") 強(qiáng)勢(shì)的點(diǎn)云處理神經(jīng)網(wǎng)絡(luò)PointNe介紹
強(qiáng)勢(shì)的點(diǎn)云處理神經(jīng)網(wǎng)絡(luò)PointNe介紹
前言
PointNet是由斯坦福大學(xué)的Charles R. Qi等人在《PointNet:Deep Learning on Point Sets for 3D Classification and Segmentation》一文中提出的模型,它可以直接對(duì)點(diǎn)云進(jìn)行處理的,對(duì)輸入點(diǎn)云中的每一個(gè)點(diǎn),學(xué)習(xí)其對(duì)應(yīng)的空間編碼,之后再利用所有點(diǎn)的特征得到一個(gè)全局的點(diǎn)云特征。Pointnet提取的全局特征能夠很好地完成分類(lèi)任務(wù),但局部特征提取能力較差,這使得它很難對(duì)復(fù)雜場(chǎng)景進(jìn)行分析。
PointNet++是Charles R. Qi團(tuán)隊(duì)在PointNet論文基礎(chǔ)上改進(jìn)版本,其核心是提出了多層次特征提取結(jié)構(gòu),有效提取局部特征提取,和全局特征。
F-PointNet將PointNet的應(yīng)用拓展到了3D目標(biāo)檢測(cè)上,可以使用PointNet或PointNet++進(jìn)行點(diǎn)云處理。它在進(jìn)行點(diǎn)云處理之前,先使用圖像信息得到一些先驗(yàn)搜索范圍,這樣既能提高效率,又能增加準(zhǔn)確率。
PointNet
1.1 PointNet思路流程
1)輸入為一幀的全部點(diǎn)云數(shù)據(jù)的集合,表示為一個(gè)nx3的2d tensor,其中n代表點(diǎn)云數(shù)量,3對(duì)應(yīng)xyz坐標(biāo)。
2)輸入數(shù)據(jù)先通過(guò)和一個(gè)T-Net學(xué)習(xí)到的轉(zhuǎn)換矩陣相乘來(lái)對(duì)齊,保證了模型的對(duì)特定空間轉(zhuǎn)換的不變性。
3)通過(guò)多次mlp對(duì)各點(diǎn)云數(shù)據(jù)進(jìn)行特征提取后,再用一個(gè)T-Net對(duì)特征進(jìn)行對(duì)齊。
4)在特征的各個(gè)維度上執(zhí)行maxpooling操作來(lái)得到最終的全局特征。
5)對(duì)分類(lèi)任務(wù),將全局特征通過(guò)mlp來(lái)預(yù)測(cè)最后的分類(lèi)分?jǐn)?shù);對(duì)分割任務(wù),將全局特征和之前學(xué)習(xí)到的各點(diǎn)云的局部特征進(jìn)行串聯(lián),再通過(guò)mlp得到每個(gè)數(shù)據(jù)點(diǎn)的分類(lèi)結(jié)果。
1.2 PointNet網(wǎng)絡(luò)結(jié)構(gòu)
它提取的“全局特征”能夠很好地完成分類(lèi)任務(wù)。下面看一下PointNet的框架結(jié)構(gòu):
