 也想造個ChatGPT?看你的算力跟得上嗎?
也想造個ChatGPT?看你的算力跟得上嗎?
近年來人工智能領域的發展可謂是日新月異主要突出個“大”“快”“準”
參數和算力規模越來越大、新模型的出現和迭代越來越快、預測結果越來越準。
回看剛剛過去的2022,好像每隔幾個月就會有公司發布一個新的AI模型,讓有史以來最大的AI模型這一稱號反復易手,全球各大頂尖的科技公司在此展開“軍備競賽”并樂此不疲。
當然,模型的“大”也帶來了性能的“強”,最近大火的ChatGPT已經能為你寫出代碼,甚至改變現有的搜索格局。就比如微軟正在將ChatGPT加入到Bing中來對抗Google,可謂是火藥味滿滿。
人工智能賽道的激烈交火
自從2018年谷歌推出3億模型參數的BERT模型,大規模預訓練模型逐漸進入人們的視野。隨后OpenAI推出了15億參數的GPT-2,這場軍備競賽便已開始了“低烈度”交火。
到了2020年,GPT-3的出現將這場軍備競賽直接拉升到千億級別。現在,萬億級別的Switch Transformer模型已經出現。在未來這場“軍備競賽”也許會更加激烈。
人工智能模型已然成長為一個“巨無霸”,就目前來看,大型語言模型的參數量依然保持增長勢頭,你幾乎看不到低于1億參數量的AI模型。
當然,這并不代表小模型是沒有潛力或是不好的。相較于大型AI模型,小型模型的投入更低,落地更加簡單,能夠更快更好的解決現實問題。只不過,大模型的泛用性及其強大的性能代表了未來人工智能發展的方向,因此也就更加容易被我們注意到。
“大”和“強”的背后是更多的挑戰
然而,強悍的性能與巨大的規模背后則是無數的資本投入,這些日漸龐大的AI模型也為現有的AI基礎設施和開發流程帶來了更多的挑戰。
眾所周知,一個強大的AI模型從誕生到商業化落地,需要大量的數據投喂、精巧的算法優化以及強大的算力支持。
現如今大模型的權重可達100GB以上,但我們的開發工具卻滯后于規模,使用起來十分費力,部署時往往要等上好幾小時,編譯時間長達兩分鐘,降低了AI工程師的工作效率,研發與迭代速度也會受到影響。
同時,訓練數據量也在以驚人的速度上漲,高質量的數據往往能加快訓練速度,而糟糕的數據可能會讓算法的效用大大降低。根據Scale AI的《人工智能準備情況》調查發現,數據質量成為獲取訓練數據時面臨的最大挑戰。
而隨著逐漸變大的體量,其參數量和算力要求給整個團隊和工程環節帶來極大的壓力。
戴爾科技集團助力AI持續前行
算力、算法、數據作為人工智能的三大要素缺一不可,強大的基礎設施總是能夠讓您更好地把握成功的機遇。
戴爾科技集團作為全球領先的數字化解決方案供應商,在AI和HPC領域深耕多年,致力于將算力轉化為業務創新能力,以科技賦能各行各業。
戴爾PowerEdge XE8545擁有強大的GPU加速器優化性能,專為高性能AI計算設計,使用業界領先的NVLink GPU直連設計,幫助您突破數據流和計算能力的界限,應對當下嚴苛的算力需求。
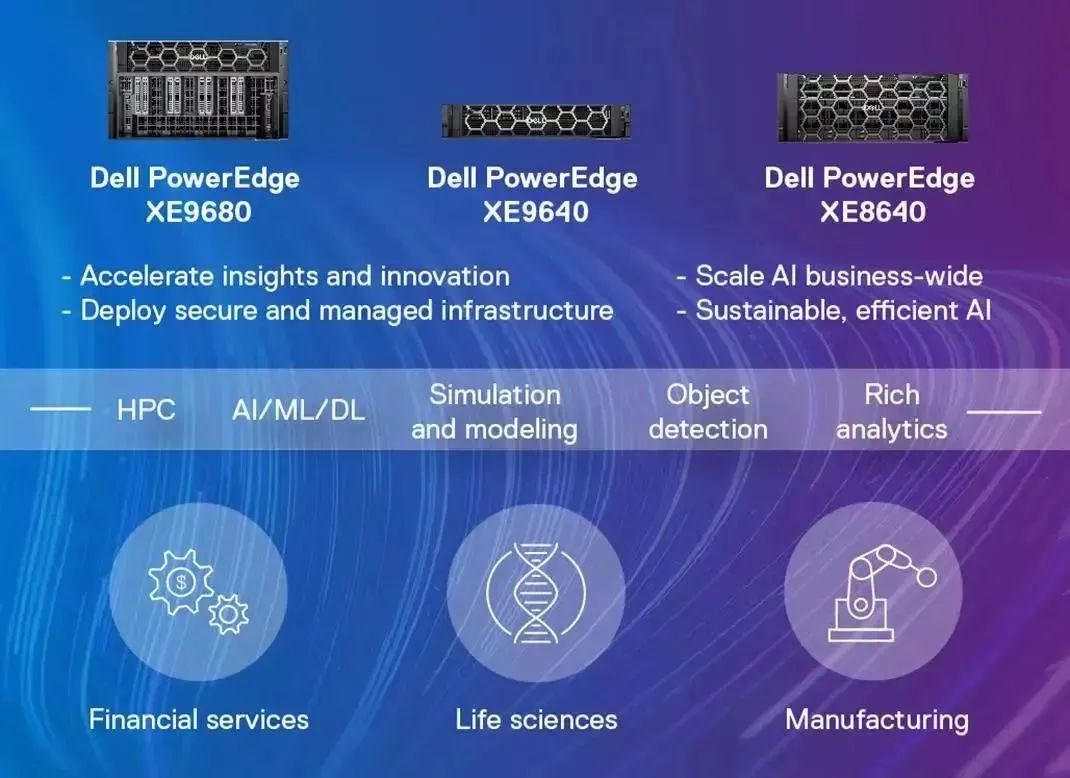
面向未來,戴爾科技集團用于AI的下一代PowerEdge產品組合也即將到來:PowerEdge XE9680、PowerEdge XE9640和PowerEdge XE8640,它們均為提供更高性能和更強大的計算結果而構建,幫助企業從容應對未來AI發展。
目前,非結構化數據用于AI的占比持續擴大,面對日益龐大且復雜的訓練數據量,高效的存儲系統對于工程師團隊的幫助則愈發顯著。在這方面,戴爾PowerScale橫向擴展NAS存儲能夠進一步消除I/O瓶頸,加快您的AI模型訓練和驗證速度,釋放非結構化數據的價值。
無論是大模型的軍備競賽,還是小模型的實用為先,AI正在以前所未有的速度持續發展,每一次突破都將為行業帶來顛覆性的變革。
戴爾科技集團將以全面的解決方案,助力越來越多的AI落地,持續以科技推動人工智能行業的發展。
審核編輯 :李倩
-
人工智能
+關注
關注
1792文章
47354瀏覽量
238812 -
模型
+關注
關注
1文章
3254瀏覽量
48894 -
ChatGPT
+關注
關注
29文章
1563瀏覽量
7775
原文標題:也想造個ChatGPT?看你的算力跟得上嗎?
文章出處:【微信號:戴爾企業級解決方案,微信公眾號:戴爾企業級解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
杰和課堂|帶你認識算力

