 完整案例!Python+SQL京東用戶行為分析
完整案例!Python+SQL京東用戶行為分析
1、項目背景
項目對京東電商運營數據集進行指標分析以了解用戶購物行為特征,為運營決策提供支持建議。本文采用了MySQL和Python兩種代碼進行指標計算以適應不同的數據分析開發環境。2、數據集介紹
本數據集為京東競賽數據集,數據已上傳后臺,回復關鍵字:京東電商,即可獲的。詳細介紹請訪問鏈接:https://jdata.jd.com/html/detail.html?id=8 數據集共有五個文件,包含了'2018-02-01'至'2018-04-15'之間的用戶數據,數據已進行了脫敏處理,本文使用了其中的行為數據表,表中共有五個字段,各字段含義如下圖所示:

3、數據清洗
#導入python相關模塊 importnumpyasnp importpandasaspd importseabornassns importmatplotlib.pyplotasplt fromdatetimeimportdatetime plt.style.use('ggplot') %matplotlibinline #設置中文編碼和負號的正常顯示 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False
#讀取數據,數據集較大,如果計算機讀取內存不夠用,可以嘗試kaggle比賽 #中的reduce_mem_usage函數,附在文末,主要原理是把int64/float64 #類型的數值用更小的int(float)32/16/8來搞定 user_action=pd.read_csv('jdata_action.csv')
#因數據集過大,本文截取'2018-03-30'至'2018-04-15'之間的數據完成本次分析 #注:僅4月份的數據包含加購物車行為,即type == 5 user_data=user_action[(user_action['action_time']>'2018-03-30')&(user_action['action_time']'2018-04-15')]
#存至本地備用 user_data.to_csv('user_data.csv',sep=',')
#查看原始數據各字段類型 behavior=pd.read_csv('user_data.csv',index_col=0) behavior[:10] output
user_idsku_idaction_timemodule_idtype 1714552982084412018-04-11154361906591 1814552983343182018-04-11155461906591 1914552982377552018-04-11151361906591 20145529864222018-04-11152561906591 2114552982685662018-04-11152661906591 2214552981159152018-04-11153561906591 2314552982082542018-04-11151661906591 2414552981772092018-04-14145966282541 251455298717932018-04-14142966282541 2614552981419502018-04-121553102072581
behavior.info() output
#查看缺失值 behavior.isnull().sum() output
user_id0 sku_id0 action_time0 module_id0 type0 dtype:int64 數據各列無缺失值。
#原始數據中時間列action_time,時間和日期是在一起的,不方便分析,對action_time列進行處理,拆分出日期和時間列,并添加星期字段求出每天對應 #的星期,方便后續按時間緯度對數據進行分析 behavior['date']=pd.to_datetime(behavior['action_time']).dt.date#日期 behavior['hour']=pd.to_datetime(behavior['action_time']).dt.hour#時間 behavior['weekday']=pd.to_datetime(behavior['action_time']).dt.weekday_name#周
#去除與分析無關的列 behavior=behavior.drop('module_id',axis=1)
#將用戶行為標簽由數字類型改為用字符表示 behavior_type={1:'pv',2:'pay',3:'fav',4:'comm',5:'cart'} behavior['type']=behavior['type'].apply(lambdax:behavior_type[x]) behavior.reset_index(drop=True,inplace=True)
#查看處理好的數據 behavior[:10] output
user_idsku_idaction_timetypedatehourweekday 014552982084412018-04-111543pv2018-04-1115Wednesday 114552983343182018-04-111554pv2018-04-1115Wednesday 214552982377552018-04-111513pv2018-04-1115Wednesday 3145529864222018-04-111525pv2018-04-1115Wednesday 414552982685662018-04-111526pv2018-04-1115Wednesday 514552981159152018-04-111535pv2018-04-1115Wednesday 614552982082542018-04-111516pv2018-04-1115Wednesday 714552981772092018-04-141459pv2018-04-1414Saturday 81455298717932018-04-141429pv2018-04-1414Saturday 914552981419502018-04-121553pv2018-04-1215Thursday
4、分析模型構建指標
1.流量指標分析
pv、uv、消費用戶數占比、消費用戶總訪問量占比、消費用戶人均訪問量、跳失率。PV UV
#總訪問量 pv=behavior[behavior['type']=='pv']['user_id'].count() #總訪客數 uv=behavior['user_id'].nunique() #消費用戶數 user_pay=behavior[behavior['type']=='pay']['user_id'].unique() #日均訪問量 pv_per_day=pv/behavior['date'].nunique() #人均訪問量 pv_per_user=pv/uv #消費用戶訪問量 pv_pay=behavior[behavior['user_id'].isin(user_pay)]['type'].value_counts().pv #消費用戶數占比 user_pay_rate=len(user_pay)/uv #消費用戶訪問量占比 pv_pay_rate=pv_pay/pv #消費用戶人均訪問量 pv_per_buy_user=pv_pay/len(user_pay)
#SQL SELECTcount(DISTINCTuser_id)UV, (SELECTcount(*)PVfrombehavior_sqlWHEREtype='pv')PV FROMbehavior_sql; SELECTcount(DISTINCTuser_id) FROMbehavior_sql WHERE WHEREtype='pay'; SELECTtype,COUNT(*)FROMbehavior_sql WHERE user_idIN (SELECTDISTINCTuser_id FROMbehavior_sql WHEREtype='pay') ANDtype='pv' GROUPBYtype;
