 車道線檢測Ultra Fast Deep Lane Detection V2講解
車道線檢測Ultra Fast Deep Lane Detection V2講解
Ultra Fast Deep Lane Detection V2
【GiantPandaCV 導語】Ultra Fast Deep Lane Detection 是個比較有特點的車道線檢測模型,把檢測轉化成分類來實現。現在出了 V2,有了幾個創新點,于是又來研究一下。之前參考 Ultra Fast Deep Lane Detection V1 設計了一個全新的車道線檢測網絡,把模型壓縮了80%,并部署使用了。另外還把 v1 和 yolov4 合并實現了多任務:https://github.com/Huangdebo/YOLOv4-MultiTask
1 介紹
這篇文章提出了一個超快車道線檢測,區別于之前基于分割和回歸的模型,該模型把車道線檢測看車是分類問題,而且使用了全連接層,加強了模型的全局感知能力。另外,本文還設計了一個混合錨點機制,對不同的車道使用不用的錨點,很好地解決了兩側車道檢測性能不佳的問題。該模型在兼顧了速度的前提下,還很好地處理了遮擋和暗光等情況,取得了不錯的性能。

2 模型設計
2.1 使用錨點來表示車道線
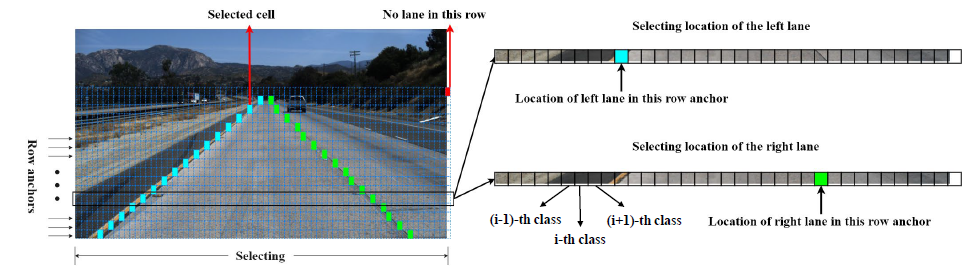
為了表示車道線,首先引入了橫向錨點,把車道線看車橫向錨點的一組關鍵點。但當兩側的車道線的水平角度比較小時,便會引起定位問題,也就是一定寬度的車道線會覆蓋到多個關鍵點,導致定位錯亂,而且角度越小,問題越嚴重:
為了解決上述的定位錯誤問題,文章便提出一種混合錨點機制,中間水平角度大的車道線使用橫向錨點來表達,兩側水平角度小的車道線用縱向錨點來表達。每條車道線都用一組歸一化坐標來表示
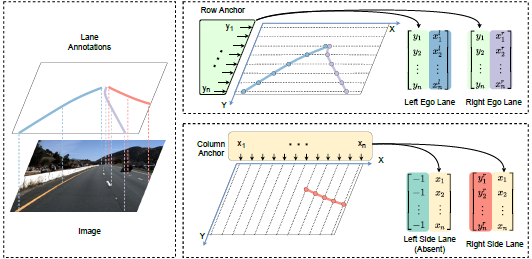
2.2 基于錨點的網絡設計
因為每條車道線都用一組歸一化坐標來表示,而且是把車道線檢測看成分類任務,于是可以通過類別數目來映射出每個車道線關鍵點的類別:
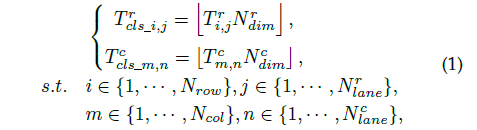
另外,網絡還添加了一個分支,用來判別車道線在該處是否存在。該分支的目標就只有兩個值:1和0,分別代表存在和不存在:
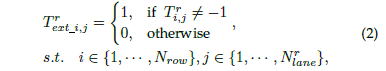
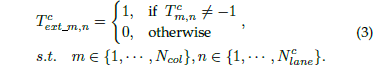
2.3 序列分類的損失函數
既然是分類任務,那自然就會想到使用基本的分類損失函數,相當于把關鍵點的不同位置看成不同的類別,直接用 CE loss 來表達:
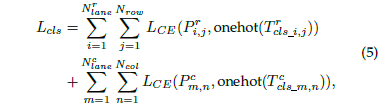
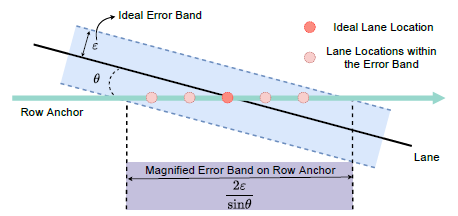
于基本的分類不一樣的是,這個位置的類別是有序的,也就是可以把這個位置的預測值看成是各個位置的投票 均值,越靠近 groundtruth 的地方投票值越大,可以緩解預測偏移的問題:
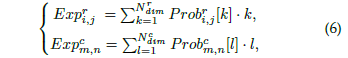
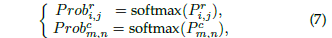 于是,可以這個期望損失可以表達成:
于是,可以這個期望損失可以表達成:
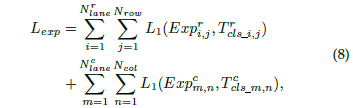
