

來自:圓圓的算法筆記
今天給大家介紹3篇EMNLP 2022中語言模型訓練方法優化的工作,這3篇工作分別是:
針對檢索優化語言模型:優化語言模型訓練過程,使能夠生成更合適的句子表示用于檢索——RetroMAE: Pre-training Retrieval-oriented Transformers via Masked Auto-Encoder;
針對事實知識提取優化語言模型:在語言模型訓練過程中引入知識庫,提升語言模型對事實知識的抽取能力——Pre-training Language Models with Deterministic Factual Knowledge;
針對目標域效果優化語言模型:將語言模型在目標domain繼續訓練,在不遺忘原始知識的情況下學到目標doman新知識——Continual Training of Language Models for Few-Shot Learning。
后臺回復【語言模型】,可以獲取14種深度學習語言模型的梳理資料。
1 針對檢索優化語言模型
在query-document檢索任務中,核心是獲取到query和document的句子表征,然后利用向量檢索的方式完成檢索任務。BERT已經成為提取句子表示向量的主流方法。然而,BERT在預訓練階段的主要任務是MLM,缺少對句子整體表示提取的優化目標,導致句子表示提取能力不足。
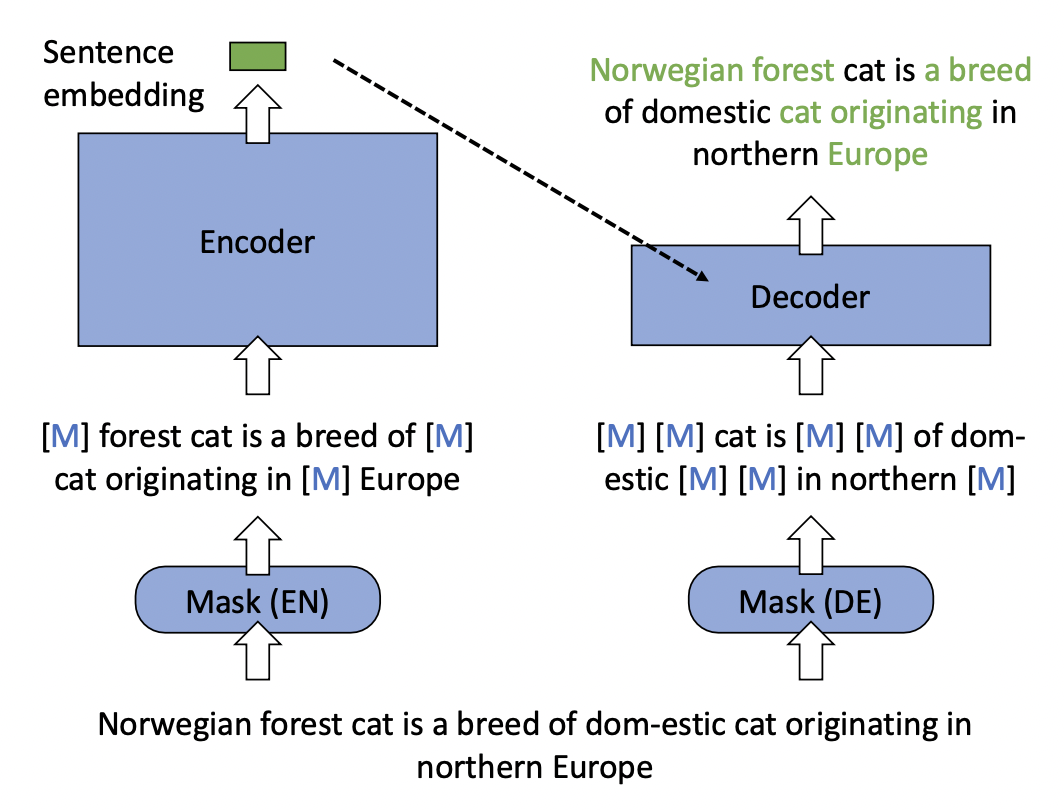
RetroMAE: Pre-Training Retrieval-oriented Language Models Via Masked Auto-Encoder這篇文章對BERT的訓練方式進行了優化,使得BERT能提取更高質量的句子表示,進而提升檢索效果。RetroMAE的整體結構如下圖所示,包括一個Encoder和一個Decoder。對于每一個樣本,Encoder的輸入隨機mask掉15%的token,和原始BERT類似,利用Encoder得到整體的句子表示。在Decoder側,輸入Encoder的句子表示,以及mask掉70%的token的樣本,讓Decoder還原整個句子。Encoder是一個比較復雜的BERT模型,Decoder則使用一個比較簡單的單層Transformer模型。
本文的模型設計思路是,Decoder提供的信息盡可能少、模型的復雜度盡可能低,這樣可以迫使Encoder生成的句子表示包含更完整的句子信息,保障了Encoder生成的句子embedding的質量。相比對比學習學習句子表示的方法,RetroMAE的優勢是效果不依賴于數據增強方法和正負樣本構造方法的選擇。
2 針對事實知識提取優化語言模型
隨著prompt的興起,預訓練語言模型經常被用于進行知識抽取。構造一個prompt模板,以完形填空的形式讓模型預測空缺位置的token,實現知識抽取。然而,預訓練語言模型的抽取結果有時會很大程度上受到prompt選擇的影響,如下表所示,魯棒性較差。一個核心原因是,在訓練語言模型的過程中,有些被mask掉的部分并不一定只有唯一一個正確答案。當被mask部分存在多個正確答案,而模型在訓練過程中被要求只預測一個正確答案時,就會導致其他本來正確的答案被強行設置成為負樣本,進而影響了模型效果。

