 目標檢測正負樣本區分策略和平衡策略總結
目標檢測正負樣本區分策略和平衡策略總結
0 簡介
本文拋棄網絡具體結構,僅僅從正負樣本區分和正負樣本平衡策略進行分析,大體可以分為正負樣本定義、正負樣本采樣和平衡loss設計三個方面,主要是網絡預測輸出和loss核心設計即僅僅涉及網絡的head部分。所有涉及到的代碼均以mmdetection為主。本文第一部分,主要包括faster rcnn、libra rcnn、retinanet、ssd和yolo一共5篇文章。第二部分包括anchor-free的平衡策略,以及最新改進算法。第三部分重點分析下anchor-free和anchor-base混合學習的Guided Anchoring以及yolo-ASFF,包括思路和代碼。
由于本人水平有限,如果有分析不對的地方,歡迎指正和交流!
1 anchor-base
1.1 two-stage
1.1.1 faster rcnn
論文名稱:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
(1) head結構
faster rcnn包括兩個head:rpn head和rcnn head。其結構如下:
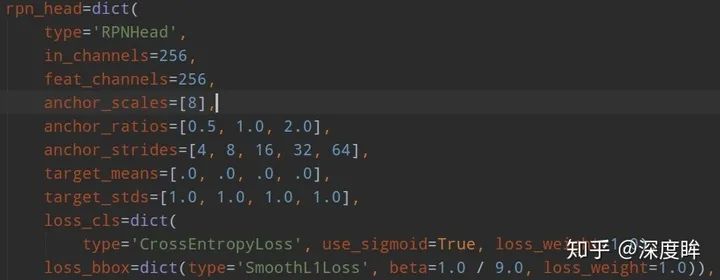
rpn head的輸出是包括分類和回歸,分類是二分類,只區分前景和背景;回歸是僅僅對于前景樣本(正樣本)進行基于anchor的變換回歸。rpn head的目的是提取roi,然后輸入到rcnn head部分進行refine。rcnn head的輸出是包括分類和回歸,分類輸出是類別數+1(1是考慮背景),回歸是僅僅對于前景樣本不考慮分類類別進行基于roi的變換回歸,rcnn head的目的是對rpn提取的roi特征進行refine,輸出精準bbox。
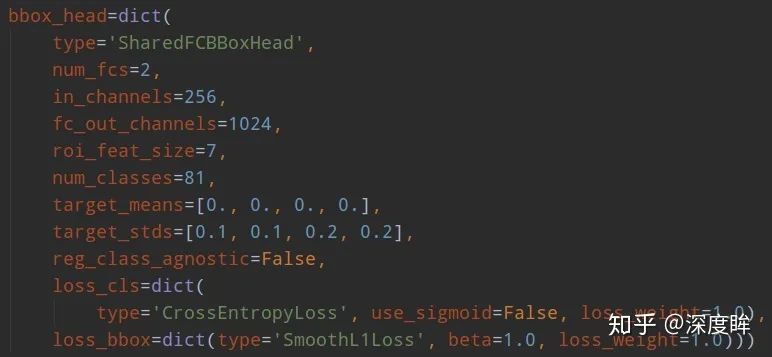
(2) 正負樣本定義
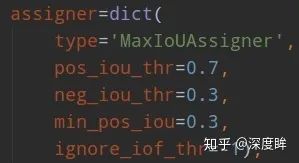
rpn和rcnn的正負樣本定義都是基于MaxIoUAssigner,只不過定義閾值不一樣而已。rpn的assigner:
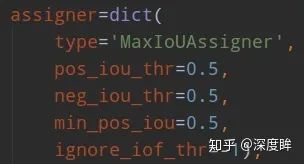
rcnn的assigner:
下面對MaxIoUAssigner進行詳細分析。首先分析原理,然后分析細節。正負樣本定義非常關鍵。MaxIoUAssigner的操作包括4個步驟:
首先初始化時候假設每個anchor的mask都是-1,表示都是忽略anchor
將每個anchor和所有gt的iou的最大Iou小于neg_iou_thr的anchor的mask設置為0,表示是負樣本(背景樣本)
對于每個anchor,計算其和所有gt的iou,選取最大的iou對應的gt位置,如果其最大iou大于等于pos_iou_thr,則設置該anchor的mask設置為1,表示該anchor負責預測該gt bbox,是高質量anchor
3的設置可能會出現某些gt沒有分配到對應的anchor(由于iou低于pos_iou_thr),故下一步對于每個gt還需要找出和最大iou的anchor位置,如果其iou大于min_pos_iou,將該anchor的mask設置為1,表示該anchor負責預測對應的gt。通過本步驟,可以最大程度保證每個gt都有anchor負責預測,如果還是小于min_pos_iou,那就沒辦法了,只能當做忽略樣本了。從這一步可以看出,3和4有部分anchor重復分配了,即當某個gt和anchor的最大iou大于等于pos_iou_thr,那肯定大于min_pos_iou,此時3和4步驟分配的同一個anchor。
從上面4步分析,可以發現每個gt可能和多個anchor進行匹配,每個anchor不可能存在和多個gt匹配的場景。在第4步中,每個gt最多只會和某一個anchor匹配,但是實際操作時候為了多增加一些正樣本,通過參數gt_max_assign_all可以實現某個gt和多個anchor匹配場景。通常第4步引入的都是低質量anchor,網絡訓練有時候還會帶來噪聲,可能還會起反作用。
簡單總結來說就是:如果anchor和gt的iou低于neg_iou_thr的,那就是負樣本,其應該包括大量數目;如果某個anchor和其中一個gt的最大iou大于pos_iou_thr,那么該anchor就負責對應的gt;如果某個gt和所有anchor的iou中最大的iou會小于pos_iou_thr,但是大于min_pos_iou,則依然將該anchor負責對應的gt;其余的anchor全部當做忽略區域,不計算梯度。該最大分配策略,可以盡最大程度的保證每個gt都有合適的高質量anchor進行負責預測,
下面結合代碼進行分析:主要就是assign_wrt_overlaps函數,核心操作和注釋如下:
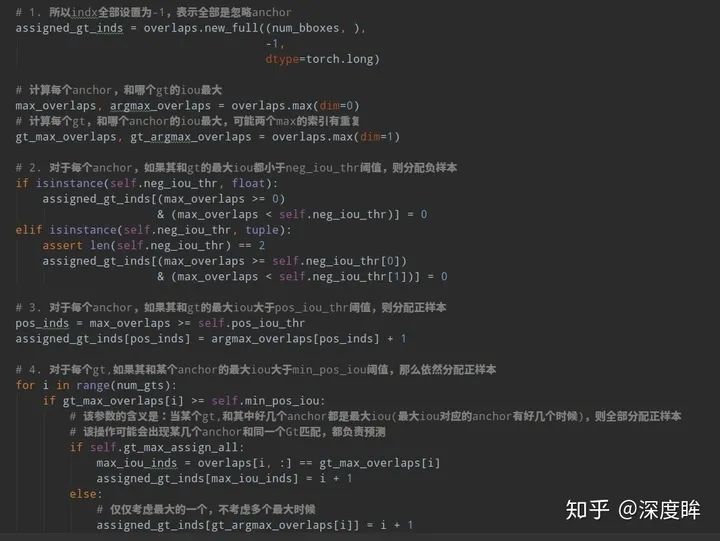
通過代碼可以發現,當設置self.gt_max_assign_all=True時候是可能出現第4步的某個gt和多個anchor匹配場景,默認參數就是True。
由于rcnn head預測值是rpn head的refine,故rcnn head面對的anchor(其實就是rpn輸出的roi)和gt的iou會高于rpn head部分,anchor質量更高,故min_pos_iou閾值設置的比較高,由于pos_iou_thr和neg_iou_thr設置都是0.5,那么忽略區域那就是沒有了,因為rcnn head面對的都是高質量樣本,不應該還存在忽略區域。
(3) 正負樣本采樣
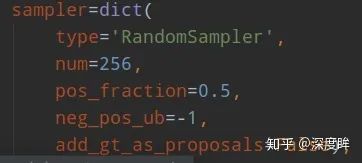
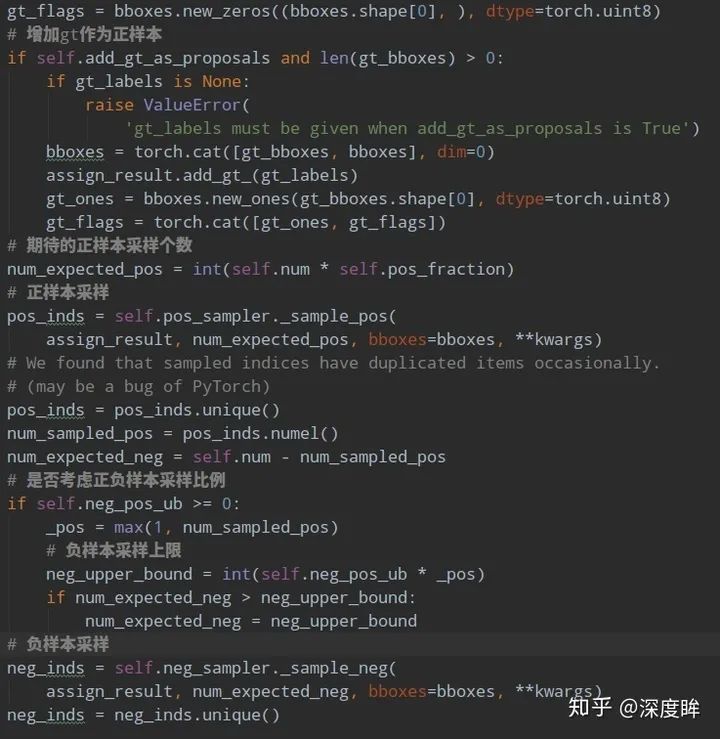
步驟2可以區分正負和忽略樣本,但是依然存在大量的正負樣本不平衡問題,解決辦法可以通過正負樣本采樣或者loss上面一定程度解決,faster rcnn默認是需要進行正負樣本采樣的。rpn head和rcnn head的采樣器都比較簡單,就是隨機采樣,閾值不一樣而已。rpn head采樣器:
rcnn head采樣器:
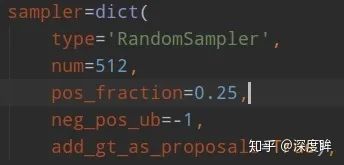
num表示采樣后樣本總數,包括正負和忽略樣本,pos_fraction表示其中的正樣本比例。add_gt_as_proposals是為了放在正樣本太少而加入的,可以保證前期收斂更快、更穩定,屬于技巧。neg_pos_ub表示正負樣本比例,用于確定負樣本采樣個數上界,例如我打算采樣1000個樣本,正樣本打算采樣500個,但是可能實際正樣本才200個,那么正樣本實際上只能采樣200個,如果設置neg_pos_ub=-1,那么就會對負樣本采樣800個,用于湊足1000個,但是如果設置為neg_pos_ub比例,例如1.5,那么負樣本最多采樣200x1.5=300個,最終返回的樣本實際上不夠1000個。默認情況neg_pos_ub=-1。由于rcnn head的輸入是rpn head的輸出,在網絡訓練前期,rpn無法輸出大量高質量樣本,故為了平衡和穩定rcnn訓練過程,通常會對rcnn head部分添加gt作為proposal。其代碼非常簡單:
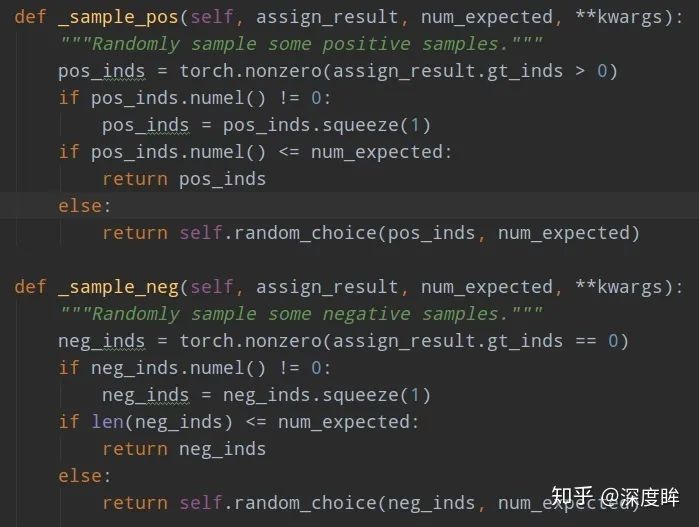
對正負樣本單獨進行隨機采樣就行,如果不夠就全部保留。
由于原始faster rcnn采用的loss是ce和SmoothL1Loss,不存在loss層面解決正負樣本不平衡問題,故不需要分析loss。
1.1.2 libra rcnn
論文名稱:Libra R-CNN: Towards Balanced Learning for Object Detection
libra主要是分析訓練過程中的不平衡問題,提出了對應的解決方案。由于libra rcnn的head部分和正負樣本定義沒有修改,故不再分析,僅僅分析正負樣本采樣和平衡loss設計部分。
(1) 正負樣本采樣
注意libra rcnn的正負樣本采樣規則修改僅僅是對于rcnn而言,對于rpn head沒有任何修改,依然是隨機采樣器。原因是作者的主要目的是為了漲點mAP,作者認為rpn漲幾個點對最終bbox 預測map沒有多大幫助,因為主要是靠rcnn部分進行回歸預測才能得到比較好的mAP。其參數如下:
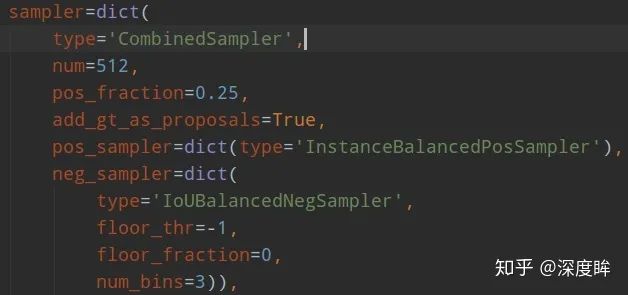
主要看IoUBalancedNegSampler部分即可。僅僅作用于負樣本(iou=0~0.5之間)。作者認為樣本級別的隨機采樣會帶來樣本不平衡,由于負樣本本身iou的不平衡,當采用隨機采樣后,會出現難負(iou 0.5附近)和易負(iou接近0)樣本不平衡采樣,導致后面性能不好。作者發現了如果是隨機采樣的話,隨機采樣到的樣本超過70%都是在IoU在0到0.05之間的,都是易學習負樣本,作者覺得是不科學的,而實際統計得到的事實是60%的hard negative都落在IoU大于0.05的地方,但是隨機采樣只提供了30%,實在是太少了。最常用的解決難易樣本不平衡問題的解決辦法就是ohem,基于Loss排序來采樣難負樣本,但是作者分析,(1) 這種方法對噪音數據會比較敏感,因為錯誤樣本loss高;(2) 參數比較難調。所以作者提出了IoU-balanced Sampling,如下所示:
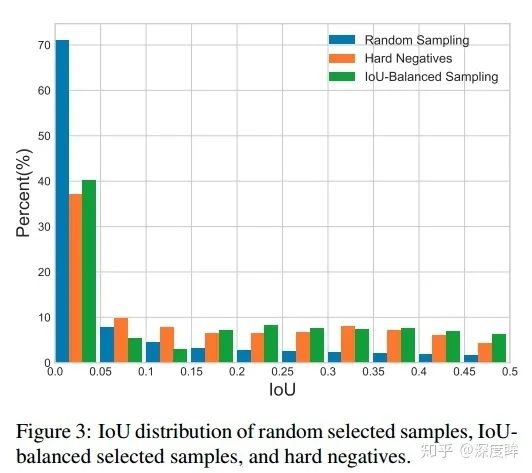
可以看出,隨機采樣效果最不好,而iou balanced sampling操作會盡量保證各個iou區間內都會采樣到。由于該操作比較簡單,就不貼論文公式了。核心操作是對負樣本按照iou劃分k個區間,每個區間再進行隨機采樣,保證易學習負樣本和難負樣本比例盡量平衡,實驗表明對K不敏感,作者設置的是3。具體做法是對所有負樣本計算和gt的iou,并且劃分K個區間后,在每個區間內均勻采樣就可以了。假設分成三個區間,我想總共取9個,第一個區間有20個候選框,第二個區間有10個,第三個區間有5個,那這三個區間的采樣概率就是9/(3x20),9/(3x10),9/(3x5),這樣的概率就能在三個區間分別都取3個,因為區間內候選框多,它被選中的概率小,最終體現各個區間都選這么多框。
實際代碼做法是:首先按照iou分成k個區間,先嘗試在不同區間進行隨機采樣采相同多數目的樣本,如果不夠就全部采樣;進行一輪后,如果樣本數不夠,再剩下的樣本中均勻隨機采樣。例如假設總共有1000個候選負樣本(區間1:800個,區間2:120個,區間3:80個),分為3個區間,總共想取333個,那么理論上每個區間是111個,首先第一次在不同區間均勻采樣,此時區間1可以采樣得到111個,區間2也可以得到111個,區間3不夠,所以全部保留;然后不夠的樣本數,在剩下的(800-111)+(120-111)+0個里面隨機取31個,最終補齊333個。核心代碼如下:
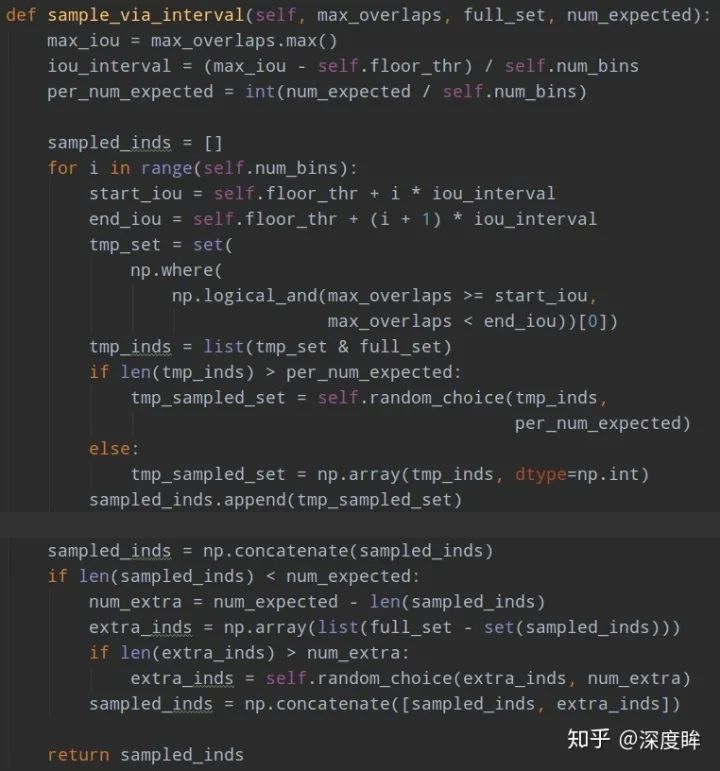
意思是在各個區間內,如果夠數目就隨機采樣,如果不夠那就剩下的負樣本里面全部采樣。
(2) 平衡回歸loss
原始的faster rcnn的rcnn head,使用的回歸loss是smooth l1,作者認為這個依然存在不平衡。作者分析是:loss解決Classification和Localization的問題,屬于多任務loss,那么就存在一個平衡權重,一般來說回歸權重會大一些,但一味的提高regression的loss其實會讓outlier的影響變大(類似于OHEM中的noise label),outlier外點樣本這里作者認為是樣本損失大于等于1.0,這些樣本會產生巨大的梯度不利于訓練過程,小于的叫做inliers。平衡回歸loss的目的是既不希望放大外點對梯度的影響,又要突出內點中難負樣本的梯度,從而實現對外點容忍,對內點區分難負樣本的作用。為此作者在smooth l1的基礎上進行重新設計,得到Balanced L1 Loss。核心操作就是想要得到一個當樣本在附近產生稍微大點的梯度的函數。首先smooth l1的定義如下:
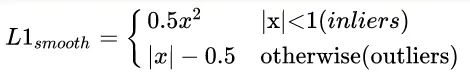
其梯度如下:
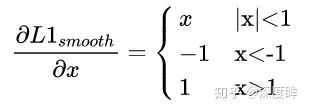
為了突出難樣本梯度,需要重新設計梯度函數,作者想到了如下函數:

