 UDP和TCP的區別
UDP和TCP的區別
UDP 和 TCP 的區別
在上一則文章中,對 TCP 的三次握手建立連接和四次揮手釋放連接進行了詳細地闡述,本節教程針對于 TCP 的其他內容進行講解,首先是同處于傳輸層協議的UDP協議,這兩者有什么區別與聯系呢?
相同點那就是說:UDP 和 TCP 是 TCP/IP 體系結構運輸層中的兩個重要協議,下圖是TCP/IP的體系結構圖:
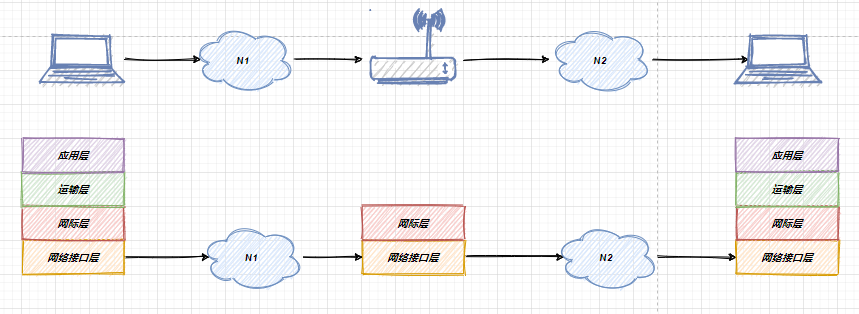
額外補充的一點就是說,在 TCP和 UDP 協議下層的IP協議,IP協議可以為各種網絡應用提供服務,使用IP層協議互連不同的網絡接口,下面是一個結構圖:

image-20210718234432031
TCP和UDP的使用頻率也僅次于位于網際層的IP協議。
UDP也稱之為是用戶數據報協議,而TCP呢,被稱之為傳輸控制協議,比較顯著的一點區別就是說,UDP 是無連接的,而TCP 是面向連接的,下面是兩種通信方式通信的一個示意圖:

image-20210718235508609
如上圖所示,對于UDP來講,其無需建立連接就能夠進行數據傳輸,而對于 TCP來講,其在進行數據傳輸之前,需要進行“三報文握手”建立連接,然后才進行數據傳輸,數據傳輸完成之后,還需要進行“四報文揮手”釋放連接。
也正是因為UDP無連接的特性,對于UDP來說,其支持 單播、多播以及廣播 ,而對于TCP來說,因為三次握手建立的的連接,它有了一條可靠的信道,它也就僅僅支持 單播 ,下面是兩個通信方式的示意圖:

image-20210719000338512
緊接著,分析一下UDP和TCP數據傳輸的詳細過程

image-20210706213718285
可以看到,對于 UDP來講,其是面向應用報文的,發送方的應用進程將應用報文交付給傳輸層的UDP,UDP直接給應用層報文添加一個UDP首部,使之成為UDP用戶數據報,然后進行發送,接收方的UDP收到該UDP用戶數據報后,去掉UDP首部,將應用層報文交付給應用進程,換言之,就是說UDP對應用進程交下來的報文既不合并也不拆分,而是保留這些報文的邊界,也就是說,UDP是面向應用報文的。
緊接著,上圖的右邊是TCP的數據發送流程,發送方的TCP把應用進程交付下來的數據塊看作是一連串的無結構的字節流,TCP并不知道這些待傳送的字節流的含義,僅僅將他們編號,并存儲在自己的發送緩存中,TCP根據發送策略,從發送緩存中提取出一定數量的字節,構建TCP報文段并發送,接收方的TCP一方面從接收到的TCP報文中取出數據載荷部分并存儲在接收緩存中,一方面將接收緩存中的一些字節交付給應用進程,TCP不保證所收到的數據塊與發送方應用進程所發出的數據塊具有對應大小的關系,但是呢,接收方應用進程收到的字節流必須和發送方應用進程發出的字節流完全一樣,與此同時,接收方應用進程必須有能力識別收到的字節流,把它還原成有意義的應用層數據。也就是說,TCP是面向字節流的,這也正是TCP實現可靠傳輸、流量控制以及擁塞控制的基礎。
緊接著,再來看另外一個對比,其示意圖如下所示:

image-20210706215655559
就是說對于TCP/IP體系架構來說,網際層 向上提供無連接不可靠的傳輸服務 ,而對于 UDP來說,其所再運輸層向上提供無連接不可靠的傳輸服務,這樣一種機制也就造成了數據包的丟失以及誤碼現象,但是對于UDP傳輸來講,它就僅僅是丟棄其他什么也不做;但是對于TCP傳輸協議來講呢,網際層 向上提供無連接不可靠的傳輸服務 ,TCP所處的傳輸層向上提供面向連接的可靠傳輸服務,這也就實現了基于TCP連接的可靠信道,不會出現傳輸差錯,誤碼,丟失,亂序以及重復的問題。
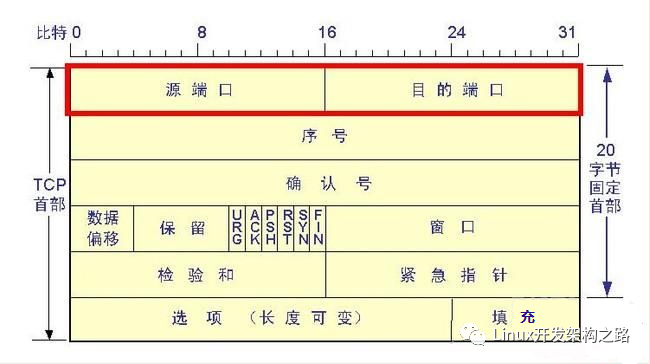
下面對比一下UDP和TCP報文的首部,一個UDP用戶數據報由首部和數據載荷兩部分組成,TCP報文段也是由首部和數據載荷部分組成,其中UDP用戶數據報首部僅僅8個字節,僅僅包含源端口,目的端口,長度以及校驗和。而對于TCP來講,其首部包含的信息較多,其首部大小最小為20字節,最大為60字節。

image-20210707133649551
小結
綜上所述,針對于TCP和UDP來說兩者的特點與區別匯總如下:
用戶數據報協議UDP
- 無連接
- 支持一對一,一對多,多對一和多對多交互通信
- 對應用層交付的報文直接打包
- 盡最大努力交付,也就是不可靠;不使用流量控制和擁塞控制
- 首部開銷小,僅 8 字節
傳輸控制層協議TCP
- 面向連接
- 每一條
TCP連接只能有兩個端點,只能是一對一通信 - 面向字節流
- 可靠傳輸,使用流量控制和擁塞控制
- 首部最小20字節,最大60字節
TCP 的流量控制
滑動窗口的引出
在上一則文章敘述 TCP三次握手和四次揮手的那個過程中,我們知道對于TCP的通信來講,是每發送一個數據,都要進行一次確認應答。當上一個數據包收到應答了,再發送下一個數據包,這樣一個通信的流程是如下所示的:

image-20210711105416703
通過上述這個示意圖也可以看出,如果說每次發送一個數據包應答一次再發送下一個數據包,這樣的效率也過于低下了,這時候也就引入了滑動窗口的概念。那有了窗口,就可以指定窗口的大小了,窗口大小也就是指無需要等待應答,而可以繼續發送數據的最大值,比如說如果當前的窗口是 3 的話,那么發送方就可以連續發送三個TCP段,而且如上圖所示如果其中的一個ACK丟失了,那么可以通過下一個確認應答進行確認,比方說,如果ACK 600丟失了,那么ACK 700的確認應答就可以替代ACK 600的確認應答。

image-20210711233912755
流量控制
根據上述引出的滑動窗口機制,我們知道,因為此機制的原因,我們能夠使得傳輸速率更快了,但是如果發送方的發送速率過快,那么接收方就可能來不及處理,這就會造成數據的丟失,而即將敘述的流量控制,就是讓 發送方的發送速率不要太快,要讓接收方能夠來得及接收 ,而利用滑動窗口機制可以很方便地在 TCP 連接上實現對發送方的流量控制。
在介紹流量控制是如何實現的之前,先來分別看看發送方和接收方的滑動窗口,首先來介紹發送方的 窗口 ,那對于發送方來講,這個窗口有多大呢?這是取決于接收方能夠處理多大的數據,也就是說在發送數據之前,接受方會給發送方報一個 窗口大小 ,這個窗口大小也就是 Advertised window ,具體是什么意思呢?看如下示意圖:

image-20210727010803750
- LastByteAcked: 第一部分和第二部分的分界線
- LastByteSent: 第二部分和第三部分的分界線
通過示意圖也可以看出來,對于Advertised window來說,這個窗口的大小應該等于 第二部分+第三部分 。
對于接收端來講,它的緩存里面記錄的內容要簡單一些,示意圖如下所示:

image-20210712002717332
其中,MaxRcvBuffer也正如其字面意思,就是最大緩存的量,對于接收方的窗口大小也就如藍色方框所示,說到這里呢,也就引入了一個問題,就是說:接收窗口和發送窗口的大小是相等的么?
答案是 并不是完全相等,接收窗口的大小是約等于發送窗口的大小的 。
原因在于滑動窗口不是一成不變的,比如說,當接收方的應用進程讀取數據比較快的時候,這樣的話接收窗口就會很快空出來,但是要把這一消息告訴發送方,需要經過網絡傳輸,那么這樣依賴就會出現不一致的情況,所以說,是約等于的。
發送方和接收方的窗口就基本這些內容,接下來是關于流量控制的內容:
先假設窗口不變,也就是9,當 4 的確認來的時候,窗口會向右移動一個,整個時候,13這個序號的包也可以發送了。

