 動態追蹤技術分類及其使用方法
動態追蹤技術分類及其使用方法
文章介紹幾種常用的內核動態追蹤技術,對 ftrace、perf 及 eBPF 的使用方法進行案例說明。
1.什么是動態追蹤
動態追蹤技術,是通過探針機制來采集內核或者應用程序的運行信息,從而可以不用修改內核或應用程序的代碼,就獲得調試信息,對問題進行分析、定位。
通常在排查和調試異常問題時,我們首先想到的是使用 GDB 在程序運行路徑上設置斷點,然后結合命令進行分析定位; 或者,在程序源碼中增加一系列的日志,從日志輸出中尋找線索。 不過,斷點往往會中斷程序的正常運行; 而增加新的日志,往往需要重新編譯和部署。 在面對偶現問題以及對時延要求嚴格的場景下,GDB 和增加日志的方式就不能滿足需求了。
動態追蹤為這些問題提供了完美的方案:它既不需要停止服務,也不需要修改程序的代碼; 程序還按照原來的方式正常運行時,就可以分析出問題的根源。 同時,相比以往的進程級跟蹤方法(比如 ptrace),動態追蹤往往只會帶來很小的性能損耗。
2.動態追蹤技術分類
動態追蹤的工具很多,systemtap、perf、ftrace、sysdig、eBPF 等。 動態追蹤的事件源根據事件類型不同,主要分為三類:靜態探針, 動態探針以及硬件事件。
- 硬件事件:通常由性能監控計數器 PMC(Performance Monitoring Counter)產生,包括了各類硬件的性能情況,比如 CPU 的緩存、指令周期、分支預測等。
- 靜態探針:事先在代碼中定義好,并編譯到應用程序或者內核中的探針。 這些探針只有在開啟探測功能時,才會被執行到; 未開啟時并不會執行。 常見的靜態探針包括內核中的跟蹤點(tracepoints)和 USDT(Userland Statically Defined Tracing)探針。
- 動態探針:沒有事先在代碼中定義,但卻可以在運行時動態添加的探針,比如函數的調用和返回等。 動態探針支持按需在內核或者應用程序中添加探測點,具有更高的靈活性。 常見的動態探針有兩種,即用于內核態的 kprobes 和用于用戶態的 uprobes。 需要注意的是 kprobes 需要內核編譯時開啟 CONFIG_KPROBE_EVENTS,uprobes 則需要內核編譯時開啟 CONFIG_UPROBE_EVENTS。
3動態追蹤之ftrace
ftrace 最早用于函數跟蹤,后來擴展支持了各種事件跟蹤功能。 ftrace 通過 debugfs 以普通文件的形式,向用戶空間提供訪問接口,這樣不需要額外的工具,就可以通過掛載點(通常為 /sys/kernel/debug/tracing 目錄)的文件讀寫,來跟 ftrace 交互,跟蹤內核或者應用程序的運行事件。
在使用 ftrace 之前,首先要確定當前系統是否已經掛載了 debugfs,可以使用如下方式進行確認。
#方式一:查看掛載信息
mount | grep debugfs
#方式二:查看掛載點
ls /sys/kernel/debug/tracing
如果在上面的查找結果中有輸出,說明當前系統已經掛載了 debugfs,如果系統未掛載 debugfs,則使用如下的命令進行掛載。
mount -t debugfs nodev /sys/kernel/debug
在 /sys/kernel/debug/tracing 目錄下提供了各種跟蹤器(tracer)和事件(event),一些常用的選項如下。
- available_tracers:當前系統支持的跟蹤器;
- available_events:當前系統支持的事件;
- current_tracer:當前正在使用的跟蹤器; 默認為 nop,表示不做任何跟蹤操作,使用 echo 命令把跟蹤器的名字寫入該文件,即可切換到不同的跟蹤器;
- trace:當前的跟蹤信息;
- tracing_on:用于開始或暫停跟蹤;
- trace_options:設置 ftrace 的一些相關選項;
ftrace 提供了多個跟蹤器,用于跟蹤不同類型的信息,比如函數調用、中斷關閉、進程調度等。 具體支持的跟蹤器取決于系統配置,使用如下的命令來查詢當前系統支持的跟蹤器。
root@ubuntu:/sys/kernel/debug/tracing# cat available_tracers
hwlat blk mmiotrace function_graph wakeup_dl wakeup_rt wakeup function nop
