 為什么Chimera GPNPU如此充滿想象力和令人眼花繚亂呢
為什么Chimera GPNPU如此充滿想象力和令人眼花繚亂呢
希臘神話中,Chimera是一種巨大的噴火混血動物,由不同的動物部位組成;現在它被用來描述任何想象力豐富、難以置信或令人眼花繚亂的東西。
筆者最近從Quadric那里接觸到Chimera GPNPU(通用神經處理器),真是“產品”如其名。
Quadric公司成立于2017年,最初計劃基于其新創Chimera GPNPU架構提供推理邊緣芯片 (針對物聯網“邊緣”推理應用的芯片)。
他們的第一塊芯片被快速驗證,一些早期用戶已經在進行試驗。但最近,Quadric公司決定將Chimera GPNPU授權為IP,向更廣泛的客戶群體展示他們的技術。
下圖是利用Chimera GPNPU實現面部識別和認證的簡化示意圖,我們就以此作為切入點看下為什么Chimera GPNPU如此“充滿想象力”和“令人眼花繚亂”。
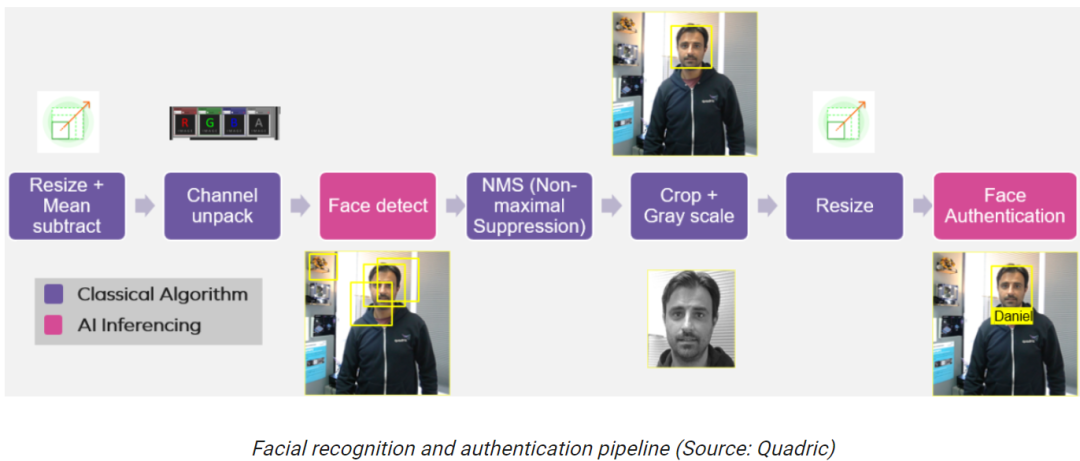
假設所有這些功能都在智能相機SoC中實現,一個攝像機/傳感器為左邊的第一個功能塊提供視頻流。這個應用很可能會用于未來幾代的門鈴攝像頭中。
觀察兩個粉紅色的“Face Detect”和“Face Authentication”功能塊,它們是通過人工智能/機器學習(AI/ML)推理實現的。
在過去幾年中,這種類型的推理發展極為迅速,從學術研究到早期部署,現在幾乎成為軟件開發中的一個必不可少的元素。
將推理(基于視覺、聲音等形式)作為創建應用程序的構建塊之一,這種想法我們可以認為是“軟件2.0”。
但這實現起來并不容易,SoC傳統應對軟件2.0挑戰的方式如下(a)所示。
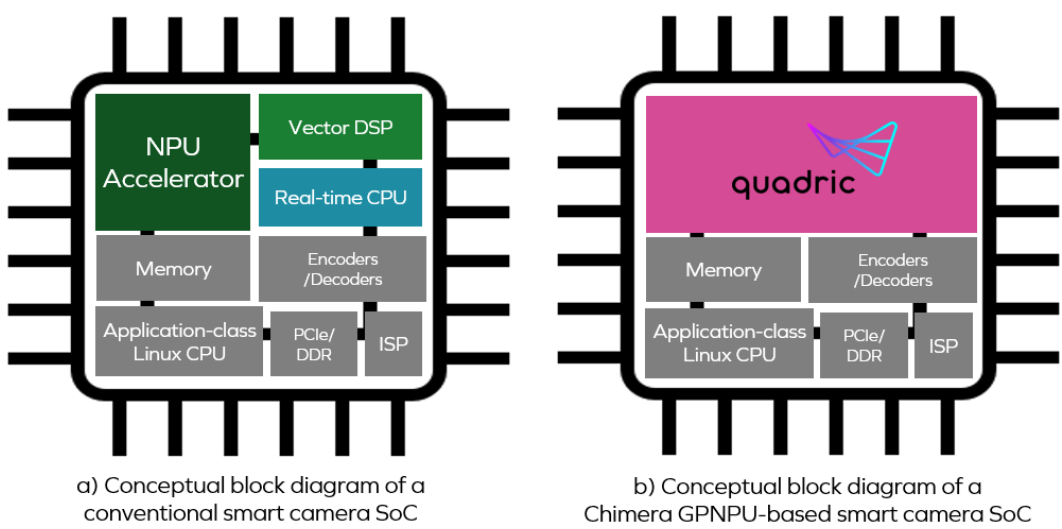
從(a)圖中可以看到,神經處理器單元(NPU)、矢量數字信號處理器(DSP)和實時中央處理器(CPU)為三個獨立的核心。
要實現前面的面部識別和認證流程,使用常規方法,前兩個功能塊(Resize和Channel unpack)相關的處理將在DSP核心上執行。
然后,DSP生成的數據將被送到NPU核心上運行神經網絡“Face Detect”模型;NPU的輸出再送給CPU核心,CPU將運行一個“NMS”算法來決定使用哪個算法效果最好。
然后,DSP將使用CPU識別的邊界框在圖像上執行更多的任務,如“Crop + Gray Scale”和“Resize”。最后,這些數據將送到NPU核心上運行“Face Authenticate”模型。