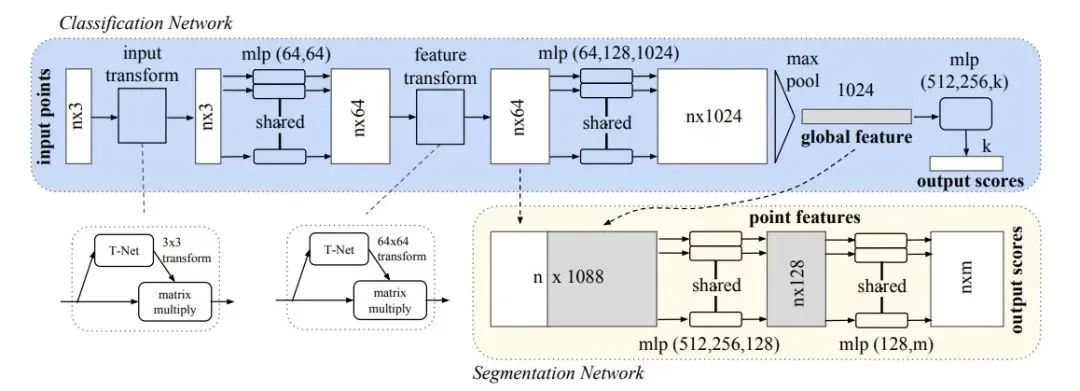
下面解釋一個(gè)網(wǎng)絡(luò)中各個(gè)部件的作用。
1)transform:第一次,T-Net 3x3,對(duì)輸入點(diǎn)云進(jìn)行對(duì)齊:位姿改變,使改變后的位姿更適合分類(lèi)/分割;第二次,T-Net 64x64,對(duì)64維特征進(jìn)行對(duì)齊。2)mlp:多層感知機(jī),用于提取點(diǎn)云的特征,這里使用共享權(quán)重的卷積。
3)max pooling:匯總所有點(diǎn)云的信息,進(jìn)行最大池化,得到點(diǎn)云的全局信息。
4)分割部分:局部和全局信息組合結(jié)構(gòu)(concate,語(yǔ)義分割)。
5)分類(lèi)loss:交叉熵:分割loss:分類(lèi)+分割+L2(transform,原圖的正交變換)。
1.3T-Net網(wǎng)絡(luò)結(jié)構(gòu)
將輸入的點(diǎn)云數(shù)據(jù)作為nx3x1單通道圖像,接三次卷積和一次池化后,再reshape為1024個(gè)節(jié)點(diǎn),然后接兩層全連接,網(wǎng)絡(luò)除最后一層外都使用了ReLU激活函數(shù)和批標(biāo)準(zhǔn)化。
1.4 模型效果
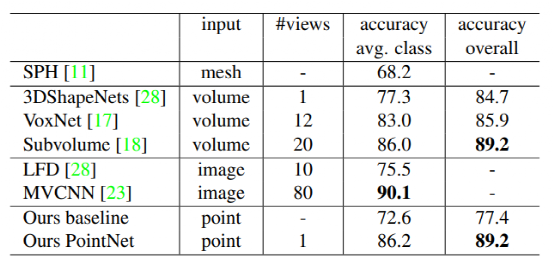
ModelNet40 上的分類(lèi)結(jié)果:
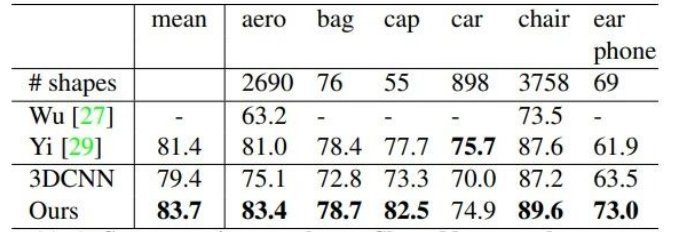
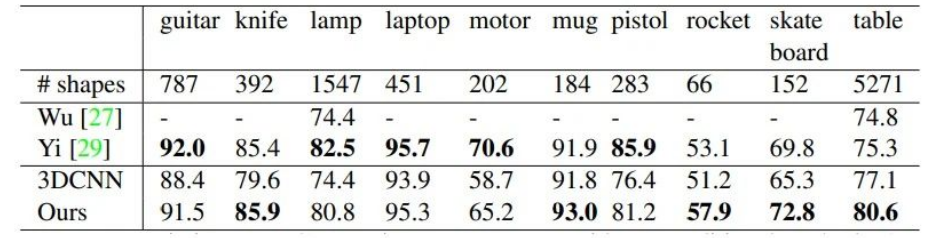
ShapeNet部分?jǐn)?shù)據(jù)集上的分割結(jié)果:
不足:缺乏在不同尺度上提取局部信息的能力。
PointNet++
Pointnet提取的全局特征能夠很好地完成分類(lèi)任務(wù),由于模型基本上都是單點(diǎn)采樣,代碼底層用的是2Dconv,只有maxpooling整合了整體特征,所以局部特征提取能力較差,這使得它很難對(duì)復(fù)雜場(chǎng)景進(jìn)行分析。
PointNet++的核心是提出了多層次特征提取結(jié)構(gòu),有效提取局部特征提取,和全局特征。
2.1 思路流程
先在輸入點(diǎn)集中選擇一些點(diǎn)作為中心點(diǎn),然后圍繞每個(gè)中心點(diǎn)選擇周?chē)狞c(diǎn)組成一個(gè)區(qū)域,之后每個(gè)區(qū)域作為PointNet的一個(gè)輸入樣本,得到一組特征,這個(gè)特征就是這個(gè)區(qū)域的特征。
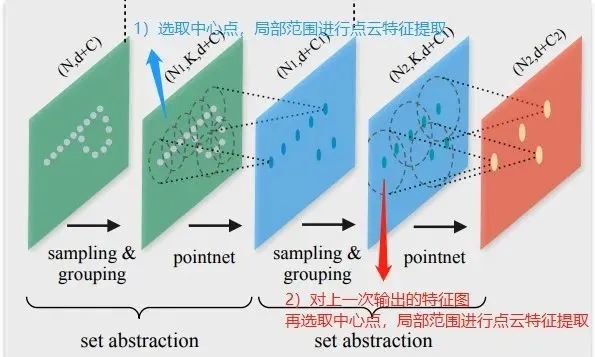
之后中心點(diǎn)不變,擴(kuò)大區(qū)域,把上一步得到的那些特征作為輸入送入PointNet,以此類(lèi)推,這個(gè)過(guò)程就是不斷的提取局部特征,然后擴(kuò)大局部范圍,最后得到一組全局的特征,然后進(jìn)行分類(lèi)。
