 Distributed Data Parallel中的分布式訓練
Distributed Data Parallel中的分布式訓練
實現原理
與DataParallel不同的是,Distributed Data Parallel會開設多個進程而非線程,進程數 = GPU數,每個進程都可以獨立進行訓練,也就是說代碼的所有部分都會被每個進程同步調用,如果你某個地方print張量,你會發現device的差異
sampler會將數據按照進程數切分,
「確保不同進程的數據不同」
每個進程獨立進行前向訓練
每個進程利用Ring All-Reduce進行通信,將梯度信息進行聚合
每個進程同步更新模型參數,進行新一輪訓練
按進程切分
如何確保數據不同呢?不妨看看DistributedSampler的源碼
#判斷數據集長度是否可以整除GPU數 #如果不能,選擇舍棄還是補全,進而決定總數 #Ifthedatasetlengthisevenlydivisibleby#ofreplicas #thenthereisnoneedtodropanydata,sincethedataset #willbesplitequally. if(self.drop_lastand len(self.dataset)%self.num_replicas!=0): #num_replicas=num_gpus self.num_samples=math.ceil((len(self.dataset)- self.num_replicas)/self.num_replicas) else: self.num_samples=math.ceil(len(self.dataset)/ self.num_replicas) self.total_size=self.num_samples*self.num_replicas #根據是否shuffle來創建indices ifself.shuffle: #deterministicallyshufflebasedonepochandseed g=torch.Generator() g.manual_seed(self.seed+self.epoch) indices=torch.randperm(len(self.dataset),generator=g).tolist() else: indices=list(range(len(self.dataset))) ifnotself.drop_last: #addextrasamplestomakeitevenlydivisible padding_size=self.total_size-len(indices) ifpadding_size<=?len(indices): ????????#?不夠就按indices順序加 ????????#?e.g.,?indices為[0,?1,?2,?3?...],而padding_size為4 ????????#?加好之后的indices[...,?0,?1,?2,?3] ????????indices?+=?indices[:padding_size] ????else: ????????indices?+=?(indices?*?math.ceil(padding_size?/?len(indices)))[:padding_size] else: ????#?remove?tail?of?data?to?make?it?evenly?divisible. ????indices?=?indices[:self.total_size] assert?len(indices)?==?self.total_size #?subsample #?rank代表進程id indices?=?indices[self.rankself.num_replicas] return?iter(indices)