Pre-training Language Models with Deterministic Factual Knowledge針對這個問題,提出了在構造預訓練樣本時,引入知識庫對數據進行過濾。核心是在KG中查找知識信息,看樣本中被mask掉的實體是否這段文本的描述中唯一確定的正確答案。如果是,那么這個樣本不會給語言模型帶來歧義,正常參與訓練;否則就是一個多答案樣本,從訓練數據中去除掉。通過這種數據過濾的方式,讓模型在訓練階段見到的預測任務都是只有一個確定答案的,解決了多答案mask token預測的影響。
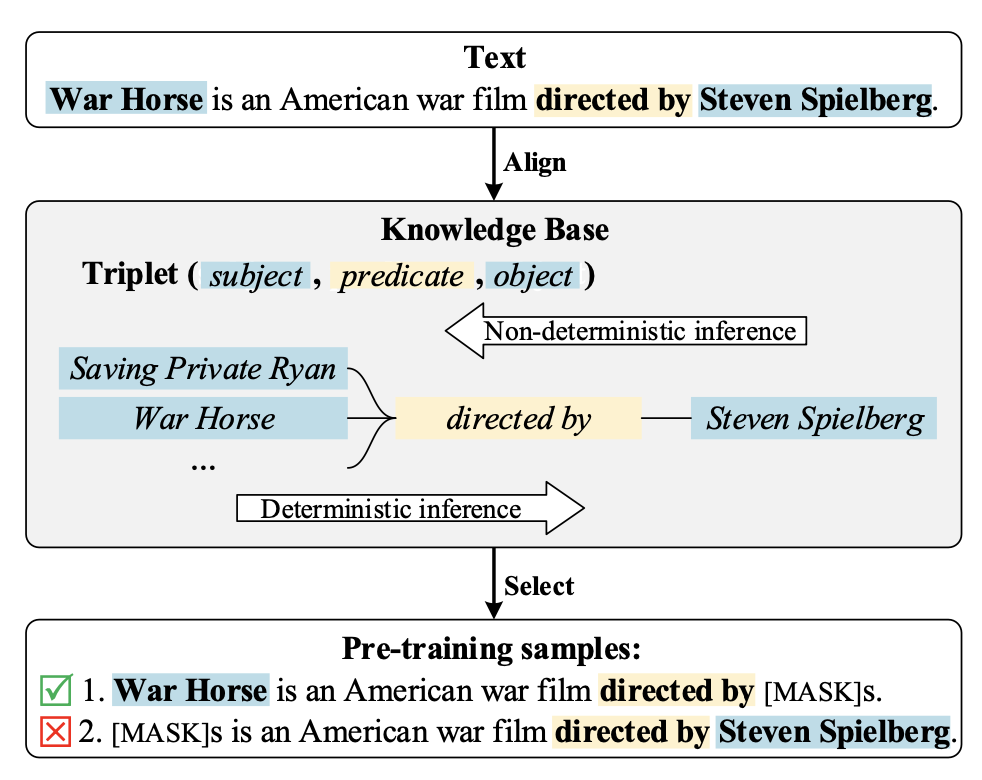
為了進一步提升模型能力,文中提出了Clue Contrastive Learning和Clue Classification兩個任務。Clue Contrastive Learning的目標是讓模型具備一種能力:當上下文指向的答案是確定性的時候,就預測一個更有信心一些。通過構造確定性樣本和非確定性樣本,以這對樣本的對比關系進行學習。Clue Classification讓語言模型知道上下文信息中存在什么樣的線索。通過保留決定性線索、刪除決定性線索、刪除其他非決定性線性構造三種樣本用于分類。
3 針對目標域效果優化語言模型
在使用預訓練語言模型解決下游NLP任務時,如果目標任務的有label數據較少,一種能提升效果的方法是先將語言模型在目標任務domain上無監督語料上繼續訓練,讓語言模型適應目標任務的文本分布。在面對下游各類、持續增加的任務時,我們需要不斷的使用新任務domain的語言訓練語言模型。這樣做的風險可能會破壞原來語言模型學到的知識,導致信息遺忘等問題,帶來老任務上效果的下降。