2.2 整體網(wǎng)絡(luò)結(jié)構(gòu)
PointNet++ 在不同尺度提取局部特征,通過(guò)多層網(wǎng)絡(luò)結(jié)構(gòu)得到深層特征。PointNet++按照任務(wù)也分為 classification (分類(lèi)網(wǎng)絡(luò))和 segmentation (分割網(wǎng)絡(luò))兩種,輸入和輸出分別與PointNet中的兩個(gè)網(wǎng)絡(luò)一致。
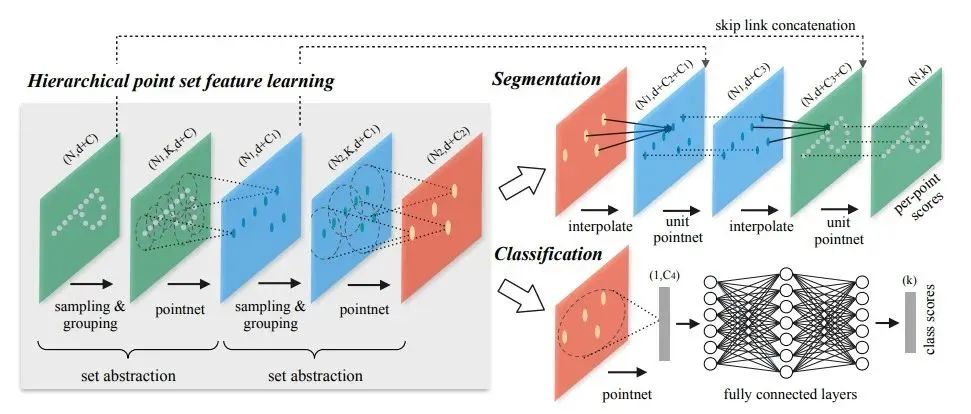
PointNet++會(huì)先對(duì)點(diǎn)云進(jìn)行采樣(sampling)和劃分區(qū)域(grouping),在各個(gè)小區(qū)域內(nèi)用基礎(chǔ)的PointNet網(wǎng)絡(luò)進(jìn)行特征提取(MSG、MRG),不斷迭代。
對(duì)于分類(lèi)問(wèn)題,直接用PointNet提取全局特征,采用全連接得到每個(gè)類(lèi)別評(píng)分。對(duì)于分割問(wèn)題,將高維的點(diǎn)反距離插值得到與低維相同的點(diǎn)數(shù),再特征融合,再使用PointNet提取特征 。
比較PointNet++兩個(gè)任務(wù)網(wǎng)絡(luò)的區(qū)別:
在得到最高層的 feature 之后,分類(lèi)網(wǎng)絡(luò)使用了一個(gè)小型的 PointNet + FCN 網(wǎng)絡(luò)提取得到最后的分類(lèi) score;
分割網(wǎng)絡(luò)通過(guò)“跳躍連接” 操作不斷與底層 “低層特征圖”信息融合,最終得到逐點(diǎn)分分類(lèi)語(yǔ)義分割結(jié)果。(“跳躍連接”對(duì)應(yīng)上圖的 skip link connection;低層特征圖 具有分辨率較大,保留較豐富的信息,雖然整體語(yǔ)義信息較弱。)
2.3網(wǎng)絡(luò)結(jié)構(gòu)組件
1)采樣層(sampling)
激光雷達(dá)單幀的數(shù)據(jù)點(diǎn)可以多達(dá)100k個(gè),如果對(duì)每一個(gè)點(diǎn)都提取局部特征,計(jì)算量是非常巨大的。因此,作者提出了先對(duì)數(shù)據(jù)點(diǎn)進(jìn)行采樣。作者使用的采樣算法是最遠(yuǎn)點(diǎn)采樣(farthest point sampling, FPS),相對(duì)于隨機(jī)采樣,這種采樣算法能夠更好地覆蓋整個(gè)采樣空間。
2)組合層(grouping)
為了提取一個(gè)點(diǎn)的局部特征,首先需要定義這個(gè)點(diǎn)的“局部”是什么。一個(gè)圖片像素點(diǎn)的局部是其周?chē)欢D距離下的像素點(diǎn),通常由卷積層的卷積核大小確定。同理,點(diǎn)云數(shù)據(jù)中的一個(gè)點(diǎn)的局部由其周?chē)o定半徑劃出的球形空間內(nèi)的其他點(diǎn)構(gòu)成。組合層的作用就是找出通過(guò)采樣層后的每一個(gè)點(diǎn)的所有構(gòu)成其局部的點(diǎn),以方便后續(xù)對(duì)每個(gè)局部提取特征。
