 李飛飛高徒盤點年度十大AI亮點:核聚變、ChatGPT、AlphaFold上榜
李飛飛高徒盤點年度十大AI亮點:核聚變、ChatGPT、AlphaFold上榜
【導讀】2022年有哪些人工智能的突破?今天,李飛飛高徒Jim Fan盤點了年度十大AI亮點。
人工智能的爆炸正在扭曲我們的時間感。
你能相信Stable Diffusion只有4個月大,而ChatGPT的出現還不到一個月嗎?
打個形象的比喻,只要眨一下眼,你就會錯過一個全新的行業。2022年的AI領域,大規模的生成模型像雨后春筍一樣地冒出,改變了整個AI界的格局。
而且,這些模型正在迅速走出實驗室,在現實中被應用。
比如,LLM技術就啟發了兩個新興的領域——決策代理(游戲、機器人等等)和 AI4Science。
李飛飛高徒Jim Fan為我們總結了2022年的十大AI高光時刻。讓我們把時間倒轉,看看2022年都有哪些令人驚嘆的AI突破。 一、文字-圖像生成
一、文字-圖像生成DALLE-2是第一個可以從任意標題生成逼真的高分辨率圖像的大規模擴散模型。
它啟動了AI的藝術革命,催生了許多新的應用程序、初創公司和思維方式。

但 DALLE-2被保護在OpenAI的圍墻后面,并沒有開源。
在OpenAI之后,LMU的StabilityAI和runwayml邁出了英勇的一步,基于「潛在擴散」算法訓練了他們自己的互聯網規模的text2image模型。他們稱該模型為「穩定擴散」,并開源了代碼和權值(weighs)。 事實證明,Stable Diffusion的開放性,讓它給游戲帶來了巨變。現在,許多初創公司和研究實驗室都在Stable Diffusion的基礎上創建新的應用程序,Stable Diffusion本身也被開源社區不斷改進。最近,Stable Diffusion已經達到了v2.1版本,可以在單個GPU上運行了。
事實證明,Stable Diffusion的開放性,讓它給游戲帶來了巨變。現在,許多初創公司和研究實驗室都在Stable Diffusion的基礎上創建新的應用程序,Stable Diffusion本身也被開源社區不斷改進。最近,Stable Diffusion已經達到了v2.1版本,可以在單個GPU上運行了。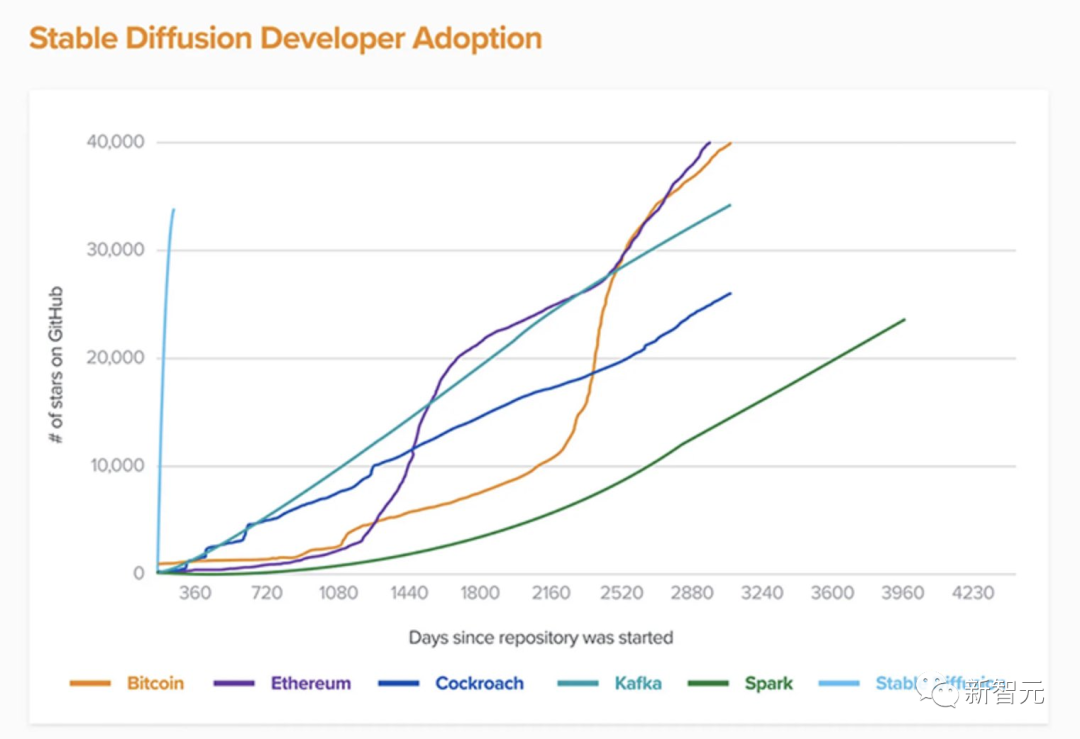
另外,今年還有來自GoogleAI的兩個image2text模型。GoogleAI既沒有發布模型也沒有發布API,但從論文中,我們仍然可以看到不少有趣的見解。
Imagen
https://imagen.research.google

