 Prometheus Metric的實踐總結
Prometheus Metric的實踐總結
使用 Promethues 實現應用監控的一些實踐
在這篇文章中我們介紹了如何利用 Prometheus 監控應用。在后續的工作中隨著監控的深入,我們結合自己的經驗和官方文檔總結了一些 Metrics 的實踐。希望這些實踐能給大家提供參考。
確定監控對象
在具體設計 Metrics 之前,首先需要明確需要測量的對象。需要測量的對象應該依據具體的問題背景、需求和需監控的系統本身來確定。
從需求出發
Google 針對大量分布式監控的經驗總結出四個監控的黃金指標,這四個指標對于一般性的監控測量對象都具有較好的參考意義。這四個指標分別為:
延遲:服務請求的時間。
通訊量:監控當前系統的流量,用于衡量服務的容量需求。
錯誤:監控當前系統所有發生的錯誤請求,衡量當前系統錯誤發生的速率。
飽和度:衡量當前服務的飽和度。主要強調最能影響服務狀態的受限制的資源。例如,如果系統主要受內存影響,那就主要關注系統的內存狀態。
以上四種指標,其實是為了滿足四個監控需求:
反映用戶體驗,衡量系統核心性能。如:在線系統的時延,作業計算系統的作業完成時間等。
反映系統的吞吐量。如:請求數,發出和接收的網絡包大小等。
幫助發現和定位故障和問題。如:錯誤計數、調用失敗率等。
反映系統的飽和度和負載。如:系統占用的內存、作業隊列的長度等。
除了以上常規需求,還可根據具體的問題場景,為了排除和發現以前出現過或可能出現的問題,確定相應的測量對象。比如,系統需要經常調用的一個庫的接口可能耗時較長,或偶有失敗,可制定 Metrics 以測量這個接口的時延和失敗數。
從需要監控的系統出發
為了滿足相應的需求,不同系統需要觀測的測量對象也是不同的。在 官方文檔 的最佳實踐中,將需要監控的應用分為了三類:
線上服務系統(Online-serving systems):需對請求做即時的響應,請求發起者會等待響應。如 web 服務器。
離線計算系統(Offline processing):請求發起者不會等待響應,請求的作業通常會耗時較長。如批處理計算框架 Spark 等。
批處理作業(Batch jobs):這類應用通常為一次性的,不會一直運行,運行完成后便會結束運行。如數據分析的 MapReduce 作業。
對于每一類應用其通常情況下測量的對象是不太一樣的。其總結如下:
線上服務系統:主要有請求、出錯的數量,請求的時延等。
線下計算系統:最后開始處理作業的時間,目前正在處理作業的數量,發出了多少 items, 作業隊列的長度等。
批處理作業:最后成功執行的時刻,每個主要 stage 的執行時間,總的耗時,處理的記錄數量等。
除了系統本身,有時還需監控子系統:
使用的庫(Libraries): 調用次數,成功數,出錯數,調用的時延。
