

商品搜索引擎是電商平臺滿足用戶購物需求的一個重要系統,它根據用戶輸入的搜索詞,返回個性化的排序列表。商品一般會被歸為某一大類下某個小類目,例如電子產品,在電子產品這個大類目下面還有更細粒度的類目(冰箱或者電視)。這種體系用于構造查詢類別的層次結構。在不同的查詢類別中,價格和品牌知名度等特征的分布差異很大。在CTR(點擊率)/CVR(轉化率)預估問題中,特征重要性在不同類目間也是不一樣的。本文主要介紹專家混合模型(MoE)在京東搜索精排中的應用,以及結合實際場景對MoE模型進行的一系列改進。
Part1. 背景介紹
越來越多的人轉向電子商務來滿足他們的購物需求,這給搜索排名帶來了新的挑戰。電子商務搜索排名的一個關鍵輸入是產品類別標簽,店主通常被要求用特定的類別來標記他們的產品,以方便搜索索引。從這些產品類別中,可以構造查詢類別的概念,通常是通過聚合在查詢下正確檢索到的最頻繁出現的產品類別。目前大多數電子商務排名系統都沒有為每個查詢類別部署專用模型的工程資源,即使是主要的查詢類別也是如此。但是作為人工編目員,自然的策略是首先確定查詢最可能屬于的類別,然后檢索該類別中的項目。不同類別的特性對于產品排名的重要性可能不同。直觀地說,根據用戶購買反饋判斷,不同類別的單獨排名策略應該能夠提高整體產品搜索相關性。
??京東電商平臺有一套完整的以樹形結構組織的多層級類目結構。下圖是一個兩層級類目結構的示意圖,不同的Top-Categories 之間,用戶的購物行為會有比較明顯的差異,例如:當用戶搜索食品相關商品時,可能選擇銷量高的;而當搜索服飾相關商品時,可能會更關注風格、品牌等信息。相反同一個Top-Categories下的Sub-Categories之間,用戶的購物行為一般比較接近。
此外,對于一些小類目的商品,在訓練集樣本量上和大類目相比差距懸殊,在模型訓練過程中會被大類目商品的樣本所影響和主導。針對類目差異和小類目學習這兩個問題,本文提出了一種多類目MoE(Mixture of Experts)模型。
Part2. 多類目MoE模型
MoE模型
MoE 主要包括兩個核心部分:門網絡(gating network)和專家網絡(expert network)。門網絡的輸出作為對應的專家網絡的權重,用于對專家網絡的輸出進行加權求和。MoE 模型的輸出可以寫成下面的公式:
其中,N表示專家網絡的個數,G表示門網絡,Q表示專家網絡。
Top-K gating MoE模型
模型會根據門網絡的輸出,選擇最大的K個權重所對應的專家網絡進行激活,然后只對選中的K個專家網絡的輸出進行加權求和。計算公式如下:
在Top_k MoE模型中,如果一個專家網絡對應的權重值不在最高的K個集合里,那么經過softmax函數之后權重會變為0。從而在模型訓練中這些專家網絡不會被激活,能降低模型的計算復雜度。
多類目MoE的模型
針對上述提到的類目差異和小類目學習兩個問題,本文在Top_K MoE 的基礎上加入了兩種改進方法,提出了多類目MoE的模型結構,如下圖:
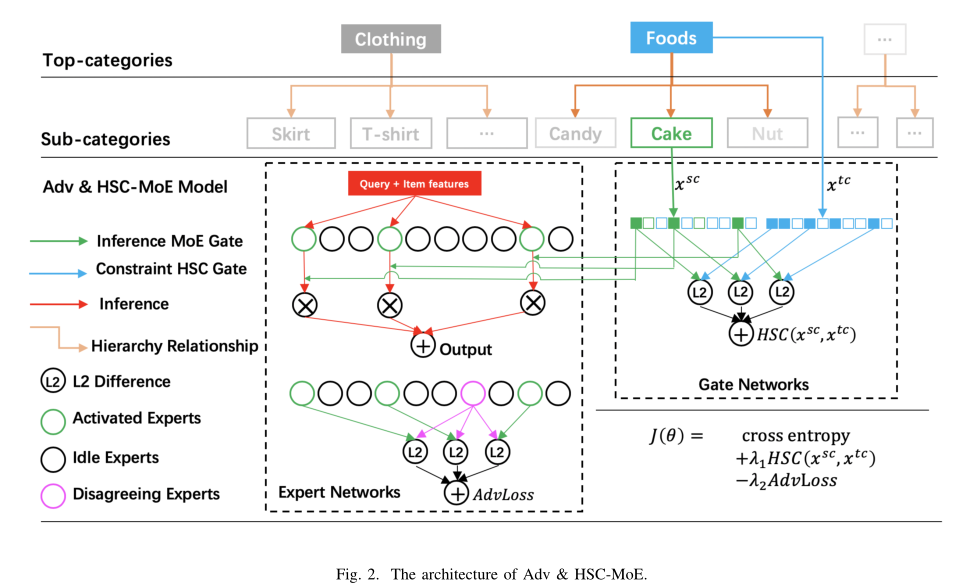
(1)Hierarchical Soft Constraint(HSC)網絡