3)特征提取層(feature learning)
因?yàn)镻ointNet給出了一個(gè)基于點(diǎn)云數(shù)據(jù)的特征提取網(wǎng)絡(luò),因此可以用PointNet對(duì)組合層給出的各個(gè)局部進(jìn)行特征提取來(lái)得到局部特征。值得注意的是,雖然組合層給出的各個(gè)局部可能由不同數(shù)量的點(diǎn)構(gòu)成,但是通過(guò)PointNet后都能得到維度一致的特征(由上述K值決定)。
2.4 不均勻點(diǎn)云組合grouping方法
不同于圖片數(shù)據(jù)分布在規(guī)則的像素網(wǎng)格上且有均勻的數(shù)據(jù)密度,點(diǎn)云數(shù)據(jù)在空間中的分布是不規(guī)則且不均勻的。當(dāng)點(diǎn)云不均勻時(shí),每個(gè)子區(qū)域中如果在分區(qū)的時(shí)候使用相同的球半徑,會(huì)導(dǎo)致部分稀疏區(qū)域采樣點(diǎn)過(guò)小。作者提出多尺度成組 (MSG)和多分辨率成組 (MRG)兩種解決辦法。
1)多尺度組合MSG:對(duì)于選取的一個(gè)中心點(diǎn)設(shè)置多個(gè)半徑進(jìn)行成組,并將經(jīng)過(guò)PointNet對(duì)每個(gè)區(qū)域抽取后的特征進(jìn)行拼接(concat)來(lái)當(dāng)做該中心點(diǎn)的特征,這種做法會(huì)產(chǎn)生很多特征重疊,結(jié)果會(huì)可以保留和突出(邊際疊加)更多局部關(guān)鍵的特征,但是這種方式不同范圍內(nèi)計(jì)算的權(quán)值卻很難共享,計(jì)算量會(huì)變大很多。
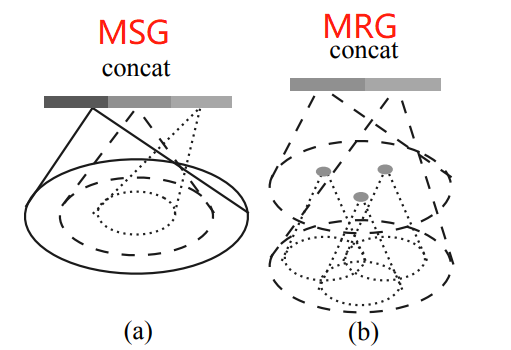
2)多分辨率組合MRG:MRG避免了大量的計(jì)算,但仍然保留了根據(jù)點(diǎn)的分布特性自適應(yīng)地聚合信息的能力。對(duì)不同特征層上(分辨率)提取的特征再進(jìn)行concat,以b圖為例,最后的concat包含左右兩個(gè)部分特征,分別來(lái)自底層和高層的特征抽取,對(duì)于low level點(diǎn)云成組后經(jīng)過(guò)一個(gè)pointnet和high level的進(jìn)行concat,思想是特征的抽取中的跳層連接。
當(dāng)局部點(diǎn)云區(qū)域較稀疏時(shí),上層提取到的特征可靠性可能比底層更差,因此考慮對(duì)底層特征提升權(quán)重。當(dāng)然,點(diǎn)云密度較高時(shí)能夠提取到的特征也會(huì)更多。這種方法優(yōu)化了直接在稀疏點(diǎn)云上進(jìn)行特征抽取產(chǎn)生的問(wèn)題,且相對(duì)于MSG的效率也較高。
選擇哪一種?