Ring All-Reduce
那么什么是「Ring All-Reduce」呢?又為啥可以降低通信成本呢?
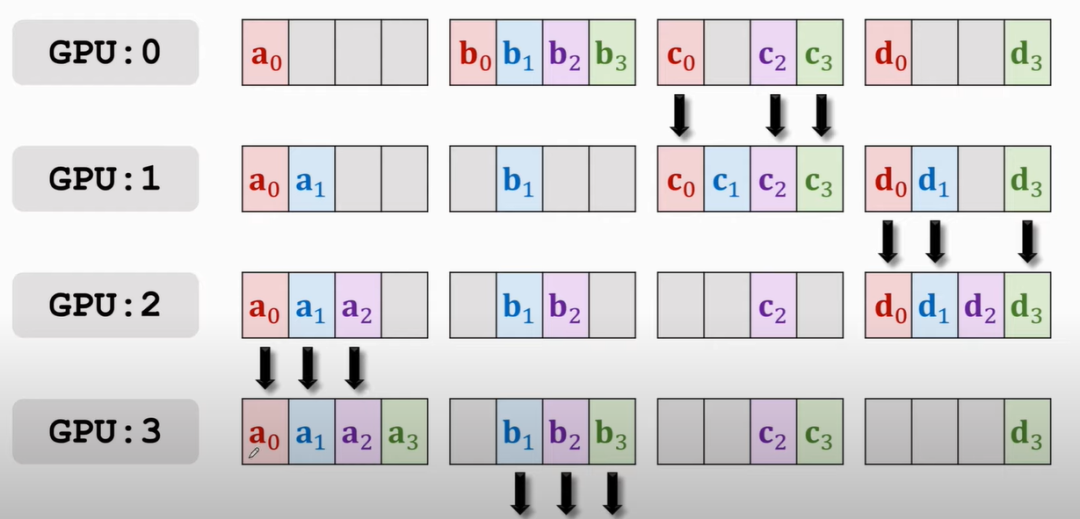
首先將每塊GPU上的梯度拆分成四個部分,比如,如下圖(此部分原理致謝下王老師,講的很清晰[1]:
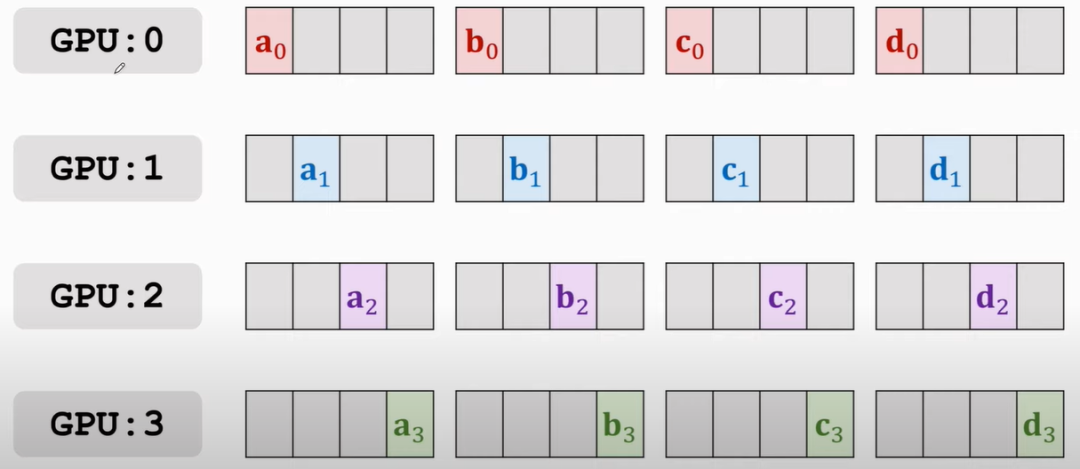
所有GPU的傳播都是「同步」進行的,傳播的規律有兩條:
只與自己下一個位置的GPU進行通信,比如0 > 1,3 > 0
四個部分,哪塊GPU上占的多,就由該塊GPU往它下一個傳,初始從主節點傳播,即GPU0,你可以想象跟接力一樣,a傳b,b負責傳給c
第一次傳播如下:
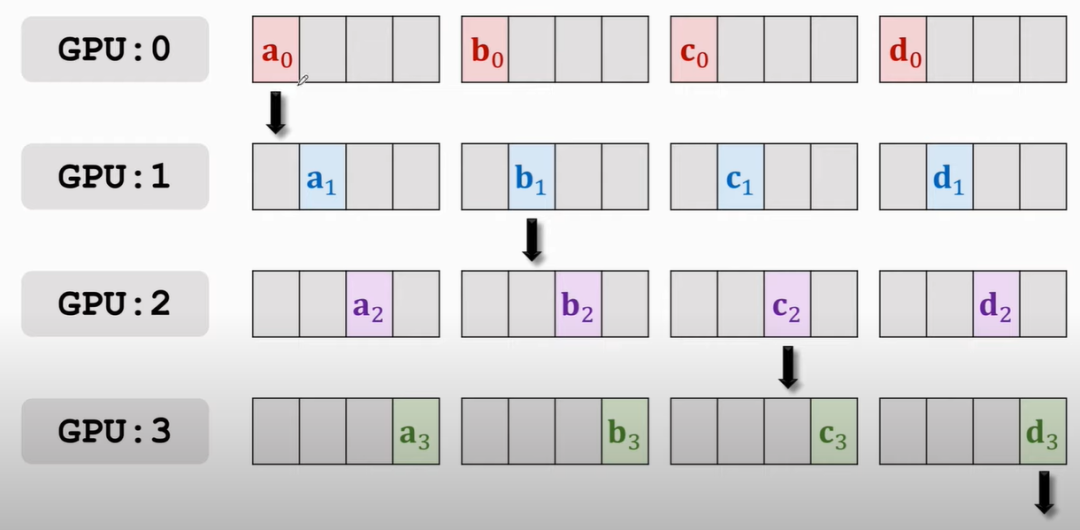
那么結果就是:
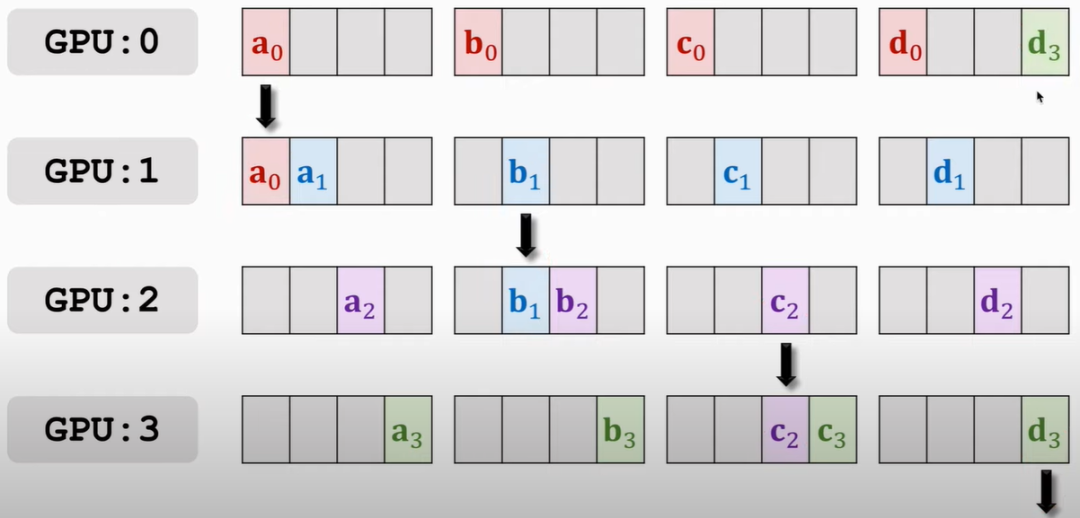
那么,按照誰多誰往下傳的原則,此時應該是GPU1往GPU2傳a0和a1,GPU2往GPU3傳b1和b2,以此類推
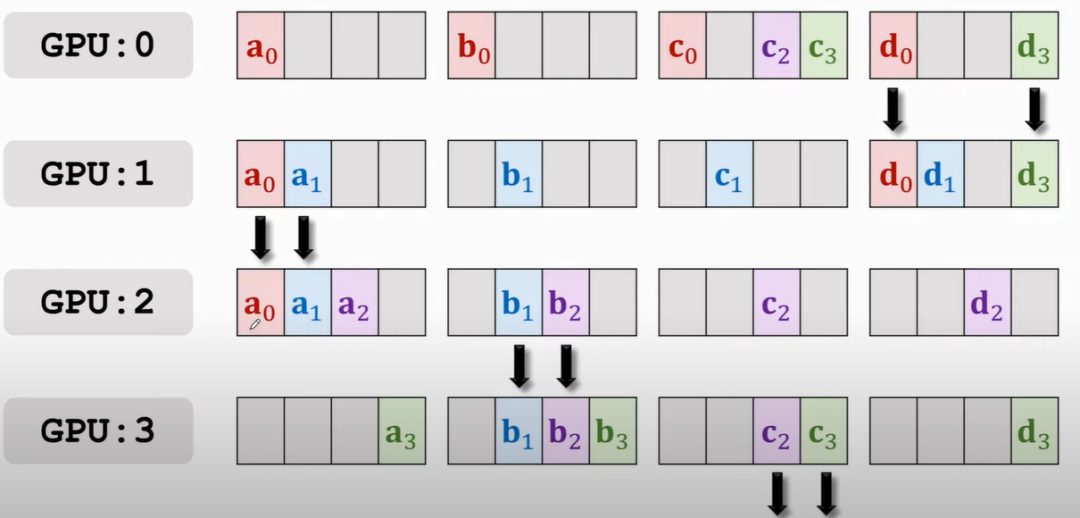
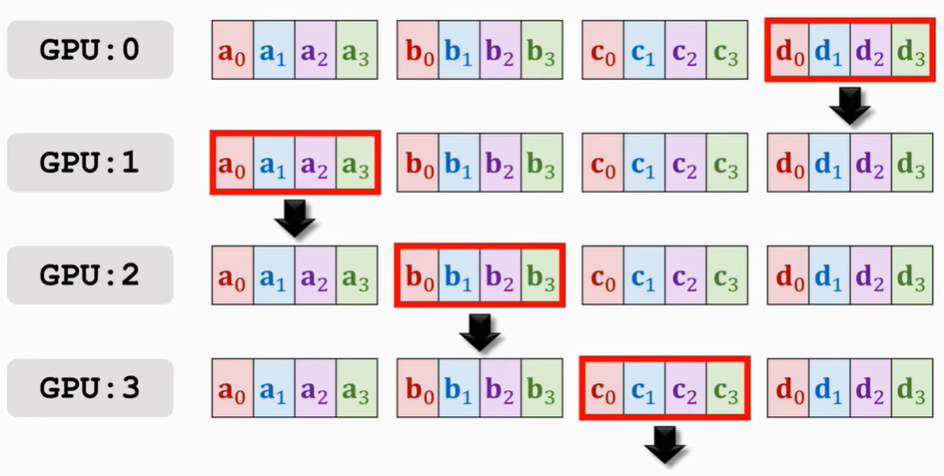
接下來再傳播就會有GPU3 a的部分全有,GPU0上b的部分全有等,就再往下傳
再來幾遍便可以使得每塊GPU上都獲得了來自其他GPU的梯度啦
代碼使用
基礎概念
第一個是后端的選擇,即數據傳輸協議,從下表可以看出[2],當使用CPU時可以選擇gloo而GPU則可以是nccl
| 「Backend」 | 「gloo」 | 「mpi」 | 「nccl」 | |||
|---|---|---|---|---|---|---|
| Device | CPU | GPU | CPU | GPU | CPU | GPU |
| send | ? | ? | ? | ? | ? | ? |
| recv | ? | ? | ? | ? | ? | ? |
| broadcast | ? | ? | ? | ? | ? | ? |
| all_reduce | ? | ? | ? | ? | ? | ? |
| reduce | ? | ? | ? | ? | ? | ? |
| all_gather | ? | ? | ? | ? | ? | ? |
| gather | ? | ? | ? | ? | ? | ? |
| scatter | ? | ? | ? | ? | ? | ? |
| reduce_scatter | ? | ? | ? | ? | ? | ? |
| all_to_all | ? | ? | ? | ? | ? | ? |
| barrier | ? | ? | ? | ? | ? | ? |
接下來是一些參數的解釋[3]:
| Arg | Meaning |
|---|---|
| group | 一次發起的所有進程構成一個group,除非想更精細通信,創建new_group |
| world_size | 一個group中進程數目,即為GPU的數量 |
| rank | 進程id,主節點rank=0,其他的在0和world_size-1之間 |
| local_rank | 進程在本地節點/機器的id |
舉個例子,假如你有兩臺服務器(又被稱為node),每臺服務器有4張GPU,那么,world_size即為8,rank=[0, 1, 2, 3, 4, 5, 6, 7], 每個服務器上的進程的local_rank為[0, 1, 2, 3]
然后是「初始化方法」的選擇,有TCP和共享文件兩種,一般指定rank=0為master節點
TCP顯而易見是通過網絡進行傳輸,需要指定主節點的ip(可以為主節點實際IP,或者是localhost)和空閑的端口
