 一張RTX 2080Ti搞定大模型訓練!算力節省136倍!
一張RTX 2080Ti搞定大模型訓練!算力節省136倍!
任何 transformer 變體、任何數據集都通用。
在一塊消費級 GPU 上只用一天時間訓練,可以得到什么樣的 BERT 模型?
最近一段時間,語言模型再次帶火了 AI 領域。預訓練語言模型的無監督訓練屬性使其可以在海量樣本基礎上進行訓練,并獲得大量語義語法知識,不論分類還是問答,似乎沒有 AI 解決不了的問題。
然而,大模型既帶來了技術突破,也對算力提出了無窮無盡的需求。
最近,來自馬里蘭大學的 Jonas Geiping、Tom Goldstein 討論了所有關于擴大計算規模的研究,深入探討了縮小計算規模的改進方向。他們的研究引發了機器學習社區的關注。
在新研究中,作者對于單塊消費級 GPU(RTX 2080Ti)能訓練出什么樣的語言模型進行了討論,并獲得了令人興奮的結果。讓我們看看它是如何實現的:
模型規模的擴展
在自然語言處理(NLP)領域,基于 Transformer 架構的預訓練模型已經成為主流,并帶來諸多突破性進展。很大程度上,這些模型性能強大的原因是它們的規模很大。隨著模型參數量和數據量的增長,模型的性能會不斷提高。因此,NLP 領域內掀起了一場增大模型規模的競賽。
然而,很少有研究人員或從業者認為他們有能力訓練大型語言模型(LLM),通常只有行業內的科技巨頭擁有訓練 LLM 的資源。
為了扭轉這一趨勢,來自馬里蘭大學的研究者進行了一番探索。
論文《Cramming: Training a Language Model on a Single GPU in One Day》:

論文鏈接:https://arxiv.org/abs/2212.14034
這個問題對于大多數研究人員和從業者來說具有重要意義,因為這將成為模型訓練成本的參考,并有望打破 LLM 訓練成本超高的瓶頸。該研究的論文迅速在推特上引發關注和討論。

IBM 的 NLP 研究專家 Leshem Choshen 在推特上評價道:「這篇論文總結了所有你能想到的大模型訓練 trick。」
馬里蘭大學的研究者認為:如果按比例縮小的模型預訓練是大型預訓練的可行模擬,那么這將開啟一系列目前難以實現的大規模模型的進一步學術研究。
此外,該研究嘗試對過去幾年 NLP 領域的整體進展進行基準測試,而不僅僅局限于模型規模的影響。
該研究創建了一項稱為「Cramming」的挑戰 —— 在測試前一天學習整個語言模型。研究者首先分析了訓練 pipeline 的方方面面,以了解哪些修改可以實際提高小規模模擬模型的性能。并且,該研究表明,即使在這種受限環境中,模型性能也嚴格遵循在大型計算環境中觀察到的擴展定律。