當(dāng)局部區(qū)域的密度低時(shí),第一矢量可能不如第二矢量可靠,因?yàn)橛?jì)算第一矢量的子區(qū)域包含更稀疏的點(diǎn)并且更多地受到采樣不足的影響。在這種情況下,第二個(gè)矢量應(yīng)該加權(quán)更高。另一方面,當(dāng)局部區(qū)域的密度高時(shí),第一矢量提供更精細(xì)細(xì)節(jié)的信息,因?yàn)樗哂幸暂^低水平遞歸地表達(dá)較高分辨率檢查的能力。
2.5 模型效果
分類(lèi)對(duì)比:

分割對(duì)比:
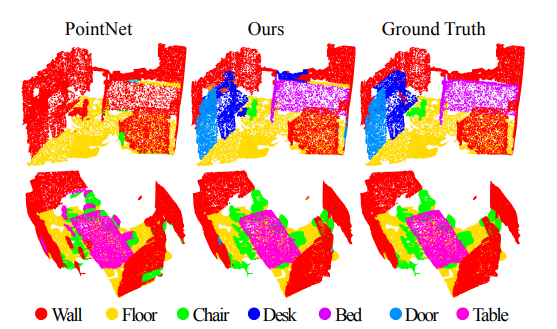
小結(jié)復(fù)雜場(chǎng)景點(diǎn)云一般采用PointNet++進(jìn)行處理,而簡(jiǎn)單場(chǎng)景點(diǎn)云則采用PointNet。如果只從點(diǎn)云分類(lèi)和分割兩個(gè)任務(wù)角度分析,分類(lèi)任務(wù)只需要max pooling操作之后的特征信息就可完成,而分割任務(wù)則需要更加詳細(xì)的local context信息。
F-PointNet 也是直接處理點(diǎn)云數(shù)據(jù)的方案,但這種方式面臨著挑戰(zhàn),比如:如何有效地在三維空間中定位目標(biāo)的可能位置,即如何產(chǎn)生 3D 候選框,假如全局搜索將會(huì)耗費(fèi)大量算力與時(shí)間。
F-PointNet是在進(jìn)行點(diǎn)云處理之前,先使用圖像信息得到一些先驗(yàn)搜索范圍,這樣既能提高效率,又能增加準(zhǔn)確率。
3.1 基本思路
首先使用在 RGB 圖像上運(yùn)行的 2D 檢測(cè)器,其中每個(gè)2D邊界框定義一個(gè)3D錐體區(qū)域。然后基于這些視錐區(qū)域中的 3D 點(diǎn)云,我們使用 PointNet/PointNet++ 網(wǎng)絡(luò)實(shí)現(xiàn)了 3D實(shí)例分割和非模態(tài) 3D 邊界框估計(jì)。總結(jié)一下思路,如下:
基于圖像2D目標(biāo)檢測(cè)。
基于圖像生成錐體區(qū)域。
在錐體內(nèi),使用 PointNet/PointNet++ 網(wǎng)絡(luò)進(jìn)行點(diǎn)云實(shí)例分割。
它是在進(jìn)行點(diǎn)云處理之前,先使用圖像信息得到一些先驗(yàn)搜索范圍,這樣既能提高效率,又能增加準(zhǔn)確率。先看看下面這張圖:
在這張圖里,左上角的意思是先把圖像和點(diǎn)云信息標(biāo)定好(這個(gè)屬于傳感器的外參標(biāo)定,在感知之前進(jìn)行;獲取兩個(gè)傳感器之間旋轉(zhuǎn)矩陣和平移向量,就可以得到相互的位置關(guān)系)。