Parti
https://parti.research.google。它是一個沒有diffusion的Transformer模型。

ChatGPT和GPT-3.5都使用了一種叫做RLHF(「從人類反饋中強化學習」)的新技術。
這也就意味著,提示工程或許很快就會消失了。
ChatGPT的流行,已經催生了一波新的創業公司和競爭者,比如Jasper Chat、YouChat、Replit的Ghostwriter chat,以及perplexity_ai。
這些競爭者提供了如此直觀的搜索方式,連谷歌的高管們都開始出汗了! 三、文本- 機器人模型如何給GPT提供胳膊和腿,讓它們能打掃你混亂的廚房?與NLP不同,機器人模型需要與物理世界互動。
在今年,大的預訓練Transformer終于開始解決機器人領域最難的問題了!VIMA
10月,我和同事創建了一個 「機器人GPT 」——名為VIMA的tranformer。它可以接收任何混合的文本、圖像和視頻作為prompt,并輸出機器人手臂的控制。我們的模型被稱為VIMA(「VisuoMotor Attention」),已經完全開源了。現在,單個智能體已經能夠解決視覺目標、視頻的一次性模仿、新概念基礎、視覺約束等,具有了模型容量和數據的強大擴展性。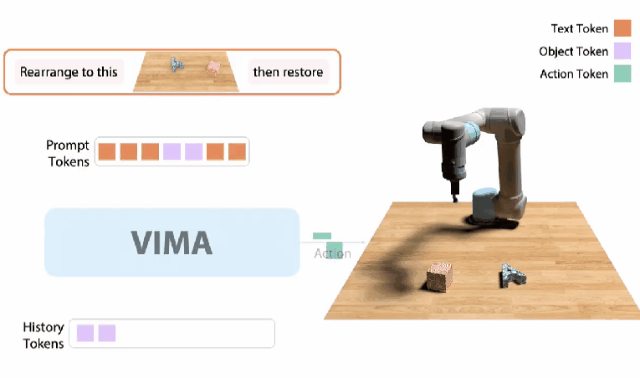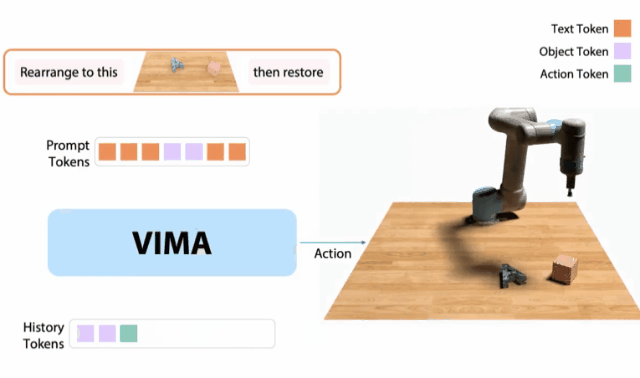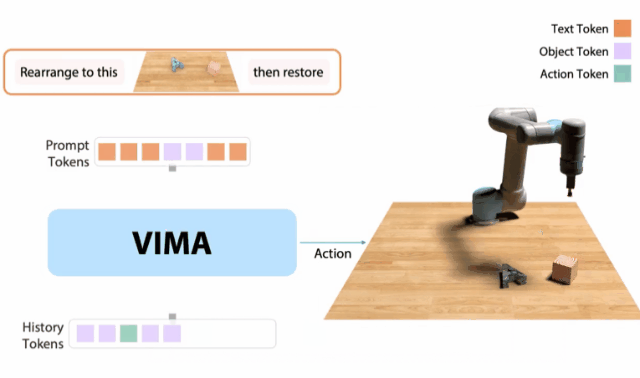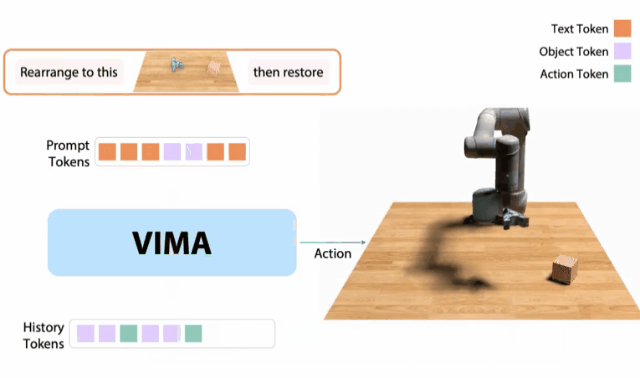
RT-1
沿著與VIMA類似的路徑,來自GoogleAI的研究人員發布了RT-1,這是一種在700項任務和130K的人類演示上訓練的機器人transformer。
這些數據是由13個機器人在17個月內收集的,是字面意義上的鋼鐵部隊!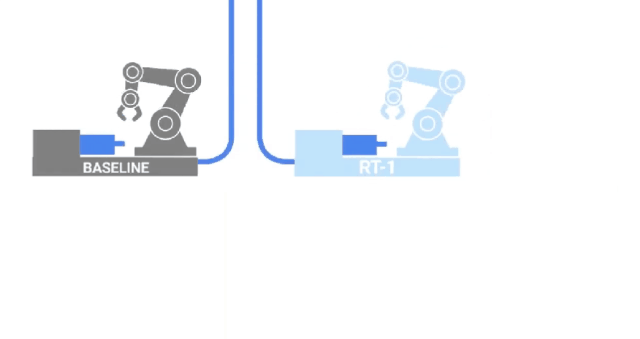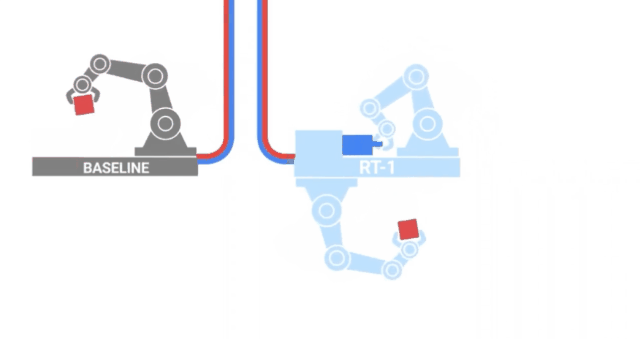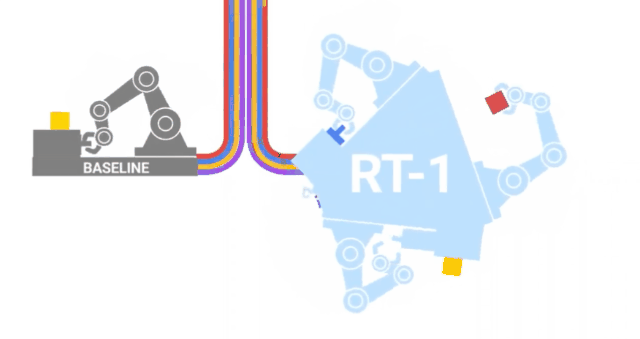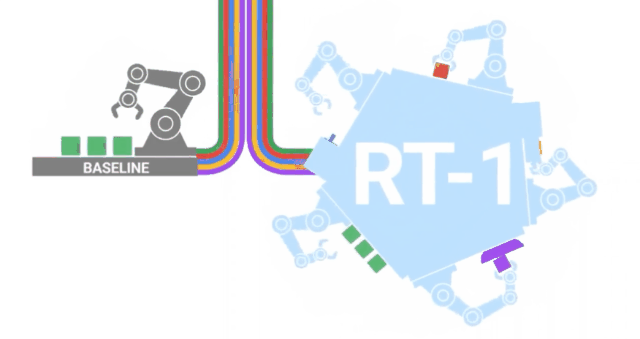 四、文本 - 視頻本質上說,視頻就是隨著時間的推移捆綁在一起的一系列圖像,給我們創造了運動的錯覺。