importtorch.distributedasdist dist.init_process_group(backend,init_method='tcp://ip:port', rank=rank,world_size=world_size)
共享文件的話需要手動刪除上次啟動時殘留的文件,加上官方有一堆警告,還是建議使用TCP
dist.init_process_group(backend,init_method='file://Path', rank=rank,world_size=world_size)
launch方法
「初始化」
這里先講用launch的方法,關于torch.multiprocessing留到后面講
在啟動后,rank和world_size都會自動被DDP寫入環境中,可以提前準備好參數類,如argparse這種
args.rank=int(os.environ['RANK']) args.world_size=int(os.environ['WORLD_SIZE']) args.local_rank=int(os.environ['LOCAL_RANK'])
首先,在使用distributed包的任何其他函數之前,按照tcp方法進行初始化,需要注意的是需要手動指定一共可用的設備CUDA_VISIBLE_DEVICES
defdist_setup_launch(args): #tellDDPavailabledevices[NECESSARY] os.environ['CUDA_VISIBLE_DEVICES']=args.devices args.rank=int(os.environ['RANK']) args.world_size=int(os.environ['WORLD_SIZE']) args.local_rank=int(os.environ['LOCAL_RANK']) dist.init_process_group(args.backend, args.init_method, rank=args.rank, world_size=args.world_size) #thisisoptional,otherwiseyoumayneedtospecifythe #devicewhenyoumovesomethinge.g.,model.cuda(1) #ormodel.to(args.rank) #Settingdevicemakesthingseasy:model.cuda() torch.cuda.set_device(args.rank) print('TheCurrentRankis%d|TheTotalRanksare%d' %(args.rank,args.world_size))
「DistributedSampler」
接下來創建DistributedSampler,是否pin_memory,根據你本機的內存決定。pin_memory的意思是提前在內存中申請一部分專門存放Tensor。假如說你內存比較小,就會跟虛擬內存,即硬盤進行交換,這樣轉義到GPU上會比內存直接到GPU耗時。
因而,如果你的內存比較大,可以設置為True;然而,如果開了導致卡頓的情況,建議關閉
fromtorch.utils.dataimportDataLoader,DistributedSampler train_sampler=DistributedSampler(train_dataset,seed=args.seed) train_dataloader=DataLoader(train_dataset, pin_memory=True, shuffle=(train_samplerisNone), batch_size=args.per_gpu_train_bs, num_workers=args.num_workers, sampler=train_sampler) eval_sampler=DistributedSampler(eval_dataset,seed=args.seed) eval_dataloader=DataLoader(eval_dataset, pin_memory=True, batch_size=args.per_gpu_eval_bs, num_workers=args.num_workers, sampler=eval_sampler)