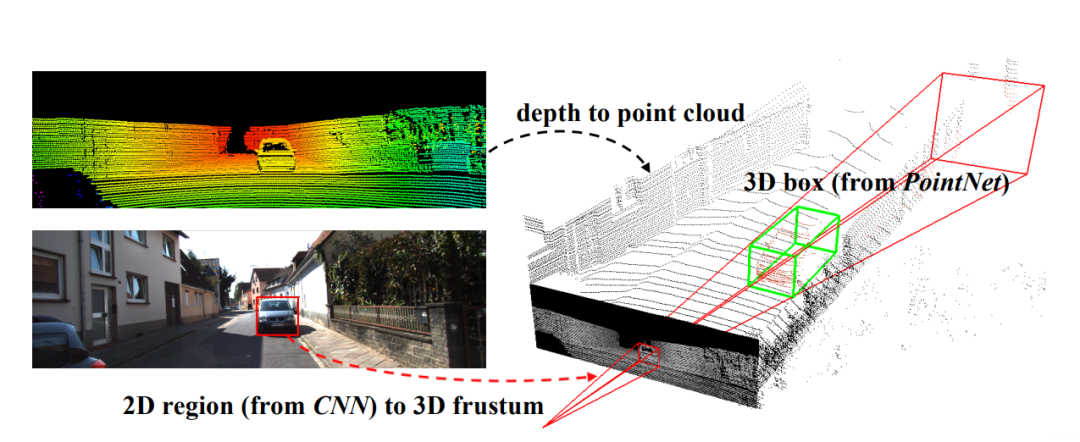
左下角是用目標(biāo)檢測(cè)算法檢測(cè)出物體的邊界框(BoundingBox),有了邊界框之后,以相機(jī)為原點(diǎn),沿邊界框方向延伸過(guò)去就會(huì)形成一個(gè)錐體(上圖的右半部分),該論文題目里frustum這個(gè)詞就是錐體的意思。然后用點(diǎn)云對(duì)該物體進(jìn)行識(shí)別的時(shí)候,只需要在這個(gè)錐體內(nèi)識(shí)別就行了,大大減小了搜索范圍。
3.2 模型框架
模型結(jié)構(gòu)如下:(可以點(diǎn)擊圖片放大查看)
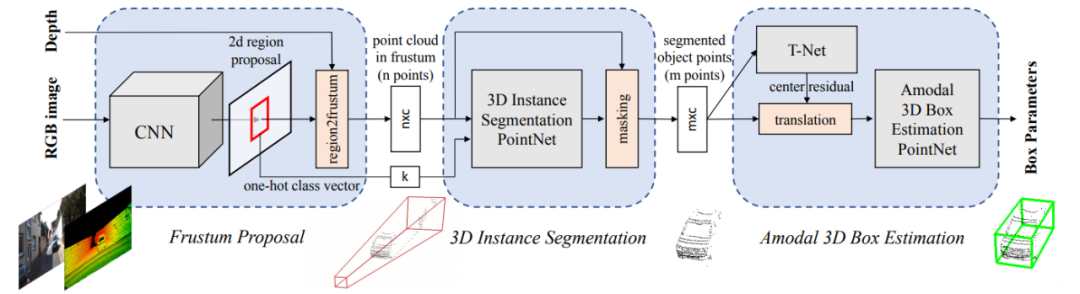
網(wǎng)絡(luò)共分為三部分,第一部分是使用圖像進(jìn)行目標(biāo)檢測(cè)并生成錐體區(qū)域,第二部分是在錐體內(nèi)的點(diǎn)云實(shí)例分割,第三部分是點(diǎn)云物體邊界框的回歸。
3.3基于圖像生成錐體區(qū)域
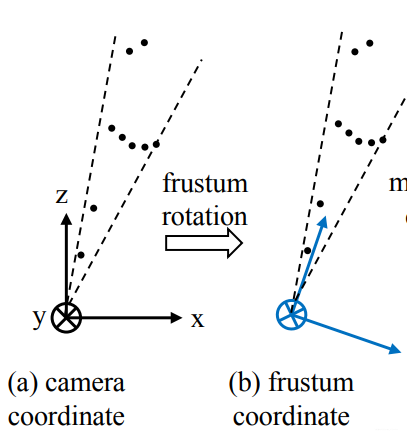
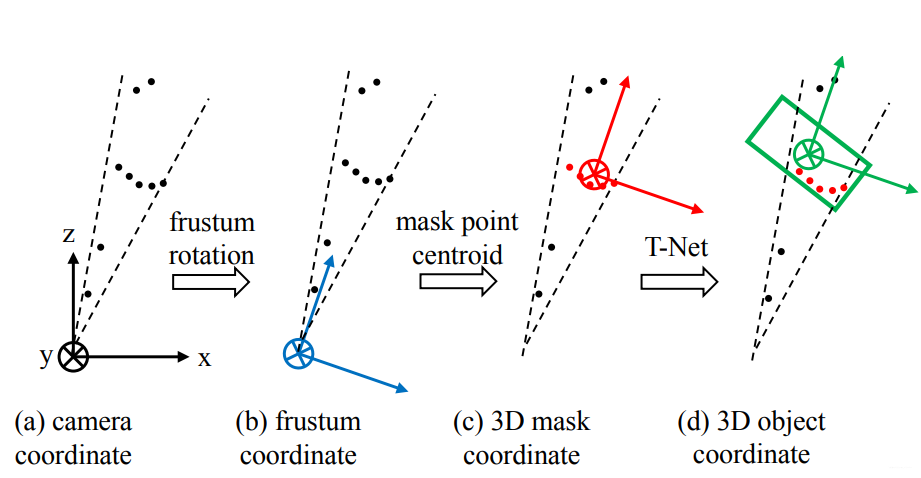
由于檢測(cè)到的目標(biāo)不一定在圖像的正中心,所以生成的錐體的軸心就不一定和相機(jī)的坐標(biāo)軸重合,如下圖中(a)所示。為了使網(wǎng)絡(luò)具有更好的旋轉(zhuǎn)不變性,我們需要做一次旋轉(zhuǎn),使相機(jī)的Z軸和錐體的軸心重合。如下圖中(b)所示。
3.4 在錐體內(nèi)進(jìn)行點(diǎn)云實(shí)例分割
實(shí)例分割使用PointNet。一個(gè)錐體內(nèi)只提取一個(gè)物體,因?yàn)檫@個(gè)錐體是圖像中的邊界框產(chǎn)生的,一個(gè)邊界框內(nèi)也只有一個(gè)完整物體。
在生成錐體的時(shí)候提到了旋轉(zhuǎn)不變性,此處完成分割這一步之后,還需要考慮平移不變性,因?yàn)辄c(diǎn)云分割之后,分割的物體的原點(diǎn)和相機(jī)的原點(diǎn)必不重合,而我們處理的對(duì)象是點(diǎn)云,所以應(yīng)該把原點(diǎn)平移到物體中去,如下圖中(c)所示。
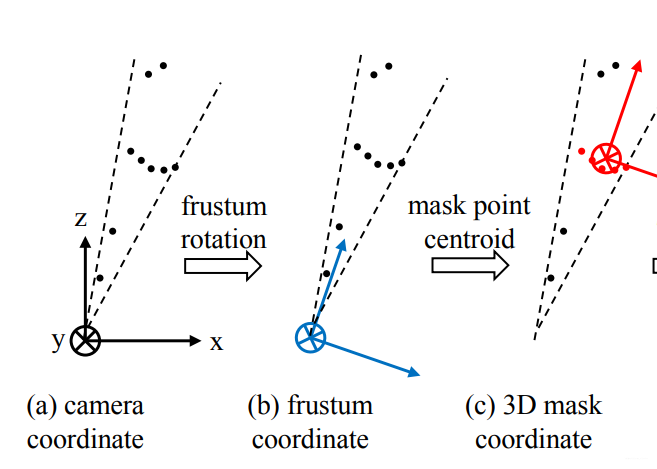
3.5 生成精確邊界框
生成精確邊界框的網(wǎng)絡(luò)結(jié)構(gòu):
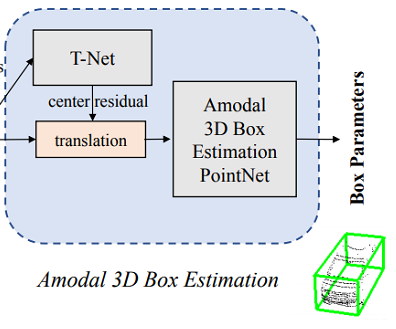