算力基礎篇:從零開始了解算力
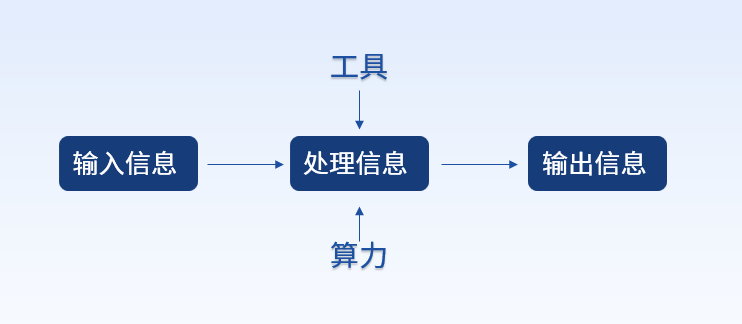
淺析三大算力之異同

大模型時代的算力需求
AI智算中心算力服務商探索智造完成A輪融資
急!OpenAI再推王炸GPT-4o,算力跟得上嗎?
算力系列基礎篇——算力101:從零開始了解算力

算力十問:超算智算,通算及算存比
智能算力規模超通用算力,大模型對智能算力提出高要求

ChatGPT算力芯片如何做算力輸出





 工商網監
工商網監
評論