以上是系統支持的所有跟蹤器,function 表示跟蹤函數的執行,function_graph 則是跟蹤函數的調用關系,也就是生成直觀的調用關系圖,這是最常用的兩種跟蹤器。 也可以通過配置內核,使系統支持更多類型的跟蹤器。
在使用跟蹤器前,需要確定好跟蹤目標,包括內核函數和事件,函數是指內核中的函數名,事件是指內核中預先定義的跟蹤點。 可以使用如下方式查看內核支持跟蹤的函數和事件。
#查看內核支持追蹤的函數
cat available_filter_functions
#查看內核支持追蹤的事件
cat available_events
接下來以一個簡單的示例說明 ftrace 的基本用法,比如我們需要跟蹤 open 的系統調用,open 在內核中的實現接口為 do_sys_open,所以需要將跟蹤的函數設置為 do_sys_open,以下是跟蹤過程的步驟。
#設置函數跟蹤點為 do_sys_open
echo do_sys_open > set_graph_function
#設置當前跟蹤器為 function_graph
echo function_graph > current_tracer
#配置 trace 屬性:顯示當前的進程
echo funcgraph-proc > trace_options
#清除 trace 緩存
echo > trace
#開啟跟蹤
echo 1 > tracing_on
#產生 do_sys_open 調用
ls
#關閉跟蹤
echo 0 > tracing_on
在關閉跟蹤后,使用 cat 命令查看跟蹤結果,如下所示,在 trace 文件中保存了跟蹤到的信息,第一列表示接口執行的 CPU,第二列表示任務名稱和進程 PID,第三列是函數執行延遲,最后一列是函數調用關系圖。
root@ubuntu:/sys/kernel/debug/tracing# cat trace
# tracer: function_graph
#
# CPU TASK/PID DURATION FUNCTION CALLS
# | | | | | | | | |
2) ls-46073 | | do_sys_open() {
2) ls-46073 | | getname() {
2) ls-46073 | | getname_flags() {
2) ls-46073 | | kmem_cache_alloc() {
2) ls-46073 | | _cond_resched() {
2) ls-46073 | 0.119 us | rcu_all_qs();
2) ls-46073 | 0.416 us | }
2) ls-46073 | 0.095 us | should_failslab();
2) ls-46073 | 0.112 us | memcg_kmem_put_cache();
2) ls-46073 | 1.041 us | }
2) ls-46073 | | __check_object_size() {
2) ls-46073 | 0.097 us | check_stack_object();
2) ls-46073 | 0.100 us | __virt_addr_valid();
2) ls-46073 | 0.097 us | __check_heap_object();
2) ls-46073 | 0.662 us | }
2) ls-46073 | 2.109 us | }
2) ls-46073 | 2.414 us | }
ftrace 的輸出通過不同級別的縮進,直觀展示了各函數間的調用關系。 但是 ftrace 的使用需要好幾個步驟,用起來并不方便,不過,trace-cmd 已經把這些步驟給包裝了起來,這樣,就可以通過一行命令,完成上述所有過程。 trace-cmd 的安裝方式如下。
# Ubuntu
apt install trace-cmd
# CentOS
yum install trace-cmd
trace-cmd安裝好之后,可以通過執行如下的命令輸出類似的結果,值得注意的是 trace-cmd 的執行不能在 /sys/kernel/debug/tracing 路徑,否則執行出出錯,提示信息為“trace-cmd: Permission denied”。
trace-cmd record -p function_graph -g do_sys_open -O funcgraph-proc ls
trace-cmd report
