 TI Edge AI Academy簡化嵌入式邊緣AI應用開發
TI Edge AI Academy簡化嵌入式邊緣AI應用開發
如果在沒有嵌入式處理器供應商提供的合適工具和軟件的支持下,既想設計高能效的邊緣人工智能(AI)系統,同時又要加快產品上市時間,這項工作難免會冗長乏味。面臨的一系列挑戰包括選擇恰當的深度學習模型、針對性能和精度目標對模型進行訓練和優化,以及學習使用在嵌入式邊緣處理器上部署模型的專用工具。
下面讓我們來了解如何不借助手動工具或手動編程來選擇模型、隨時隨地訓練模型并將其無縫部署到TI處理器上,從而實現硬件加速推理。
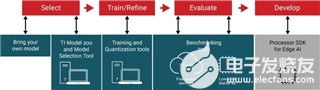
圖1: 邊緣AI應用的開發流程
第1步:選擇模型
邊緣AI系統開發的首要任務是選擇合適的DNN模型,同時要兼顧系統的性能、精度和功耗目標。GitHub上的TI邊緣AI Model Zoo等工具可助您加速此流程。
Model Zoo廣泛匯集了TensorFlow、PyTorch和MXNet框架中常用的開源深度學習模型。這些模型在公共數據集上經過預訓練和優化,可以在TI適用于邊緣AI的處理器上高效運行。TI會定期使用開源社區中的新模型以及TI設計的模型對Model Zoo進行更新,為您提供性能和精度經過優化的廣泛模型選擇。
Model Zoo囊括數百個模型,TI模型選擇工具(如圖2所示)可以幫助您在不編寫任何代碼的情況下,通過查看和比較性能統計數據(如推理吞吐量、延遲、精度和雙倍數據速率帶寬),快速比較和找到適合您AI任務的模型。

圖2:TI 模型選擇工具
第2步:訓練和優化模型
選擇模型后,下一步是在TI處理器上對其進行訓練或優化,以獲得出色的性能和精度。憑借我們的軟件架構和開發環境,您可隨時隨地訓練模型。
從TI Model Zoo中選擇模型時,借助訓練腳本可讓您在自定義數據集上為特定任務快速傳輸和訓練模型,而無需花費較長時間從頭開始訓練或使用手動工具。訓練腳本、框架擴展和量化感知培訓工具可幫助您優化自己的DNN模型。
第3步:評估模型性能
在開發邊緣AI應用之前,需要在實際硬件上評估模型性能。
TI提供靈活的軟件架構和開發環境,您可以在TensorFlow Lite、ONNX RunTime或TVM和支持Neo AI DLR的SageMaker Neo運行環境引擎三者中選擇習慣的業界標準Python或C++應用編程接口(API),只需編寫幾行代碼,即可隨時隨地訓練自己的模型,并將模型編譯和部署到TI硬件上。在這些業界通用運行環境引擎的后端,我們的TI深度學習(TIDL)模型編譯和運行環境工具可讓您針對TI的硬件編譯模型,將編譯后的圖或子圖部署到深度學習硬件加速器上,并在無需任何手動工具的情況下實現卓越的處理器推理性能。
在編譯步驟中,訓練后量化工具可以自動將浮點模型轉換為定點模型。該工具可通過配置文件實現層級混合精度量化(8位和16位),從而能夠足夠靈活地調整模型編譯,以獲得出色的性能和精度。
不同常用模型的運算方式各不相同。同樣位于GitHub上的TI邊緣AI基準工具可幫助您為TI Model Zoo中的模型無縫匹配DNN模型功能,并作為自定義模型的參考。
評估TI處理器模型性能的方式有兩種:TDA4VM入門套件評估模塊(EVM)或TI Edge AI Cloud,后者是一項免費在線服務,可支持遠程訪問TDA4VM EVM,以評估深度學習推理性能。借助針對不同任務和運行時引擎組合的數個示例腳本,五分鐘之內便可在TI硬件上編程、部署和運行加速推理,同時收集基準測試數據。
第4步:部署邊緣AI應用程序
您可以使用開源Linux?和業界通用的API來將模型部署到TI硬件上。然而,將深度學習模型部署到硬件加速器上只是難題的冰山一角。
為幫助您快速構建高效的邊緣AI應用,TI采用了GStreamer框架。借助在主機Arm?內核上運行的GStreamer插件,您可以自動將計算密集型任務的端到端信號鏈加速部署到硬件加速器和數字信號處理內核上。
圖3展示了適用于邊緣AI的Linux Processor SDK的軟件棧和組件。
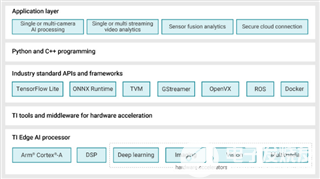
圖3:適用于邊緣AI的Linux Processor SDK組件
結語
如果您對本文中提及的工具感到陌生或有所擔憂,請放寬心,因為即使您想要開發和部署AI模型或構建AI應用,也不必成為AI專家。TI Edge AI Academy能夠幫助您在自學、課堂環境中通過測驗學習AI基礎知識,并深入了解AI系統和軟件編程。實驗室提供了構建“Hello World” AI應用的分步代碼,而帶有攝像頭捕獲和顯示功能的端到端高級應用使您能夠按照自己的節奏順利開發AI應用。
審核編輯:湯梓紅
-
嵌入式
+關注
關注
5082文章
19104瀏覽量
304817 -
ti
+關注
關注
112文章
8064瀏覽量
212365 -
人工智能
+關注
關注
1791文章
47183瀏覽量
238263 -
邊緣AI
+關注
關注
0文章
93瀏覽量
4992
發布評論請先 登錄
相關推薦
TI解讀:嵌啟未來 邊緣AI不邊緣

Arm推出GitHub平臺AI工具,簡化開發者AI應用開發部署流程
德承強固型嵌入式工控機 搶攻Edge AI應用市場
AMD分析嵌入式邊緣AI的發展
使用TI Edge AI Studio和AM62A進行基于視覺AI的缺陷檢測

恩智浦加速嵌入式AI創新應用開發
AI普及給嵌入式設計人員帶來新挑戰

嵌入式軟件開發與AI整合

AI引爆邊緣計算變革,塑造嵌入式產業新未來AI引爆邊緣計算變革,塑造嵌入式產業新未來——2024研華嵌入式

AI與開源力推嵌入式系統創新升級
AMD Versal SoC刷新邊緣AI性能,單芯片方案驅動嵌入式系統

AMD Versal SoC全新升級邊緣AI性能,單芯片方案驅動嵌入式系統






 工商網監
工商網監
評論