用上述方法實現后,我們可能會發現沒有達到想要的吞吐率。如何找出性能瓶頸在哪里?另外,三個核心之間交換數據產生了多少功耗?
真正的潛在問題是,擁有三個獨立的處理器核心會使整個設計過程變得繁瑣。
例如,硬件設計人員必須決定要為每個核心分配多少內存,以及在功能塊之間需要多大的緩沖區。同時,軟件開發人員需要決定如何在內核之間劃分算法。這很痛苦,因為程序員不愿意花大量時間考慮所運行目標平臺的硬件細節。
另一個問題是ML模型正在迅速發展,誰都不知道未來幾年會有怎樣的ML模型。
所有這些問題都會導致ML部署無法盡可能快地加速,因為針對這種類型的常規目標平臺進行開發,對于編程、調試和性能調優等方面來說,都是一件非常痛苦的事情。
再回到Chimera GPNPU,它由前面圖(b)部分的粉色區域表示。
GPNPU將DSP、CPU和NPU的屬性結合在單個核心中,作為一個傳統的CPU/DSP的組合,它可以運行C/ C++代碼,具有完整的32位標量+向量指令集架構(ISA),同時可以用作一個NN圖處理器,運行8位推理優化的ML代碼。這種方法通過在同一個引擎上運行兩種類型的代碼,獨特地解決了信號傳輸的挑戰。
我們可以認為Chimera GPNPU是經典的馮·諾依曼RISC機和收縮陣列/2D矩陣架構的混合體。
Chimera GPNPU的一個關鍵優勢是它能夠適應不斷發展和日益復雜的ML網絡。現在東西變得越來越復雜,需要在NN的體系結構中做更多的條件控制流,可以是CNN, RNN, DNN等等。
傳統的NPU通常是硬連接的加速器,不能條件執行。例如有一個專用加速器,用戶不能在第14層的某個地方停下來檢查條件或中間結果,然后分支判斷并做各種面向控制流的事情。
在這些情況下,必須在NPU和CPU之間來回移動數據,這將對性能和功耗產生沖擊。而使用一個Chimera GPNPU,我們可以在NN和控制代碼之間在時鐘基礎上來回切換。
這里還有很多需要討論,比如Chimera GPNPU在執行卷積層(這是CNN的核心)方面的出色表現,以及它們的TOPS(每秒萬億次操作)評分,都令筆者非常興奮。這里不再詳細闡述,有需要的讀者可以咨詢Quadric公司。
最后,筆者想快速概述一下Quadric軟件開發工具包(SDK),如下所示。
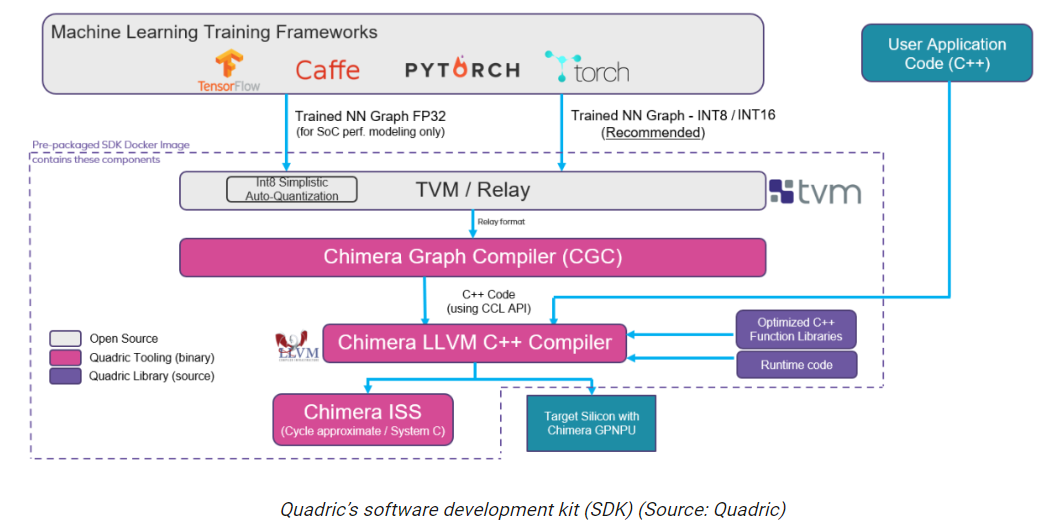
歸根結底,一切都是由軟件驅動的。使用TensorFlow、PyTorch、Caffe等框架生成的經過訓練的神經網絡圖/模型被送入Apache TVM(一個用于CPU、GPU和ML加速器的開源機器學習編譯器框架),生成一個Relay輸出(Relay是TVM框架的高級中間表示)。