梯度公式可以實現上述任務。然后反向計算就可以得到Loss函數了。為了保證連續,還需要增加(9)的限制。
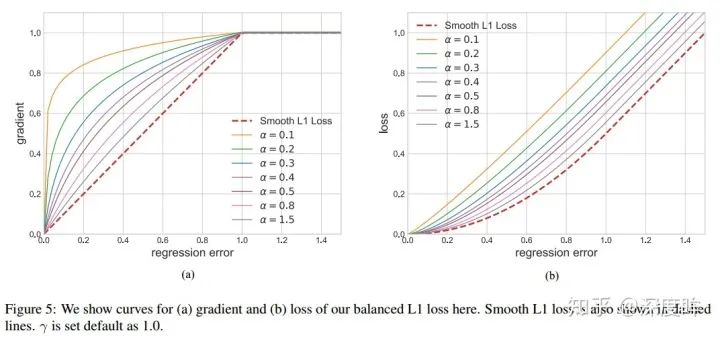
左邊是梯度曲線,右邊是loss曲線,可以看出非常巧妙。
1.2 one-stage
1.2.1 focal loss
論文名稱:Feature Pyramid Networks for Object Detection
該論文也叫做retinanet,是目前非常主流的FPN目標檢測one-stage網絡結構,本文主要是提出了一個focal loss來對難易樣本進行平衡,屬于平衡loss范疇。
(1) 網絡結構
由于該網絡結構非常流行,故這里僅僅簡要說明下,不做具體分析。
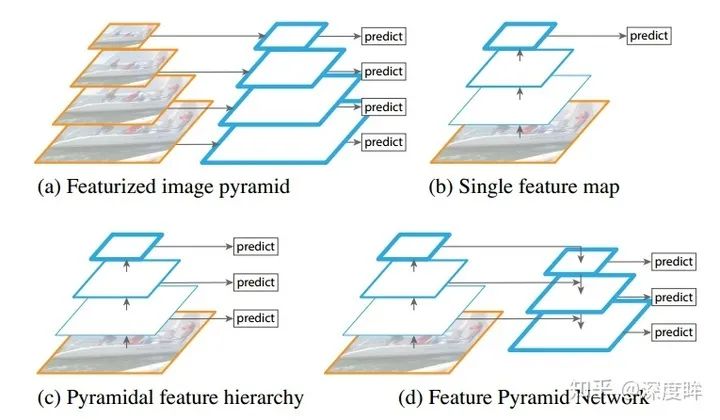
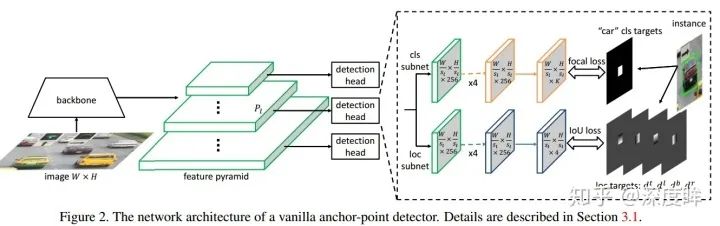
圖(d)即為retinanet的網絡結構。主要特點是:(1) 多尺度預測輸出;(2) 采用FPN結構進行多層特征圖融合。網絡進行多尺度預測,尺度一共是5個,每個尺度共享同一個head結構,但是分類和回歸分支是不共享權重的。
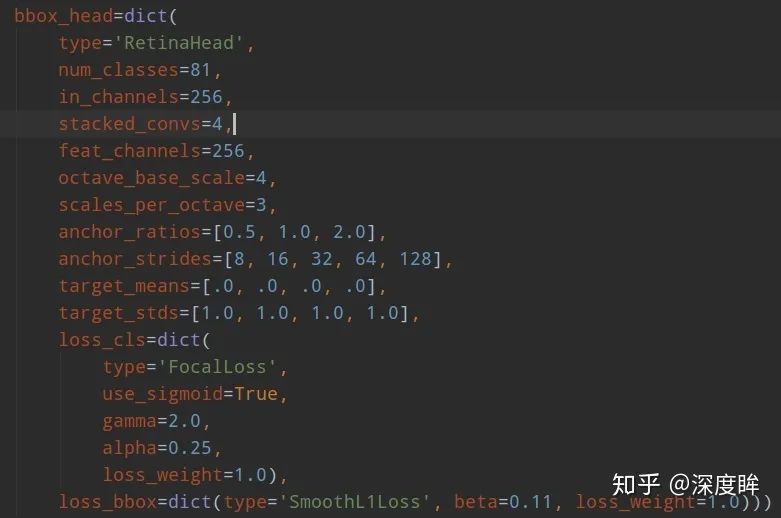
為了方便和faster rcnn進行對比,下面再次貼出rpn結構,并解釋參數含義。
1. 共同部分
anchor_strides表示對應的特征圖下采樣次數,由于retinanet是從stage1開始進行多尺度預測,故其stride比rpn大一倍;anchor_ratios表示anchor比例,一般是1:1,1:2和2:1三種;
2. 不同部分
rpn中的anchor_scales表示每個特征尺度上anchor的base尺度,例如這里是8,表示設定的anchor大小是8_[4,8,16,32,64],可以看出每個預測層是1個size * 3個比例,也就是每個預測層是3個anchor;而retianet是不同的,scales_pre_octave=3表示每個尺度上有3個scale size,分別是__,而octave_base_scale=4,意思其實和rpn的anchor_scales意思一樣,但是這里換個名字是因為retinanet的scale值是固定的,就一個值,而rpn可能是多個值;通過上面的設置,retinanet的每個預測層都有scale_pre_octivate_len(anchor_ratios)個anchor,這里是9個,是非常多的,anchor的大小是octave_base_scale * [8,16,32,64,128]。可以明顯發現retinanet正負樣本不平衡問題比faster rcnn更加嚴重。
(2) 正負樣本定義
retinanet是one-stage算法,其采用的正負樣本定義操作是MaxIoUAssigner,閾值定義和rpn不一樣,更加嚴格。如下所示:
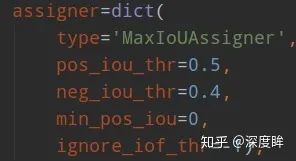
min_pos_iou=0,可以保證每個GT一定有對應的anchor負責預測。0.4以下是負樣本,0.5以上且是最大Iou的anchor是正樣本0.4~0.5之間的anchor是忽略樣本。其不需要正負樣本采樣器,因為其是通過平衡分類loss來解決的。
(3) 平衡分類loss
FocalLoss是本文重點,是用于處理分類分支中大量正負樣本不平衡問題,或者說大量難易樣本不平衡問題。作者首先也深入分析了OHEM的不足:它通過對loss排序,選出loss最大的example來進行訓練,這樣就能保證訓練的區域都是hard example,這個方法的缺陷,是把所有的easy example(包括easy positive和easy negitive)都去除掉了,造成easy positive example無法進一步提升訓練的精度(表現的可能現象是預測出來了,但是bbox不是特別準確),而且復雜度高影響檢測效率。故作者提出一個簡單且高效的方法:Focal Loss焦點損失函數,用于替代OHEM,功能是一樣的,需要強調的是:FL本質上解決的是將大量易學習樣本的loss權重降低,但是不丟棄樣本,突出難學習樣本的loss權重,但是因為大部分易學習樣本都是負樣本,所以順便解決了正負樣本不平衡問題。其是根據交叉熵改進而來,本質是dynamically scaled cross entropy loss,直接按照loss decay掉那些easy example的權重,這樣使訓練更加bias到更有意義的樣本中去,說通俗點就是一個解決分類問題中類別不平衡、分類難度差異的一個 loss。
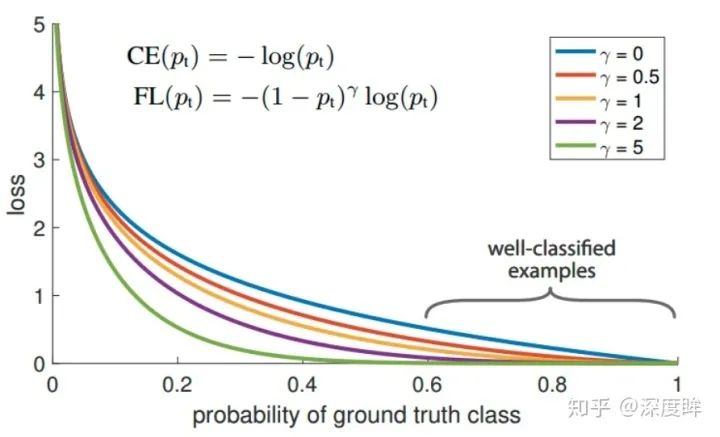
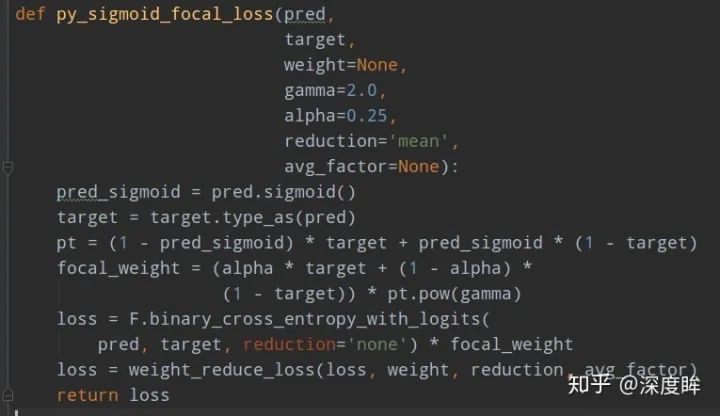
上面的公式表示label必須是one-hot形式。只看圖示就很好理解了,對于任何一個類別的樣本,本質上是希望學習的概率為1,當預測輸出接近1時候,該樣本loss權重是很低的,當預測的結果越接近0,該樣本loss權重就越高。而且相比于原始的CE,這種差距會進一步拉開。由于大量樣本都是屬于well-classified examples,故這部分樣本的loss全部都需要往下拉。其簡單思想版本如下:
1.2.2 yolov2 or yolov3
論文名稱:YOLOv3: An Incremental Improvement
yolov2和yolov3差不多,主要是網絡有差異,不是我們分析的重點,下面以yolov3為例。
(1) head結構
yolov3也是多尺度輸出,每個尺度有3個anchor。對于任何一個分支都是輸出[anchor數×(x,y,w,h,confidence,class類別數)h',w']。需要注意的是,其和faster rcnn或者ssd不一樣,其類別預測是不考慮背景的,所以才多引入了一個confidence的概念,該分支用于區分前景和背景。,所以最復雜的設計就在condidence上面了。
(2) 正負樣本定義
yolo系列的正負樣本定義比較簡單,原則和MaxIoUAssigner(固定anchor和gt值計算)非常類似,但是更加簡單粗暴:保證每個gt bbox一定有一個唯一的anchor進行對應,匹配規則就是IOU最大,而沒有考慮其他亂七八糟的。具體就是:對于某個ground truth,首先要確定其中心點要落在哪個cell上,然后計算這個cell的每個anchor與ground truth的IOU值,計算IOU值時不考慮坐標,只考慮形狀(因為anchor沒有坐標xy信息),所以先將anchor與ground truth的中心點都移動到同一位置(原點),然后計算出對應的IOU值,IOU值最大的那個先驗框anchor與ground truth匹配,對應的預測框用來預測這個ground truth。這個匹配規則和ssd和faster rcnn相比,簡單很多,其沒有啥閾值的概念。對于分類分支和bbox回歸分支,采用上述MaxIoU分配原則,可以保證每個gt bbox一定有唯一的anchor進行負責預測,而不考慮閾值,即使某些anchor與gt的匹配度不高也負責,而faster rcnn里面的MaxIoUAssigner是可能由于anchor設置不合理導致某個gt沒有anchor進行對應,而變成忽略區域的。可以看出這種分配制度會導致正樣本比較少。對于confidence分支,其在上述MaxIoU分配原則下,還需要從負樣本中劃分出額外的忽略區域。因為有些anchor雖然沒有和gt有最大iou,但是其iou依然很高,如果作為正樣本來對待,由于質量不是很高以及為了和分類、回歸分支的正樣本定義一致,所以不適合作為正樣本,但是如果作為負樣本那也不合適,畢竟iou很大,這部分位置的anchor就應該設置為忽略區域,一般忽略iou閾值是0.7即將負樣本中的iou大于0.7中的anchor設置為忽略區域(需要特別注意一個細節:此處的iou是每個位置的anchor預測值和所有gt計算iou,而不是固定的anchor和所有gt計算iou,因為此處需要考慮位置信息,faster rcnn系列不需要這么算的原因是faster rcnn是每個位置都會預測xywh,而yolo系列是基于grid網格預測,xy和wh預測是分開來的,所以會更復雜一些)。總結就是:
1.基于max iou分配準則,區分正負樣本
2.在負樣本范圍內,將iou(基于anchor預測值和gt計算)大于忽略閾值的anchor定義為忽略區域,實時改變
3.此時就區分出了正、負和忽略anchor樣本,正anchor用于分類、回歸分支學習,正負anchor用于confidence分支學習,忽略區域不考慮。
對于yolov3,由于是多尺度預測,故還有一個細節需要注意:首先需要將gt利用 max iou原則分配到不同的預測層上去,然后在每個層上單獨計算正負樣本和忽略樣本,也就是和faster rcnn不一樣的地方是yolov3不存在某個gt會分配到多個層進行預測的可能性,而是一定是某一層負責的。但是不同的具體代碼實現時候可能會有些許差別。
(3) loss
由于其采用的是普通的bce分類Loss和smooth l1 回歸loss,故不再進行分析。
1.2.3 ssd
論文地址:SSD: Single Shot MultiBox Detector
(1) head結構
ssd是最典型的多尺度預測結構,是非常早期的網絡。
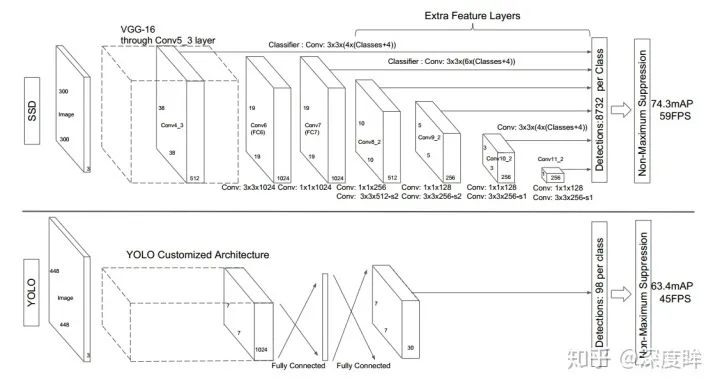
其ssd300的head結構如下:
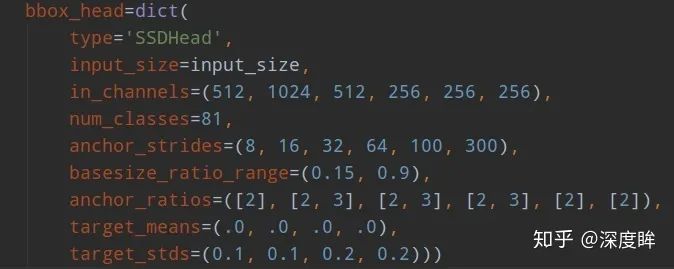
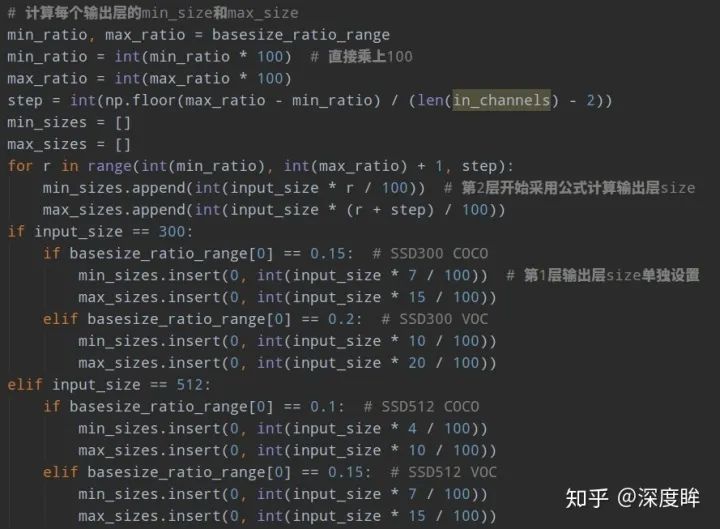
可以看出,ssd一共包括6個尺度輸出,每個尺度的strides可以從anchor_strides中看出來,basesize_ratio_range表示正方形anchor的min_size和max_size,anchor_ratios表示每個預測層的anchor個數,以及比例。有點繞,下面具體分析。為了方便設置anchor,作者設計了一個公式來生成anchor,具體為:
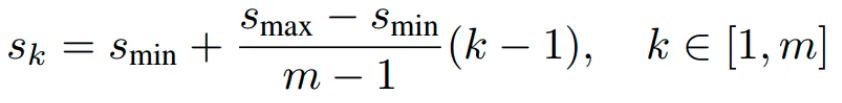
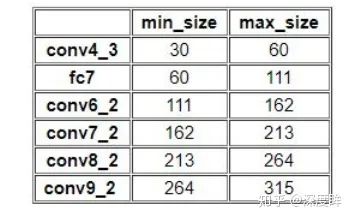
k為特征圖索引,m為5,而不是6,因為第一層輸出特征圖Conv4_3比較特殊,是單獨設置的,表示anchor大小相對于圖片的比例,和是比例的最小和最大值,論文中設置min=0.2(ssd300中,coco數據集設置為0.15,voc數據集設置為0.2),max=0.9,但是實際上代碼不是這樣寫的。實際上是:對于第一個特征圖Conv4_3,其先驗框的尺度比例一般設置為,故第一層的=0.1,輸入是300,故conv4_3的min_size=30。對于從第二層開始的特征圖,則利用上述公式進行線性增加,然后再乘以圖片大小,可以得到各個特征圖的尺度為60,111,162,213,264。最后一個特征圖conv9_2的size是直接計算的,300*105/100=315。以上計算可得每個特征的min_size和max_size,如下:
計算得到min_size和max_size后,需要再使用寬高比例因子來生成更多比例的anchor,一般選取,但是對于比例為1的先驗框,作者又單獨多設置了一種比例為1,的尺度,所以一共是6種尺度。但是在實現時,Conv4_3,Conv8_2和Conv9_2層僅使用4個先驗框,它們不使用長寬比為3,1/3的先驗框,每個單元的先驗框的中心點分布在各個單元的中心。具體細節如下:
以feature map上每個點的中點為中心(offset=0.5),生成一些列同心的prior box(然后中心點的坐標會乘以step,相當于從feature map位置映射回原圖位置)。
正方形prior box最小邊長為和最大邊長為:min_size和
根據aspect ratio,會生成2個長方形,長寬為
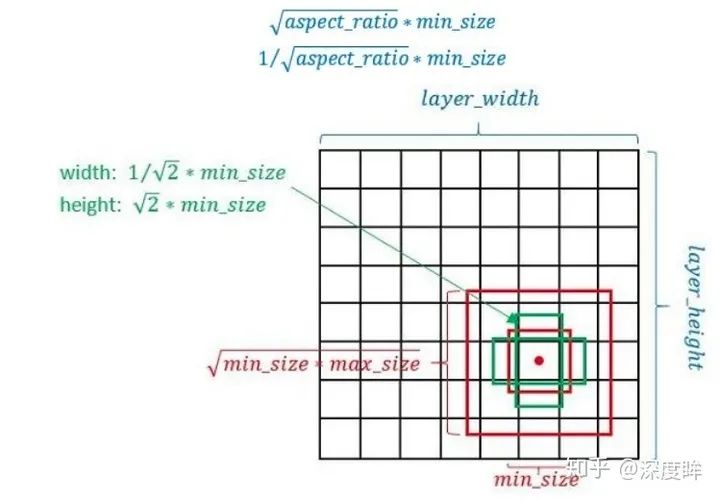
目的是保存在該比例下,面積不變。以fc7為例,前面知道其min_size=60,max_size=111,由于其需要6種比例,故生成過程是:
第一種比例,(min_size,min_size)=(60,60)
第二種比例,,
第三種比例,,
第四種比例,(sqrt{60×110},sqrt{60×110})$
不管哪個框架實現,核心思想都是一樣,但是可能某些數據的設置不一樣。下面以mmdetection為例:
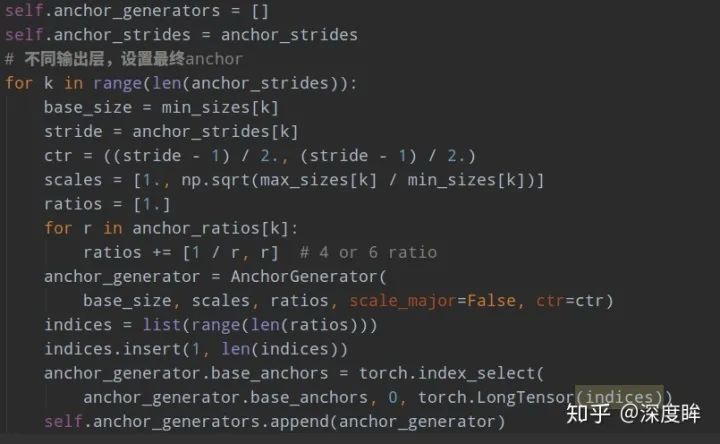
(2) 正負樣本定義
ssd采用的正負樣本定義器依然是MaxIoUAssigner,但是由于參數設置不一樣,故有了不同的解釋。
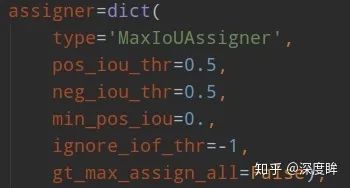
其定義anchor與gt的iou小于0.5的就全部認為是負樣本,大于0.5的最大iou樣本認為是正樣本anchor,同時由于min_pos_iou=0以及gt_max_assign_all=False,可以發現該設置的結果是每個gt可能和多個anchor匹配上,匹配閾值比較低,且每個gt一定會和某個anchor匹配上,不可能存在gt沒有anchor匹配的情況,且沒有忽略樣本。總結下意思就是:
anchor和所有gt的iou都小于0.5,則認為是負樣本
anchor和某個gt的最大iou大于0.5,則認為是正樣本
gt和所有anchor的最大iou值,如果大于0.0,則認為該最大iou anchor是正樣本
沒有忽略樣本
(3) 平衡分類loss
由于正負樣本差距較大,如果直接采用ce和smooth l1訓練,效果可能不太好,比較樣本不平衡嚴重。故作者的ce loss其實采用了ohem+ce的策略,通過train_cfg.neg_pos_ratio=3來配置負樣本是正樣本的3倍。
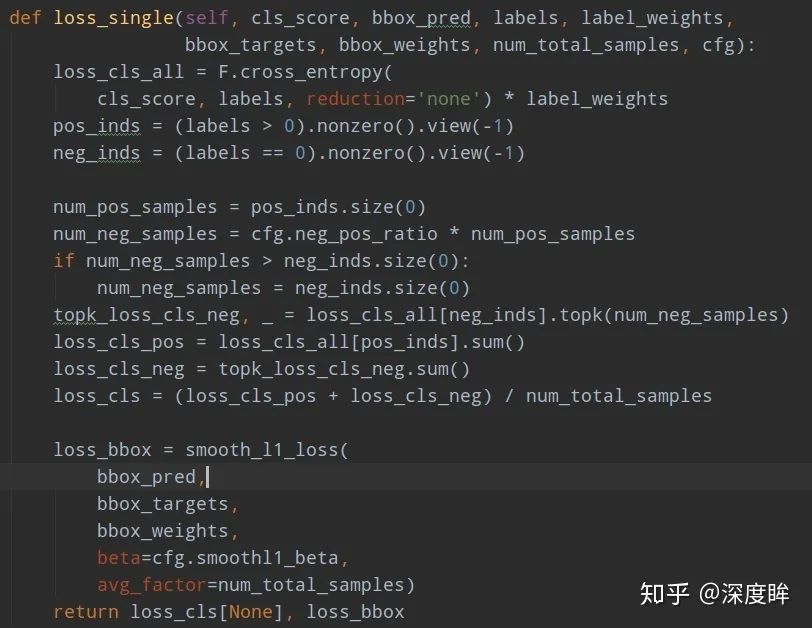
核心就是按照分類loss進行topk,得到3倍的負樣本進行反向傳播。
2 anchor-free
2.1 fcos
論文名稱:FCOS: Fully Convolutional One-Stage Object Detection
FCOS堪稱anchor free論文的典范,因為其結構主流,思路簡單清晰,效果蠻好,故一直是后續anchor free的基準對比算法。FCOS的核心是將輸入圖像上的位置作為anchor point的中心點,并且對這些anchor point進行回歸。
(1) head結構
fcos的骨架和neck部分是標準的resnet+fpn結構,和retinanet完全相同。如下所示:
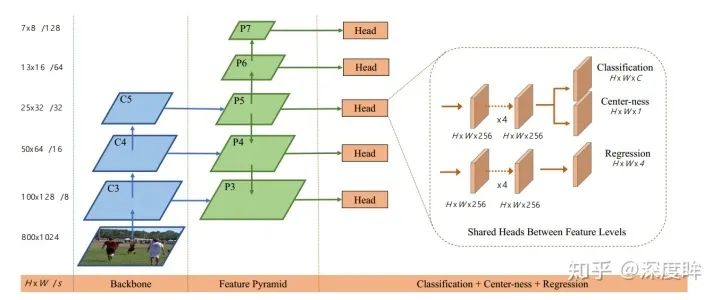
我們僅僅考慮head部分。除去center-ness分支,則可以看出和retinanet完全相同。其配置如下:
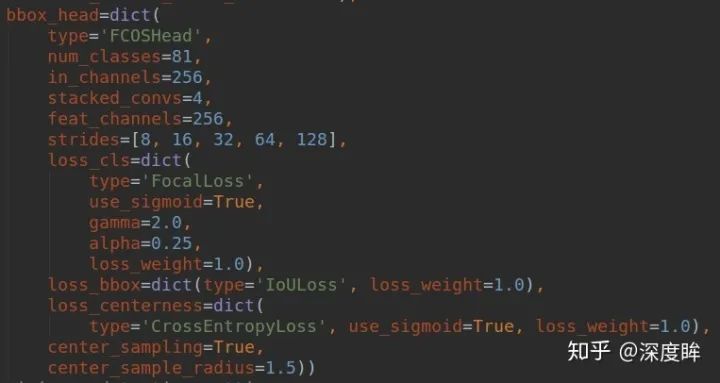
可以看出一共5個尺度進行預測,每個尺度的stride可以從strides中看出來。由于其是anchor free論文,故少了很多復雜參數。
(2) 正負樣本定義
考慮到anchor free預測值和anchor base不一樣,故還是需要提前說下網絡預測形式。FCOS是全卷積預測模式,對于cls分支,輸出是h x w x (class+1),每個空間位置值為1,表示該位置有特定類別的gt bbox,對于回歸分支,輸出是h x w x 4,其4個值的含義是:

每個點回歸的4個數代表距離4條邊的距離,非常簡單易懂。和所有目標檢測算法一樣,需要提前定義好正負樣本,同時由于是多尺度預測輸出,還需要首先考慮gt由哪一個輸出層具體負責。作者首先設計了min_size和max_size來確定某個gt到底由哪一層負責,具體設置是0, 64, 128, 256, 512和無窮大,也就是說對于第1個輸出預測層而言,其stride=8,負責最小尺度的物體,對于第1層上面的任何一個空間位置點,如果有gt bbox映射到特征圖上,滿足0 < max(中心點到4條邊的距離) < 64,那么該gt bbox就屬于第1層負責,其余層也是采用類似原則。總結來說就是第1層負責預測尺度在0~64范圍內的gt,第2層負責預測尺度在64~128范圍內的gt,其余類推。通過該分配策略就可以將不同大小的gt分配到最合適的預測層進行學習。
第二步是需要確定在每個輸出層上面,哪些空間位置是正樣本區域,哪些是負樣本區域。原版的fcos的正負樣本策略非常簡單粗暴:在bbox區域內的都是正樣本,其余地方都是負樣本,而沒有忽略樣本區域。可想而知這種做法不友好,因為標注本身就存在大量噪聲,如果bbox全部區域都作為正樣本,那么bbox邊沿的位置作為正樣本負責預測是難以得到好的效果的,顯然是不太靠譜的(在文本檢測領域,都會采用shrink的做法來得到正樣本區域),所以后面又提出了center sampling的做法來確定正負樣本,具體是:引入了center_sample_radius(基于當前stride參數)的參數用于確定在半徑范圍內的樣本都屬于正樣本區域,其余區域作為負樣本,依然沒有定義忽略樣本。默認配置center_sample_radius=1.5,如果第1層為例,其stride=8,那么也就是說在該輸出層上,對于任何一個gt,基于gt bbox中心點為起點,在半徑為1.5*8=12個像素范圍內都屬于正樣本區域。其核心代碼如下:
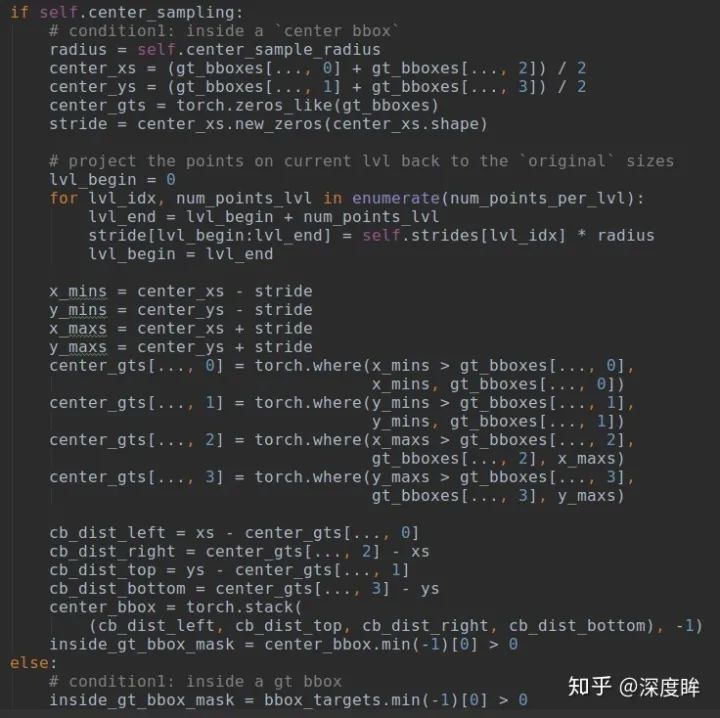
如果需要進行中心采樣,那么基于采樣半徑比例×當前stride的范圍內都屬于正樣本inside_gt_bbox_mask,其余樣本全部屬于負樣本。可能很多人都有疑問:為啥不需要設置忽略區域?個人猜測原因可能是:1. 設置忽略區域,又需要增加一個超參;2.多了一個center-ness分支,可以很大程度抑制這部分區域對梯度的影響。3.間接的增加了正樣本數目。不管咋說應該是作者實驗后發現沒有很大必要吧。
(3) 平衡loss設計
可以發現上述肯定存在大量正負樣本不平衡問題,故作者對于分類分支采用了one-stage常用的focal loss;對于bbox回歸問題,由于很多論文表明直接優化bbox比單獨優化4個值更靠譜,故作者采用了GIOU loss來回歸4個值,對于center-ness分支,采用的是CrossEntropyLoss,當做分類問題處理。
(4) 附加內容
center-ness作用比較大,從上面的正負樣本定義就可以看出來,如果沒有center-ness,對于所有正樣本區域,其距離bbox中心不同遠近的loss權重居然是一樣的,這明顯是違反直覺的,理論上應該越是遠離Bbox中心的空間位置,其權重應該越小,作者實驗也發現如果沒有center-ness分支,會產生大量假正樣本,導致很多虛檢。center-ness本質就是對正樣本區域按照距離gt bbox中心來設置權重,這是作者的做法,還有很多類似做法,不過有些是在Loss上面做文章,例如在ce loss基礎上乘上一個類似預center-ness的權重來實現同樣效果(例如Soft Anchor-Point Object Detection)。center-ness效果如下:

2.2 centernet
論文名稱:Objects as Points
centernet也是非常流行的anchor-free論文,其核心是:一些場景的cv任務例如2d目標檢測、3d目標檢測、深度估計和關鍵點估計等等任務都可以建模成以物體中心點學習,外加上在該中心點位置處額外學習一些各自特有屬性的通用做法。對于目標檢測,可以將bbox回歸問題建模成學習bbox中心點+bbox寬高問題,如下所示:

(1) head結構
centernet的輸出也非常簡單,其相比較于FCOS等算法,使用更大分辨率的輸出特征圖(縮放了4倍),本質上是因為其采用關鍵點檢測思路做法,而關鍵點檢測精度要高,通常是需要輸出高分辨率特征圖,同時不需要多尺度預測。其輸出預測頭包含3個分支,分別是
1. 分類分支h' x w' x (c+1),如果某個特定類的gt bbox的中心點落在某個位置上,那么該通道的對應位置值設置為1,其余為0;
2. offset分支h' x w' x 2,用于學習量化偏差,圖像下采樣時,gt bbox的中心點會因數據是離散的而產生偏差,例如gt bbox的中心點坐標是101,而由于輸入和輸出相差4倍,導致gt bbox映射到特征圖上坐標由25.25量化為了25,這就出現了101-25x4=1個pix的誤差,如果下采樣越大,那么量化誤差會越大,故可以使用offset分支來學習量化誤差,這樣可以提高預測精度。
3. 寬高分支h' x w' x 2,表示gt bbox的寬高。
其中1.2分支和cornetnet的做法完全相同。而由于objects as points的建模方式和FCOS的建模方式不一樣,故centernet的正負樣本定義就會產生很大區別。主要是寬高分支的通道數是2,而不是4,也就是說其輸入到寬高分支的正樣本其實會非常少,必須是gt bbox的中心位置才是正樣本,左右偏移位置無法作為正樣本,也沒有啥忽略樣本的概念,這個是和FCOS的最大區別。
(2) 正負樣本定義
由于centernet特殊的建模方式,故其正負樣本定義特別簡單,不需要考慮多尺度、不需要考慮忽略區域,也不用考慮iou,正樣本定義就是某個gt bbox中心落在哪個位置上,那么那個位置就是正樣本,其余位置全部是負樣本。
(3) 平衡Loss設計
前面說過目標檢測所有論文的樣本平衡策略都主要包括正負樣本定義、正負樣本采樣和平衡loss設計,不管啥目標檢測算法都省不了,對于centernet,其正負樣本定義非常簡單,可以看出會造成極其嚴重的正負樣本不平衡問題,然后也無法像two-stage算法一樣設計正負樣本采樣策略,那么平衡問題就必須要在loss上面解決。對于offset和寬高預測分支,其只對正樣本位置進行監督,故核心設計就在平衡分類上面。對于分類平衡loss,首選肯定是focal loss了,但是還不夠,focal loss的核心是壓制大量易學習樣本的權重,但是由于我們沒有設置忽略區域,在正樣本附近的樣本,實際上非常靠近正樣本,如果強行設置為0背景來學習,那其實相當于難負樣本,focal loss會突出學這部分區域,導致loss難以下降、不穩定,同時也是沒有必要的,因為我們的label雖然是0或者1的,但是在前向后處理時候是當做高斯熱圖(0~1之間呈現2d高斯分布特點)來處理的,我們學到最后的輸出只要滿足gt bbox中心值比附近區域大就行,不一定要學習出0或者1的圖。
基于上述設定,在不修改分類分支label的情況下,在使用focal loss的情況下,作者的做法是對正樣本附近增加懲罰,基于2d高斯分布來降低這部分權重,相當于起到了類似于忽略區域的作用。可以簡單認為是focal focal loss。
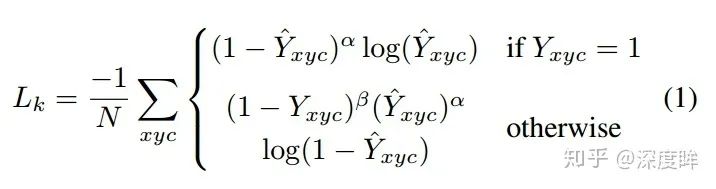
其中
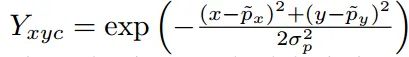
Y是label,0或者1,當Y=1時候,也就是正樣本位置,就是標準的focal loss設定;其余區域,分為附近區域和外圍區域,附近的定義采用了自適應寬高標準差的做法,在2d高斯分布內部的屬于附近區域,外面的都稱為外圍背景區域,外圍區域也是標準的focal loss定義。故作者設計更改的就是附近區域,也就是,可以發現如果去掉,就是標準的focal loss。附近區域中越靠近中心點的懲罰Y越大,Loss權重越小,表示該位置對于正還是負的區分越模糊。
可能很多人有疑問:明明label是0-1的,為啥學出來的會是高斯熱圖,而不是0-1熱圖?我的分析是:如果不考慮附近區域,而是僅僅采用focal loss那么確實應該學出來的最接近0-1熱圖,但是由于基于距離gt bbox中心遠近不同,設置了不同的懲罰系數,導致網絡學習時候對于這部分學習出來的值關注程度不一樣,可能就會產生這種現象,舉例來說:即使采用上述label,最完美的輸出應該是0或1的,但是實際上很難,對于偏離gt bbox附近一點點的位置,假設其預測輸出為0,那么肯定是loss最低,但是可能訓練不到那么好,那么由于其權重比較小,其學習出0.9,其實loss也不會太大,但是如果距離遠一點的,其也學習出0.9,由于其loss權重比較大,就會迫使網絡預測要變小一點點,例如變成0.8輸出。基于這種權重分布,訓練出來的熱圖可能就會按照1-loss權重的分布呈現,出現高斯熱圖。學習關鍵點中心,作者采用的是分類loss,不清楚如果直接采用回歸loss,效果咋樣,我覺得效果應該不會差。因為關鍵點檢測一般都是采用l2回歸loss直接監督在高斯熱圖上。并且因為寬高、offset分支其實也都是回歸loss,三個分支都采用回歸Loss不好嗎?
還有一個問題:寬高和offset的監督僅僅在gt bbox中心位置,其余位置全部是忽略區域。這種做法其實很不魯棒,也就是說bbox性能其實完全靠分類分支,如果分類分支學習的關鍵點有偏差,那么由于寬高的特殊監督特性,可能會導致由于中心點定位不準而帶來寬高不準的情況(特別的如果中心點預測丟失了,那么寬高預測再準也沒有用),后面有些論文有其他解決辦法,
2.3 atss
論文名稱:Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
本文寫的非常好,作者試圖分析問題:anchor-free和anchor-base算法的本質區別是啥?性能為啥不一樣?最終結論是其本質區別就在于正負樣本定義不同。只要我們能夠統一正負樣本定義方式,那么anchor-free和anchor-base就沒有啥實際區別了,性能也是非常一致的。正負樣本定義也是我寫這篇文章的一個最大要說明的地方,因為其非常關鍵,要想徹底理解不同目標檢測算法的區別,那么對于正負樣本定義必須要非常清楚。
(1) head部分
由于這篇論文細節比較多,為了論文完整性,我這里大概說下,不重點描述。作者為了找出本質區別,采用了anchor-base經典算法retinanet以及anchor-free經典算法FCOS來說明,因為這兩篇論文非常相似,最好進行對比。