ftrace 的追蹤功能不止于此,它不僅能追蹤到接口的調用關系,還能抓取接口調用的時間戳,用于性能分析; 還可根據需要追蹤的接口進行模糊過濾,眾多的功能不在這里詳細介紹,如果項目中需要用到再進行具體了解和總結。
4.動態追蹤之perf
perf 的功能強大,可以統計分析出應用程序或者內核中的熱點函數,從而用于程序性能分析; 也可以用來分析 CPU cache、CPU 遷移、分支預測、指令周期等各種硬件事件; 還可以對感興趣的事件進行動態追蹤。 下面以 do_sys_open 為例,設置目標函數追蹤。 執行如下命令,可以查詢所有支持的事件。
perf list
在 perf 的各個子命令中添加 --event 選項,設置追蹤感興趣的事件。 如果這些預定義的事件不滿足實際需要,可以使用 perf probe 來動態添加。 而且,除了追蹤內核事件外,perf 還可以用來跟蹤用戶空間的函數。 執行如下代碼添加 do_sys_open 探針。
#執行指令
perf probe --add do_sys_open
#輸出
Added new event:
probe:do_sys_open (on do_sys_open)
You can now use it in all perf tools, such as:
perf record -e probe:do_sys_open -aR sleep 1
探針添加成功后,就可以在所有的 perf 子命令中使用。 比如,上述輸出就是一個 perf record 的示例,執行它就可以對 1s 內的 do_sys_open 進行采樣,如下所示。
#執行命令
perf record -e probe:do_sys_open -aR sleep 1
#輸出
[ perf record: Woken up 1 times to write data ][ perf record: Captured and wrote 0.810 MB perf.data (18 samples) ]
執行如下命令顯示采樣結果,輸出結果中列出了調用 do_sys_open 的任務名稱、進程 PID 以及運行的 CPU 等信息。
#執行命令
perf script
#輸出
perf 3676 [003] 7619.618568: probe:do_sys_open: (ffffffffa92e78e0)
sleep 3677 [000] 7619.621118: probe:do_sys_open: (ffffffffa92e78e0)
sleep 3677 [000] 7619.621130: probe:do_sys_open: (ffffffffa92e78e0)
vminfo 1403 [001] 7619.864117: probe:do_sys_open: (ffffffffa92e78e0)
dbus-daemon 749 [001] 7619.864222: probe:do_sys_open: (ffffffffa92e78e0)
dbus-daemon 749 [001] 7619.864310: probe:do_sys_open: (ffffffffa92e78e0)
irqbalance 743 [000] 7620.013548: probe:do_sys_open: (ffffffffa92e78e0)
irqbalance 743 [000] 7620.013687: probe:do_sys_open: (ffffffffa92e78e0)
在使用結束后,使用如下命令刪除探針。
#刪除 do_sys_open 探針
perf probe --del probe:do_sys_open
5.動態追蹤之eBPF
eBPF 相對于 ftrace 和 perf 更加靈活,它可以通過 C 語言自由擴展,這些擴展通過 LLVM (Low Level Virtual Machine) 轉換為 BPF 字節碼后,加載到內核中執行。
5.1 搭建 eBPF 開發環境
雖然 Linux 內核很早就已經支持了 eBPF,但很多新特性都是在 4.x 版本中逐步增加的。 所以,想要穩定運行 eBPF 程序,內核至少需要 4.9 或者更新的版本。 而在開發和學習 eBPF 時,為了體驗和掌握最新的 eBPF 特性,推薦使用更新的 5.x 內核,接下來的案例是基于 Ubuntu20.04 系統,內核版本為 5.15.0-56-generic,eBPF 開發和運行需要相關的開發工具如下。
