 DALL-E和Flamingo能相互理解嗎?
DALL-E和Flamingo能相互理解嗎?
本文提出了一個統一的框架,其中包括文本到圖像生成模型和圖像到文本生成模型,該研究不僅為改進圖像和文本理解提供了見解,而且為多模態模型的融合提供了一個有前途的方向。
多模態研究的一個重要目標就是提高機器對于圖像和文本的理解能力。特別是針對如何在兩種模型之間實現有意義的交流,研究者們付出了巨大努力。舉例來說,圖像描述(image captioning)生成應當能將圖像的語義內容轉換輸出為可被人們理解的連貫文本。相反,文本 - 圖像生成模型也可利用文本描述的語義來創建逼真的圖像。
這就會帶來一些同語義相關的有趣問題:對于給定的圖像,哪種文本描述最準確地描述了圖像?同樣地,對于給定的文本,最有意義的圖像實現方式又是哪種?針對第一個問題,一些研究宣稱最佳的圖像描述應該是既自然且還能還原視覺內容的信息。而對于第二個問題,有意義的圖像應該是高質量的、多樣性的且忠于文本內容的。
不論怎樣,在人類交流的推動下,包含文本 - 圖像生成模型及圖像 - 文本生成模型的交互任務可以幫助我們選擇最準確的圖像文本對。
如圖 1 所示,在第一個任務中,圖像 - 文本模型是信息發送者,文本 - 圖像模型是信息接收者。發送者的目標是使用自然語言將圖像的內容傳達給接收者,以便其理解該語言并重建真實的視覺表征。一旦接收者可以高保真地重建原始圖像信息,則表明信息已傳遞成功。研究者認為這樣生成的文本描述即為最優的,通過其產生的圖像也最近似于原始圖像。

這一規律受到人們使用語言進行交流的啟發。試想如下情形:在一個緊急呼救的場景中,警察通過電話獲知車禍的情況和受傷人員的狀況。這本質上涉及現場目擊者的圖像描述過程。警方需要根據語言描述在腦海中重建環境場景,以組織恰當的救援行動。顯然,最好的文本描述應該是該場景重建的最佳指南。
第二個任務涉及文本重建:文本 - 圖像模型成為信息發送者,圖像 - 文本模型則成為信息接收者。一旦兩個模型就文本層面上信息內容達成一致,那么用于傳達信息的圖像媒介即為重現源文本的最優圖像。
本文中,來自慕尼黑大學、西門子公司等機構的研究者提出的方法,同智能體間通信緊密相關。語言是智能體之間交換信息的主要方法。可我們如何確定第一個智能體與第二個智能體對什么是貓或什么是狗這樣的問題有相同的理解呢?

論文地址:https://arxiv.org/abs/2212.12249
本文所想要探求的想法是讓第一個智能體分析圖像并生成描述該圖像的文本,而后第二個智能體獲取該文本并據此來模擬圖像。其中,后一個過程可以被認為是一個具象化體現的過程。該研究認為,如果第二個智能體模擬的圖像與第一個智能體接收到的輸入圖像相似(見圖 1),則通信成功。
在實驗中,該研究使用現成的模型,特別是近期開發的大規模預訓練模型。例如,Flamingo 和 BLIP 是圖像描述模型,可以基于圖像自動生成文本描述。同樣地,基于圖像 - 文本對所訓練的圖像生成模型可以理解文本的深層語義并合成高質量的圖像,例如 DALL-E 模型和潛在擴散模型 (SD) 即為這種模型。
此外,該研究還利用 CLIP 模型來比較圖像或文本。CLIP 是一種視覺語言模型,可將圖像和文本對應起來表現在共享的嵌入空間(embedding space)中。該研究使用手動創建的圖像文本數據集,例如 COCO 和 NoCaps 來評估生成的文本的質量。圖像和文本生成模型具有允許從分布中采樣的隨機分量,因而可以從一系列候選的文本和圖像中選擇最佳的。不同的采樣方法,包括核采樣,均可以被用于圖像描述模型,而本文采用核采樣作為基礎模型,以此來顯示本文所使用方法的優越性。
方法概覽