image-20210726001856097
如果說這個時候,發送方發送的過快,會將第三部分的10、11、12、13全部發送完畢,之后就停止發送了,未發送可發送部分為0

image-20210726002732414
這個時候,只有當包 5 的確認到達的時候,在客戶端相當于窗口再滑動了一格,這個時候,第 14 個包才可以發送。

image-20210726003909427
如果接收方處理的太慢了,那么就可以通過確認信息來調整窗口的大小,現在假設一種比較極端的情況,就是說接收端一直不處理數據,那么當數據包6的確認到達之后,窗口大小就不能是 9了,就需要縮小一個變為8,下方是發送方在收到一個6的確認包之后,窗口的變化情況,可以看到此時窗口的變化方式并不是向右移動一格,而是窗口的左邊向由縮進一格,窗口的整體大小并沒有發生變化。

image-20210726004657587
如果說接收端一直不處理數據,那么隨著確認的包越來越多,窗口也就越來越小,直到為0,下方是接收方窗口的變化情況:

image-20210726004911416
與上圖接收方對應的發送窗口的情況如下如所示,當 14 的確認到達發送端的時候,發送端的窗口也調整為0,停止發送。

image-20210726005438132
如果到這種情況的話,發送方會定時發送窗口探測數據包,看是否有機會調整窗口的大小。當接收方比較慢的時候,,要防止低能窗口綜合征,別空出一個字節來就趕快告訴發送方,然后馬上又填滿了,可以當窗口太小的時候,不更新窗口,直到達到一定大小,或者緩沖區一半為空,才更新窗口。
上述就是TCP中的流量控制。
TCP 擁塞控制
在某段時間,如果對網絡中某一資源的需求超過了該資源所能夠提供的可用部分,網絡性能就要變壞,這種情況就叫做 擁塞 。
在計算機網絡中的鏈路容量(即帶寬)、交換結點中的緩存和處理機等,都是網絡的資源
如果出現擁塞而不進行控制,整個網絡的吞吐量將隨著輸入負荷的增大而下降。
下圖是理想擁塞控制,實際的擁塞控制,和無擁塞控制的一個曲線圖,曲線如下所示:

image-20210726233128809
TCP 的擁塞控制算法主要涉及到四個,分別是:
- 慢開始算法
- 擁塞避免算法
- 快重傳算法
- 快恢復算法
在講解這四種擁塞控制算法之前,先假定如下條件:
- 數據是單方向傳送的,而另一個方向只傳送確認
- 接收方總有足夠大的緩存空間,因而發送方發送的窗口的大小由網絡的擁塞程度來決定
- 以最大報文段 MSS 的個數作為討論問題的單位,而不是以字節為單位
也就是說現在發送方和接收方兩者之間的通信是這樣子的,具體過程如下圖所示:

image-20210726235358470
發送方向接收方發送一個 TCP 數據報文段,而接收方收到整個報文段之后,就向發送方回一個TCP確認報文段
也就是說,發送方維護一個叫做擁塞窗口cwnd的狀態變量,其值取決于網絡的擁塞程度,并且動態變化。
- 擁塞窗口cwnd的維護原則:只要網絡沒有出現擁塞,擁塞窗口的值就增大一些;但是只要網絡中出現擁塞,擁塞窗口就減小一些。
- 判斷出現網絡擁塞的依據:沒有按時收到應當達到的確認報文(也就是發生了超時重傳)。
發送方將擁塞窗口作為發送窗口,也就是 swnd = cwdn
維護一個慢開始門限ssthresh狀態變量:
- 當 cwnd < ssthresh 時,開始使用慢開始算法
- 當 cwnd > ssthresh 時,停止使用慢開始算法而改用擁塞避免算法
- 當 cwnd = ssthresh 時,既可以使用慢開始算法,也可以使用擁塞避免算法
慢開始和擁塞避免算法
為了更改的闡述慢開始算法,我們給出下面這樣一個折線圖,其中折線圖的橫坐標表示的是傳輸輪次,而一個傳輸輪次指的是發送方給接收方發送數據報文段之后,接收方給發送方回相應的確認報文段,一個傳輸輪次所經歷的時間,其實就是往返時間,縱坐標是擁塞窗口,這是一個動態變化的值。
在 TCP 雙方建立邏輯連接關系時,擁塞窗口的值被設置為1 ,另外還需要設置慢開始門限的初始值為16,在執行慢開始算法時,發送方每收到一個接收方發來的確認報文段時,就將擁塞窗口值+1,然后再開始下一輪次的傳輸,當擁塞窗口值增加到慢開始門限值時,就改為執行擁塞避免算法。

