 對話機器人之LaMDA
對話機器人之LaMDA
來自:NLP日志
提綱1 簡介 2 LaMDA 3 總結
1 簡介
LaMDA是在DeepMind的Sparrow跟openai的instructGPT之前由谷歌提出的對話機器人,全稱Language Models for Dialog Applications,是一個在海量對話跟web數據上進行預訓練再在人工標注數據上做進一步微調后得到的參數量高達137B的大模型。LaMDA除了在生成文本質量有所提升外,通過在人工標注數據上做進一步finetune以及讓模型學會檢索利用外部知識源的能力,使得模型在安全性以及事實性這兩個關鍵問題上獲得明顯提升。
安全性指的是模型的回復應該滿足一系列人為價值觀,例如沒有歧視跟偏見,不會生成傷害性建議。事實性指的模型的回復應該符合事實,跟外部知識源保持一致,而不是一本正經的胡說八道。???????
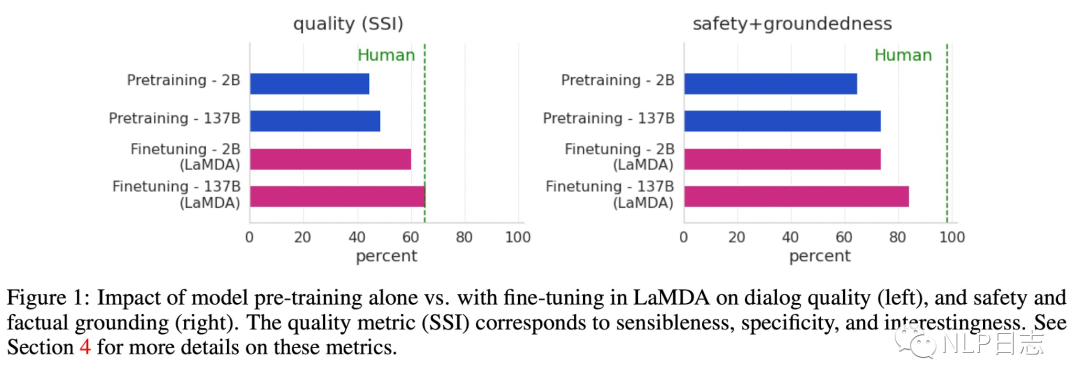
圖1: LaMDA在生成文本在多個指標下有明顯提升
2 LaMDA
Pre-training
LaMDA采用的是純decoder的結構,類似于GPT,使用了46層Transformer,模型參數量高達130B,是Meena的50倍。預訓練的任務是預測文本中的下一個token,解碼策略跟Meenay一致,都是從top-40結果采樣得到16個候選回復,再基于候選回復的對數似然得分跟長度選擇最優的回復。不同于此前的對話模型只在對話數據上訓練,LaMDA的預訓練數據集包括對話數據(1.12B)和其他web文檔數據(2.97B)。

圖2: LaMDA預訓練任務????
Finetune
LaMDA的finetune包括兩部分,一部分是針對生成文本質量跟安全性,另一部分則是學習如何利用外部的信息檢索系統。其中質量(SS I)可以從三方面評估,分別是sensibleness(文本是否合理,跟歷史對話是否有沖突),Specificity(對于前文是否有針對性,避免籠統回復,例如用戶提問“I love Eurovision”,模型生成一個籠統回復“Me too”就不符合預期),Interestingness(文本是否能引起某人注意或者好奇,是否是超出期待的巧妙回復)。而安全性(Safety)的目標則是要符合谷歌AI的基本原則,避免生成會造成傷害的不符合預期的結果,或者帶有偏見跟歧視。
