示:
當前,在英特爾獨立顯卡上做 AI 推理,需要注意的問題有:
需要固定模型輸入節點的形狀(Shape)
英特爾 GPU 上支持的算子數量與 CPU 并不一致,在部署 PPYOLE 時,如若全采用 GPU 執行,會出現如下提示

這是需要將推理硬件設置為異構方式
option.set_openvino_device("HETERO:GPU.1,CPU")
向右滑動查看完整代碼
到此,使用 FastDeploy 在英特爾 CPU 和獨立顯卡上部署AI模型的工作全部完成。
1.5總結
面對千行百業中部署 AI 模型的挑戰,FastDeploy 工具很好的保證了部署 AI 模型的精度,以及端到端 AI 性能問題,也提高了部署端工作的效率。通過 RuntimeOption,將 FastDeploy 的推理后端設置為 OpenVINO,可以非常便捷將 AI 模型部署在英特爾 CPU、集成顯卡和獨立顯卡上。
-
英特爾
+關注
關注
61文章
9949瀏覽量
171693 -
cpu
+關注
關注
68文章
10854瀏覽量
211578 -
顯卡
+關注
關注
16文章
2431瀏覽量
67574 -
AI
+關注
關注
87文章
30728瀏覽量
268886
原文標題:使用FastDeploy在英特爾CPU和獨立顯卡上端到端高效部署AI模型 | 開發者實戰
文章出處:【微信號:英特爾物聯網,微信公眾號:英特爾物聯網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于C#和OpenVINO?在英特爾獨立顯卡上部署PP-TinyPose模型
英特爾CPU部署Qwen 1.8B模型的過程
英特爾高清顯卡4600幫助
介紹英特爾?分布式OpenVINO?工具包
英特爾宣布首款獨立顯卡 意味著英特爾加入 GPU 戰局
英特爾推出面向OEM市場的入門級Xe獨立顯卡
英特爾推出銳炫A系列獨立顯卡 微星推出GeForce RTX 3090 Ti系列顯卡
低門檻AI部署工具FastDeploy開源!
在英特爾獨立顯卡上部署YOLOv5 v7.0版實時實例分割模型
使用PyTorch在英特爾獨立顯卡上訓練模型
使用英特爾AI PC為YOLO模型訓練加速






 工商網監
工商網監
評論