print('總訪問量為%i'%pv) print('總訪客數為%i'%uv) print('消費用戶數為%i'%len(user_pay)) print('消費用戶訪問量為%i'%pv_pay) print('日均訪問量為%.3f'%pv_per_day) print('人均訪問量為%.3f'%pv_per_user) print('消費用戶人均訪問量為%.3f'%pv_per_buy_user) print('消費用戶數占比為%.3f%%'%(user_pay_rate*100)) print('消費用戶訪問量占比為%.3f%%'%(pv_pay_rate*100)) output
總訪問量為6229177 總訪客數為728959 消費用戶數為395874 消費用戶訪問量為3918000 日均訪問量為389323.562 人均訪問量為8.545 消費用戶人均訪問量為9.897 消費用戶數占比為54.307% 消費用戶訪問量占比為62.898%
消費用戶人均訪問量和總訪問量占比都在平均值以上,有過消費記錄的用戶更愿意在網站上花費更多時間,說明網站的購物體驗尚可,老用戶對網站有一定依賴性,對沒有過消費記錄的用戶要讓快速了解產品的使用方法和價值,加強用戶和平臺的黏連。跳失率
#跳失率:只進行了一次操作就離開的用戶數/總用戶數 attrition_rates=sum(behavior.groupby('user_id')['type'].count()==1)/(behavior['user_id'].nunique())
#SQL SELECT (SELECTCOUNT(*) FROM(SELECTuser_id FROMbehavior_sqlGROUPBYuser_id HAVINGCOUNT(type)=1)A)/ (SELECTCOUNT(DISTINCTuser_id)UVFROMbehavior_sql)attrition_rates;
print('跳失率為%.3f%%'%(attrition_rates*100)) output
跳失率為22.585% 整個計算周期內跳失率為22.585%,還是有較多的用戶僅做了單次操作就離開了頁面,需要從首頁頁面布局以及產品用戶體驗等方面加以改善,提高產品吸引力。
2、用戶消費頻次分析
#單個用戶消費總次數 total_buy_count=(behavior[behavior['type']=='pay'].groupby(['user_id'])['type'].count() .to_frame().rename(columns={'type':'total'})) #消費次數前10客戶 topbuyer10=total_buy_count.sort_values(by='total',ascending=False)[:10] #復購率 re_buy_rate=total_buy_count[total_buy_count>=2].count()/total_buy_count.count()
#SQL #消費次數前10客戶 SELECTuser_id,COUNT(type)total_buy_count FROMbehavior_sql WHEREtype='pay' GROUPBYuser_id ORDERBYCOUNT(type)DESC LIMIT10 #復購率 CREATVIEWv_buy_count ASSELECTuser_id,COUNT(type)total_buy_count FROMbehavior_sql WHEREtype='pay' GROUPBYuser_id; SELECTCONCAT(ROUND((SUM(CASEWHENtotal_buy_count>=2THEN1ELSE0END)/ SUM(CASEWHENtotal_buy_count>0THEN1ELSE0END))*100,2),'%')ASre_buy_rate FROMv_buy_count;
topbuyer10.reset_index().style.bar(color='skyblue',subset=['total']) output
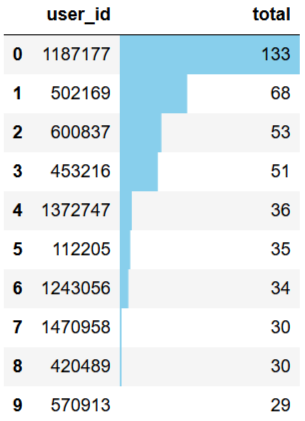
#單個用戶消費總次數可視化 tbc_box=total_buy_count.reset_index() fig,ax=plt.subplots(figsize=[16,6]) ax.set_yscale("log") sns.countplot(x=tbc_box['total'],data=tbc_box,palette='Set1') forpinax.patches: ax.annotate('{:.2f}%'.format(100*p.get_height()/len(tbc_box['total'])),(p.get_x()-0.1,p.get_height())) plt.title('用戶消費總次數') output

print('復購率為%.3f%%'%(re_buy_rate*100)) output
復購率為13.419%復購率較低,應加強老用戶召回機制,提升購物體驗,也可能因數據量較少,統計周期之內的數據 無法解釋完整的購物周期,從而得出結論有誤。
3、用戶行為在時間緯度的分布
日消費次數、日活躍人數、日消費人數、日消費人數占比、消費用戶日人均消費次數#日活躍人數(有一次操作即視為活躍) daily_active_user=behavior.groupby('date')['user_id'].nunique() #日消費人數 daily_buy_user=behavior[behavior['type']=='pay'].groupby('date')['user_id'].nunique() #日消費人數占比 proportion_of_buyer=daily_buy_user/daily_active_user #日消費總次數 daily_buy_count=behavior[behavior['type']=='pay'].groupby('date')['type'].count() #消費用戶日人均消費次數 consumption_per_buyer=daily_buy_count/daily_buy_user
#SQL #日消費總次數 SELECTdate,COUNT(type)pay_dailyFROMbehavior_sql WHEREtype='pay' GROUPBYdate; #日活躍人數 SELECTdate,COUNT(DISTINCTuser_id)uv_dailyFROMbehavior_sql GROUPBYdate; #日消費人數 SELECTdate,COUNT(DISTINCTuser_id)user_pay_dailyFROMbehavior_sql WHEREtype='pay' GROUPBYdate; #日消費人數占比 SELECT (SELECTdate,COUNT(DISTINCTuser_id)user_pay_dailyFROMbehavior_sql WHEREtype='pay' GROUPBYdate)/ (SELECTdate,COUNT(DISTINCTuser_id)uv_dailyFROMbehavior_sql GROUPBYdate) #日人均消費次數 SELECT (SELECTdate,COUNT(type)pay_dailyFROMbehavior_sql WHEREtype='pay' GROUPBYdate)/ (SELECTdate,COUNT(DISTINCTuser_id)uv_dailyFROMbehavior_sql GROUPBYdate)