四、文本 - 視頻本質上說,視頻就是隨著時間的推移捆綁在一起的一系列圖像,給我們創造了運動的錯覺。如果我們可以做text2image,那為什么不在里面加上時間軸,來獲得額外的樂趣呢?
目前,文本 - 視頻領域有3個重大的工作,但沒有一個是開源的。Make-A-Video
首先是Meta AI的Make-A-Video:不需要成對的文本-視頻數據,就可以得到文本-視頻的生成。
您可以在此處注冊試用訪問權限:https://makeavevideo.studio
 論文鏈接:https://arxiv.org/abs/2209.14792
論文鏈接:https://arxiv.org/abs/2209.14792
Imagen Video
Google AI的Imagen Video:它能使用擴散模型生成高清視頻,基于Imagen靜態圖像生成器。
演示:http://imagen.research.google/video/
 論文鏈接:https://arxiv.org/abs/2210.02303
論文鏈接:https://arxiv.org/abs/2210.02303
Phenaki
來自谷歌AI的Phenaki: 從開放領域的文本描述中生成可變長度的視頻。
演示:https://phenaki.video 論文鏈接:https://arxiv.org/abs/2210.02399
論文鏈接:https://arxiv.org/abs/2210.02399 五、文本-3D建模從設計創新產品到在電影和游戲中創造奇妙的視覺效果,3D建模正成為文本-X生成模型的下一片藍海。令人驚喜的是,2022年出現了許多卓有前途的3D生成模型。在此,Fan列舉了3個模型。
五、文本-3D建模從設計創新產品到在電影和游戲中創造奇妙的視覺效果,3D建模正成為文本-X生成模型的下一片藍海。令人驚喜的是,2022年出現了許多卓有前途的3D生成模型。在此,Fan列舉了3個模型。DreamFusion
首先登場的,是Google AI研究團隊與UC Berkeley聯合開發的DreamFusion。
 論文鏈接:https://arxiv.org/pdf/2209.14988.pdf
論文鏈接:https://arxiv.org/pdf/2209.14988.pdf該模型使用二維文本到圖像的擴散模型來執行文本到三維的合成。
基于NeRF算法,DreamFusion可以通過給定文本生成3D模型。