日志(Logging):計數每一條寫入的日志,從而可找到每條日志發生的頻率和時間。
Failures: 錯誤計數。
線程池:排隊的請求數,正在使用的線程數,總線程數,耗時,正在處理的任務數等。
緩存:請求數,命中數,總時延等。
選擇 Vector
選用 Vec 的原則:
數據類型類似但資源類型、收集地點等不同
Vec 內數據單位統一
例子:
不同資源對象的請求延遲
不同地域服務器的請求延遲
不同 http 請求錯誤的計數
…
此外,官方文檔 中建議,對于一個資源對象的不同操作,如 Read/Write、Send/Receive, 應采用不同的 Metric 去記錄,而不要放在一個 Metric 里。原因是監控時一般不會對這兩者做聚合,而是分別去觀測。 不過對于 request 的測量,通常是以 Label 做區分不同的 action。
確定 Label
常見 Label 的選擇有:
resource
region
type
…
確定 Label 的一個重要原則是:同一維度 Label 的數據是可平均和可加和的,也即單位要統一。如風扇的風速和電壓就不能放在一個 Label 里。
此外,不建議下列做法:
my_metric{label=a} 1 my_metric{label=b} 6 my_metric{label=total} 7
即在 Label 中同時統計了分和總的數據,建議采用 PromQL 在服務器端聚合得到總和的結果。或者用另外的 Metric 去測量總的數據。
命名 Metrics 和 Label
好的命名能夠見名知義,因此命名也是良好設計的一環。
Metric 的命名:
需要符合 pattern: a-zA-Z:
應該包含一個單詞作為前綴,表明這個 Metric 所屬的域。
如:
prometheus_notifications_total
process_cpu_seconds_total
ipamd_request_latency
應該包含一個單位的單位作為后綴,表明這個 Metric 的單位。
如:
http_request_duration_seconds
node_memory_usage_bytes
http_requests_total (for a unit-less accumulating count)
邏輯上與被測量的變量含義相同。
盡量使用基本單位,如 seconds,bytes。而不是 Milliseconds, megabytes。
Label 的命名:
依據選擇的維度命名,如:
region: shenzhen/guangzhou/beijing
owner: user1/user2/user3
stage: extract/transform/load
Buckets 選擇
適宜的 buckets 能使 histogram 的百分位數計算更加準確。
理想情況下,桶會使得數據分布呈階梯狀,即各桶區間內數據個數大致相同。