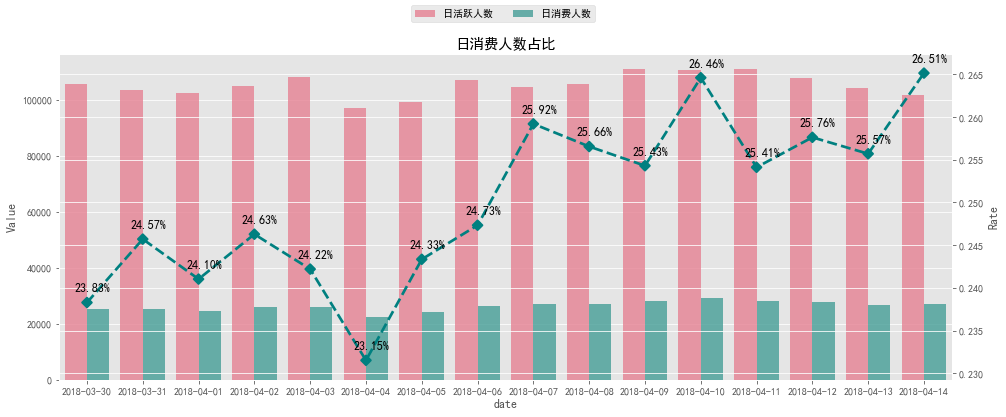
#日消費人數占比可視化 #柱狀圖數據 pob_bar=(pd.merge(daily_active_user,daily_buy_user,on='date').reset_index() .rename(columns={'user_id_x':'日活躍人數','user_id_y':'日消費人數'}) .set_index('date').stack().reset_index().rename(columns={'level_1':'Variable',0:'Value'})) #線圖數據 pob_line=proportion_of_buyer.reset_index().rename(columns={'user_id':'Rate'}) fig1=plt.figure(figsize=[16,6]) ax1=fig1.add_subplot(111) ax2=ax1.twinx() sns.barplot(x='date',y='Value',hue='Variable',data=pob_bar,ax=ax1,alpha=0.8,palette='husl') ax1.legend().set_title('') ax1.legend().remove() sns.pointplot(pob_line['date'],pob_line['Rate'],ax=ax2,markers='D',linestyles='--',color='teal') x=list(range(0,16)) fora,binzip(x,pob_line['Rate']): plt.text(a+0.1,b+0.001,'%.2f%%'%(b*100),ha='center',va='bottom',fontsize=12) fig1.legend(loc='uppercenter',ncol=2) plt.title('日消費人數占比') output
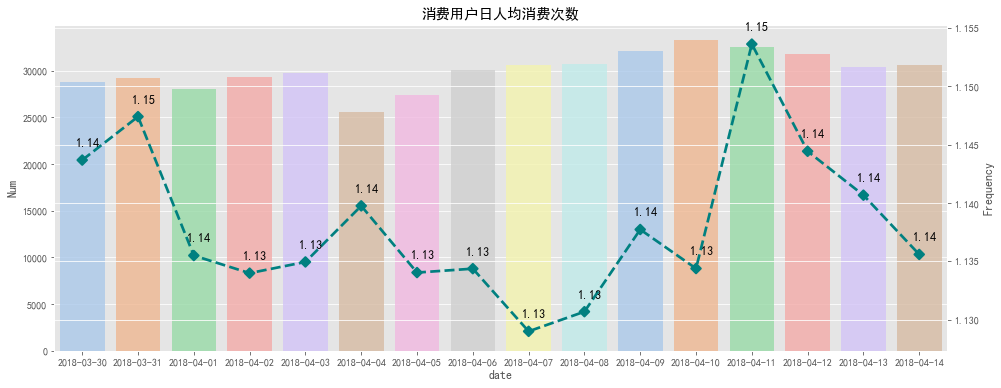
#消費用戶日人均消費次數可視化 #柱狀圖數據 cpb_bar=(daily_buy_count.reset_index().rename(columns={'type':'Num'})) #線圖數據 cpb_line=(consumption_per_buyer.reset_index().rename(columns={0:'Frequency'})) fig2=plt.figure(figsize=[16,6]) ax3=fig2.add_subplot(111) ax4=ax3.twinx() sns.barplot(x='date',y='Num',data=cpb_bar,ax=ax3,alpha=0.8,palette='pastel') sns.pointplot(cpb_line['date'],cpb_line['Frequency'],ax=ax4,markers='D',linestyles='--',color='teal') x=list(range(0,16)) fora,binzip(x,cpb_line['Frequency']): plt.text(a+0.1,b+0.001,'%.2f'%b,ha='center',va='bottom',fontsize=12) plt.title('消費用戶日人均消費次數') output
dau3_df=behavior.groupby(['date','user_id'])['type'].count().reset_index() dau3_df=dau3_df[dau3_df['type']>=3]
#每日高活躍用戶數(每日操作數大于3次) dau3_num=dau3_df.groupby('date')['user_id'].nunique()
#SQL SELECTdate,COUNT(DISTINCTuser_id) FROM (SELECTdate,user_id,COUNT(type) FROMbehavior_sql GROUPBYdate,user_id HAVINGCOUNT(type)>=3)dau3 GROUPBYdate;
fig,ax=plt.subplots(figsize=[16,6]) sns.pointplot(dau3_num.index,dau3_num.values,markers='D',linestyles='--',color='teal') x=list(range(0,16)) fora,binzip(x,dau3_num.values): plt.text(a+0.1,b+300,'%i'%b,ha='center',va='bottom',fontsize=14) plt.title('每日高活躍用戶數') output

#高活躍用戶累計活躍天數分布 dau3_cumsum=dau3_df.groupby('user_id')['date'].count()
#SQL SELECTuser_id,COUNT(date) FROM (SELECTdate,user_id,COUNT(type) FROMbehavior_sql GROUPBYdate,user_id HAVINGCOUNT(type)>=3)dau3 GROUPBYuser_id;
fig,ax=plt.subplots(figsize=[16,6]) ax.set_yscale("log") sns.countplot(dau3_cumsum.values,palette='Set1') forpinax.patches: ax.annotate('{:.2f}%'.format(100*p.get_height()/len(dau3_cumsum.values)),(p.get_x()+0.2,p.get_height()+100)) plt.title('高活躍用戶累計活躍天數分布') output

#每日瀏覽量 pv_daily=behavior[behavior['type']=='pv'].groupby('date')['user_id'].count() #每日訪客數 uv_daily=behavior.groupby('date')['user_id'].nunique()
#SQL #每日瀏覽量 SELECTdate,COUNT(type)pv_dailyFROMbehavior_sql WHEREtype='pv' GROUPBYdate; #每日訪客數 SELECTdate,COUNT(DISTINCTuser_id)uv_dailyFROMbehavior_sql GROUPBYdate;
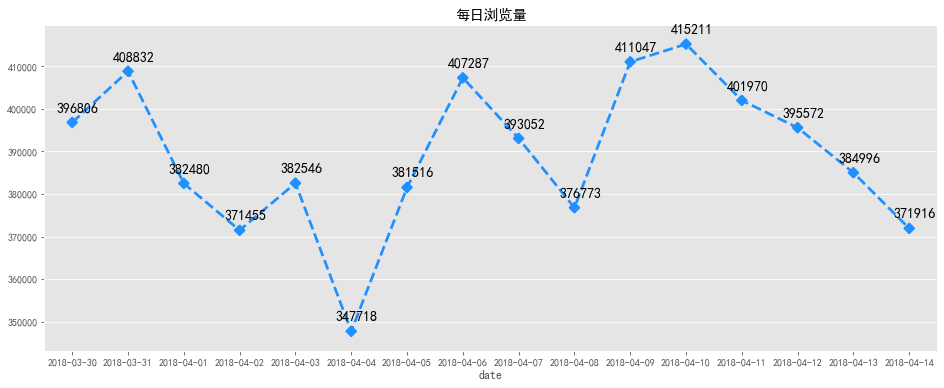
#每日瀏覽量可視化 fig,ax=plt.subplots(figsize=[16,6]) sns.pointplot(pv_daily.index,pv_daily.values,markers='D',linestyles='--',color='dodgerblue') x=list(range(0,16)) fora,binzip(x,pv_daily.values): plt.text(a+0.1,b+2000,'%i'%b,ha='center',va='bottom',fontsize=14) plt.title('每日瀏覽量') output
#每日訪客數可視化 fig,ax=plt.subplots(figsize=[16,6]) sns.pointplot(uv_daily.index,uv_daily.values,markers='H',linestyles='--',color='m') x=list(range(0,16)) fora,binzip(x,uv_daily.values): plt.text(a+0.1,b+500,'%i'%b,ha='center',va='bottom',fontsize=14) plt.title('每日訪客數') output