中繼表示的轉換和優化由Chimera CGC執行,它將轉換和優化后的神經網絡輸出為C++代碼。Chimera LLVM C++ Compiler將這些代碼與開發人員的C++應用程序代碼合并,所有這些輸出為一個可執行文件,運行在目標硅/SoC中的Chimera GPNPU上。
注意,Quadric SDK是作為預打包的Docker映像交付的,用戶可以下載并在自己的系統上運行。Quadric很快將把這個SDK托管在Amazon Web Services (AWS)上,從而允許用戶通過他們的Web瀏覽器訪問它。
讓筆者特別感興趣的是,Quadric的工作人員正在開發一個圖形用戶界面(GUI),它可以讓開發人員拖放包含CPU/DSP代碼和NPU模型的管道構建塊,將它們拼接在一起,并將所有內容編譯成一個ChimeraGPNPU image。這種無代碼開發方法將使大量開發人員能夠創建含有Chimera GPNPU的芯片。
審核編輯:劉清
-
SoC系統
+關注
關注
0文章
52瀏覽量
10690 -
機器學習
+關注
關注
66文章
8422瀏覽量
132743 -
數字信號處理器
+關注
關注
5文章
468瀏覽量
27356 -
NPU
+關注
關注
2文章
286瀏覽量
18647
原文標題:結合CPU、DSP、NPU功能為一體的新型混合處理器——Chimera GPNPU
文章出處:【微信號:SSDFans,微信公眾號:SSDFans】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
自動駕駛宣傳鋪天蓋地,真實體驗卻寡淡如水?

《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
智能家居中無線技術的比較

工商業儲能選型指南及參數詳解

專注充電充滿想象,羅馬仕全球品牌升級打造全場景用電體驗生態

專注充電充滿想象,羅馬仕全球品牌升級打造全場景用電體驗生態


眼花繚亂?數據采集卡接線端子原來是這樣接線的?#數據采集卡 #傳感器技術 #通信 #plc #pcb設計
揭秘芯片算力:為何它如此關鍵?

未來的智慧園區,充滿令人驚艷的場景
嵌入式圖形應用的架構選擇
微軟攜手OpenAI打造超級計算機數據中心 預計耗資超過1150億美元
如何選對LED錫膏?

2024年CES科技展:AI無處不在?






 工商網監
工商網監
評論