Continual Training of Language Models for Few-Shot Learning提出了一種語言模型連續學習的方法解決上述問題。核心思路是借鑒了Adapter,在語言模型中插入多個CL組件(全連接層),模型在目標domain語言上繼續學習的過程中,只更新這些CL組件,原始的語言模型保持參數不變。在具體任務上finetune時,語言模型和CL組件一起更新。
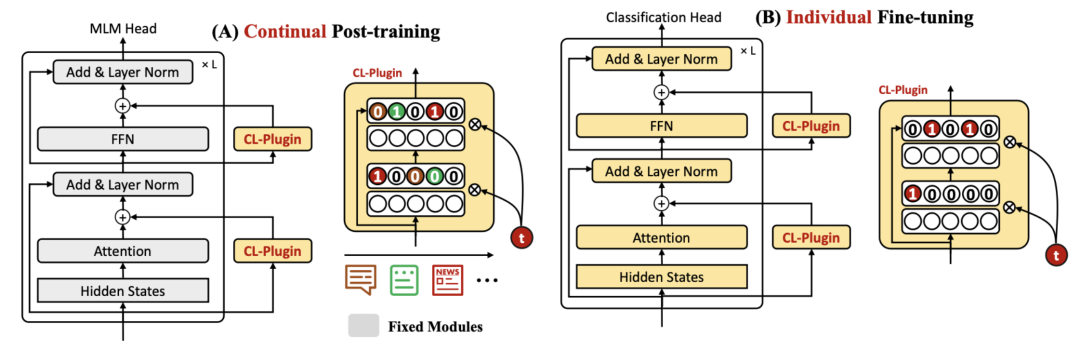
這里面的一個關鍵模塊是使用task id生成CL組件中的mask,每個任務的mask代表了哪些神經元對于當前任務最重要,這些神經元會在后續新任務的訓練中被mask掉,不進行梯度更新,防止新任務對老任務已經學到的信息造成影響。每次訓練一個新任務時,會把老任務的mask匯總起來控制住不更新的神經元,并且對新的task也學習一套mask。
4 總結
本文主要介紹了3篇EMNLP 2022中和語言模型優化相關的工作,涉及檢索、知識提取、持續學習等方面。語言模型在很多場景有各種各樣的應用,學術界對于語言模型的優化方向,逐漸從原來的大規模預訓練方式、模型結構優化,轉向到細領域的針對性優化。
-
算法
+關注
關注
23文章
4677瀏覽量
94283 -
nlp
+關注
關注
1文章
490瀏覽量
22405
原文標題:介紹幾篇EMNLP'22的語言模型訓練方法優化工作
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】揭開大語言模型的面紗
【大語言模型:原理與工程實踐】大語言模型的預訓練
Pytorch模型訓練實用PDF教程【中文】
基于粒子群優化的條件概率神經網絡的訓練方法
微軟在ICML 2019上提出了一個全新的通用預訓練方法MASS

新的預訓練方法——MASS!MASS預訓練幾大優勢!

關于語言模型和對抗訓練的工作


Multilingual多語言預訓練語言模型的套路

混合專家模型 (MoE)核心組件和訓練方法介紹





 工商網監
工商網監

評論