「加載模型」
然后加載模型,跟DataParallel不同的是需要提前放置到cuda上,還記得上面關于設置cuda_device的語句嘛,因為設置好之后每個進程只能看見一個GPU,所以直接model.cuda(),不需要指定device
同時,我們必須給DDP提示目前是哪個rank
fromtorch.nn.parallelimportDistributedDataParallelasDDP model=model.cuda() #tellDDPwhichrank model=DDP(model,find_unused_parameters=True,device_ids=[rank])
注意,當模型帶有Batch Norm時:
ifargs.syncBN: nn.SyncBatchNorm.convert_sync_batchnorm(model).cuda()
「訓練相關」
每個epoch開始訓練的時候,記得用sampler的set_epoch,這樣使得每個epoch打亂順序是不一致的
關于梯度回傳和參數更新,跟正常情況無異
forepochinrange(epochs): #recordepochs train_dataloader.sampler.set_epoch(epoch) outputs=model(inputs) loss=loss_fct(outputs,labels) loss.backward() optimizer.step() optimizer.zero_grad()
這里有一點需要小心,這個loss是各個進程的loss之和,如果想要存儲每個step平均損失,可以進行all_reduce操作,進行平均,不妨看官方的小例子來理解下:
>>>#Alltensorsbelowareoftorch.int64type. >>>#Wehave2processgroups,2ranks. >>>tensor=torch.arange(2,dtype=torch.int64)+1+2*rank >>>tensor tensor([1,2])#Rank0 tensor([3,4])#Rank1 >>>dist.all_reduce(tensor,op=ReduceOp.SUM) >>>tensor tensor([4,6])#Rank0 tensor([4,6])#Rank1
@torch.no_grad() defreduce_value(value,average=True): world_size=get_world_size() ifworld_size
看到這,肯定有小伙伴要問,那這樣我們是不是得先求平均損失再回傳梯度啊,不用,因為,當我們回傳loss后,DDP會自動對所有梯度進行平均[4],也就是說回傳后我們更新的梯度和DP或者單卡同樣batch訓練都是一致的
loss=loss_fct(...) loss.backward() #注意在backward后面 loss=reduce_value(loss,world_size) mean_loss=(step*mean_loss+loss.item())/(step+1)
還有個注意點就是學習率的變化,這個是和batch size息息相關的,如果batch擴充了幾倍,也就是說step比之前少了很多,還采用同一個學習率,肯定會出問題的,這里,我們進行線性增大[5]
N=world_size lr=args.lr*N