Magic3D
第二項成果,是英偉達AI團隊的兩個項目,名為GET3D和Magic3D。
 GET3D論文鏈接:https://nv-tlabs.github.io/GET3D/assets/paper.pdf
GET3D論文鏈接:https://nv-tlabs.github.io/GET3D/assets/paper.pdf
Magic3D論文鏈接:https://arxiv.org/pdf/2211.10440.pdf
GET3D僅使用二維圖像進行訓練,可生成具有高保真紋理和復雜幾何細節的三維圖形。

該模型允許用戶立即將其形體導入3D渲染器和游戲引擎,以便進行后續編輯。
Magic3D與DreamFusion類似,使用文本到圖像模型生成2D圖像,然后優化為體積NeRF(神經輻射場)數據,將低分辨率生成的粗略模型優化為高分辨率的精細模型。

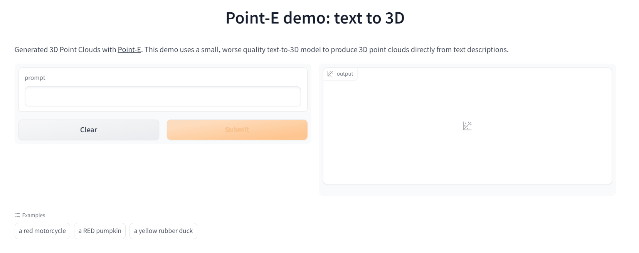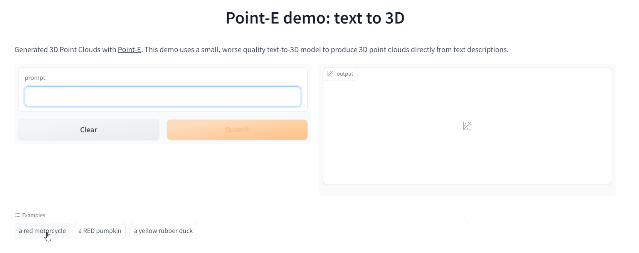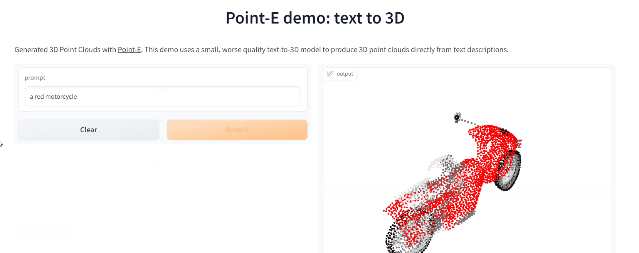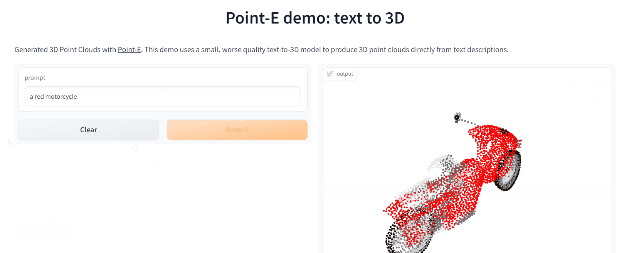
Point-E
繼年初推出的DALL-E 2用天才畫筆驚艷所有人之后,周二OpenAI發布了最新的圖像生成模型「POINT-E」,它可通過文本直接生成3D模型。

論文鏈接:https://arxiv.org/pdf/2212.08751.pdf
相比競爭對手們(如谷歌的DreamFusion)需要幾個GPU工作數個小時,POINT-E只需單個GPU便可在幾分鐘內生成3D圖像。
《我的世界》是一款測試AI通用智能的絕佳游戲。首先,它是一款無限開放的沙盒游戲,極度體現玩家的創造力。
其次,該游戲有1.4億的玩家群體,是英國總人口的兩倍。用戶基礎如此龐大,供AI學習的游戲數據可謂是源源不絕。
那么,AI能否和人類一樣盡情揮灑想象力呢?
Jim Fan和同事合作開發了第一個玩《我的世界》的AI「MineDojo」,它可以在自然語言提示下解決許多任務。

論文鏈接:https://arxiv.org/pdf/2206.08853.pdf
Fan的最終目標是建立一個「具身的ChatGPT」。目前,MineDojo平臺已經完全開源。
與此同時,Jeff Clune的團隊宣布了一個名為視頻預訓練(VPT)的模型,該模型可以直接輸出鍵盤和鼠標的動作。

論文鏈接:https://arxiv.org/pdf/2206.11795.pdf
VPT擁有更廣闊的視野,但不受語言條件的限制。在這點上,MineDojo和VPT恰好相輔相成。 七、AI外交官Meta AI推出的CICERO是第一個在《外交》游戲中實現人類水平表現的人工智能智能體。