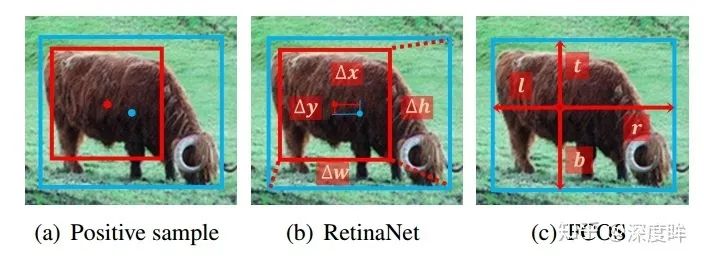
由于FCOS是基于point進行預測,故可以認為就是一個anchor,為了公平對比,將retinanet的anchor也設置為1個(#A=1),將FCOS的訓練策略移動到retinanet上面,可以發現性能依然retinanet低于fcos 0.8mAP。排除這個因素后,現在兩個算法的區別是1.正負樣本定義;2.回歸分支中從point回歸還是從anchor回歸。從point回歸就是指的每個點預測距離4條邊的距離模式,而從anchor回歸是指的retinanet那種基于anchor回歸的模式。
后面有實驗分析可以知道回歸分支中從point回歸還是從anchor回歸對最終影響很小。ATSS的head部分結構如下:
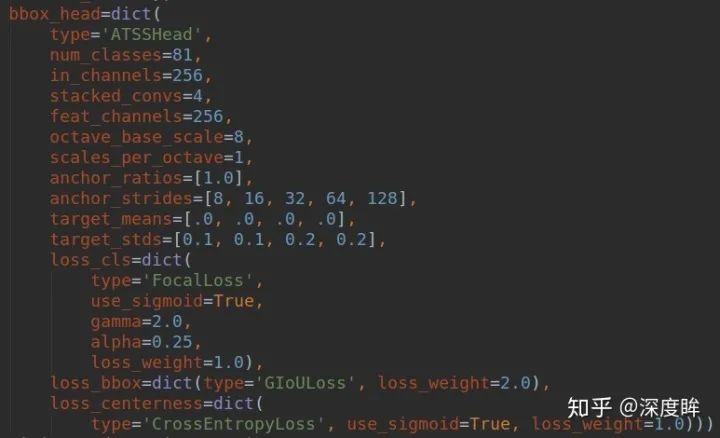
可以看出所有的參數其實就是retinanet和fcos參數的合并而已,沒有新增參數。
(2) 正負樣本定義
正負樣本定義是本文的討論重點。作者首先詳細分析了retinanet和fcos的正負樣本定義策略的不同,首先這兩個算法都是多尺度預測的,故其實都包括兩個步驟:gt分配給哪一層負責預測;gt分配給哪一個位置anchor負責預測。retinanet完全依靠統一的iou來決定哪一層哪一個位置anchor負責預測,而fcos顯式的分為兩步:先利用scale ratio來確定gt分配到哪一層,然后利用center sampling策略來確定哪些位置是正樣本。具體細節請參見的retinanet和fcos的正負樣本定義總結。這兩種操作的細微差別會導致如下情形:
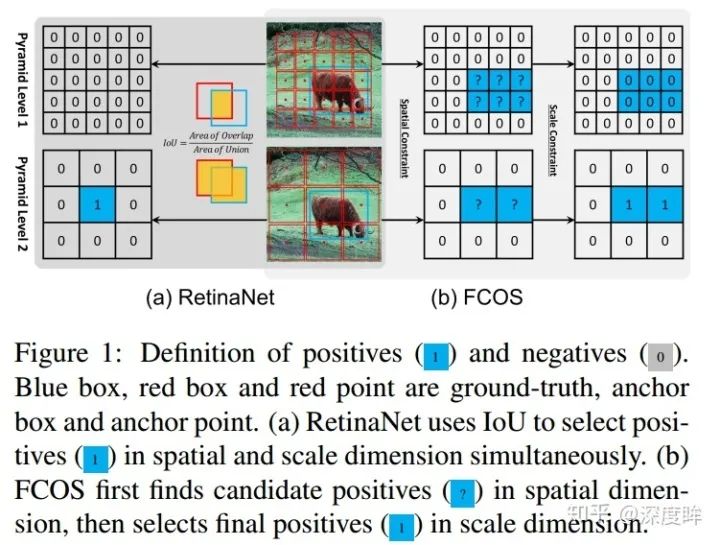
對于1和2兩個輸出預測層,retinanet采用統一閾值iou,可以確定上圖藍色1位置是正樣本,而對于fcos來說,有2個藍色1,表明fcos的定義方式會產生更多的正樣本區域。這種細微差距就會導致retinanet的性能比fcos低一些。
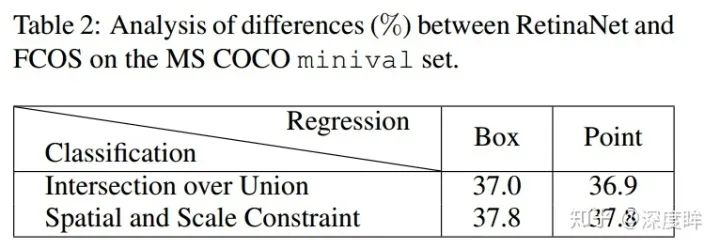
對于retinanet算法,正負樣本定義采用iou閾值,回歸分支采用原始的anchor變換回歸模式(box),mAP=37.0,采用fcos的point模式是36.9,說明到底是point還是box不是關鍵因素。但是如果換成fcos的正負樣本定義模式,mAP就可以上升為37.8,和fcos一致了,說明正負樣本定義的不同是決定anchor-base和anchor-free的本質區別。
既然找到了本質問題,作者分析肯定是fcos的正負樣本定義策略比retinanet好,但是fcos算法需要定義超參scale constraint,比較麻煩,作者希望找到一種和fcos類似功能的正負樣本定義算法,主要特定是幾乎沒有超參,或者說對超參不敏感,可以自適應,故作者提出ATSS算法。由于作者的設計可以認為是fcos正負樣本定義策略的改進版本,故mmdetection的代碼中也是針對fcos來說的,具體就是除了正負樣本定義策略和fcos不一樣外,其余全部相同,所以我們也僅僅需要關注atss部分代碼就行。

其只有一個參數topk,實驗表明參數適當就行,不敏感。下面具體分析ATSS:

流程比較簡單,但是需要注意,由于依然需要計算iou,故anchor的設置不能少,只不過anchor僅僅用于計算正負樣本區域而已,在計算loss時候還是anchor-free的,anchor默認設置就1個。主要是理解思想:
對于每個gt bbox,在每一個預測層上采樣tokp個基于l2距離的位置,作為候選;
計算gt和每個候選anchor的iou;計算所有iou的均值和方差,相加變成iou閾值(每個gt都有一個自適應的iou閾值);
遍歷每個候選anchor,如果該anchor大于iou閾值,并且anchor中心位置在gt bbox內部,那么這個就是正樣本區域,其余全部是負樣本。
均值(所有層的候選樣本算出一個均值)代表了anchor對gt衡量的普遍合適度,其值越高,代表候選樣本質量普遍越高,iou也就越大,而方差代表哪一層適合預測該gt bbox,方差越高越能區分層和層之間的anchor質量差異。均值和方差相加就能夠很好的反應出哪一層的哪些anchor適合作為正樣本。一個好的anchor設計,應該是滿足高均值、高方差的設定。
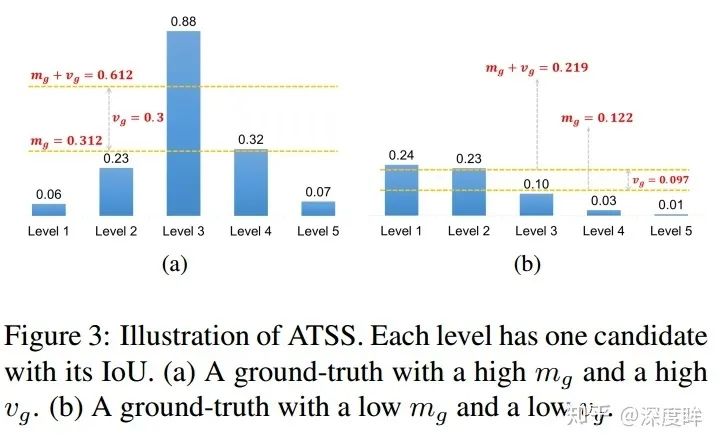
如上圖所示,(a)的閾值計算出來是0.612,采用該閾值就可以得到level3上面的才是正樣本,是高均值高方差的。同樣的如果anchor設置和gt不太匹配,計算出來的閾值為0.219,依然可以選擇出最合適的正樣本區域,雖然其屬于低均值、低方差的。采用自適應策略依然可以得到相對好的正負樣本,實現了自適應功能,至少可以保證每個GT一定有至少一個anchor負責對應。從這個設定來看,應該會出現某個gt在多個層上面都屬于正樣本區域,而沒有限制必須在其中某個層預測,相當于增加了些正樣本。K默認是9。
(3) 平衡loss設定
其loss函數設計完全和fcos一樣,不再贅述。
2.4 spad
論文名稱:Soft Anchor-Point Object Detection
本文可以認為是anchor-free論文的改進。其首先指出目前anchor-free算法存在的問題:1.attention bias,2.feature selection,并提出了相應的soft策略。由于其主要是修改了正負樣本定義策略,故是本文分析的重點。
(1) head
本文屬于anchor point類算法,即每個點都學習距離4條邊的距離,這是標準的densebox算法流程,本質上和FCOS一樣:
和FCOS的區別就在于 1. 沒有center-ness分支,2. 正樣本區域的定義采用4條邊向內shrink做法,而不是center sampling。
1.Attention bias
作者采用上面的網絡進行訓練,發現一個問題如下:
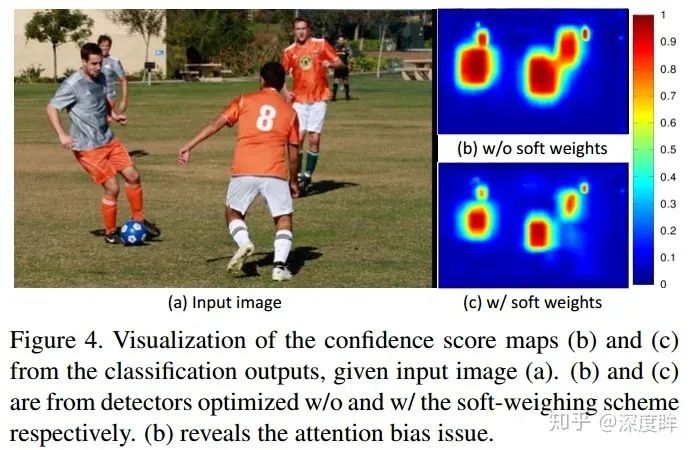
(b)是標準網絡訓練的分類confidence圖,可以看出在靠近物體中心的四周會依然會產生大量confidence很高的輸出,即沒有清晰的邊界,在訓練過程中可能會抑制掉周圍小的物體,導致小物體檢測不出來或者檢測效果很差。作者分析原因可能是在anchor-point方法在邊界地方point進行回歸,會存在特征不對齊問題或者說很難對齊。這個現象在FCOS沒有加center-ness時候也出現了,FCOS的解決辦法就是加入新的center-ness分支訓練時候抑制掉,本文解決辦法不一樣,其通過加權方法。加權后效果如(c)。
2.Feature selection
特性選擇問題其實是指的對于任何一個gt bbox,到底采用何種策略分配到不同的層級進行預測?目前目標檢測的做法是基于啟發式人工準則將實例分配到金字塔層次(retinanet),或將每個實例嚴格限制為單個層次(fcos),從而可能會導致特征能力的不充分利用。