- 將 eBPF 程序編譯成字節碼的 LLVM;
- C 語言程序編譯工具 make;
- 流行的 eBPF 工具集 BCC 和它依賴的內核頭文件;
- 內核代碼倉庫實時同步的 libbpf;
- 內核提供的 eBPF 程序管理工具 bpftool。
可運行如下命令進行相關工具的安裝。
apt install -y make clang llvm libelf-dev libbpf-dev bpfcc-tools libbpfcc-dev linux-tools-$(uname -r) linux-headers-$(uname -r)
5.2 開發 eBPF 程序的步驟
一般來說, eBPF 程序的開發分為如下 5 個步驟。
- 第一步,使用 C 語言開發一個 eBPF 程序;
- 第二步,借助 LLVM 把 eBPF 程序編譯成 BPF 字節碼;
- 第三步,通過 bpf 系統調用,把 BPF 字節碼提交給內核;
- 第四步,內核驗證并運行 BPF 字節碼,并把相應的狀態保存到 BPF 映射中;
- 第五步,用戶程序通過 BPF 映射查詢 BPF 字節碼的運行狀態。
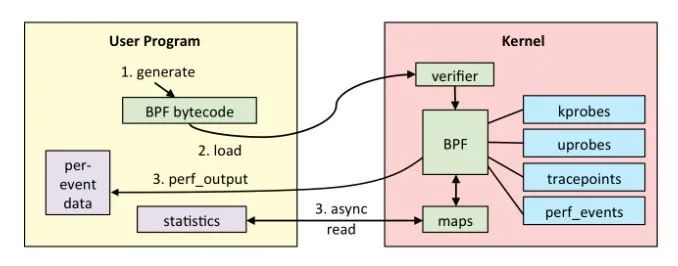
eBPF 程序執行過程
以上的每一步,都可以自己動手去完成。 但為了方便,推薦從 BCC(BPF Compiler Collection)開始學起。 BCC 是一個 BPF 編譯器集合,包含了用于構建 BPF 程序的編程框架和庫,并提供了大量可以直接使用的工具。 使用 BCC 的好處是,它把上述的 eBPF 執行過程通過內置框架抽象了起來,并提供了 Python、C++ 等編程語言接口。 這樣,就可以直接通過 Python 語言去跟 eBPF 的各種事件和數據進行交互。
5.3 借助 BCC 開發 eBPF 程序案例
接下來,就以跟蹤 openat()(即打開文件)這個系統調用為例,說明如何開發并運行第一個 eBPF 程序。 使用 BCC 開發 eBPF 程序,可以把上面的五步簡化為下面的三步。
5.3.1 使用 C 開發一個 eBPF 程序
新建一個 trace_open.c 文件,輸入如下內容。
/* 包含頭文件 */
#include BPF 程序可以利用 BPF 映射(map)進行數據存儲,而用戶程序也需要通過 BPF 映射,同運行在內核中的 BPF 程序進行交互。 用戶層為了獲取內核打開文件名稱時,就要引入 BPF 映射。 為了簡化 BPF 映射的交互,BCC 定義了一系列的庫函數和輔助宏定義。
如下是對上述代碼的說明。
- data_t 是用戶自定義的數據結構,用于保存進程 PID、時間、執行命令及文件名稱;
- 使用 BPF_PERF_OUTPUT 來定義一個 Perf 事件類型的 BPF 映射;
- bpf_get_current_pid_tgid 用于獲取進程的 TGID 和 PID。 定義的 data.pid 數據類型為 u32,所以高 32 位舍棄掉后就是進程的 PID;
- bpf_ktime_get_ns 用于獲取系統自啟動以來的時間,單位是納秒;
- bpf_get_current_comm 用于獲取進程名,并把進程名復制到預定義的緩沖區中;
- bpf_probe_read 用于從指定指針處讀取固定大小的數據,這里則用于讀取進程打開的文件名。
- perf_submit() 接口將填充好的 data 數據提交到定義的 BPF 映射中;
5.3.2 使用 Python 開發用戶態程序
創建一個 trace_open.py 文件,并輸入下面的內容。
#!/usr/bin/env python3
# 1) import bcc library
from bcc import BPF
# 2) load BPF program
b = BPF(src_file="trace_open.c")
# 3) attach kprobe
b.attach_kprobe(event="do_sys_openat2", fn_name="trace_open")
# 4) print header
print("%-18s %-16s %-6s %-16s" % ("TIME(s)", "COMM", "PID", "FILE"))
# 5) define the callback for perf event
start = 0
def print_event(cpu, data, size):