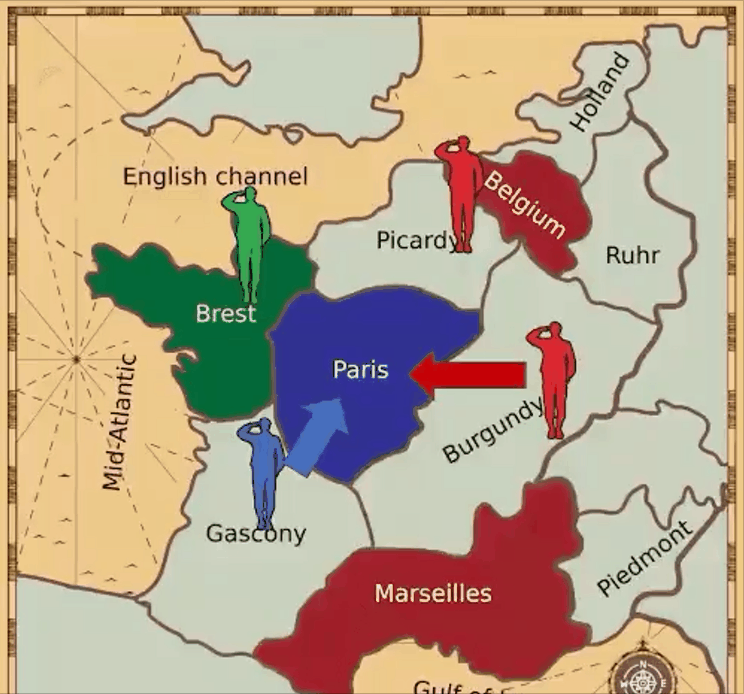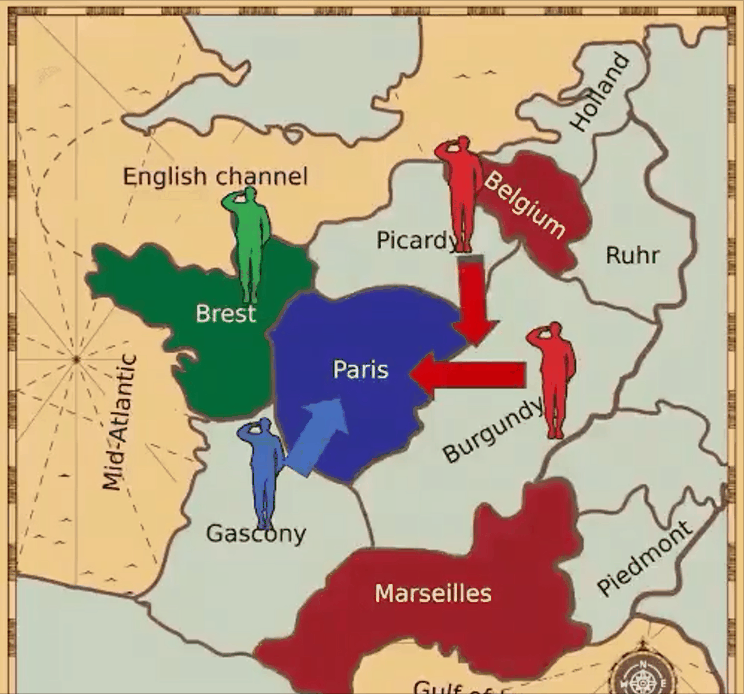