作者通過訓練發現:雖然每個GT只在特定層進行回歸,但是其學出來的特征圖是相似的,如上圖所示,也就是說:一個以上金字塔等級的特征可以共同為特定實例的檢測做出貢獻,但是來自不同等級的貢獻程度應該有所不同。這就是本文的出發點,不再強行判斷哪一層進行回歸了,而是每一層都進行回歸,但是讓網絡自行學習到金字塔層級的權重。說了半天,作者仔細談到了這兩個問題,但思考下可以發現說的都是同一個問題,都是正負樣本定義問題。attention bias說的是對于特定輸出層內的正負樣本定義問題,feature selection說的則是不同輸出層間的正負樣本定義問題,我們以前說的正負樣本定義都是hard,這里解決辦法都是soft。
(2) 正負樣本定義
對于特定輸出層內的soft正負樣本定義問題,作者的解決辦法是引入類似center-ness一樣的權重,屬于Loss層面改進,我們放在(3) 平衡loss分析;對于不同輸出層間的soft正負樣本定義問題,作者采用的是采用網絡自動學習soft權重的做法。注意:輸出層內hard正負樣本定義,作者采用的依然和FCOS相同的策略,只不過正樣本區域是通過4條邊shrink得到,而不是center sampling。輸出層間hard正負樣本定義,作者沒有用FCOS的分配策略,而是提出了新的soft代替hard。本文不再強行判斷哪一輸出層進行gt bbox回歸了,而是每一層都進行所有gt bbox回歸,但是讓網絡自行學習到金字塔層級的權重。
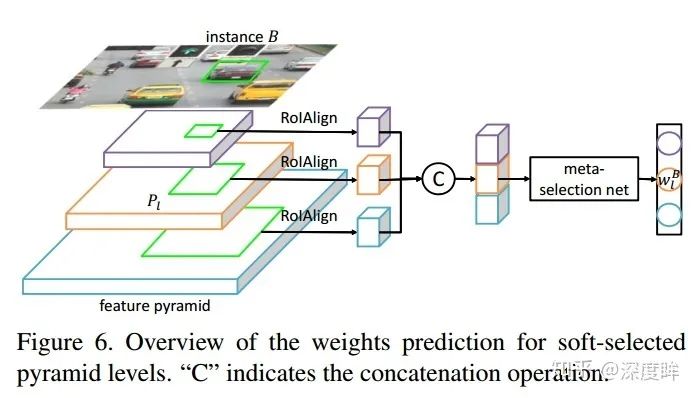
引入一個簡單的網絡來學習金字塔權重,具體做法是:利用gt bbox,映射到對應的特征圖層,然后利用roialign層提出特征,在采用簡單的分類器輸出每個層級的權重。由于金字塔層數是5,故fc的輸出是5。label設置上,這個思想的提出是參考FSAF(Feature Selective Anchor-Free Module for Single-Shot Object Detection)的做法,核心思想是不再人為定義具體是哪一層負責預測GT,而是根據loss最小的動態選擇的那個層。本文借鑒上述思想,也是自動選擇最適合的層。meta選擇網絡的獨熱碼label不是人為提前計算好的,而是根據輸出softmax層的值或者說loss來選擇的,哪個輸出節點loss最小,那么Label就設置為1,其余為0。整個meta選擇網絡和目標檢測網絡聯合訓練。
(3) 平衡loss設計
對于特定輸出層內的soft正負樣本定義問題,作者的解決辦法是引入類似center-ness一樣的權重,來對距離gt bbbx中心點進行懲罰。中心點權重最大,往外依次減少,其權重圖如fcos里面所示:
從本質上來說和centernet的解決辦法一模一樣。
看過前面centernet 平衡分類loss分析的人可能有疑問:在centernet里面,其對focal loss的權重設置是在半徑范圍內,除中心點外,離中心點越近,權重最小,往外依次增加;但是這里的設計是正好相反的,其是離中心點越近,權重越大,往外依次減少。看起來是矛盾的?其實不是,千萬不要忘記了label設計規則,centernet的分類label設置是除了中心點是1外,其余全部為0,而本文的label設置是不僅僅中心點是1,shrink附近區域的點也是1,其余全部是0,也就是說模糊區域中,centernet出發點認為是背景樣本,而本文出發點認為是前景樣本,所以其權重設置規則是正好相反的。
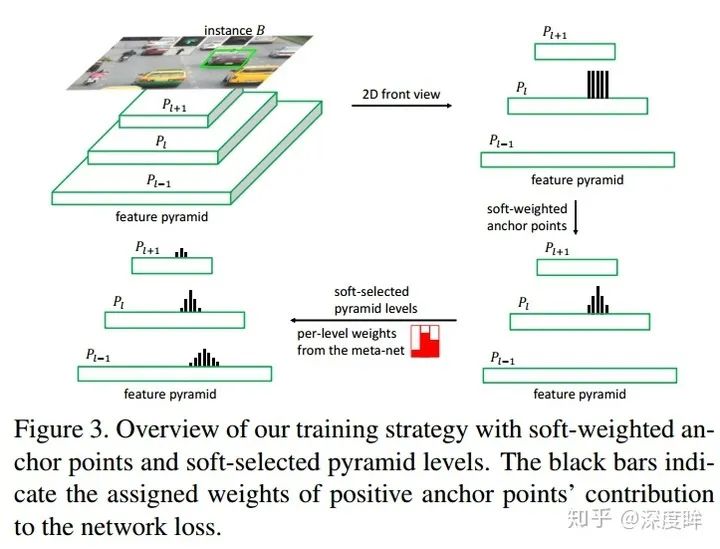
看到上圖,就可以知道本文所有的操作了。對于特定層內的正負樣本定義,原先是hard,現在通過引入權重變成了soft;對于層級間的正負樣本定義,原先只會分配到特定層,其余層都0,現在引入了soft操作,權重是自己學到的。
通過網絡學習到的層級間的權重,可以發現符合作者設定。
3 Guided Anchoring
論文名稱:Region Proposal by Guided Anchoring
3.1 核心思想
ga這篇論文我覺得做的蠻好,先不說最終效果提升多少個mAP,他的出發點是非常不錯的。anchor-base的做法都需要預設anchor,特別是對于one-stage而言,anchor設置的好壞對結果影響很大,因為anchor本身不會改變,所有的預測值都是基于anchor進行回歸,一旦anchor設置不太好,那么效果肯定影響很大。而對于two-stage而言,好歹還有一個rcnn層,其可以對RPN的輸出roi(動態anchor)進行回歸,看起來影響稍微小一點。不管是one stage還是two-stage,不管咋預測,肯定都是基于語義信息來預測的,在bbox內部的區域激活值肯定較大,這種語義信息正好可以指導anchor的生成,也就是本文的出發點:通過圖像特征來指導 anchor 的生成。通過預測 anchor 的位置和形狀,來生成稀疏而且形狀任意的 anchor。可以發現此時的anchor就是動態的了。如果將faster rcnn進行改造,將RPN層替換為ga層,那肯定也是可以的,如果將retinanet或者yolo的預測層替換為ga,那其實就完全變成了anchor-free了。但是作者采用了一種更加優雅的實現方式,其采用了一種可以直接插入當前anchor-base網絡中進行anchor動態調整的做法,而不是替換掉原始網絡結構,屬于錦上添花,從此anchor-base就變成了anchor-base混合anchor-free了(取長補短),我覺得這就是一個不錯的進步。
3.2 網絡設計
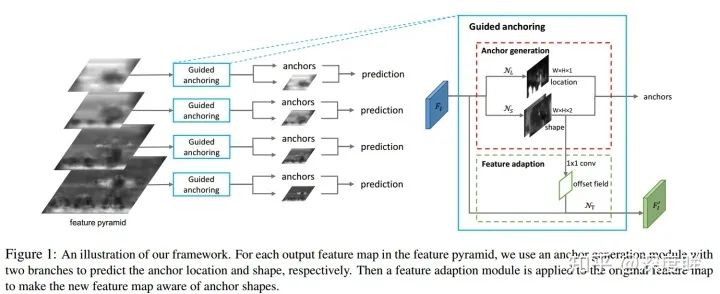
作者是以retinanet為例,但是可以應用于所有anchor-base論文中。核心操作就是在預測xywh的同時,新增兩條預測分支,一條分支是loc(batch,anchor_num * 1,h,w),用于區分前后景,目標是預測哪些區域應該作為中心點來生成 anchor,是二分類問題,這個非常好理解,另一條分支是shape(batch,anchor_num * 2,h,w),用于預測anchor的形狀。一旦訓練好了,那么應該anchor會和語義特征緊密聯系,如下所示:

其測試流程為:
對于任何一層,都會輸出4條分支,分別是anchor的loc_preds,anchor的shape_preds,原始retinanet分支的cls_scores和bbox_preds
使用閾值將loc_preds預測值切分出前景區域,然后提取前景區域的shape_preds,然后結合特征圖位置,concat得到4維的guided_anchors(x,y,w,h)
此時的guided_anchors就相當于retinanet里面的固定anchor了,然后和原始retinanet流程完全相同,基于guided_anchors和cls_scores、bbox_preds分支就可以得到最終的bbox預測值了。
可以發現和原始retinanet相比,就是多了anchor預測分支,得到動態anchor后,那就是正常的retinanet預測流程了。
3.3 loss設計
主要就是anchor的loc_preds和shape_preds的loss設計。
(1) loc_preds
anchor的定位模塊非常簡單,就是個二分類問題,希望學習出前景區域。這個分支的設定和大部分anchor-free的做法是一樣的(例如fcos)。
首先對每個gt,利用FPN中提到的roi重映射規則,將gt映射到不同的特征圖層上
定義中心區域和忽略區域比例,將gt落在中心區域的位置認為是正樣本,忽略區域是忽略樣本(模糊樣本),其余區域是背景負樣本,這種設定規則很常用,沒啥細說的,如圖所示:
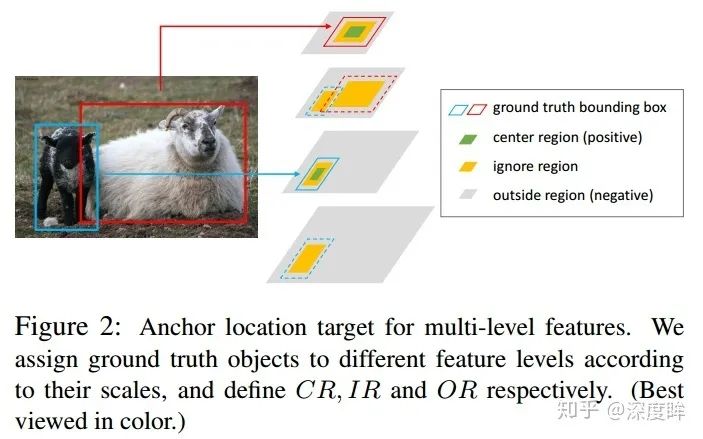
采用focal loss進行訓練
(2) loc_shape
loc_shape分支的目標是給定 anchor 中心點,預測最佳的長和寬,這是一個回歸問題。先不用管作者咋做的,我們可以先思考下可以如何做,首先預測寬高,那肯定是回歸問題,采用l1或者smooth l1就行了,關鍵是label是啥?還有哪些位置計算Loss?我們知道retinanet計算bbox 分支的target算法就是利用MaxIoUAssigner來確定特征圖的哪些位置anchor是正樣本,然后將這些anchor進行bbox回歸。現在要預測anchor的寬高,當然也要確定這個問題。
第一個問題:如何確定特征圖的哪些位置是正樣本區域?,注意作者采用的anchor個數其實是1(作者覺得既然是動態anchor,那么個數其實影響不會很大,設置為1是可以的錯),也就是說問題被簡化了,只要確定每個特征圖的每個位置是否是正樣本即可。要解決這個問題其實非常容易,做法非常多,完全可以按照anchor-free的做法即可,例如FOCS,其實就是loc_preds分支如何確定正負樣本的做法即可,確定中心區域和忽略區域。將中心區域的特征位置作為正樣本,然后直接優化預測輸出的anchor shape和對應gt的iou即可。但是論文沒有這么做,我覺得直接按照fcos的做法來確定正樣本區域,然后回歸shape,是完全可行。本文做法是采用了ApproxMaxIoUAssigner來確定的,ApproxMaxIoUAssigner和MaxIoUAssigner非常相似,僅僅多了一個Approx,其核心思想是:利用原始retinanet的每個位置9個anchor設定,計算9個anchor和gt的iou,然后在9個anchor中采用max操作,選出每個位置9個iou中最高的iou值,然后利用該iou值計算后續的MaxIoUAssigner,此時就可以得到每個特征圖位置上哪些位置是正樣本了。簡單來說,ApproxMaxIoUAssigner和MaxIoUAssigner的區別就僅僅是ApproxMaxIoUAssigner多了一個將9個anchor對應的iou中取最大iou的操作而已。
對于第二個問題:正樣本位置對應的shape target是啥,其實得到了每個位置匹配的gt,那么對應的target肯定就是Gt值了。該分支的loss是bounded iou loss,公式如下:
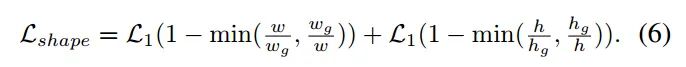
上面寫的非常簡陋,很多細節沒有寫,放在1.5節代碼分析中講解。
3.4 結果
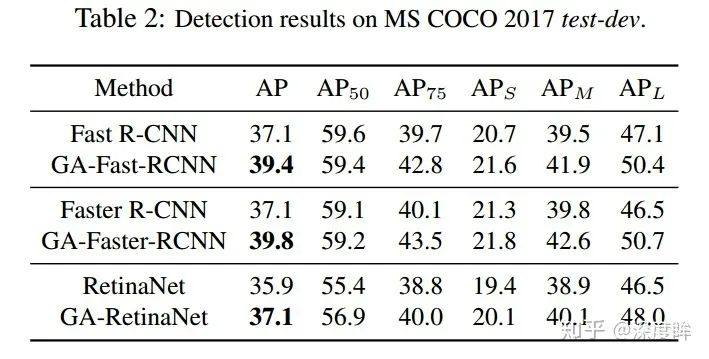

可以看出非常符合預期。
3.5 代碼分析
(1) head
本文代碼分析以retinanet為主,網絡骨架和neck就沒啥說的了,直接截圖:
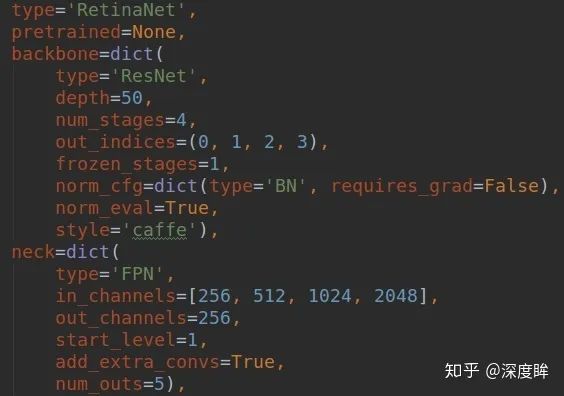
就是ResNet+FPN結構,輸出5個分支進行預測。stride為[8, 16, 32, 64, 128]。對于head部分,可以對比retinanet的head部分進行查看:
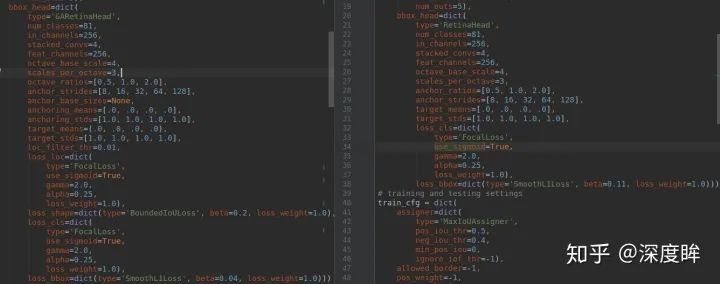
左邊是GARetinaHead,右邊是RetinaHead,可以看出配置除了loss有區別外,都是一樣的。head部分的forward非常簡單,和retinanet相比就是多了兩個shape_pred, loc_pred分支:
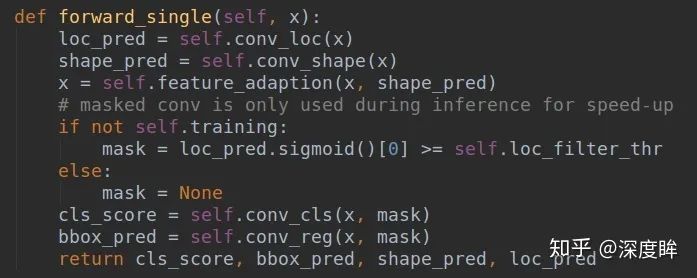
關于feature_adaption的作用作者在論文分享中:Guided Anchoring: 物體檢測器也能自己學 Anchor(https://zhuanlan.zhihu.com/p/55854246)說的很清楚了,我就不寫了。反正forward后就可以4個分支輸出。
(2) loss計算
(2-1) anchor的loc分支loss計算
loc輸出特征圖大小是(batch,1,h,w),本質上是一個二分類器,用于找出語義前景區域。
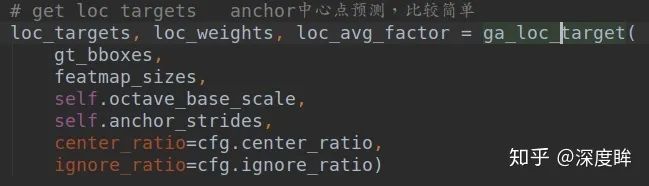
核心參數是中心區域占據比例center_ratio=0.2,忽略區域占比ignore_ratio=0.5.首先需要計算loc分支的target,方便后面計算loss,對應的函數是ga_loc_target,由于代碼比較多,不太好寫,我只能寫個大概流程出來。