#每時瀏覽量 pv_hourly=behavior[behavior['type']=='pv'].groupby('hour')['user_id'].count() #每時訪客數 uv_hourly=behavior.groupby('hour')['user_id'].nunique()
#SQL #每時瀏覽量 SELECTdate,COUNT(type)pv_dailyFROMbehavior_sql WHEREtype='pv' GROUPBYhour; #每時訪客數 SELECTdate,COUNT(DISTINCTuser_id)uv_dailyFROMbehavior_sql GROUPBYhour;
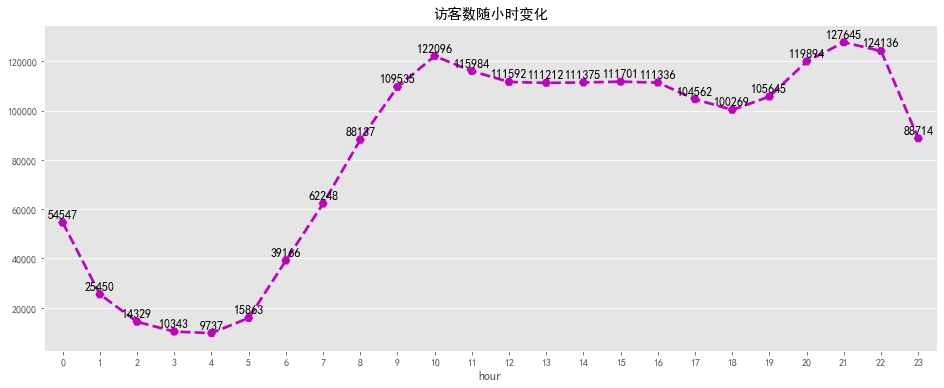
#瀏覽量隨小時變化可視化 fig,ax=plt.subplots(figsize=[16,6]) sns.pointplot(pv_hourly.index,pv_hourly.values,markers='H',linestyles='--',color='dodgerblue') fora,binzip(pv_hourly.index,pv_hourly.values): plt.text(a,b+10000,'%i'%b,ha='center',va='bottom',fontsize=12) plt.title('瀏覽量隨小時變化') output

#訪客數隨小時變化可視化 fig,ax=plt.subplots(figsize=[16,6]) sns.pointplot(uv_hourly.index,uv_hourly.values,markers='H',linestyles='--',color='m') fora,binzip(uv_hourly.index,uv_hourly.values): plt.text(a,b+1000,'%i'%b,ha='center',va='bottom',fontsize=12) plt.title('訪客數隨小時變化') output
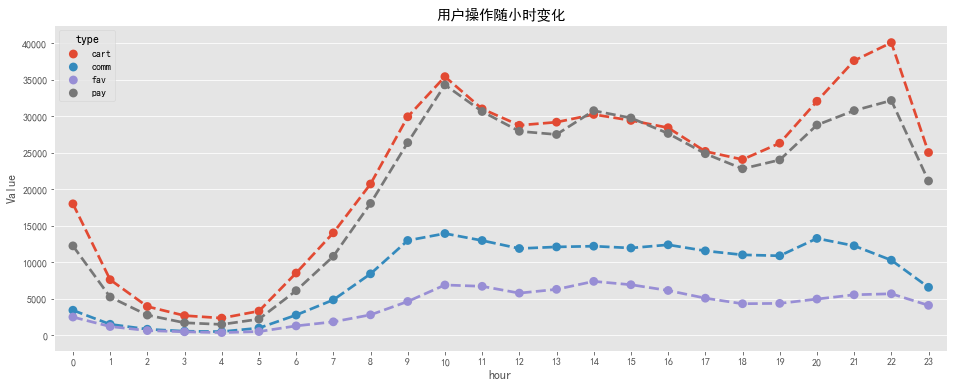
#用戶各操作隨小時變化 type_detail_hour=pd.pivot_table(columns='type',index='hour',data=behavior,aggfunc=np.size,values='user_id') #用戶各操作隨星期變化 type_detail_weekday=pd.pivot_table(columns='type',index='weekday',data=behavior,aggfunc=np.size,values='user_id') type_detail_weekday=type_detail_weekday.reindex(['Monday','Tuesday','Wednesday','Thursday','Friday','Saturday','Sunday'])
#SQL #用戶各操作隨小時變化 SELECThour, SUM(CASEWHENbehavior='pv'THEN1ELSE0END)AS'pv', SUM(CASEWHENbehavior='fav'THEN1ELSE0END)AS'fav', SUM(CASEWHENbehavior='cart'THEN1ELSE0END)AS'cart', SUM(CASEWHENbehavior='pay'THEN1ELSE0END)AS'pay' FROMbehavior_sql GROUPBYhour ORDERBYhour #用戶各操作隨星期變化 SELECTweekday, SUM(CASEWHENbehavior='pv'THEN1ELSE0END)AS'pv', SUM(CASEWHENbehavior='fav'THEN1ELSE0END)AS'fav', SUM(CASEWHENbehavior='cart'THEN1ELSE0END)AS'cart', SUM(CASEWHENbehavior='pay'THEN1ELSE0END)AS'pay' FROMbehavior_sql GROUPBYweekday ORDERBYweekday
tdh_line=type_detail_hour.stack().reset_index().rename(columns={0:'Value'}) tdw_line=type_detail_weekday.stack().reset_index().rename(columns={0:'Value'}) tdh_line=tdh_line[~(tdh_line['type']=='pv')] tdw_line=tdw_line[~(tdw_line['type']=='pv')]
#用戶操作隨小時變化可視化 fig,ax=plt.subplots(figsize=[16,6]) sns.pointplot(x='hour',y='Value',hue='type',data=tdh_line,linestyles='--') plt.title('用戶操作隨小時變化') output
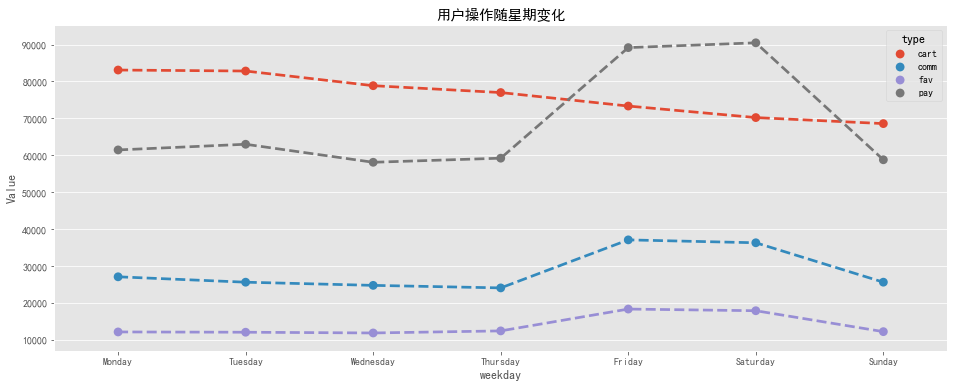
#用戶操作隨星期變化可視化 fig,ax=plt.subplots(figsize=[16,6]) sns.pointplot(x='weekday',y='Value',hue='type',data=tdw_line[~(tdw_line['type']=='pv')],linestyles='--') plt.title('用戶操作隨星期變化') output
4、用戶行為轉化漏斗
#導入相關包 frompyechartsimportoptionsasopts frompyecharts.chartsimportFunnel importmath
behavior['action_time']=pd.to_datetime(behavior['action_time'],format='%Y-%m-%d%H:%M:%S')
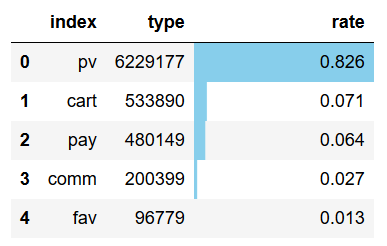
#用戶整體行為分布 type_dis=behavior['type'].value_counts().reset_index() type_dis['rate']=round((type_dis['type']/type_dis['type'].sum()),3)
type_dis.style.bar(color='skyblue',subset=['rate']) output
df_con=behavior[['user_id','sku_id','action_time','type']]
df_pv=df_con[df_con['type']=='pv'] df_fav=df_con[df_con['type']=='fav'] df_cart=df_con[df_con['type']=='cart'] df_pay=df_con[df_con['type']=='pay'] df_pv_uid=df_con[df_con['type']=='pv']['user_id'].unique() df_fav_uid=df_con[df_con['type']=='fav']['user_id'].unique() df_cart_uid=df_con[df_con['type']=='cart']['user_id'].unique() df_pay_uid=df_con[df_con['type']=='pay']['user_id'].unique()
pv - buy