buckets 的設計可遵從如下經驗:
需要知道數據的大致分布,若事先不知道可先用默認桶 ({.005, .01, .025, .05, .1, .25, .5, 1, 2.5, 5, 10})或 2 倍數桶({1,2,4,8…})觀察數據分布再調整 buckets。
數據分布較密處桶間隔制定的較窄一些,分布稀疏處可制定的較寬一些。
對于多數時延數據,一般具有長尾的特性,較適宜用指數形式的桶(ExponentialBuckets)。
初始桶上界一般覆蓋10%左右的數據,若不關注頭部數據也可以讓初始上界更大一些。
若為了更準確計算特定百分位數,如90%,可在90%的數據處加密分布桶,即減少桶的間隔。
比如我在監控我們某些任務耗時的時候,就是選根據實際情況估算出大致的 bucket 取值,上線后觀察數據和監控再去調整 bucket, 這樣經過幾次調整應該就能調整到比較合適的 bucket。
Grafana 使用技巧
查看所有維度
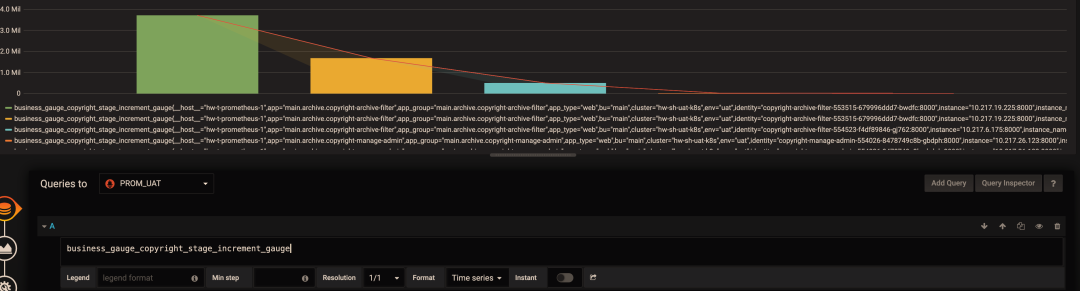
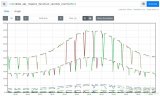
如果你想知道是否還能按其它維度分組,并快速查看還有哪些維度,可采用以下技巧:在 query 的表達式上只保留指標名稱,不做任何計算,Legend format 也留空。這樣就能顯示出原始的 metric 數據。如下圖所示
標尺聯動
在 Settings 面板中,有一個 Graph Tooltip 設置項,默認使用 Default。
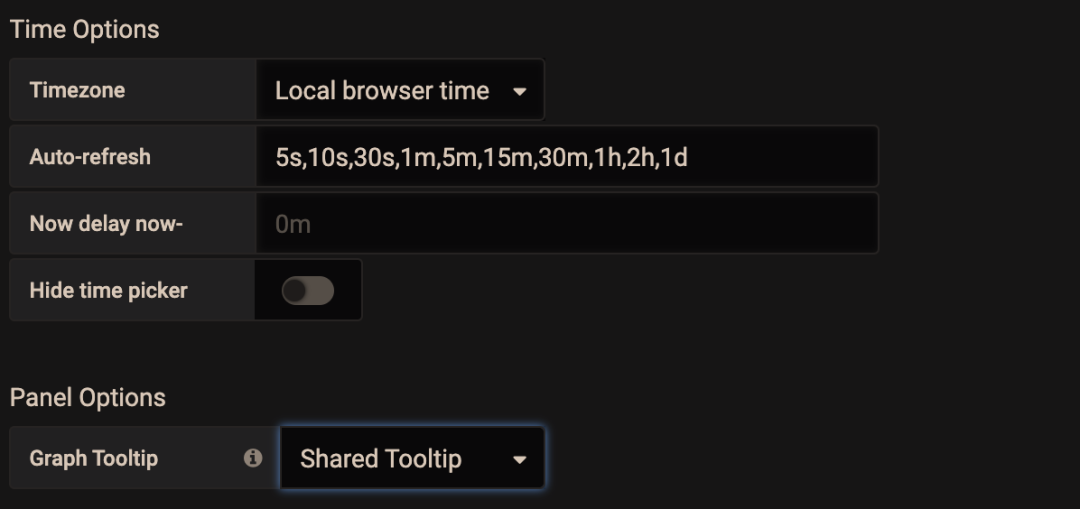
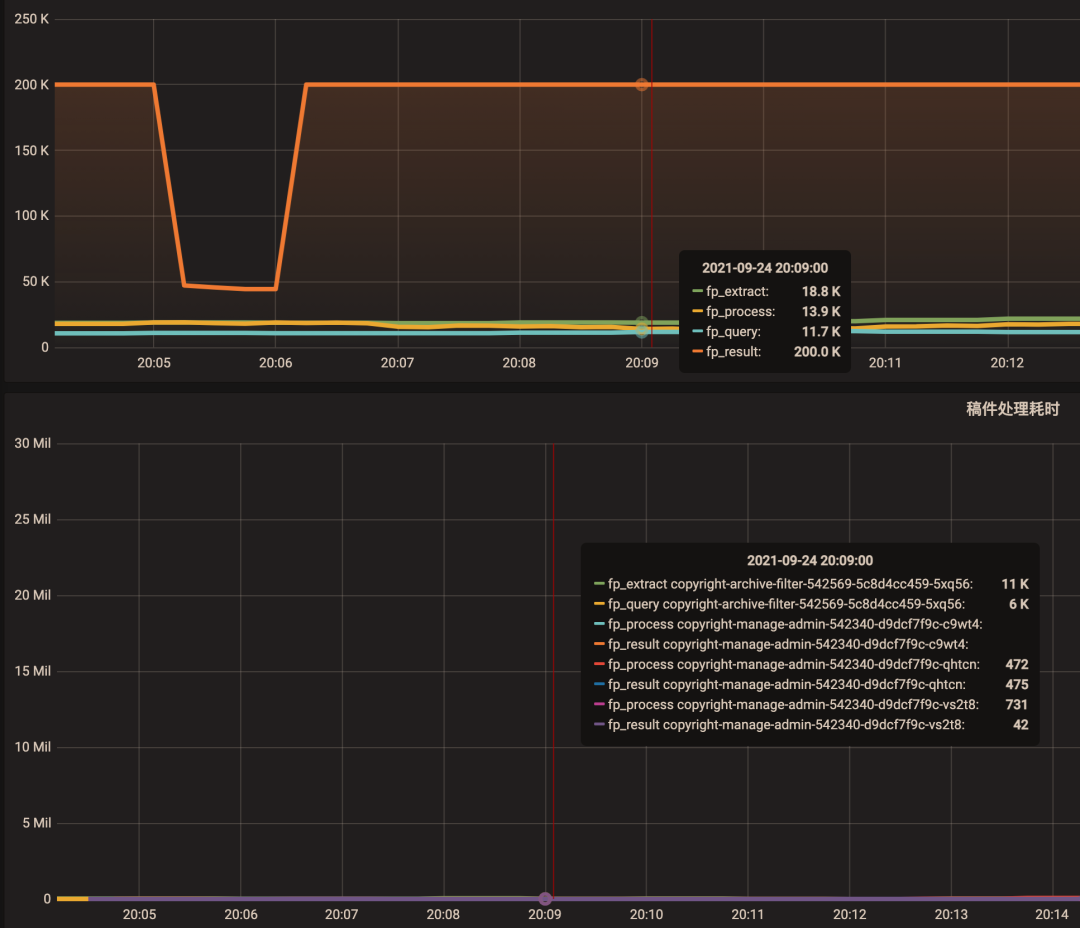
下面將圖形展示工具分別調整為 Shared crosshair 和 Shared Tooltip 看看效果。可以看到標尺能聯動展示了,方便排查問題時確認 2 個指標的關聯性。
將圖形展示工具調整為 Shared Tooltip:
審核編輯 :李倩
-
測量
+關注
關注
10文章
4849瀏覽量
111241 -
Prometheus
+關注
關注
0文章
27瀏覽量
1714
原文標題:Prometheus Metric 的實踐總結,搞定監控需注意~
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
MES系統的最佳實踐案例

TFT適配LVGL實踐分享

RTOS開發最佳實踐

【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》2.0

Prometheus監控業務指標詳解

Prometheus新手常犯的6項錯誤你知道嗎?
Prometheus實戰篇:Exporter知識概述





 工商網監
工商網監
評論