雖然較小的模型架構可以加快梯度計算,但隨著時間的推移,模型改進的總體速度幾乎保持不變。該研究嘗試利用擴展定律在不影響模型大小的情況下通過提高梯度計算的有效率獲得性能提升。最后,該研究成功訓練出性能可觀的模型 —— 在 GLUE 任務上接近甚至超過 BERT—— 而且訓練成本很低。
資源有限
為了模擬普通從業者和研究人員的資源環境,該研究首先構建了一個資源受限的研究環境:
一個任意大小的基于 transformer 的語言模型,完全從頭開始使用掩碼語言建模(masked-language modeling)進行訓練;
pipeline 中不能包含現有的預訓練模型;
任何原始文本(不包括下游數據)都可以包含在訓練中,這意味著可以通過明智地選擇如何以及何時對數據進行采樣來實現加速,前提是采樣機制不需要預訓練模型;
原始數據的下載和預處理不計入總預算,這里的預處理包括基于 CPU 的 tokenizer 構造、tokenization 和 filtering,但不包括表征學習;
訓練僅在單塊 GPU 上進行 24 小時;
下游性能在 GLUE 上進行評估,GLUE 上的下游微調僅限于僅使用下游任務的訓練數據進行簡單訓練(5 個 epoch 或者更少),并且需要使用為所有 GLUE 任務設置的全局超參數,下游微調不計算在總預算中。
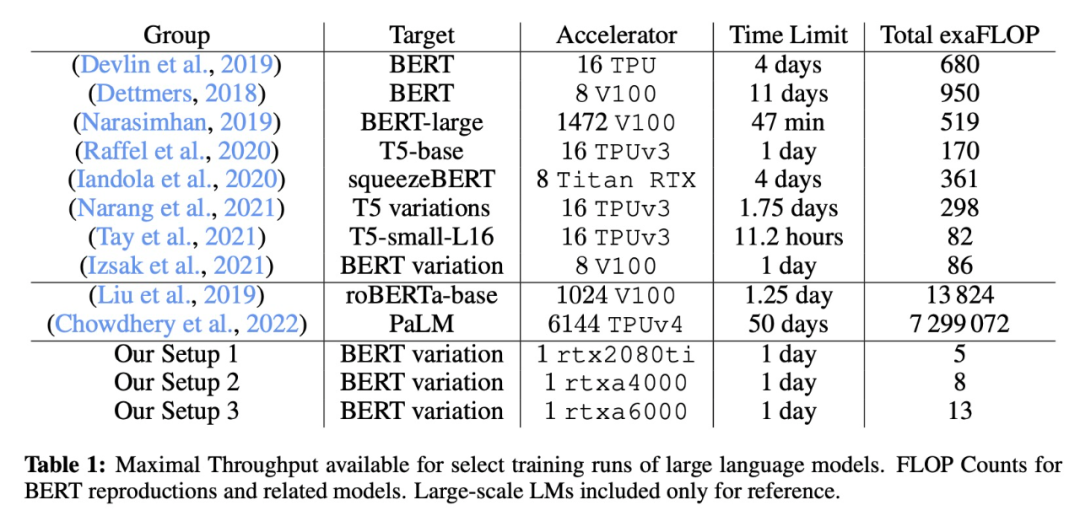
該研究與一些經典大模型的具體訓練設置比較如下表所示:
改進方法
研究人員實施并測試了已有工作提出的一些修改方向,包括通用實現和初始數據設置,并嘗試了修改架構、訓練以及改動數據集的方法。
實驗在 PyTorch 中進行,不使用特質化的實現以盡量公平,所有內容都保留在 PyTorch 框架的實現級別上,只允許可應用于所有組件的自動運算符融合,另外只有在選擇了最終的架構變體之后,才會重新啟用高效注意力內核。
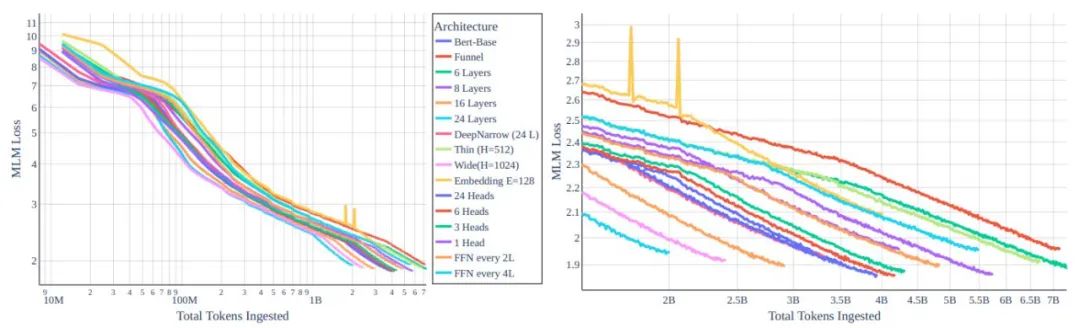
圖 1:不同 transformer 架構變體 MLM 損失函數與 token 對比的情況。左:全局視圖。右圖:放大到 10e8 和更多 token 情況下。所有模型都用相同算力成本訓練,我們可以看到:通過架構重塑實現的改進微乎其微。
有關提升性能,我們最先想到的方法肯定是修改模型架構。從直覺上,較小 / 較低容量的模型似乎在一日一卡式的訓練中是最優的。然而在研究了模型類型與訓練效率之間的關系后,研究人員發現縮放法則為縮小規模設置了巨大的障礙。每個 token 的訓練效率在很大程度上取決于模型大小,而不是 transformer 的類型。