從這個(gè)結(jié)構(gòu)里可以看出,在生成邊界框之前,需要經(jīng)過(guò)一個(gè)T-Net,這個(gè)東西的作用是生成一個(gè)平移量,之所以要做這一步,是因?yàn)樵谏弦徊降玫降奈矬w中心并不完全準(zhǔn)確,所以為了更精確地估計(jì)邊界框,在此處對(duì)物體的質(zhì)心做進(jìn)一步的調(diào)整,如下圖中(d)所示。
下面就是邊界框回歸了,對(duì)一個(gè)邊界框來(lái)講,一共有七個(gè)參數(shù),包括:
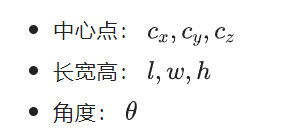
最后總的殘差就是以上目標(biāo)檢測(cè)、T-Net和邊界框殘差之和,可以據(jù)此構(gòu)建損失函數(shù)。
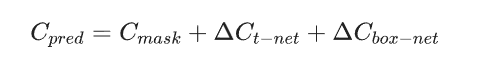
3.6 PointNet關(guān)鍵點(diǎn)
(1) F-PointNet使用2D RGB圖像
F-PointNet使用2D RGB圖像原因是:1.當(dāng)時(shí)基于純3D點(diǎn)云數(shù)據(jù)的3D目標(biāo)檢測(cè)對(duì)小目標(biāo)檢測(cè)效果不佳。所以F-PointNet先基于2D RGB做2D的目標(biāo)檢測(cè)來(lái)定位目標(biāo),再基于2d目標(biāo)檢測(cè)結(jié)果用其對(duì)應(yīng)的點(diǎn)云數(shù)據(jù)視錐進(jìn)行bbox回歸的方法來(lái)實(shí)現(xiàn)3D目標(biāo)檢測(cè)。2.使用純3D的點(diǎn)云數(shù)據(jù),計(jì)算量也會(huì)特別大,效率也是這個(gè)方法的優(yōu)點(diǎn)之一。使用成熟的2D CNN目標(biāo)檢測(cè)器(Mask RCNN)生成2D檢測(cè)框,并輸出one-hot 分類(lèi)向量(即基于2D RGB圖像的分類(lèi))。
(2)錐體框生成
2D檢測(cè)框結(jié)合深度信息,找到最近和最遠(yuǎn)的包含檢測(cè)框的平面來(lái)定義3D視錐區(qū)域frustum proposal。然后在該frustum proposal里收集所有的3D點(diǎn)來(lái)組成視錐點(diǎn)云(frustum point cloud)。
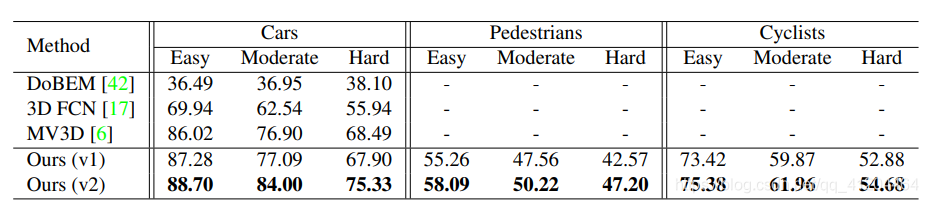
3.7 實(shí)驗(yàn)結(jié)果
與其他模型對(duì)比:
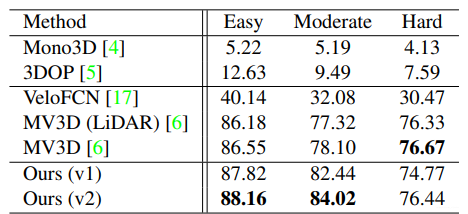
模型效果:

3.8 優(yōu)點(diǎn)
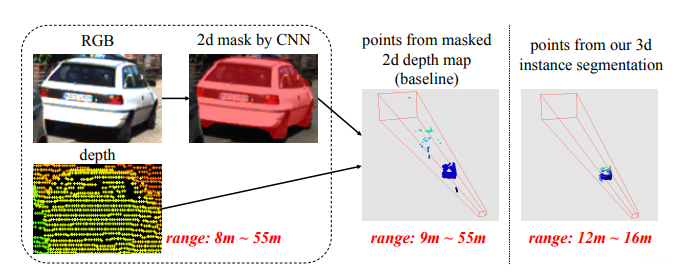