另外,對于網絡另一個用以判別車道線是否存在的分支,就是一個二分類問題,其損失函數可以表達成:
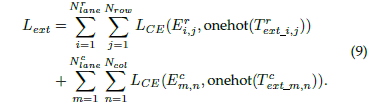
所以整個模型的損失函數便可以組成: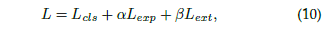
3 消融實驗
3.1 混合錨點機制的作用
混合錨點機制中包含了橫向錨點策略和縱向錨點策略,針對不同的車道線,使用不同的策略。為了對比混合錨點機制的作用,作者分別單獨使用橫向錨點策略和縱向錨點策略以及混合錨點來進行對比:
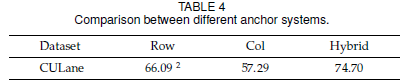
3.2 序列分類的作用
相比于基本的分類任務,文章中所用的序列分類還利用了車道線關鍵點位置的有序性。為了對比序列分類的作用,作者還使用了傳統分類和回歸的方式來比對。對于回歸方式,則是把網絡的分類頭換成回歸頭,并用 smooth L1 los 來訓練。實驗表明,利用了關鍵點有序性的序列分類的性能明顯優于一般的分類和回歸方式:
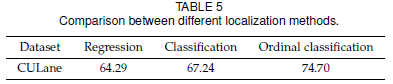
3.3 序列分類損失的消融
序列分類的損失函數包含了兩部分,一個是基本的分類損失和一個期望損失。作者也進行了消融實驗來對比它們的作用:
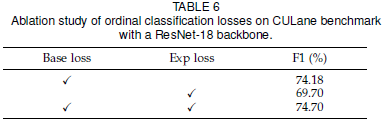
3.4 類別的個數和錨點數量的影響
因為是把車道線的位置檢測看成是關鍵點位置的分類,那久必須要設定一個類別數目,作者通過調整類別數目來做對比實驗,發現隨著類別數目的增加,模型的性能顯示提升然后再下降,說明類別數目并不是越多越好。同樣,錨點的數量也需要預先設定,原則上講,錨點數量越多,對車道線的檢測就越精細,但也意味著計算量也更大,所以必須要在模型速度和性能上做一個權衡。
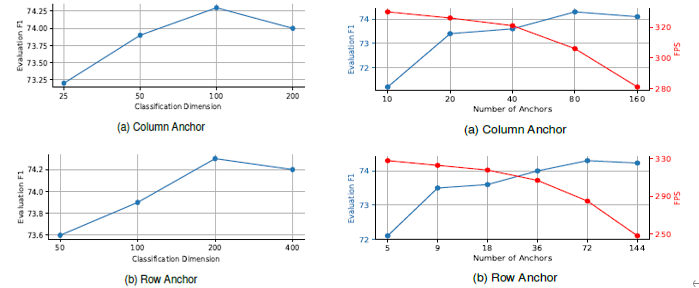
4 結論
使用了混合錨點機制和序列分類損失,緩解了 V1 中兩側車道線檢測性能不足的問題,而且還能保持一樣的高效率。但錨點的數目和序列分類的數目丟等參數都需要手動設定,可能存在一定的數據相關性。而且網絡最后一層使用的是全連接層來提升網絡的感知能力,導致參數比較大,對工程部署不太友好,這些都是可優化的點。
審核編輯 :李倩
-
檢測
+關注
關注
5文章
4509瀏覽量
91639 -
模型
+關注
關注
1文章
3286瀏覽量
49010 -
機制
+關注
關注
0文章
24瀏覽量
9809
原文標題:車道線檢測 Ultra Fast Deep Lane Detection V2 講解
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【實戰】Python+OpenCV車道線檢測識別項目:實現L2級別自動駕駛必備(配套課程+平臺實踐)

淺析SDIO協議V2和V3版本的區別
如何通過SDK功能獲取esptouch v2 apk的自定義數據?
SC171開發套件V2 技術資料

深度解讀RoCE v2的核心技術原理
CMSIS-RTOS V1與V2的區別是什么?
硬件平臺介紹及使用(SC171開發套件V2)
使用ST-link V2的過程中電腦插入讀卡器設備后無法正常識別ST-link V2的原因?
榮耀Magic V2 RSR保時捷設計亮相MWC 2024巴塞羅那全球發布會
大模型系列:Flash Attention V2整體運作流程






 工商網監
工商網監
評論