fav_cart_list=set(df_fav_uid)|set(df_cart_uid) pv_pay_df=pd.merge(left=df_pv,right=df_pay,how='inner',on=['user_id','sku_id'],suffixes=('_pv','_pay')) pv_pay_df=pv_pay_df[(~pv_pay_df['user_id'].isin(fav_cart_list))&(pv_pay_df['action_time_pv']'action_time_pay'])]
uv=behavior['user_id'].nunique() pv_pay_num=pv_pay_df['user_id'].nunique() pv_pay_data=pd.DataFrame({'type':['瀏覽','付款'],'num':[uv,pv_pay_num]}) pv_pay_data['conversion_rates']=(round((pv_pay_data['num']/pv_pay_data['num'][0]),4)*100)
attr1=list(pv_pay_data.type) values1=list(pv_pay_data.conversion_rates) data1=[[attr1[i],values1[i]]foriinrange(len(attr1))]
#用戶行為轉化漏斗可視化 pv_pay=(Funnel(opts.InitOpts(width="600px",height="300px")) .add( series_name="", data_pair=data1, gap=2, tooltip_opts=opts.TooltipOpts(trigger="item",formatter="{b}:{c}%"), label_opts=opts.LabelOpts(is_show=True,position="inside"), itemstyle_opts=opts.ItemStyleOpts(border_color="#fff",border_width=1) ) .set_global_opts(title_opts=opts.TitleOpts(title="用戶行為轉化漏斗圖")) ) pv_pay.render_notebook() output
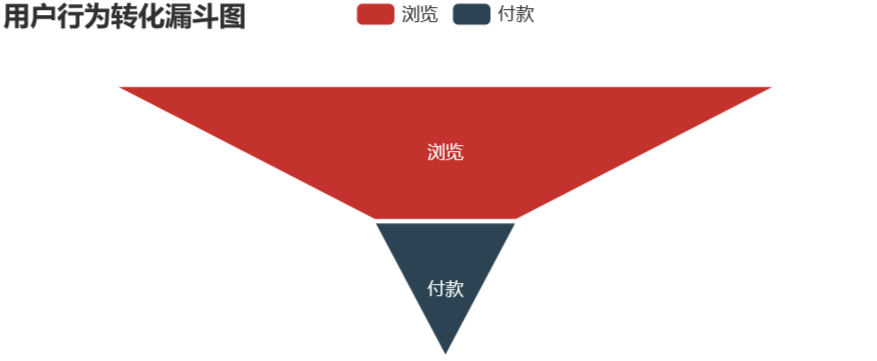
pv - cart - pay
pv_cart_df=pd.merge(left=df_pv,right=df_cart,how='inner',on=['user_id','sku_id'],suffixes=('_pv','_cart')) pv_cart_df=pv_cart_df[pv_cart_df['action_time_pv']'action_time_cart']] pv_cart_df=pv_cart_df[~pv_cart_df['user_id'].isin(df_fav_uid)] pv_cart_pay_df=pd.merge(left=pv_cart_df,right=df_pay,how='inner',on=['user_id','sku_id']) pv_cart_pay_df=pv_cart_pay_df[pv_cart_pay_df['action_time_cart']'action_time']]
uv=behavior['user_id'].nunique() pv_cart_num=pv_cart_df['user_id'].nunique() pv_cart_pay_num=pv_cart_pay_df['user_id'].nunique() pv_cart_pay_data=pd.DataFrame({'type':['瀏覽','加購','付款'],'num':[uv,pv_cart_num,pv_cart_pay_num]}) pv_cart_pay_data['conversion_rates']=(round((pv_cart_pay_data['num']/pv_cart_pay_data['num'][0]),4)*100)
attr2=list(pv_cart_pay_data.type) values2=list(pv_cart_pay_data.conversion_rates) data2=[[attr2[i],values2[i]]foriinrange(len(attr2))]
#用戶行為轉化漏斗可視化 pv_cart_buy=(Funnel(opts.InitOpts(width="600px",height="300px")) .add( series_name="", data_pair=data2, gap=2, tooltip_opts=opts.TooltipOpts(trigger="item",formatter="{b}:{c}%"), label_opts=opts.LabelOpts(is_show=True,position="inside"), itemstyle_opts=opts.ItemStyleOpts(border_color="#fff",border_width=1) ) .set_global_opts(title_opts=opts.TitleOpts(title="用戶行為轉化漏斗圖")) ) pv_cart_buy.render_notebook() output
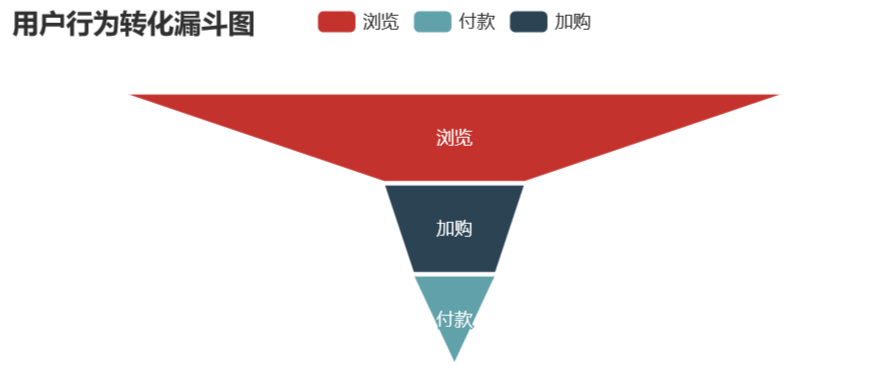
pv - fav - pay
pv_fav_df=pd.merge(left=df_pv,right=df_fav,how='inner',on=['user_id','sku_id'],suffixes=('_pv','_fav')) pv_fav_df=pv_fav_df[pv_fav_df['action_time_pv']'action_time_fav']] pv_fav_df=pv_fav_df[~pv_fav_df['user_id'].isin(df_cart_uid)] pv_fav_pay_df=pd.merge(left=pv_fav_df,right=df_pay,how='inner',on=['user_id','sku_id']) pv_fav_pay_df=pv_fav_pay_df[pv_fav_pay_df['action_time_fav']'action_time']]
uv=behavior['user_id'].nunique() pv_fav_num=pv_fav_df['user_id'].nunique() pv_fav_pay_num=pv_fav_pay_df['user_id'].nunique() pv_fav_pay_data=pd.DataFrame({'type':['瀏覽','收藏','付款'],'num':[uv,pv_fav_num,pv_fav_pay_num]}) pv_fav_pay_data['conversion_rates']=(round((pv_fav_pay_data['num']/pv_fav_pay_data['num'][0]),4)*100)
attr3=list(pv_fav_pay_data.type) values3=list(pv_fav_pay_data.conversion_rates) data3=[[attr3[i],values3[i]]foriinrange(len(attr3))]