global start
event = b["events"].event(data)
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %-16s" % (time_s, event.comm, event.pid, event.fname))
# 6) loop with callback to print_event
b["events"].open_perf_buffer(print_event)
while 1:
try:
b.perf_buffer_poll()
except KeyboardInterrupt:
exit()
如下是對上述代碼的說明。
- 第 1) 處導入了 BCC 庫的 BPF 模塊,以便接下來調用;
- 第 2) 處調用 BPF() 加載第一步開發的 BPF 源代碼;
- 第 3) 處將 BPF 程序掛載到內核探針(簡稱 kprobe),其中 do_sys_openat2() 是系統調用 openat() 在內核中的實現;
- 第 4) 處輸出顯示標題;
- 第 5) 處的 print_event 定義一個數據處理的回調函數,打印進程的名字、PID 以及它調用 openat 時打開的文件;
- 第 6) 處的 open_perf_buffer 定義了名為 "events" 的 Perf 事件映射,而后通過一個循環調用 perf_buffer_poll 讀取映射的內容,并執行回調函數輸出進程信息。
5.3.3 執行 eBPF 程序
用戶態程序開發完成之后,最后一步就是執行它了。 需要注意的是,eBPF 程序需要以 root 用戶來運行,非 root 用戶需要加上 sudo 來執行,輸入如下命令執行程序。
python3 trace_open.py
命令執行后,可以在另一個終端中輸入 cat 或 ls 命令(執行文件打開命令),然后回到運行 trace_open.py 腳本的終端,結果如下。
TIME(s) COMM PID FILE
0.000000000 b'ls' 5171 b'/etc/ld.so.cache'
0.000021937 b'ls' 5171 b'/lib/x86_64-linux-gnu/libselinux.so.1'
......
2.088971702 b'gsd-housekeepin' 1803 b'/etc/fstab'
2.089056747 b'gsd-housekeepin' 1803 b'/proc/self/mountinfo'
......
2.741662512 b'cat' 5172 b'/etc/ld.so.cache'
2.741681539 b'cat' 5172 b'/lib/x86_64-linux-gnu/libc.so.6'
......
5.4 eBPF 開發方式簡介
除了 BCC 之外,eBPF 還有可以使用其他的方式進行輔助開發,比如 bpftrace 和 libbpf,每種方法都有自己的優點和適用范圍,以下是這三種方式的對比。
- bpftrace 通常用在快速排查和定位系統上,它支持用單行腳本的方式來快速開發并執行一個 eBPF 程序。 不過,bpftrace 的功能有限,不支持特別復雜的 eBPF 程序,也依賴于 BCC 和 LLVM 動態編譯執行。
- BCC 通常用在開發復雜的 eBPF 程序中,其內置的各種小工具也是目前應用最為廣泛的 eBPF 小程序。 不過,BCC 也不是完美的,它依賴于 LLVM 和內核頭文件才可以動態編譯和加載 eBPF 程序。
- libbpf 是從內核中抽離出來的標準庫,用它開發的 eBPF 程序可以直接分發執行,這樣就不需要每臺機器都安裝 LLVM 和內核頭文件了。 不過,它要求內核開啟 BTF 特性,需要非常新的發行版才會默認開啟(如 RHEL 8.2+ 和 Ubuntu 20.10+ 等)。
在實際應用中,可以根據內核版本、內核配置、eBPF 程序復雜度,以及是否允許安裝內核頭文件和 LLVM 編譯工具等,來選擇最合適的方案。
-
內核
+關注
關注
3文章
1372瀏覽量
40278 -
Linux
+關注
關注
87文章
11292瀏覽量
209328 -
命令
+關注
關注
5文章
683瀏覽量
22011 -
追蹤技術
+關注
關注
0文章
19瀏覽量
4299
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論