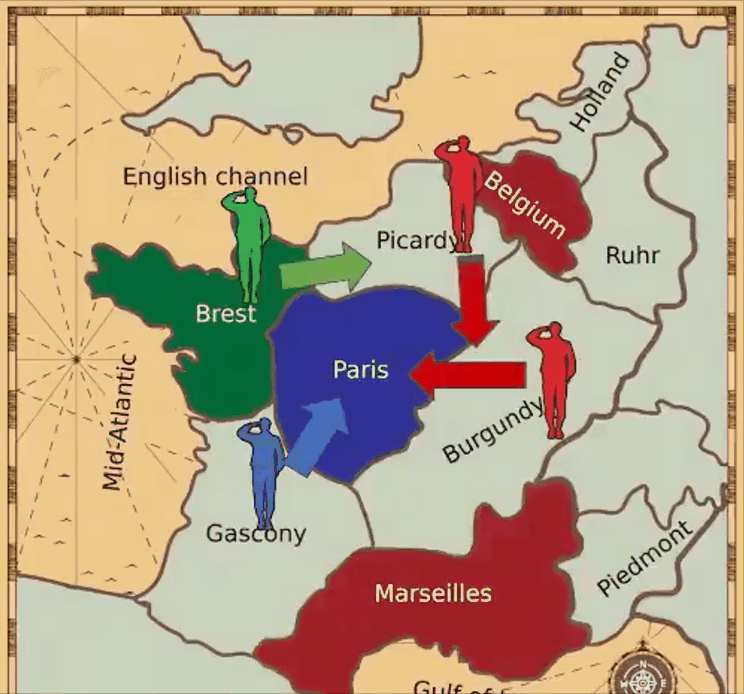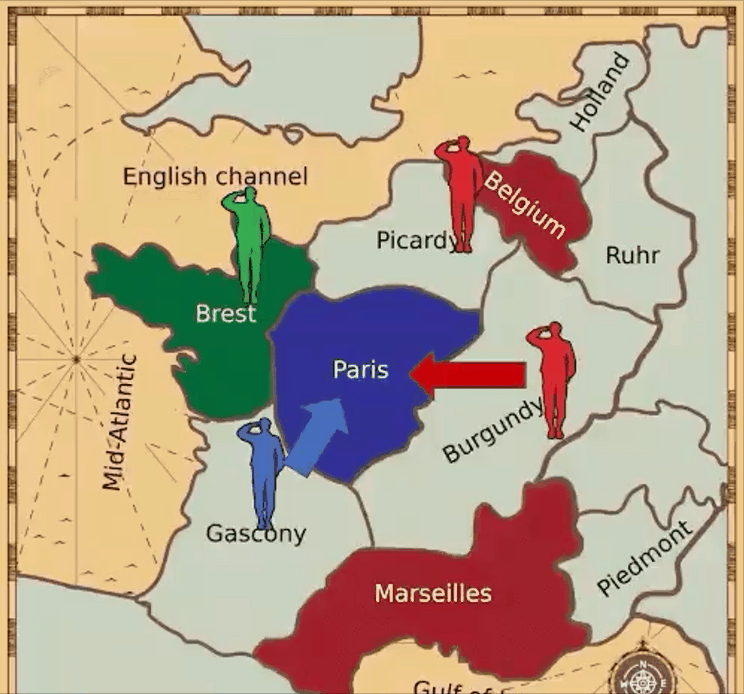