#用戶行為轉化漏斗可視化 pv_fav_buy=(Funnel(opts.InitOpts(width="600px",height="300px")) .add( series_name="", data_pair=data3, gap=2, tooltip_opts=opts.TooltipOpts(trigger="item",formatter="{b}:{c}%"), label_opts=opts.LabelOpts(is_show=True,position="inside"), itemstyle_opts=opts.ItemStyleOpts(border_color="#fff",border_width=1) ) .set_global_opts(title_opts=opts.TitleOpts(title="用戶行為轉化漏斗圖")) ) pv_fav_buy.render_notebook() output

pv - fav - cart - pay
pv_fav=pd.merge(left=df_pv,right=df_fav,how='inner',on=['user_id','sku_id'],suffixes=('_pv','_fav')) pv_fav=pv_fav[pv_fav['action_time_pv']'action_time_fav']] pv_fav_cart=pd.merge(left=pv_fav,right=df_cart,how='inner',on=['user_id','sku_id']) pv_fav_cart=pv_fav_cart[pv_fav_cart['action_time_fav']
uv=behavior['user_id'].nunique() pv_fav_n=pv_fav['user_id'].nunique() pv_fav_cart_n=pv_fav_cart['user_id'].nunique() pv_fav_cart_pay_n=pv_fav_cart_pay['user_id'].nunique() pv_fav_cart_pay_data=pd.DataFrame({'type':['瀏覽','收藏','加購','付款'],'num':[uv,pv_fav_n,pv_fav_cart_n,pv_fav_cart_pay_n]}) pv_fav_cart_pay_data['conversion_rates']=(round((pv_fav_cart_pay_data['num']/pv_fav_cart_pay_data['num'][0]),4)*100)
attr4=list(pv_fav_cart_pay_data.type) values4=list(pv_fav_cart_pay_data.conversion_rates) data4=[[attr4[i],values4[i]]foriinrange(len(attr4))]
#用戶行為轉化漏斗可視化 pv_fav_buy=(Funnel(opts.InitOpts(width="600px",height="300px")) .add( series_name="", data_pair=data4, gap=2, tooltip_opts=opts.TooltipOpts(trigger="item",formatter="{b}:{c}%"), label_opts=opts.LabelOpts(is_show=True,position="inside"), itemstyle_opts=opts.ItemStyleOpts(border_color="#fff",border_width=1) ) .set_global_opts(title_opts=opts.TitleOpts(title="用戶行為轉化漏斗圖")) ) pv_fav_buy.render_notebook() output

不同路徑用戶消費時間間隔分析:
pv - cart - pay
pcp_interval=pv_cart_pay_df.groupby(['user_id','sku_id']).apply(lambdax:(x.action_time.min()-x.action_time_cart.min())).reset_index() pcp_interval['interval']=pcp_interval[0].apply(lambdax:x.seconds)/3600 pcp_interval['interval']=pcp_interval['interval'].apply(lambdax:math.ceil(x))
fig,ax=plt.subplots(figsize=[16,6]) sns.countplot(pcp_interval['interval'],palette='Set1') forpinax.patches: ax.annotate('{:.2f}%'.format(100*p.get_height()/len(pcp_interval['interval'])),(p.get_x()+0.1,p.get_height()+100)) ax.set_yscale("log") plt.title('pv-cart-pay路徑用戶消費時間間隔') output
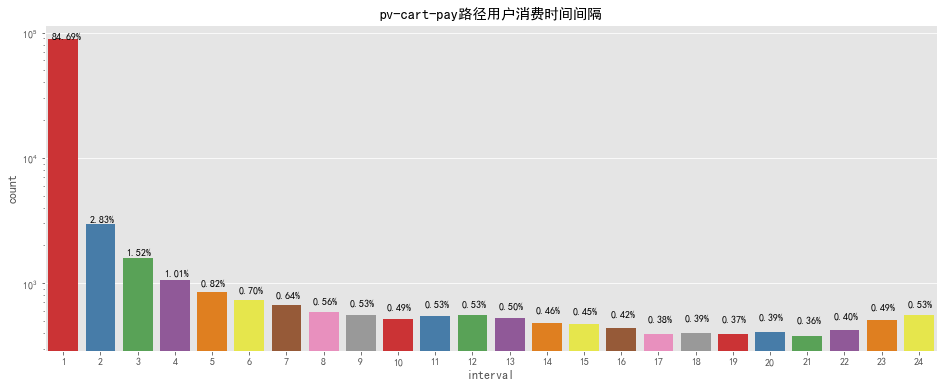
pv - fav - pay
pfp_interval=pv_fav_pay_df.groupby(['user_id','sku_id']).apply(lambdax:(x.action_time.min()-x.action_time_fav.min())).reset_index() pfp_interval['interval']=pfp_interval[0].apply(lambdax:x.seconds)/3600 pfp_interval['interval']=pfp_interval['interval'].apply(lambdax:math.ceil(x))
fig,ax=plt.subplots(figsize=[16,6]) sns.countplot(pfp_interval['interval'],palette='Set1') forpinax.patches: ax.annotate('{:.2f}%'.format(100*p.get_height()/len(pfp_interval['interval'])),(p.get_x()+0.1,p.get_height()+10)) ax.set_yscale("log") plt.title('pv-fav-pay路徑用戶消費時間間隔') output
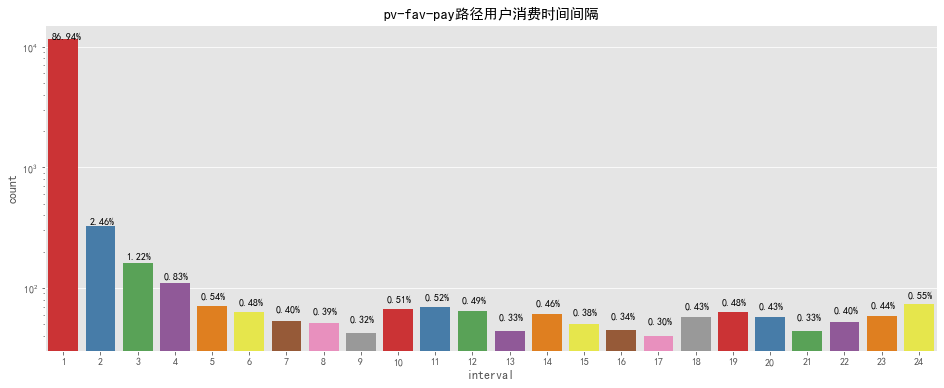
#SQL #漏斗圖 SELECTtype,COUNT(DISTINCTuser_id)user_num FROMbehavior_sql GROUPBYtype ORDERBYCOUNT(DISTINCTuser_id)DESC SELECTCOUNT(DISTINCTb.user_id)ASpv_fav_num,COUNT(DISTINCTc.user_id)ASpv_fav_pay_num FROM ((SELECTDISTINCTuser_id,sku_id,action_timeFROMusersWHEREtype='pv')ASa LEFTJOIN (SELECTDISTINCTuser_id,sku_id,action_timeFROMusersWHEREtype='fav' ANDuser_idNOTIN (SELECTDISTINCTuser_id FROMbehavior_sql WHEREtype='cart'))ASb ONa.user_id=b.user_idANDa.sku_id=b.sku_idANDa.action_time<=?b.action_time LEFT?JOIN (SELECT?DISTINCT?user_id,sku_id,item_category,times_new?FROM?users?WHERE?behavior_type='pay')ASc ONb.user_id=c.user_idANDb.sku_id=c.sku_idANDANDb.action_time<=?c.action_time); 比較四種不同的轉化方式,最有效的轉化路徑為瀏覽直接付款轉化率為21.46%,其次為瀏覽加購付款,轉化率為12.47%,可以發現隨著結算方式越來越復雜轉化率越來越低。 加購的方式比收藏購買的方式轉化率要高,推其原因為購物車接口進入方便且可以做不同商家比價用,而收藏則需要更繁瑣的操作才可以查看到商品,因此轉化率較低。 可以優化商品搜索功能,提高商品搜索準確度、易用性,減少用戶搜索時間。 根據用戶喜好在首頁進行商品推薦,優化重排商品詳情展示頁,提高顧客下單欲望,提供一鍵購物等簡化購物步驟的功能。 客服也可以留意加購及關注用戶,適時推出優惠福利及時解答用戶問題,引導用戶購買以進一步提高轉化率。 對于用戶消費時間間隔,可以通過限時領券購買、限時特惠價格等進一步縮短用戶付款時間,提高訂單量。