此外,較小的模型學習效率較低,這在很大程度上減緩了吞吐量的增加。幸運的是,在相同大小的模型中,訓練效率幾乎保持不變這一事實,意味著我們可以在參數量類似的架構中尋找合適的,主要根據影響單個梯度步驟的計算時間來做出設計選擇。
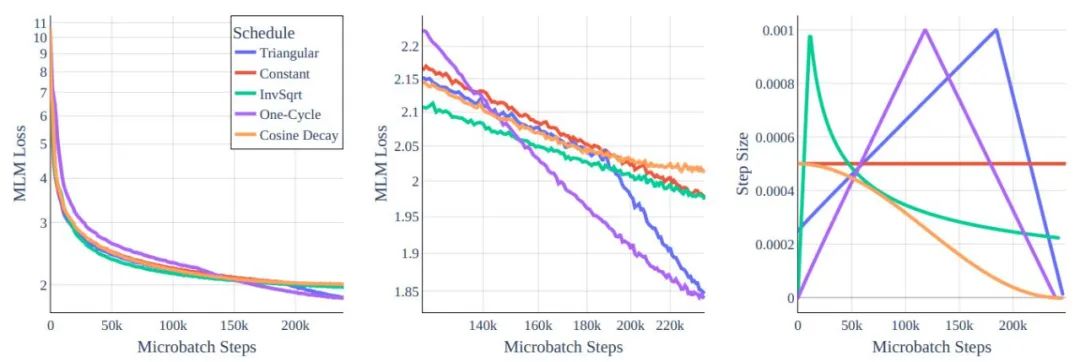
圖 2:學習率 Schedule。盡管在全局范圍內行為相似,但在中間的放大圖里可以看到差異確實存在。
在該工作中,作者研究了訓練超參數對 BERT-base 架構的影響。可以理解的是,原始 BERT 訓練方法的模型在 Cramming 式訓練要求中的表現不佳,因此研究人員重新審視了一些標準選擇。
作者也研究了優化數據集的思路。擴展法則阻礙了通過架構修改取得重大收益的方式(超出計算效率),但縮放定律并不妨礙我們在更好的數據上進行訓練。如果想在在每秒訓練更多的 token,我們應該尋求在更好的 token 上訓練。
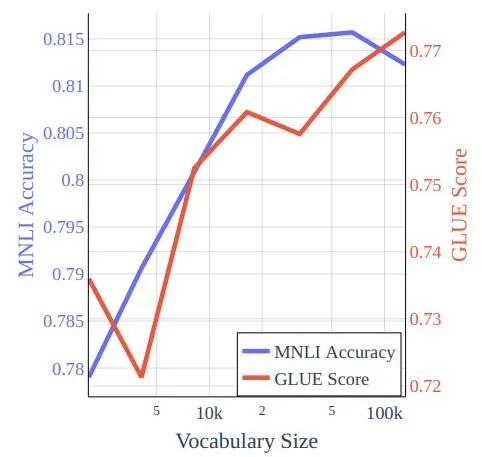
圖 3:在 bookcorpus-wikipedia 數據的 Cramming 式訓練中訓練的模型的詞匯量與 GLUE 分數和 MNLI 準確性。
在 GLUE 上的表現
研究人員系統地評估了 GLUE 基準的性能和 WNLI,并注意到在前面的部分中只使用了 MNLI (m),并且沒有根據完整的 GLUE 分數調整超參數。在新研究中對于 BERT-base 作者微調了 5 個 epoch 的所有數據集,batch size 為 32,學習率為 2 × 10-5。對于 Cramming 訓練的模型這不是最優的,其可以從 16 的 batch size 和 4 × 10?5 的學習率以及余弦衰減中獲得微小的改進(此設置不會改進預訓練的 BERT check point)。
表 3 和表 4 描述了此設置在 GLUE 下游任務上的性能。作者比較了原始的 BERT-base check point、在達到算力上限后停止的 BERT 預訓練設置、Izsak 等人 2021 年研究中描述的設置和修改后的設置,為每塊 GPU 設置訓練一天。總體而言,性能出奇地好,尤其是對于 MNLI、QQP、QNLI 和 SST-2 等較大的數據集,下游微調可以消除完整 BERT 模型和 Cramming 設置變體之間的剩余差異。
此外,作者發現新方法與算力有限的普通 BERT 訓練及 Izsak 等人描述的方法相比都有很大改進。對于 Izsak 等人的研究,其描述的方法最初是為一個完整的 8 GPU 刀片服務器設計的,并且在新的場景中,將其中的 BERT-large 模型壓縮到較小的 GPU 上是導致大部分性能下降的原因。
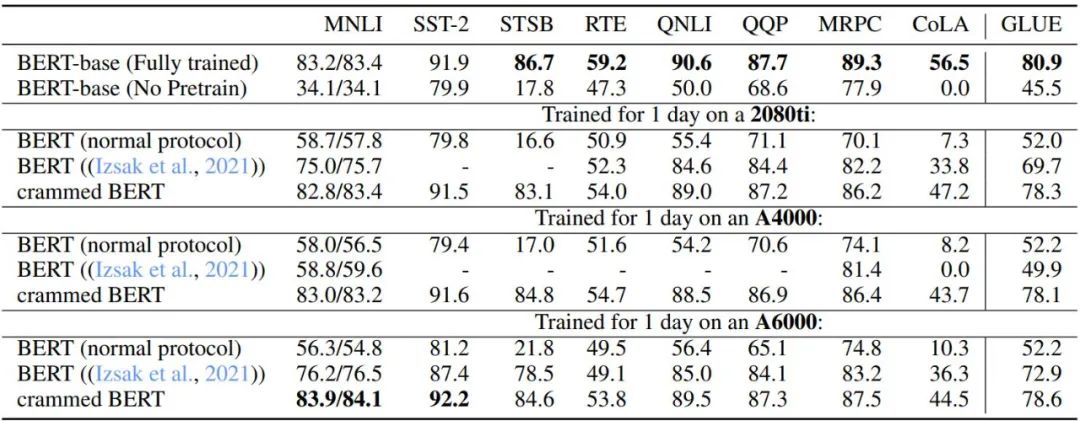