肯定有人說,誒,你線性增大肯定不能保證梯度的variance一致了,正確的應該是正比于,關于這個的討論不妨參考[6]
「evaluate相關」
接下來,細心的同學肯定好奇了,如果驗證集也切分了,metric怎么計算呢?此時就需要咱們把每個進程得到的預測情況集合起來,t就是一個我們需要gather的張量,最后將每個進程中的t按照第一維度拼接,先看官方小例子來理解all_gather
>>>#Alltensorsbelowareoftorch.int64dtype. >>>#Wehave2processgroups,2ranks. >>>tensor_list=[torch.zeros(2,dtype=torch.int64)for_inrange(2)] >>>tensor_list [tensor([0,0]),tensor([0,0])]#Rank0and1 >>>tensor=torch.arange(2,dtype=torch.int64)+1+2*rank >>>tensor tensor([1,2])#Rank0 tensor([3,4])#Rank1 >>>dist.all_gather(tensor_list,tensor) >>>tensor_list [tensor([1,2]),tensor([3,4])]#Rank0 [tensor([1,2]),tensor([3,4])]#Rank1defsync_across_gpus(t,world_size): gather_t_tensor=[torch.zeros_like(t)for_in range(world_size)] dist.all_gather(gather_t_tensor,t) returntorch.cat(gather_t_tensor,dim=0)
可以簡單參考我前面提供的源碼的evaluate部分,我們首先將預測和標簽比對,把結果為bool的張量存儲下來,最終gather求和取平均。
這里還有個有趣的地方,tensor默認的類型可能是int,bool型的res拼接后自動轉為0和1了,另外bool型的張量是不支持gather的
defeval(...) results=torch.tensor([]).cuda() forstep,(inputs,labels)inenumerate(dataloader): outputs=model(inputs) res=(outputs.argmax(-1)==labels) results=torch.cat([results,res],dim=0) results=sync_across_gpus(results,world_size) mean_acc=(results.sum()/len(results)).item() returnmean_acc
「模型保存與加載」
模型保存,參考部分官方教程[7],我們只需要在主進程保存模型即可,注意,這里是被DDP包裹后的,DDP并沒有state_dict,這里barrier的目的是為了讓其他進程等待主進程保存模型,以防不同步
defsave_checkpoint(rank,model,path): ifis_main_process(rank): #Allprocessesshouldseesameparametersastheyall #startfromsamerandomparametersandgradientsare #synchronizedinbackwardpasses. #Therefore,savingitinoneprocessissufficient. torch.save(model.module.state_dict(),path) #Useabarrier()tokeepprocess1waitingforprocess0 dist.barrier()
加載的時候別忘了map_location,我們一開始會保存模型至主進程,這樣就會導致cuda:0顯存被占據,我們需要將模型remap到其他設備