a)Finetuning for quality and safety
這部分的finetune既包括給定上文生成回復的生成任務,也包括評估回復質量跟安全性的判別式任務。對于生成任務,訓練樣本格式由“
Finetune過程先對LaMDA的判別任務進行優化,使得模型可以預測候選回復的質量得分跟安全性得分,然后過濾掉安全性得分低于閾值的候選回復,再根據質量得分對候選回復進行排序(3*P(sensibleness)+P(specificity)+P(interestingness)),選擇其中得分最高的回復作為模型生成的結果。再利用已經訓練后LaMDA的打分模型,篩選出高質量的訓練數據,用于LaMDA的生成任務的finetune,使得模型可以生成高質量的回復。根據下圖也可以看到利用高質量數據進行的finetune讓模型在各方面都有了明顯的提升。
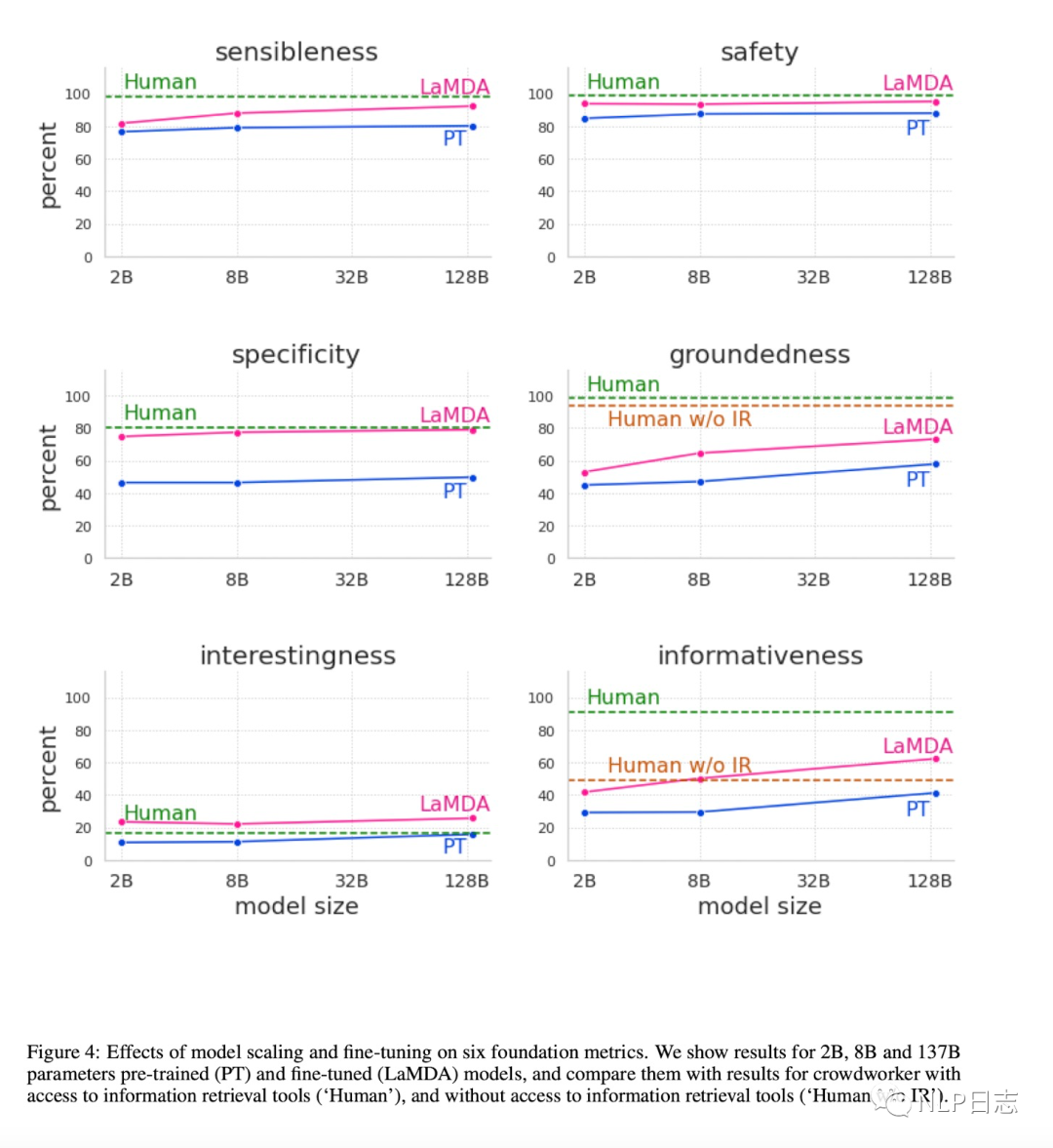
圖3: finetune模型在多個指標上的提升
b)Finetuning to learn to call an external information retrieval system
這部分也稱為Groundedness,針對語言模型的可能生成看起來可信,但是違背事實的幻視問題,LaMDA通過學習使用利用外部知識源去緩解這個問題。LaMDA構建一個包含信息檢索系統,計算模塊,翻譯模塊的工具(簡稱TS),這部分的finetune也包括兩個子任務,第一個是將歷史上文跟模型回復一起輸入到模型中,生成對應的檢索query。第二個子任務是將歷史上文+模型回復+檢索結果一同輸入到模型中,讓模型決定是生成新的檢索query或者生成最終回復(根據生成的第一個字符串決定,如果是TS,則繼續檢索,如果是User則返回對應結果)
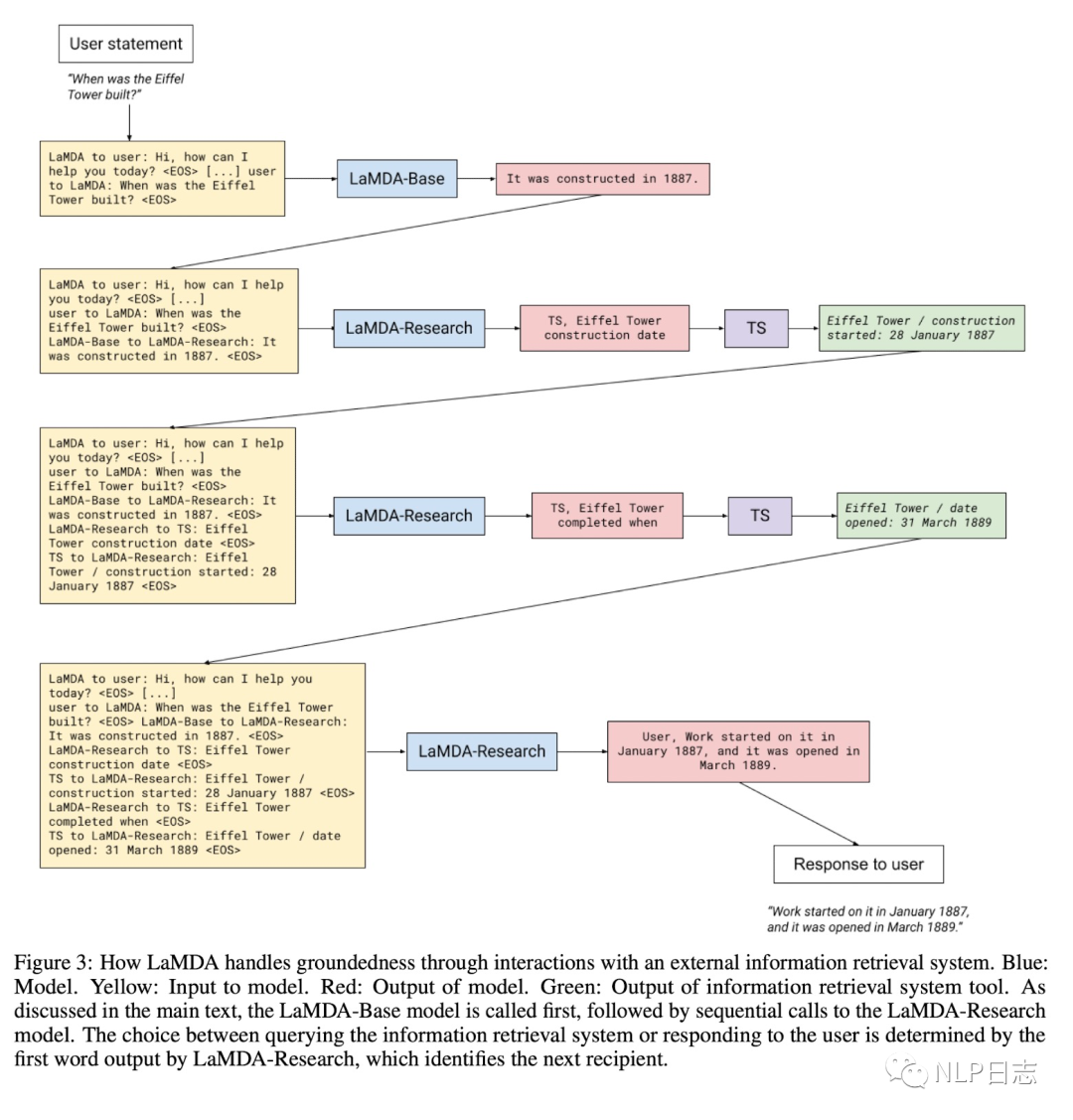
圖4: LaMDA Search流程?