image-20210727001131965
上述的折線圖該如何解釋呢?就是說,如果最開始,發送方的擁塞窗口值為1,發送方發送一個TCP 報文段至接收方,接收方收到之后,發送TCP確認報文段至發送方,當發送方收到這個確認報文段之后,就將擁塞窗口的值加1,因為在這里,擁塞窗口的值就等于發送窗口的值,所以,此時發送窗口的值為 2,那么發送方就能夠發送兩個報文段到接收方,當發送方收到這兩個報文段的確認報文段后,就將擁塞窗口設置為 4,此時發送方就能發送4個TCP報文段至接收方,按照這樣一種原理,圖中數據包每增加一個輪次,擁塞窗口的值就呈現指數增長,直至增加到慢開始門限值,也就是 16,此時改為擁塞避免算法。
何為擁塞避免算法呢,也就是說當前來講,每個傳輸輪次結束之后,擁塞窗口的值改為線性加1,而不是像慢開始算法那樣擁塞窗口的值呈現指數增長,比如說此時發送方能夠發送15~30號的數據報文段,當發送方收到 15 ~30 號的數據確認報文段,將擁塞窗口值加1增大到17,依據此原理,發送方和接收方又進行了幾個輪次的數據傳輸,達到如下所示的一個折線圖:

image-20210727002623522
如果說此時,在擁塞窗口值達到 24 的時候,發送方又向接收方發送了一串數據包,假設這串報文段在傳輸過程中,丟失了幾個,這必然會造成發送方對這些丟失報文段的超時重傳,發送方依據此判斷網絡很可能出現了擁塞,那么這個時候就需要做如下的工作:將慢開始門限值更新為發生擁塞時擁塞窗口值的一半,然后將擁塞窗口值調整為1 ,重新執行慢開始算法,當擁塞窗口達到慢開始門限值的時候,就執行擁塞避免算法,具體過程如圖所示:

image-20210727003147211
最后,對這一整個過程進行標注,標注之后的折線圖如圖所示:

image-20210727003439349
快重傳算法
有些時候,個別報文段會在網絡中丟失,但是實際網絡中并沒有發生擁塞,這也將導致發送方超時重傳,并且誤認為是發生了擁塞,這個時候,發送方將擁塞窗口設置為最小值1,并且錯誤地啟動了慢開始算法,因而降低了傳輸效率。
而采用快重傳算法可以讓發送方盡可能早地知道發生了個別報文段的丟失,也就是說快重傳也就是讓發送方盡快進行重傳,而不是等待超時重傳計時器超時再重傳。
具體是怎么樣呢?就是說接收方不要等待自己發送數據時才進行捎帶確認,而是要立即發送確認;即使是收到了失序的報文段也要立即發出對已經收到報文段的重復確認,發送方一旦收到 3 個連續的重復確認,就將相應的報文段立即重傳,而不是等待該報文段超時重傳計時器超時再重傳。
具體的過程是怎么樣的呢,看如下所示的示意圖:

image-20210727004738434
通過上圖可以看到,在發送M2時,并沒有等待M1的確認報文段到達之后再發送,而是在確認報文段到達之前就將 M2 的報文段發送出去了,發送 M3 的時候,數據報發生了丟失,在發送 M4 的時候,接收方收到之后,會繼續回傳報文段 M2 的確認,一直到發送 M6 的時候,都是回傳的M2的確認包,而此時對于M2的確認包的接收已經累計3個了,就立即重傳M3報文段,這樣也就不會造成對 M3 報文段的超時重傳,也就不會將擁塞窗口調整為 1 ,也就能夠大大提升網絡的傳輸效率。
快恢復算法
發送方一旦收到3個重復確認,就知道現在只是丟失了個別的報文段。于是不啟動慢開始算法,而執行快恢復算法;發送方將慢開始門限值和擁塞窗口值調整為當前窗口的一半;開始執行擁塞避免算法。
小結
綜上所述,我們綜合前面所敘述的慢開始和擁塞避免算法,以及快重傳和快恢復算法舉一個例子,例子如下所示:

image-20210727010118107
這個圖結合上述的理論能很好的進行解釋,這里就不在進行闡述了。
總結
至此,關于計算機網絡中 TCP 部分的闡述到此也就結束了,結合前面一則的 TCP 教程閱讀更佳哦~
-
TCP
+關注
關注
8文章
1353瀏覽量
79055 -
UDP
+關注
關注
0文章
325瀏覽量
33931 -
體系結構
+關注
關注
0文章
28瀏覽量
9635
發布評論請先 登錄
相關推薦
一文詳解udp與tcp的區別(UDT原理分析)
多線程和多進程的區別
TCP協議和UDP協議的區別有哪些
TCP和UDP的區別分析
UDP和TCP的區別

UDP一定比TCP更快嗎?什么情況下用UDP會更慢?







 工商網監
工商網監
評論