(1)舍棄了global fusion,提高了檢測(cè)效率;并且通過(guò)2D detector和3D Instance Segmentation PointNet對(duì)3D proposal實(shí)現(xiàn)了逐維(2D-3D)的精準(zhǔn)定位,大大縮短了對(duì)點(diǎn)云的搜索時(shí)間。下圖是通過(guò)3d instance segmentation將搜索范圍從9m~55m縮減到12m~16m。
(2)相比于在BEV(Bird's Eye view)中進(jìn)行3D detection,F(xiàn)-PointNet直接處理raw point cloud,沒(méi)有任何維度的信息損失,使用PointNet能夠?qū)W習(xí)更全面的空間幾何信息,特別是在小物體的檢測(cè)上有很好的表現(xiàn)。下圖是來(lái)自Hao Su 2018年初的課程,現(xiàn)在的KITTI榜有細(xì)微的變動(dòng)。
(3)利用成熟的2D detector對(duì)proposal進(jìn)行分類(lèi)(one-hot class vector,打標(biāo)簽),起到了一定的指導(dǎo)作用,能夠大大降低PointNet對(duì)三維空間物體的學(xué)習(xí)難度。
3.9 模型代碼
開(kāi)源代碼:GitHub - charlesq34/frustum-pointnets: Frustum PointNets for 3D Object Detection from RGB-D Data
作者代碼的運(yùn)行環(huán)境:
系統(tǒng):Ubuntu 14.04 或 Ubuntu 16.04
深度框架:TensorFlow1.2(GPU 版本)或 TensorFlow1.4(GPU 版本)
其他依賴庫(kù):cv2、mayavi等。
審核編輯:劉清
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4778瀏覽量
101009 -
RGB
+關(guān)注
關(guān)注
4文章
801瀏覽量
58623 -
FPS
+關(guān)注
關(guān)注
0文章
35瀏覽量
12023
原文標(biāo)題:一文搞懂PointNet全家桶——強(qiáng)勢(shì)的點(diǎn)云處理神經(jīng)網(wǎng)絡(luò)
文章出處:【微信號(hào):3D視覺(jué)工坊,微信公眾號(hào):3D視覺(jué)工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
人工神經(jīng)網(wǎng)絡(luò)的原理和多種神經(jīng)網(wǎng)絡(luò)架構(gòu)方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論