論文鏈接:https://arxiv.org/pdf/2212.04356.pdf
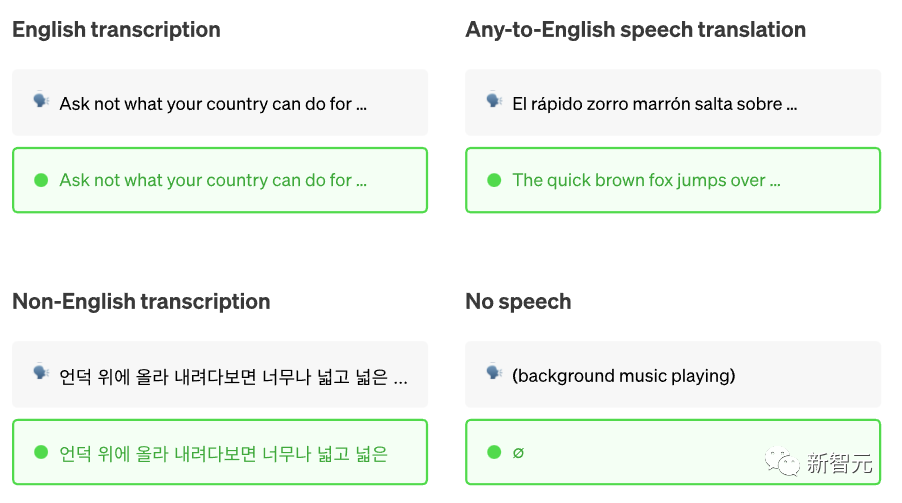
Whisper經過了來自網絡的680,000小時音頻數據的訓練。Open AI強調,Whisper的語音識別能力已達到人類水準。