5、用戶留存率分析
#留存率 first_day=datetime.date(datetime.strptime('2018-03-30','%Y-%m-%d')) fifth_day=datetime.date(datetime.strptime('2018-04-03','%Y-%m-%d')) tenth_day=datetime.date(datetime.strptime('2018-04-08','%Y-%m-%d')) fifteenth_day=datetime.date(datetime.strptime('2018-04-13','%Y-%m-%d')) #第一天新用戶數 user_num_first=behavior[behavior['date']==first_day]['user_id'].to_frame() #第五天留存用戶數 user_num_fifth=behavior[behavior['date']==fifth_day]['user_id'].to_frame() #第十留存用戶數 user_num_tenth=behavior[behavior['date']==tenth_day]['user_id'].to_frame() #第十五天留存用戶數 user_num_fifteenth=behavior[behavior['date']==fifteenth_day]['user_id'].to_frame()
#第五天留存率 fifth_day_retention_rate=round((pd.merge(user_num_first,user_num_fifth).nunique()) /(user_num_first.nunique()),4).user_id #第十天留存率 tenth_day_retention_rate=round((pd.merge(user_num_first,user_num_tenth).nunique()) /(user_num_first.nunique()),4).user_id #第十五天留存率 fifteenth_day_retention_rate=round((pd.merge(user_num_first,user_num_fifteenth).nunique()) /(user_num_first.nunique()),4).user_id
#留存率可視化 fig,ax=plt.subplots(figsize=[16,6]) sns.barplot(x='n日后留存率',y='Rate',data=retention_rate, palette='Set1') x=list(range(0,3)) fora,binzip(x,retention_rate['Rate']): plt.text(a,b+0.001,'%.2f%%'%(b*100),ha='center',va='bottom',fontsize=12) plt.title('用戶留存率') output
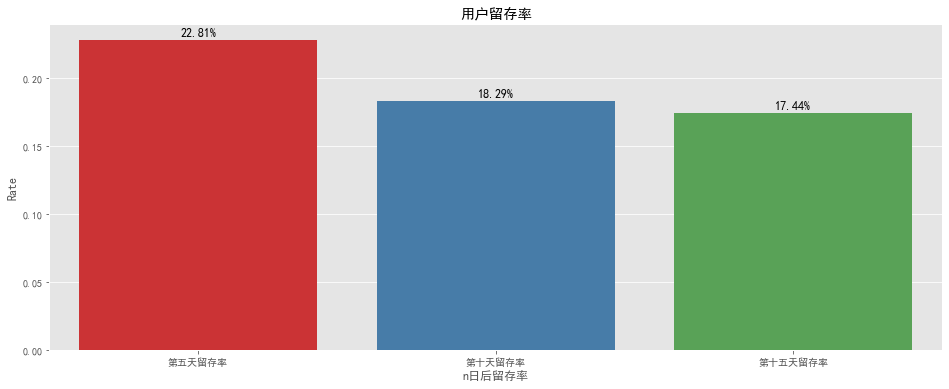
#SQL #n日后留存率=(注冊后的n日后還登錄的用戶數)/第一天新增總用戶數 createtableretention_rateasselectcount(distinctuser_id)asuser_num_firstfrombehavior_sql wheredate='2018-03-30'; altertableretention_rateaddcolumnuser_num_fifthINTEGER; updateretention_ratesetuser_num_fifth= (selectcount(distinctuser_id)frombehavior_sql wheredate='2018-04-03'anduser_idin(SELECTuser_idFROMbehavior_sql WHEREdate='2018-03-30')); altertableretention_rateaddcolumnuser_num_tenthINTEGER; updateretention_ratesetuser_num_tenth= (selectcount(distinctuser_id)frombehavior_sql wheredate='2018-04-08'anduser_idin(SELECTuser_idFROMbehavior_sql WHEREdate='2018-03-30')); altertableretention_rateaddcolumnuser_num_fifteenthINTEGER; updateretention_ratesetuser_num_fifteenth= (selectcount(distinctuser_id)frombehavior_sql wheredate='2018-04-13'anduser_idin(SELECTuser_idFROMbehavior_sql WHEREdate='2018-03-30')); SELECTCONCAT(ROUND(100*user_num_fifth/user_num_first,2),'%')ASfifth_day_retention_rate, CONCAT(ROUND(100*user_num_tenth/user_num_first,2),'%')AStenth_day_retention_rate, CONCAT(ROUND(100*user_num_fifteenth/user_num_first,2),'%')ASfifteenth_day_retention_rate fromretention_rate;
6、商品銷量分析
#商品總數 behavior['sku_id'].nunique() output
239007
#商品被購前產生平均操作次數 sku_df=behavior[behavior['sku_id'].isin(behavior[behavior['type']=='pay']['sku_id'].unique())].groupby('sku_id')['type'].value_counts().unstack(fill_value=0) sku_df['total']=sku_df.sum(axis=1) sku_df['avg_beha']=round((sku_df['total']/sku_df['pay']),2) fig,ax=plt.subplots(figsize=[8,6]) sns.scatterplot(x='avg_beha',y='pay',data=sku_df,palette='Set1') ax.set_xscale("log") ax.set_yscale("log") plt.xlabel('平均操作次數') plt.ylabel('銷量') output
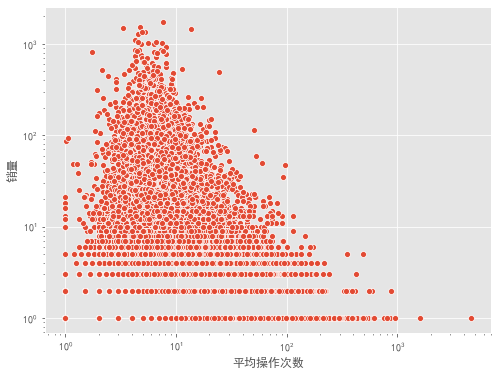