針對小類目樣本學習問題,本文的改進是增加一個與MoE門網絡結構相同的HSC門網絡(圖種藍色部分)。HSC門網絡的輸入是Top-Category,輸出與MoE的門網絡結構維度一致,代表了不同專家網絡對于Top-Category 的重要程度。同時將激活的專家網絡對應的權重和HSC門網絡對應的權重的L2距離作為模型訓練的一個損失項,加入到模型的訓練過程中。
??具體來說,圖2中的Top-Category和Sub-Category具有層次關系,Top-Category是父節點,Sub-Category是子節點。為了進一步強調不同門網絡的功能,我們分別將它們稱之為inference MoE gate(綠色部分)和constraint HSC gate(藍色部分)。
a. Inference MoE Gate
將Sub-Category的嵌入向量,輸入inference gate,其輸出代表專家的權重。定義inference gate函數如下:
其中,是一個 q×N的可訓練的權重矩陣,q表示embedding的維度,N表示expert的個數。
??為了節省計算,只在中保留前K個值,并將其余值設置為?∞。然后應用softmax函數從前K個中得到如下的概率分布:
,如果
,如果<
由于有K個大于0的值,為了節省計算,只激活這些對應的專家。模型的計算復雜度取決于單個專家的網絡和K的取值。
b. Inference MoE Gate
在模型中,constraint gate和inference gate具有相同的結構。用表示constraint gate,表示inference gate,constraint gate的輸入特征記為,是Top-Category的嵌入向量,定義inference gate和constraint gate之間的分層軟約束(HSC)如下:
??通過上述HSC網絡,可以讓相同Top-Category下的所有Sub-Category所激活的專家網絡盡量的接近。尤其對于樣本量少的小類目,可以利用到相同Top-category下的其他類目信息,能一定程度上解決小樣本學習難的問題。
(2)Adversarial Regularization
第二個改進是Adversarial Regularization。在Top_K門網絡結構中,對于每條樣本,專家網絡都會分為激活的專家網絡和沒有激活的專家網絡。Adversarial Regularization的目的是在訓練過程中讓不同專家網絡盡量區別開,避免專家網絡的預測結果相同。即鼓勵激活的專家網絡和沒有被激活的專家網絡給出的預測結果差異較大。Adversarial Regularization計算公式如下:
其中, 表示激活的專家網絡集合, 表示沒有被激活的專家網絡集合。
??增加了HSC網絡和Adversarial Regularization之后,模型的損失函數如下所示:
Part3. 實驗結論
作者在Amazon和In-house兩個數據集上分別評估了所提出模型的效果。表格中的Adv-MoE和HSC-MoE分別表示只有Adversarial Regularization和HSC loss的兩個模型,Adv&HSC-MoE表示作者提出的最終多類目模型。