論文鏈接:https://www.nature.com/articles/s41586-021-04301-9
同樣在本月,美國能源部宣布了一項巨大的突破:人類首次實現了核聚變反應的凈能量增益!
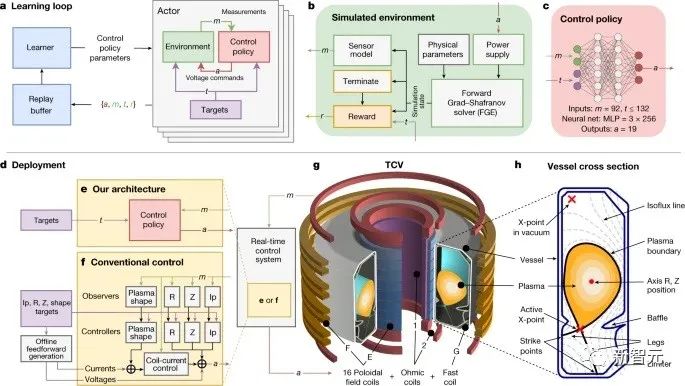
7月,DeepMind宣布了「蛋白質宇宙」——將AlphaFold的蛋白質數據庫擴展到2億個結構!
此外,英偉達AI研究團隊還拓展了BioNeMo大型語言模型的框架,以幫助生物技術公司和研究人員生成、預測和理解生物分子數據。

視頻講解:https://www.youtube.com/watch?v=PWcNlRI00jo&t=4399s
以上便是Jim Fan對2022年十大AI亮點的盤點。當然,Fan也表示,還有無數令人興奮的作品為人工智能的進步做出了貢獻。每篇論文都是AI大廈里的一磚一瓦,所有的努力都應該慶祝。
不過,Fan在最后也強調,隨著人工智能系統變得越來越強大,我們必須意識到潛在的危險和風險,并采取措施減輕它們。
無論是通過仔細的培訓設計、適當的監督還是全新的保障方法,人工智能的安全與倫理成為越來越的AI專家所討論的議程。
毫無疑問,2022年是充滿奇跡的一年,也是令人驚嘆的一年。未來一年又會有什么震驚世界的突破?我們與你一起關注。參考資料:
https://twitter.com/drjimfan/status/1607746957753057280?s=46&t=OVM_4zdRW2rQwqLohMdPpw
END
歡迎加入Imagination GPU與人工智能交流2群 入群請加小編微信:eetrend89
入群請加小編微信:eetrend89(添加請備注公司名和職稱)
推薦閱讀 對話Imagination中國區董事長:以GPU為支點加強軟硬件協同,助力數字化轉型ICCAD 2022圓滿落幕,Imagination異構計算引領“芯”未來
 Imagination Technologies是一家總部位于英國的公司,致力于研發芯片和軟件知識產權(IP),基于Imagination IP的產品已在全球數十億人的電話、汽車、家庭和工作場所中使用。獲取更多物聯網、智能穿戴、通信、汽車電子、圖形圖像開發等前沿技術信息,歡迎關注 Imagination Tech!
Imagination Technologies是一家總部位于英國的公司,致力于研發芯片和軟件知識產權(IP),基于Imagination IP的產品已在全球數十億人的電話、汽車、家庭和工作場所中使用。獲取更多物聯網、智能穿戴、通信、汽車電子、圖形圖像開發等前沿技術信息,歡迎關注 Imagination Tech!
原文標題:李飛飛高徒盤點年度十大AI亮點:核聚變、ChatGPT、AlphaFold上榜
文章出處:【微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
-
imagination
+關注
關注
1文章
573瀏覽量
61317 -
ChatGPT
+關注
關注
29文章
1560瀏覽量
7604
原文標題:李飛飛高徒盤點年度十大AI亮點:核聚變、ChatGPT、AlphaFold上榜
文章出處:【微信號:Imgtec,微信公眾號:Imagination Tech】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
比亞迪海豹榮獲日本年度風云車十大最佳車型獎
全國產PSM高壓電源控制系統,助力核聚變技術發展
可控核聚變解決方案
解決方案丨持續注能人造太陽裝置,助力我國可控核聚變技術研究

解決方案丨持續注能人造太陽裝置,助力我國可控核聚變技術研究
業務資訊丨森木磊石持續發力加速器、核聚變;PPEC電源控制核心走入高校課堂

AI浪潮下的十大消費者新趨勢
度亙核芯榮獲“2023年度中國十大光學產業技術”獎


韓國“人造太陽”在核聚變研究中取得重大突破
科學家利用AI預測核聚變反應堆裂變模式,避免重啟反應堆
核電站工作原理 核電站是核聚變還是核裂變
睿創微納8微米榮獲“2023年度山東十大科技創新成果”
睿創微納8微米榮獲“2023年度山東十大科技創新成果”

2023年度十大科技名詞






 工商網監
工商網監
評論