- 左下角操作少購買少,屬于冷門購買頻率較低的產品。
- 左上角操作少購買多,屬于快消類產品,可選擇品牌少,少數品牌壟斷的行業。
- 右下角操作多購買少,品牌多,但是購買頻率低,應為貴重物品類。
- 右上角操作多購買多,大眾品牌,可選多,被購買頻次高。
#商品銷量排行 sku_num=(behavior[behavior['type']=='pay'].groupby('sku_id')['type'].count().to_frame() .rename(columns={'type':'total'}).reset_index()) #銷量大于1000的商品 topsku=sku_num[sku_num['total']>1000].sort_values(by='total',ascending=False) #單個用戶共購買商品種數 sku_num_per_user=(behavior[behavior['type']=='pay']).groupby(['user_id'])['sku_id'].nunique() topsku.set_index('sku_id').style.bar(color='skyblue',subset=['total']) output

#SQL #sku銷量排行 SELECTsku_id,COUNT(type)sku_numFROMbehavior_sql WHEREtype='pay' GROUPBYsku_id HAVINGsku_num>1000 ORDERBYsku_numDESC;
7、RFM用戶分層
#RFM #由于缺少M(金額)列,僅通過R(最近一次購買時間)和F(消費頻率)對用戶進行價值分析 buy_group=behavior[behavior['type']=='pay'].groupby('user_id')['date'] #將2018-04-13作為每個用戶最后一次購買時間來處理 final_day=datetime.date(datetime.strptime('2018-04-14','%Y-%m-%d')) #最近一次購物時間 recent_buy_time=buy_group.apply(lambdax:final_day-x.max()) recent_buy_time=recent_buy_time.reset_index().rename(columns={'date':'recent'}) recent_buy_time['recent']=recent_buy_time['recent'].map(lambdax:x.days) #近十五天內購物頻率 buy_freq=buy_group.count().reset_index().rename(columns={'date':'freq'}) RFM=pd.merge(recent_buy_time,buy_freq,on='user_id')
RFM['R']=pd.qcut(RFM.recent,2,labels=['1','0']) #天數小標簽為1天數大標簽為0 RFM['F']=pd.qcut(RFM.freq.rank(method='first'),2,labels=['0','1']) #頻率大標簽為1頻率小標簽為0 RFM['RFM']=RFM['R'].astype(int).map(str)+RFM['F'].astype(int).map(str) dict_n={'01':'重要保持客戶', '11':'重要價值客戶', '10':'重要挽留客戶', '00':'一般發展客戶'} #用戶標簽 RFM['用戶等級']=RFM['RFM'].map(dict_n) RFM_pie=RFM['用戶等級'].value_counts().reset_index() RFM_pie['Rate']=RFM_pie['用戶等級']/RFM_pie['用戶等級'].sum() fig,ax=plt.subplots(figsize=[16,6]) plt.pie(RFM_pie['Rate'],labels=RFM_pie['index'],startangle=90,autopct="%1.2f%%", counterclock=False,colors=['yellowgreen','gold','lightskyblue','lightcoral']) plt.axis('square') plt.title('RFM用戶分層') output

- 對于重要價值客戶來說,要提高該部分用戶的滿意度,服務升級,發放特別福利,增大該部分用戶留存率,在做運營推廣時也要給與特別關注,避免引起用戶反感。
- 對于重要保持客戶,他們購物頻次較高,但最近一段時間沒有消費,可以推送相關其他商品,發放優惠卷、贈品和促銷信息等,喚回該部分用戶。
- 對于重要挽留客戶,他們最近消費過,但購物頻次較低,可以通過問卷有禮的方式找出其對平臺的不滿,提升購物體驗,增大用戶粘性。
- 對于一般發展客戶,做到定期發送郵件或短信喚回,努力將其轉化為重要保持客戶或重要挽留客戶。
#SQL #RFM CREATEVIEWRF_tableAS SELECTuser_id,DATEDIFF('2018-04-14',MAX(date))ASR_days, COUNT(*)ASF_count FROMbehavior_sqlWHEREtype='pay'GROUPBYuser_id; SELECTAVG(R_days),AVG(F_count) FROMRF_table createviewRF_layeras SELECTuser_id,(CASEWHENR_days"重要價值客戶" WHENR=1andF=0THEN"重要挽留客戶" WHENR=0andF=1THEN"重要保持客戶" WHENR=0andF=0THEN"一般發展客戶"ELSE0END)as用戶價值 FROMRF_layer; SELECT*FROMcustomer_value;
5、總結
1.可以增加渠道推廣投入,進行精準人群推廣,推出新用戶福利,吸引新用戶,推出團購、分享有禮等活動促進老帶新,推出促銷活動刺激老用戶,提高訪客數和瀏覽量。提高產品質量,提高商品詳情頁對用戶的吸引力,降低跳失率。 2.根據用戶操作隨時間變化規律來開展營銷活動,使活動更容易觸達用戶,在用戶訪問高峰期多推送用戶感興趣商品。 3.復購率較低,說明用戶對平臺購物體驗不滿,需要找出用戶槽點,提高用戶購物滿意度,優化商品推送機制,對老用戶給予特別福利,提高他們所享受權益。轉化率也偏低,需要改善平臺搜索機制降低提高搜索效率,優化購物路徑降低購物復雜度,改善商品詳情信息展示方式便于信息的獲取。 4.留存率相對穩定,為進一步提高留存率,可以定期推出秒殺活動,推出專享優惠券,推出簽到有禮環節,增加用戶瀏覽時長和深度,提高用戶粘性。分析用戶對產品的真實使用感受與評價,提高用戶忠誠度。 5.通過RFM對用戶進行分層,將用戶從一個整體拆分成特征明顯的群體,有針對性的采取不同的營銷方法進行精準化營銷,用有限的公司資源優先服務于公司最重要的客戶。審核編輯 :李倩
-
SQL
+關注
關注
1文章
767瀏覽量
44173 -
python
+關注
關注
56文章
4798瀏覽量
84802 -
數據集
+關注
關注
4文章
1208瀏覽量
24731
原文標題:完整案例!Python + SQL 京東用戶行為分析
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
淺談SQL優化小技巧
如何使用SQL進行數據分析
SQL與NoSQL的區別
大數據從業者必知必會的Hive SQL調優技巧
行為分析智能監測攝像機

IP 地址在 SQL 注入攻擊中的作用及防范策略
如何在SQL中創建觸發器
恒訊科技分析:sql數據庫怎么用?
什么是 Flink SQL 解決不了的問題?
AI行為識別視頻監控系統 Python

SQL全外連接剖析





 工商網監
工商網監
評論