表格 3:基線 BERT 與 Cramming 版本模型的 GLUE-dev 性能比較。其中所有任務的超參數都是固定的,epoch 限制為 5 個,缺失值為 NaN。是為 8 GPU 刀片服務器設計的,而在這里,所有計算被塞進了一塊 GPU。
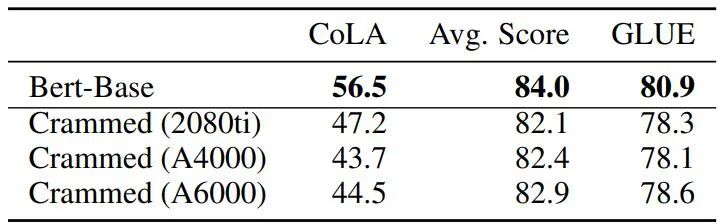
表格 4:基線 BERT 與填充模型的 GLUE-dev 性能比較。
總體而言,使用論文中的方法,訓練結果已經非常接近原版 BERT,但要知道后者使用的總 FLOPS 是新方法 45-136 倍(在 16 塊 TPU 上要花費四天時間)。而當訓練時間延長 16 倍時(在 8 塊 GPU 上訓練兩天),新方法的性能實際上比原始 BERT 提高了很多,達到了 RoBERTa 的水平。
總結
在該工作中,人們討論了基于 transformer 的語言模型在計算量非常有限的環境中可以實現多少性能,值得慶幸的是,幾條修改方向可以讓我們在 GLUE 上獲得不錯的下游性能。研究人員表示,希望這項工作可以為進一步的改進提供一個基線,并進一步給近年來為 transformer 架構提出的許多改進和技巧提供理論支撐。
審核編輯 :李倩
-
gpu
+關注
關注
28文章
4743瀏覽量
129006 -
自然語言處理
+關注
關注
1文章
618瀏覽量
13573 -
算力
+關注
關注
1文章
985瀏覽量
14848 -
大模型
+關注
關注
2文章
2476瀏覽量
2816
原文標題:重磅!一張RTX 2080Ti搞定大模型訓練!算力節省136倍!
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
浪潮信息與智源研究院攜手共建大模型多元算力生態
從零開始訓練一個大語言模型需要投資多少錢?

AI時代算力的重要性及現狀:平衡發展與優化配置的挑戰
大模型后訓練時代,九章云極DataCanvas公司打造普惠算力服務新范式

摩爾線程GPU算力底座助力大模型產業發展
名單公布!【書籍評測活動NO.41】大模型時代的基礎架構:大模型算力中心建設指南
萬卡集群解決大模型訓算力需求,建設面臨哪些挑戰

超算訓練大模型,不浪費一丁點計算資源
摩爾線程張建中:以國產算力助力數智世界,滿足大模型算力需求
【大語言模型:原理與工程實踐】大語言模型的預訓練
潞晨科技Colossal-AI + 浪潮信息AIStation,大模型開發效率提升10倍
智能算力規模超通用算力,大模型對智能算力提出高要求
科大訊飛發布“訊飛星火V3.5”:基于全國產算力訓練的全民開放大模型






 工商網監
工商網監
評論