defload_checkpoint(rank,model,path): #remapthemodelfromcuda:0tootherdevices map_location={'cuda:%d'%0:'cuda:%d'%rank} model.module.load_state_dict( torch.load(path,map_location=map_location) )
進程銷毀
運行結束后記得銷毀進程:
defcleanup(): dist.destroy_process_group() cleanup()
如何啟動
在終端輸入下列命令【單機多卡】
python-mtorch.distributed.launch--nproc_per_node=NUM_GPUS main.py(--arg1--arg2--arg3andallother argumentsofyourtrainingscript)
目前torch 1.10以后更推薦用run
torch.distributed.launch->torch.distributed.run/torchrun
多機多卡是這樣的:
#第一個節點啟動 python-mtorch.distributed.launch --nproc_per_node=NUM_GPUS --nnodes=2 --node_rank=0 --master_addr="192.168.1.1" --master_port=1234main.py #第二個節點啟動 python-mtorch.distributed.launch --nproc_per_node=NUM_GPUS --nnodes=2 --node_rank=1 --master_addr="192.168.1.1" --master_port=1234main.py
mp方法
第二個方法就是利用torch的多線程包
importtorch.multiprocessingasmp #rankmp會自動填入 defmain(rank,arg1,...): pass if__name__=='__main__': mp.spawn(main,nprocs=TOTAL_GPUS,args=(arg1,...))
這種運行的時候就跟正常的python文件一致:
pythonmain.py
優缺點
「優點」:相比于DP而言,不需要反復創建和銷毀線程;Ring-AllReduce算法提高通信效率;模型同步方便
「缺點」:操作起來可能有些復雜,一般可滿足需求的可先試試看DataParallel。
審核編輯:劉清
-
gpu
+關注
關注
28文章
4754瀏覽量
129077 -
PIN管
+關注
關注
0文章
36瀏覽量
6361 -
TCP通信
+關注
關注
0文章
146瀏覽量
4248
原文標題:深入理解Pytorch中的分布式訓練
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于ptp的分布式系統設計
HarmonyOS Next 應用元服務開發-分布式數據對象遷移數據文件資產遷移
HarmonyOS Next 應用元服務開發-分布式數據對象遷移數據權限與基礎數據
分布式通信的原理和實現高效分布式通信背后的技術NVLink的演進

分布式光纖聲波傳感技術的工作原理
分布式輸電線路故障定位中的分布式是指什么

分布式SCADA系統的特點的組成
鴻蒙開發接口數據管理:【@ohos.data.distributedData (分布式數據管理)】

HarmonyOS開發實例:【分布式數據服務】
HarmonyOS實戰案例:【分布式賬本】
分布式系統在交通監控工程中的創新應用案例
AI加速智能家居分布式語音技術發展
鴻蒙OS 分布式任務調度
什么是分布式架構?





 工商網監
工商網監
評論