 一種基于new concepts的text-to-image生成模型的fine-tuning方法
一種基于new concepts的text-to-image生成模型的fine-tuning方法
2. 引言
最近通過文本生成圖像的深度學習相關技術取得了非常大的進展,2021已經成為了圖像生成的一個新的milestone,諸如DALL-E和Stable diffusion這種模型都取得了長足的進步,甚至達到了“出圈”的效果。通過簡單文本prompts,用戶能夠生成前所未有的質量的圖像。這樣的模型可以生成各種各樣的對象、風格和場景,并把它們進行組合排序,這讓現有的圖像生成模型看上去是無所不能的。

但是,盡管這些模型具有多樣性和一些泛化能力,用戶經常希望從他們自己的生活中合成特定的概念。例如,親人、朋友、寵物或個人物品和地點,這些都是非常有意義的concept,也和個人對于生成圖像的信息有對齊。由于這些概念天生就是個人的,因此在大規模的模型訓練過程中很難出現。
事后通過詳細的文字,來描述這種概念是非常不方便的,也無法保留足夠多的視覺細節來生成新的personal的concepts。這就需要模型具有一定的“定制”能力。也就是說如果給定少量用戶提供的圖像,我們能否用新概念(例如寵物狗或者“月亮門”,如圖所示)增強現有的文本到圖像擴散模型?經過微調的模型應該能夠將它們與現有概念進行概括并生成新的變化。這帶來了幾個比較嚴峻的挑戰:
首先,模型傾向于遺忘現有概念的含義:例如,在添加“moon gate”這一concept的時候,“moon”的含義就會丟失。
其次,由于stable diffusion這樣的網絡往往參數會超級多,所以在小數據上訓練模型,容易造成對訓練樣本進行過擬合,而且采樣中變化也有限。
此外,論文還關注了一個更具挑戰性的問題,即組group fine-tuning,即能夠超越單個個體concept的微調,并將多個概念組合在一起。學習多個新的concepts同時也是存在一定的挑戰的,比如 concept mixing以及concept omission。
在這項工作中,論文提出了一種fine-tuning技術,即文本到圖像擴散模型的“定制擴散”。我們的方法在計算和內存方面都很有效。為了克服上述挑戰,新方法固定一小部分模型權重,即文本到潛在特征的key值映射在cross-attention layer中。fine-tuning這些足以更新模型的新concepts。
為了防止模型喪失原來強大的表征能力,新方法僅僅使用一小組的圖像與目標圖像類似的真實圖像進行訓練。我們還在微調期間引入data的augamation,這可以讓模型更快的收斂,并獲得更好的結果。論文提出的方法實驗是構建在Stable Diffusion之上,并對各種數據集進行了實驗,其中最少有四幅訓練圖像。
對于添加單個concept,新提出的方法顯示出比相似任務的作品和基線更好的文本對齊和視覺相似性。更重要的是,我們的方法可以有效地組成多個新concepts,而直接對不同的concepts進行組合的方法則遇到困難,經常會省略一個。最后,我們的方法只需要存儲一小部分參數(模型權重的3%),消耗的GPU memory非常有限,同時也減少了fine-tuning的時間。
3. 方法
總結來講,論文提出的方法,就是僅更新權重的一小部分,即模型的交叉注意力層。此外,由于目標概念的訓練樣本很少,所以使用一個真實圖像的正則化集,以防止過擬合。
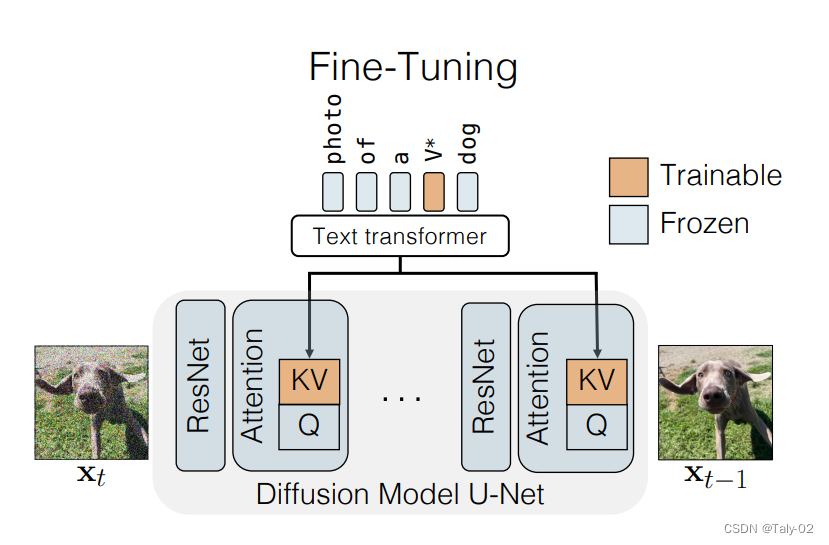
對于Single-Concept Fine-tuning,給定一個預訓練的text-to-image diffusion model,我們的目標是在模型中加入一個新的concept,只要給定四張圖像和相應的文本描述進行訓練。fine-tuning后的模型應保留其先驗知識,允許根據文本提示使用新概念生成新的圖像類型。
這可能具有挑戰性,因為更新的文本到圖像的映射可能很容易過擬合少數可用圖像。所以保證泛化性就非常有必要,也比較有挑戰。所以就僅僅fine-tuning新的K和V,而對于query,則保持不變,這樣就可以增加新概念的同時,保證模型的表征能力不受到太多的影響。優化目標還是diffusion的形式:
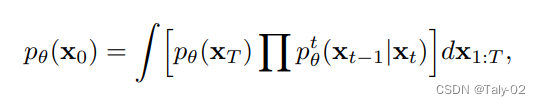
概括起來實際上非常簡單,就是訓練一個k和v的矩陣,來擴充維度,增加模型的表征能力,使其能生成更為豐富的圖像內容。
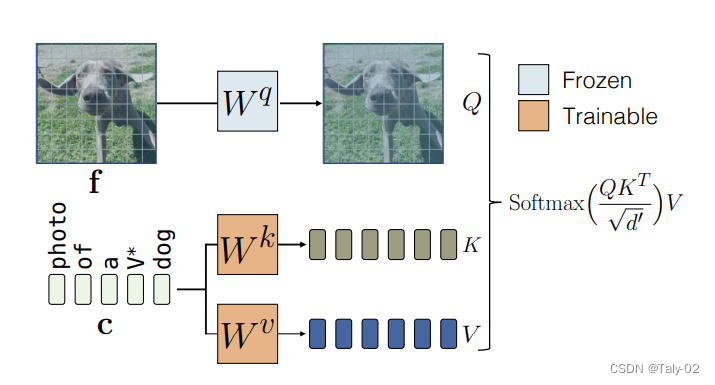
而對于Multiple-Concept Compositional Fine-tuning,為了對多個概念進行微調,我們將每個概念的訓練數據集合并,并使用我們的方法將它們聯合訓練。為了表示目標概念,我們使用不同的修飾符的,并將它們與每個層的交叉注意關鍵和值矩陣一起初始化,并優化它們。通過將權重更新限制為交叉注意key和value參數,與DreamBooth等方法相比,可以顯著更好地將兩個概念合并在一起。