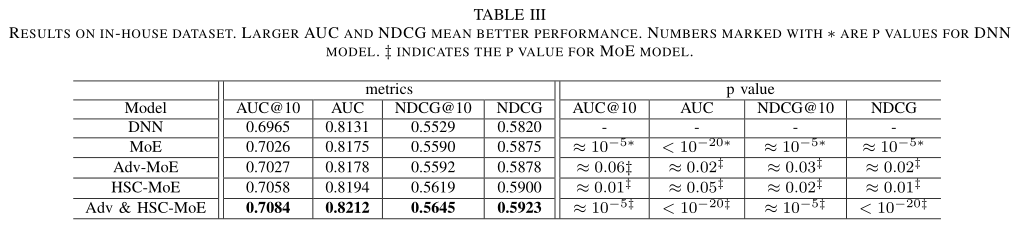
??作者首先在In-house數據集上測試了模型的整體效果、類目差異的效果以及在小樣本類目上的提升效果。表3給出了各個模型在AUC和NDCG兩個指標上結果。與DNN模型相比,本文提出的Adv&HSC-MoE模型在AUC指標上實現了0.96%的增益(NDCG為0.99%),具有較好的泛化性能。
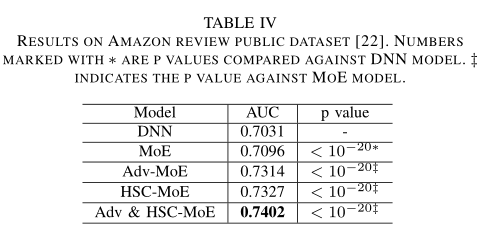
同時,作者也在amazon數據集上做了實驗,下表顯示改進后的Adv-MoE、HSC-MoE和Adv& HSC-MoE結果與In-house一致,驗證了對抗正則化和分層軟約束技術的一般適用性。
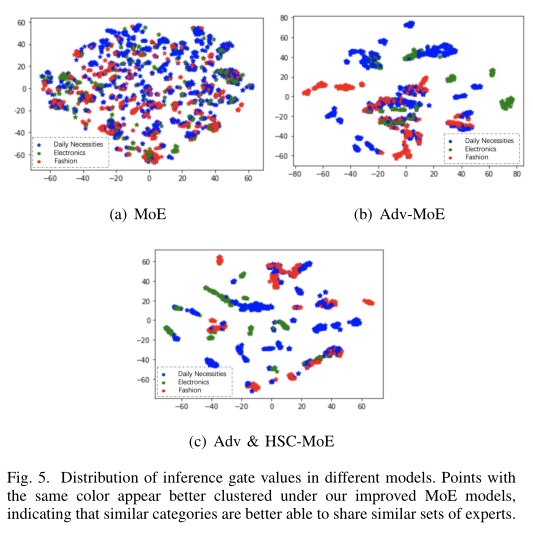
MoE模型門網絡的輸出代表了各個專家網絡的權重,作者同樣測試了不同類目下門網絡的輸出結果,以評估模型對于類目差異的學習效果。本文將門網絡的輸出結果使用T-SNE降維展示出來,以便觀察不同類目的聚類效果。圖5中藍色表示日用百貨類目,綠色表示電器類目,紅色表示流行服飾類目。結果顯示,本文的方法聚類效果更好,這表明對于相似的類目,本文提出的模型更傾向于選擇相似的專家網絡,差異大的類目,更傾向于選擇不同的專家網絡。
Part4. 總結
本文提出的對抗性正則化和層次軟約束技術是在產品搜索中開發類別感知排名模型的有效方法。它在行業規模的數據集上取得了顯著的改進,主要體現在以下幾個方面:(1)同一Top-Categories下的Sub-Categories可以共享相似的專家,從而克服了有限訓練數據下的參數稀疏性;(2)對抗性正則化鼓勵專家“獨立思考”,從不同角度處理每個問題。
審核編輯 :李倩
-
網絡
+關注
關注
14文章
7782瀏覽量
90514 -
模型
+關注
關注
1文章
3500瀏覽量
50103 -
數據集
+關注
關注
4文章
1223瀏覽量
25312
原文標題:京東:基于多類目MoE模型的電商搜索引擎
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
微軟面臨法國反壟斷機構調查
LZO Data Compression,高性能LZO無損數據壓縮加速器介紹,FPGA&ASIC
蘋果為谷歌支付數十億美元辯護,參與搜索案反壟斷審判
SSR的優勢和劣勢分析
阿里國際推出全球首個B2B AI搜索引擎Accio
阿里國際推出B2B領域AI搜索引擎Accio
租用多ip云服務器可以帶來哪些好處?應用場景有哪些?
Meta開發新搜索引擎,減少對谷歌和必應的依賴
月訪問量超2億,增速113%!360AI搜索成為全球增速最快的AI搜索引擎
電商搜索革命:大模型如何重塑購物體驗?
恒訊科技分析:香港站群服務器為什么要做偽靜態處理呢?
OpenAI推出SearchGPT原型,正式向Google搜索引擎發起挑戰
微軟計劃在搜索引擎Bing中引入AI摘要功能
AI搜索挑戰百度谷歌,重塑信息檢索的市場?
大模型應用Step-By-Step





 工商網監
工商網監

評論