有了每個特征圖上,每個位置是正負還是忽略樣本的結果,就可以針對預測的Loc特征圖計算focal loss了:
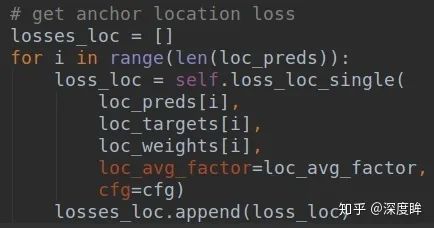
(2-2) anchor的shape分支loss計算
這個分支稍微復雜一點點。首先我們要先熟悉下train_cfg
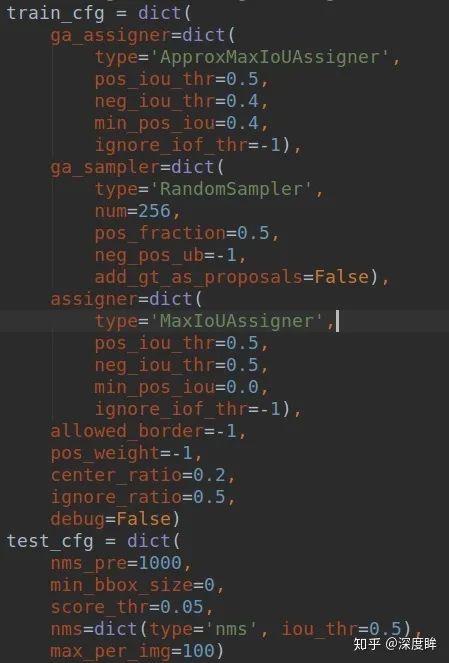
對于GA分支,主要包括ApproxMaxIoUAssigner和RandomSampler,而原始的retinanet分類和回歸分支沒有任何改變,不再贅述。ApproxMaxIoUAssigner是用來近似計算shape特征圖分支上哪些位置負責預測gt bbox,而RandomSampler主要目的不是用來平衡正負樣本的,因為shape分支監督的只有正樣本,沒有啥平衡問題。上述兩個類非常關鍵,理解清楚了才能理解最核心的shape target計算過程。
(1) 計算5個特征圖上,每個位置9個anchor,組成anchor_list

這個函數和其他anchor-base的anchor生成過程完全相同,就是利用特征圖大小、anchor設置得到所有預設anchor的(x0,y0,x1,y1)坐標
(2) 計算每個特征圖的每個位置上shape預測的基數

可能這個不好理解。其實在原文中作者指出shape分支直接預測gt bbox的寬高值不太穩定,因為數值波動范圍比較大,為了穩定,作者回歸的shape預測值實際上是在某個縮放系數下的值,具體是:
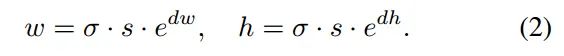
,s是每個特征圖的stride,w就是原始gt bbox寬,dw才是shape分支的預測值。上述的squares_list存儲的就是每層特征圖的每個位置的基數,用于還原shape預測值到真實比例,由于anchor=1,且對于任意層而言是固定的,所以在代碼實現上作者也用了anchor_generate代碼來實現
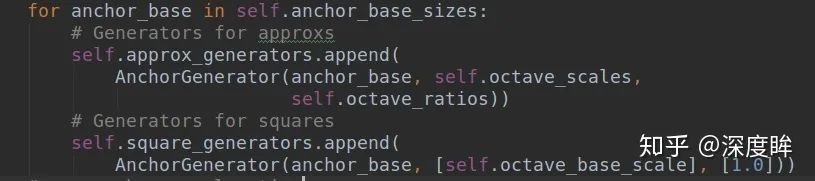
可以明顯發現approx_generators是每個位置9個anchor,而square_generators每個位置是1個anchor,且是正方形。為了方便區分,你可以認為squares_list存儲的就是每一層的還原基數而已,和anchor沒啥關系的,只不過可以等價實現而已。而guided_anchors_list其實就是在squares_list基礎上結合loc預測和shape預測得到的動態anchor,用于訓練原始的retinanet的分類和回歸分支。而如何利用squares_list、loc_pred和shape_pred得到最終的動態anchor,做法非常簡單,如下所示(測試階段也是這個流程):
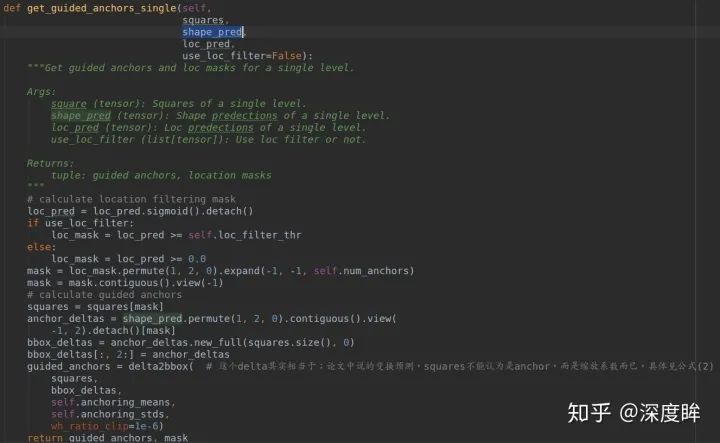
(3) 計算shape target
在得到squares_list、approxs_list和gt_bboxes,下面核心就是計算shape target了。函數是:
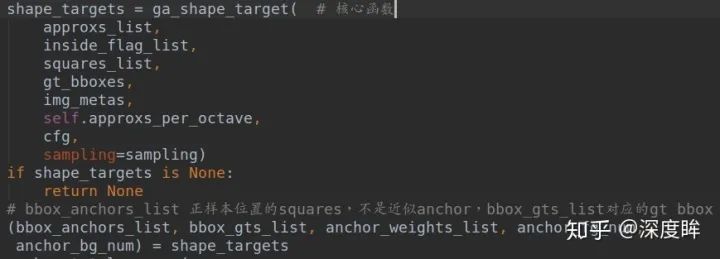
計算shape target的流程包括2步:
1、確定哪些位置是正樣本,通過ApproxMaxIoUAssigner類實現;
2. 每個正樣本位置的label,通過RandomSampler實現。
這兩個操作看起來和faster rcnn的rpn階段的loss計算相同,其實僅僅思想相同而已,但是實現差別還是很大的。
假設你已經了解了MaxIoUAssigner的實現過程,而ApproxMaxIoUAssigner的實現是繼承自MaxIoUAssigner的,其核心差別是:
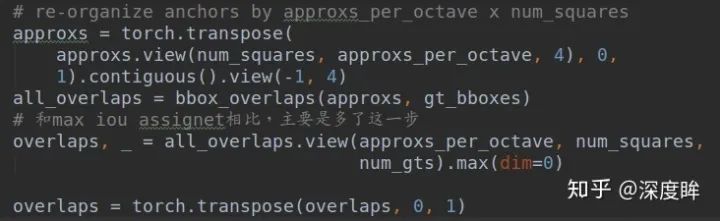
而MaxIoUAssigner僅僅有以下一行而已:
overlaps = bbox_overlaps(gt_bboxes, bboxes)
ApproxMaxIoUAssigner的做法是對于每個位置,先計算9個anchor和gt bbox的iou,然后max選擇最大iou,將anchor=9變成anchor=1(因為預測就是只有1個anchor),然后在這個overlaps基礎上再進行MaxIoUAssigner分配機制,從而確定哪些位置是正樣本,同時會記錄每個位置負責的gt bbox索引,方便后面計算。下一步是RandomSampler函數,但是要非常注意:retinanet的是RandomSampler調用過程:
assign_result = bbox_assigner.assign(anchors, gt_bboxes, gt_bboxes_ignore, gt_labels)
而ga分支的調用過程是:
# 確定了哪些位置是正樣本區域后,需要加入正樣本區域的squares值。注意這里加入的anchor不是近似anchor,而是squares sampling_result = bbox_sampler.sample(assign_result, squares, gt_bboxes)
函數內部實現是一樣的,但是由于傳入的參數不一樣,所有解釋就不一樣了。第一行的輸入是anchor和gt bbox,意思是隨機采樣正負樣本,并且同時將gt bbox作為label,后面直接計算回歸loss,但是注意ga分支的輸入是assign_result和squares,而不是assign_result和gt bbox,也不是assign_result和approxs。也就是說咱們暫時把每個正樣本位置shape預測值的target認為是squares值,后面還會進一步操作。
到這里為止,就已經知道了shape_target返回的各個值含義了。bbox_anchors_list存儲的是所有正樣本位置的squares值,bbox_gts_list是對應的gt bbox值,在得到所有需要的值后終于可以開始計算shape target的loss了。
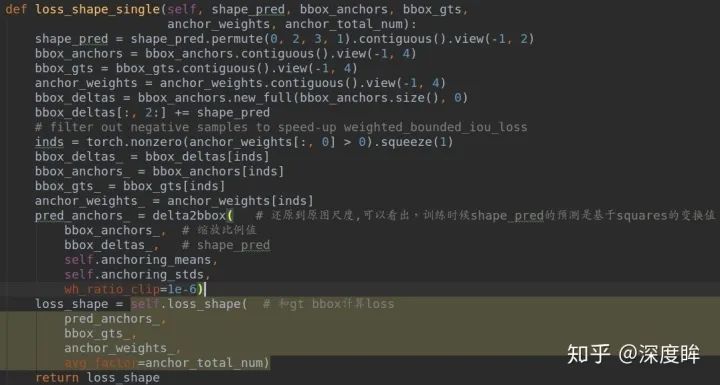
bbox_anchor其實就是bbox_anchors_list,將bbox_anchors_list和shape_pred經過delta2bbox就還原得到真實的bbox預測值了,只不過由于本分支僅僅用于預測shape,故bbox_deltas的前兩個維度一直是0,loss_shape是BoundedIoULoss。
到此,核心代碼就分析完了。稍微難理解的就是shape target的計算過程了。
4 yolo-asff
論文名稱:Learning Spatial Fusion for Single-Shot Object Detection
源碼地址:https://github.com/ruinmessi/ASFF
簡介
先貼性能:
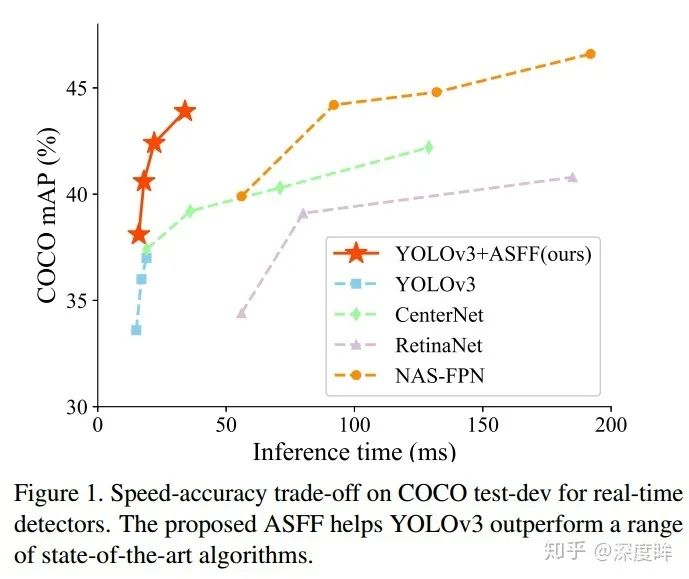
首先可以看出是非常強的。雖然本文題目重點是說ASFF層的牛逼地方,但是我覺得看本文,重點不在這里,而是yolov3的強baseline。

通過一些訓練技巧,將yolov3從33.0mAP,提升到38.8mAP,我覺得這個才是重點需要學習的地方。這其實反映出一個明顯問題:骨架的改進固然重要,但是訓練技巧絕對要引起重視,很多新提出的算法搞了半天提升了1個mAP點,還不如從訓練技巧上面想點辦法來的快(在人臉檢測領域就會針對人臉尺度問題針對性的提出大量訓練技巧,是非常高效的),畢竟訓練技巧只會影響訓練過程,對推理沒有任何額外負擔,何樂不為。
ASFF
本文先分析不那么重要的部分,即本文最大改進ASFF(Adaptively Spatial Feature Fusion)操作,其實熟悉BiFpn的人應該馬上就能get到idea了,我覺得本質上沒有啥區別。FPN操作是一個非常常用的用于對付大小尺寸物體檢測的辦法,作者指出FPN的缺點是不同尺度之間存在語義gap,舉例來說基于iou準則,某個gt bbox只會分配到某一個特定層,而其余層級對應區域會認為是背景(但是其余層學習出來的語義特征其實也是連續相似的,并不是完全不能用的),如果圖像中包含大小對象,則不同級別的特征之間的沖突往往會占據要素金字塔的主要部分,這種不一致會干擾訓練期間的梯度計算,并降低特征金字塔的有效性。
一句話就是:目前這種concat或者add的融合方式不夠科學。本文覺得應該自適應融合,自動找出最合適的融合特征,如下所示:
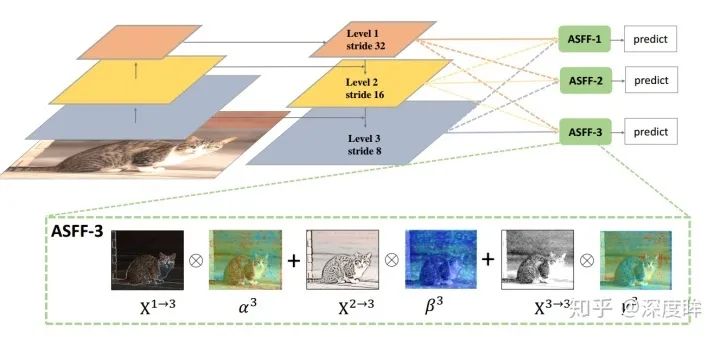
簡要思想就是:原來的FPN add方式現在變成了add基礎上多了一個可學習系數,該參數是自動學習的,可以實現自適應融合效果,類似于全連接參數。ASFF具體操作包括 identically rescaling和adaptively fusing。定義FPN層級為l,為了進行融合,對于不同層級的特征都要進行上采樣或者下采樣操作,用于得到同等空間大小的特征圖,上采樣操作是1x1卷積進行通道壓縮,然后雙線性插值得到;下采樣操作是對于1/2特征圖是采樣3 × 3 convolution layer with a stride of 2,對于1/4特征圖是add a 2-stride max pooling layer然后引用stride 卷積。Adaptive Fusion