可以發現,增加約束還是讓模型具有更強的表征能力的。最下面一行才和真正的門比較相似,同時生成的月亮也非常合理。
4. 實驗

給定一個新concepts的圖像如左側顯示的目標圖像,提出的方法可以在看不見的上下文和藝術風格中生成帶有該概念的圖像。
第一行:代表水彩畫藝術風格中的概念。方法還可以在背景中生成山脈,而 DreamBooth 和 Textual Inversion 忽略了這一點。
第二行:改變背景場景。我們的方法和 DreamBooth 的表現與 Textual Inversion 相似且更好。
第三行:添加另一個對象,例如帶有目標桌子的橙色沙發。新的方法成功地添加了另一個對象。第四行:改變對象屬性,如花瓣的顏色。第五行:用太陽鏡裝飾私人寵物貓。我們的方法比基線更好地保留了視覺相似性,同時僅更改花瓣顏色或為貓添加太陽鏡。

可以發現Multiple-Concept Compositional Fine-tuning的效果也非常驚艷。

風格遷移的效果也不錯。
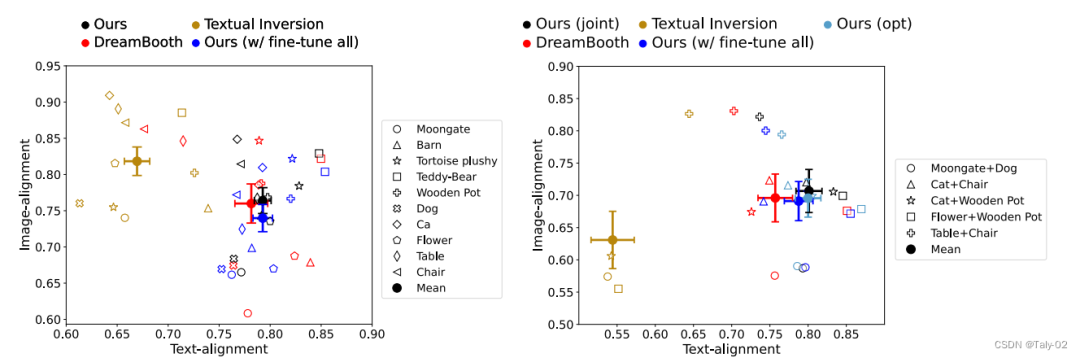
定量指標也有比較有競爭力的表現:
5. 結論
論文提出了一種基于new concepts的text-to-image生成模型的fine-tuning方法。只需使用一些有限的圖像示例, 新方法就能一高效的方法生成微調概念的新樣本同時保留原有的生成能力。而且,我們只需要保存一小部分模型權重。此外,方法可以連貫地在同一場景中組合多個新概念,這是之前的方法所缺少的能力。
審核編輯:劉清
-
gpu
+關注
關注
28文章
4743瀏覽量
128988
原文標題:如何簡單高效地定制自己的文本作畫模型?
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大語言模型優化生成管理方法
LLM和傳統機器學習的區別
一種創新的動態軌跡預測方法
Whatsapp正在開發一種新的生成人工智能功能
使用TensorFlow進行神經網絡模型更新
大模型為什么要微調?大模型微調的原理
rup是一種什么模型
如何用C++創建簡單的生成式AI模型
人工神經網絡模型是一種什么模型
預訓練模型的基本原理和應用
ISEDA首發!大語言模型生成的代碼到底好不好使

一種利用光電容積描記(PPG)信號和深度學習模型對高血壓分類的新方法
生成SPWM波形的方法
了解鴻蒙OS Text組件

一種基于PV變換和CNN模型生成BEV數據的方法






 工商網監
工商網監
評論