在具體推理流程中,只用一個LaMDA模型,但是做了多個子任務,具體過程中該執行哪個子任務,則由當前輸入的prompt決定,例如當前輸入prompt是LaMDA to user就對應自動生成回復,如果當前prompt是LaMDA-Base to LaMDA-Research就對應生成檢索query。
3 總結
從LaMDA跟后續的Sparrow,我們也可以看到一些共同點。1)可以使用一個強大的模型同時處理多個不同任務。????2)finetune階段高質量數據對于模型的最終性能影響頗大,為了得到這些高質量的數據,LaMDA跟Sparrow在搜集finetune數據有一套嚴格的方法論。3) 讓模型學習檢索利用外部知識源,可以緩解模型幻視的問題,讓模型生成結果更佳有理可依,也讓模型可以回答與時俱進的問題。?????????????4)為生成文本的安全性設計額外的子任務,從而緩解敏感性的問題。LaMDA的成功,依舊貫徹著大力出奇跡的思路,不僅模型的參數量龐大,預訓練的語料龐大,連finetune階段的人工標注數據也不是一般人可以承受的。
-
機器人
+關注
關注
211文章
28466瀏覽量
207292 -
模型
+關注
關注
1文章
3254瀏覽量
48876
原文標題:對話機器人之LaMDA
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「具身智能機器人系統」閱讀體驗】+兩本互為支持的書
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
【「具身智能機器人系統」閱讀體驗】1.初步理解具身智能
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
【「具身智能機器人系統」閱讀體驗】+初品的體驗
《具身智能機器人系統》第1-6章閱讀心得之具身智能機器人系統背景知識與基礎模塊
開源項目!用ESP32做一個可愛的無用機器人
開源項目!用ESP32做一個可愛的無用機器人
安費諾連接器賦能自主機器人未來發展
柔性機器人與剛性機器人區別與聯系

Al大模型機器人
其利天下技術·搭載無刷電機的掃地機器人的前景如何?
AI企業Figure發布人形機器人01,具備與人對話能力,能理解情境
自動打電話的機器人有哪些功能?






 工商網監
工商網監
評論