下面講解具體操作:
(1) 首先對于第l級特征圖輸出cxhxw,對其余特征圖進行上下采樣操作,得到同樣大小和channel的特征圖,方便后續融合
(2) 對處理后的3個層級特征圖輸出,輸入到1x1xn的卷積中(n是預先設定的),得到3個空間權重向量,每個大小是nxhxw
(3) 然后通道方向拼接得到3nxhxw的權重融合圖
(4) 為了得到通道為3的權重圖,對上述特征圖采用1x1x3的卷積,得到3xhxw的權重向量
(5) 在通道方向softmax操作,進行歸一化,將3個向量乘加到3個特征圖上面,得到融合后的cxhxw特征圖
(6) 采用3x3卷積得到輸出通道為256的預測輸出層
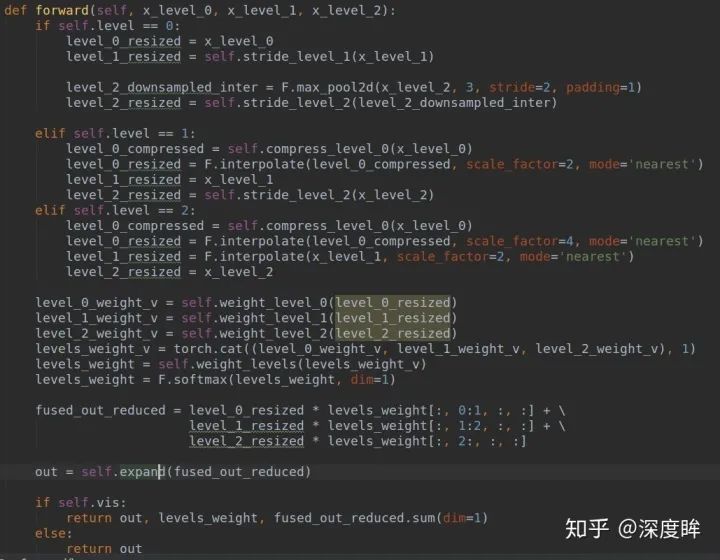
ASFF層學習得到的各種特征可視化效果如下:

強baseline
YOLOv3包括darknet53骨架網絡和3層特征金字塔網絡構成的3個尺度輸出。
首先采用基于Bag of freebies for training object detection neural networks里面提出的訓練策略來改進性能,主要包括the mixup algorithm , the cosinelearning rate schedule和 the synchronized batch normalization。其次,由于最新論文表示iou loss對于邊界框回歸效果好,故作者也額外引入了一個iou loss來優化bbox。最后,由于GA論文(Region proposal by guided anchoring)指出采用語義向導式的anchor策略可以得到更好的結果,故作者也引入了GA操作來提升性能。可以看出,結合這些策略后,在coco上面可以得到38.8的mAP,速度僅僅慢了一點點(多了GA操作),可謂是非常強大,這也反應出訓練策略對最終性能的影響非常大。
the mixup algorithm , the cosinelearning rate schedule和 the synchronized batch normalization這三個策略非常常見,沒啥好說的。額外引入一個iou loss也是常規操作。我們重點分析GA的實現。為啥要重點分析GA操作呢?因為作者實現的GA和原始論文的GA有點不同,很值得分析。
loss代碼分析
對應的代碼是YOLOv3Head.py
首先和GA一樣,也是有FeatureAdaption,用于對動態anchor特征進行自適應。
(1) 初始化函數
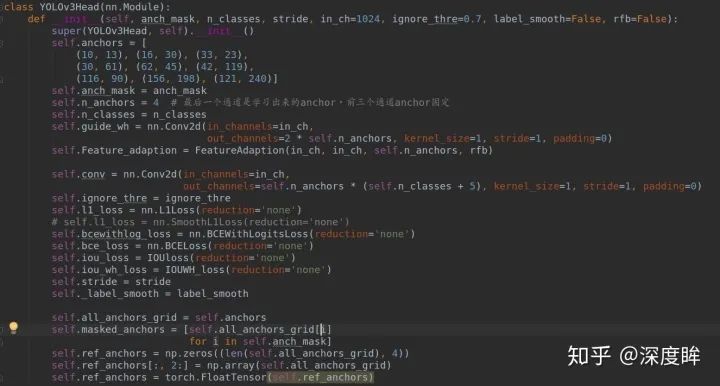
anchors里面存儲的就是原始yolov3的9組anchor,但是特別需要注意的是這里實現的anchor個數是4個,而不是GA原文的1個anchor,這個小差別會導致后面代碼有些差別。按照GA論文做法,其實1個anchor就足夠了。而且需要注意這里的GA分支沒有輸出Loc,僅僅有shape預測。原因是loc分支的目的僅僅是用于進行前后景提取,是個二分類問題,但是由于yolo有confidence分支,其有前后景提取功能,故不再需要loc分支。loss函數方面,就是多了shape預測的IOUWH_loss函數,以及bbox回歸額外引入的IOUloss,其余相同。
(2) forward函數
(2-1) 輸出預測值
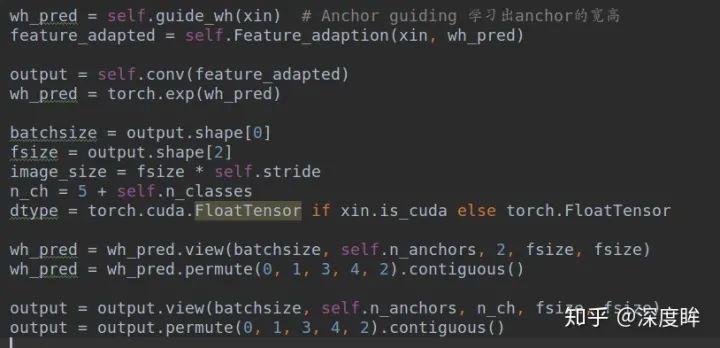
對ASFF層輸出的每一層特征圖xin,進行GA分支推理,并且經過Feature_adaption,得到最終的bbox預測輸出output,由于wh預測肯定是大于0的,故作者采用了exp函數強制大于0.此時就得到了**wh_pred(batch,4,2,h,w)和output(batch,4,5+class,h,w)**。
(2-2) 將預測anchor變換到原圖尺度,得到guide anchor
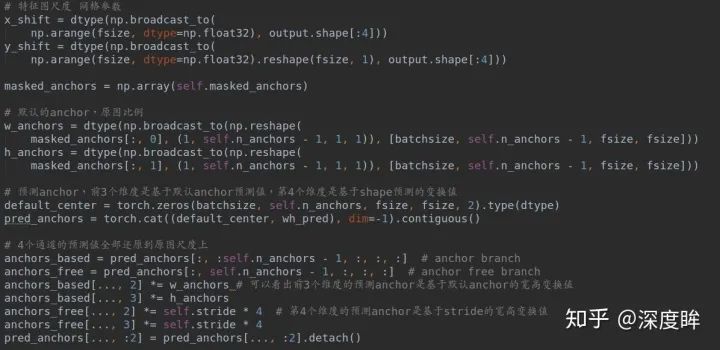
(2-3) 前向模式下基于預測anchor直接進行回歸即可得到最終bbox
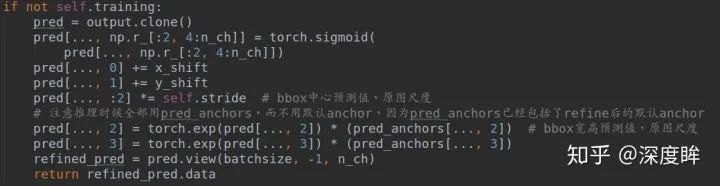
(2-4) 訓練模式下準備target先準備數據:
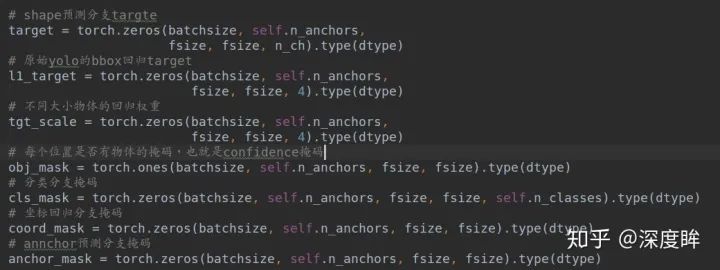
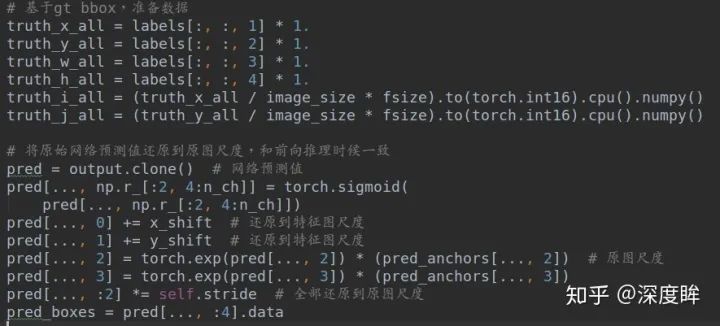
計算匹配anchor和confidence mask
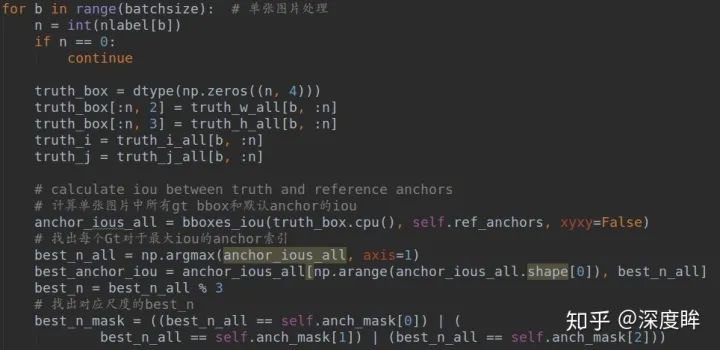
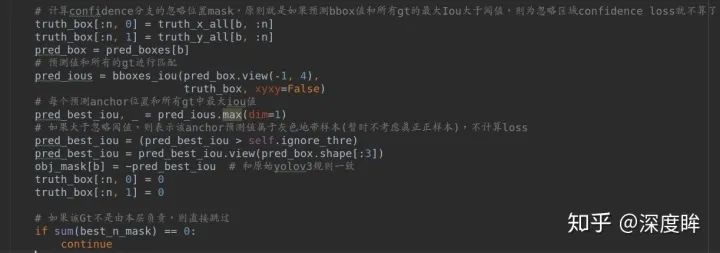
理解下面的操作才是理解了本文核心:
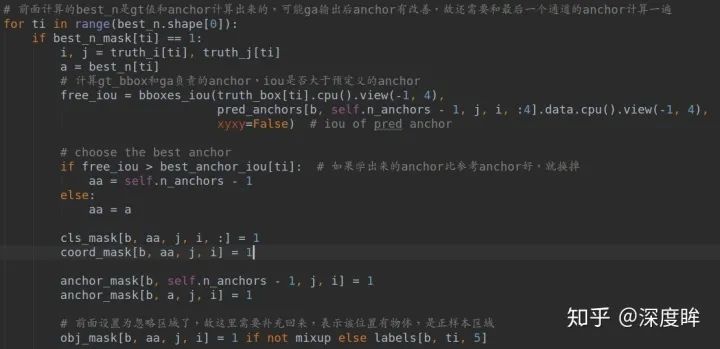
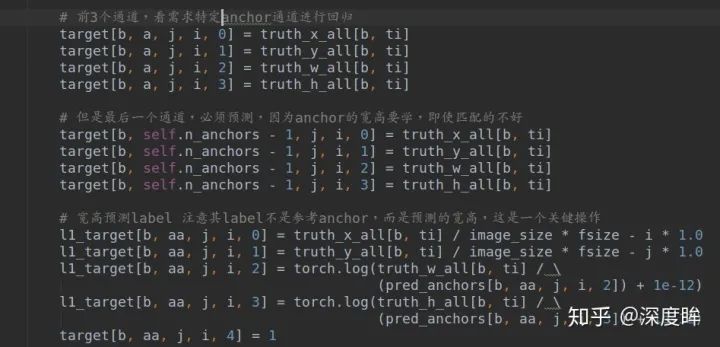
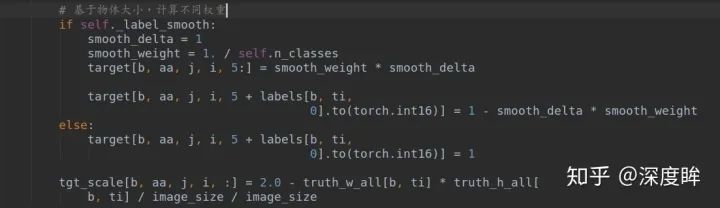
前面所有準備都好了后,就是計算loss了:
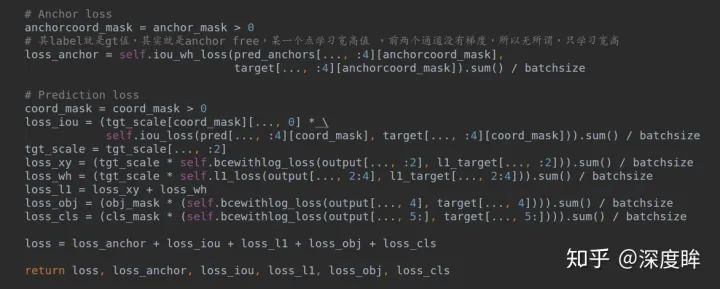
可以看出前兩個loss是額外加入的。
GA的引入可以實現:
(1) 在anchor設置不合理時候,動態引導anchor預測分支得到更好的anchor
(2) 在anchor設置合理時候,可以加速收斂,且可以進一步refine 默認anchor
我覺得本文的GA實現過程非常好,思路清晰,很好理解,可以實現anchor-base混合anchor-free,發揮各自的優勢。后續會進行各種對比實驗,驗證GA在yolo中的引導作用。
審核編輯 :李倩
-
代碼
+關注
關注
30文章
4779瀏覽量
68522 -
目標檢測
+關注
關注
0文章
209瀏覽量
15605
原文標題:目標檢測正負樣本區分策略和平衡策略總結
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
電動汽車充電對配電網影響及有序控制策略研究
什么是回歸測試_回歸測試的測試策略
貼片電容正負極怎么區分
rca輸出和平衡輸出有什么區別
振蕩器的起振條件和平衡條件
貼片電容的正負極區分的方法

電解電容的正負極怎么區分
萬用表正負極如何區分
如何區分示波器探頭的正負極
巍泰技術存在感知雷達WTR-860消減綠植、窗簾雜波干擾的策略分析


AI驅動的雷達目標檢測:前沿技術與實現策略

法拉電容正負極怎么區分 電容器正負極判斷方法
逆變電路的控制策略與方法介紹





 工商網監
工商網監
評論