本文框架由三個預訓練的 SOTA 神經網絡組成。第一,圖像 - 文本生成模型;第二,文本 - 圖像生成模型;第三,由圖像編碼器和文本編碼器組成的多模態表示模型,它可以將圖像或文本分別映射到其語義嵌入中。
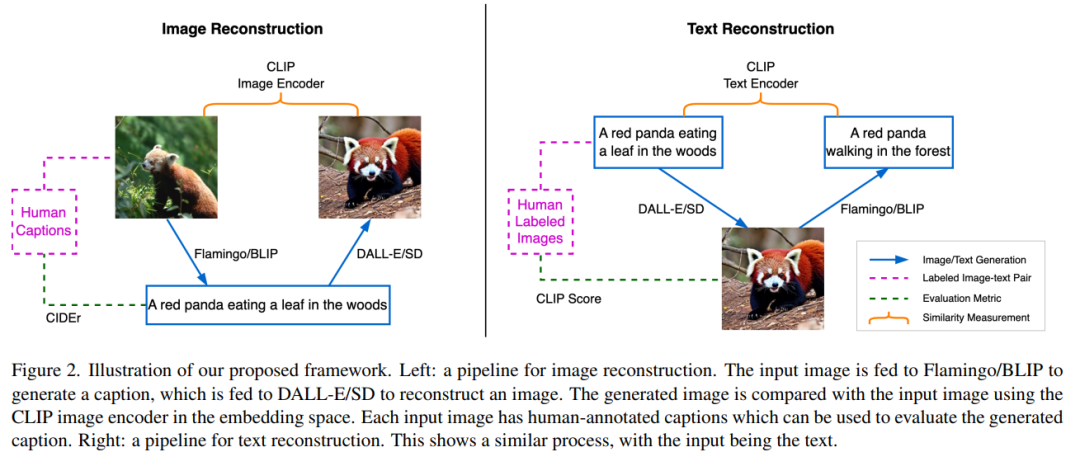
通過文本描述的圖像重建
如圖 2 左半部分所示,圖像重建任務是使用語言作為指令重建源圖像,此過程的效果實現將促使描述源場景的最佳文本生成。首先,源圖像 x 被輸送到 BLIP 模型以生成多個候選文本 y_k。例如,一只小熊貓在樹林中吃樹葉。生成的文本候選集合用 C 表示,然后文本 y_k 被發送到 SD 模型以生成圖像 x’_k。這里 x’_k 是指基于小熊貓生成的圖像。隨后,使用 CLIP 圖像編碼器從源圖像和生成的圖像中提取語義特征: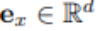 和
和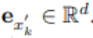 。
。
然后計算這兩個嵌入向量之間的余弦相似度,目的是找到候選的文本描述 y_s, 即
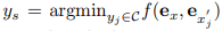
其中 s 為最接近源圖像的圖像索引。
該研究使用 CIDEr(圖像描述度量指標)并參照人類注解來評估最佳文本。由于對生成的文本質量感興趣,該研究將 BLIP 模型設定為輸出長度大致相同的文本。這樣就能保證進行相對公平的比較,因為文字的長度與可傳遞圖像中信息量的多少呈正相關。在這項工作中,所有模型都會被凍結,不會進行任何微調。
通過圖像實現文本重建
圖 2 中右側部分顯示了與上一節描述過程的相反過程。BLIP 模型需要在 SD 的引導下猜測源文本,SD 可以訪問文本但只能以圖像的格式呈現其內容。該過程始于使用 SD 為文本 y 生成候選圖像 x_k ,生成的候選圖像集用 K 來表示。使用 SD 生成圖像會涉及隨機采樣過程,其中每一次生成過程都可能會以在巨大的像素空間中得到不同的有效圖像樣本為終點。這種采樣多樣性會提供一個候選池來為篩選出最佳圖像。隨后,BLIP 模型為每個采樣圖像 x_k 生成一個文本描述 y’_k。這里 y’_k 指的是初始文本一只小熊貓在森林里爬行。然后該研究使用 CLIP 文本編碼器提取源文本和生成文本的特征,分別用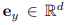 和
和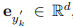 表示。此任務的目的是尋找匹配文本 y 語義的最佳候選圖像 x_s。為此,該研究需要比較生成文本和輸入文本之間的距離,然后選擇出配對文本距離最小的圖像,即
表示。此任務的目的是尋找匹配文本 y 語義的最佳候選圖像 x_s。為此,該研究需要比較生成文本和輸入文本之間的距離,然后選擇出配對文本距離最小的圖像,即
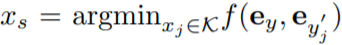 該研究認為圖像 x_s 可以最好地描繪出文本描述 y,因為它可以以最小的信息損失將內容傳遞給接收者。此外,該研究將與文本 y 相對應的圖像
該研究認為圖像 x_s 可以最好地描繪出文本描述 y,因為它可以以最小的信息損失將內容傳遞給接收者。此外,該研究將與文本 y 相對應的圖像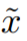 視為 y 的參考表示(reference presentation),并將最佳圖像量化為它與參考圖像的接近程度。實驗結果圖 3 中的左側圖表顯示了兩個數據集上圖像重建質量和描述文本質量之間的相關性。對于每個給定圖像,重建圖像質量(在 x 軸中顯示)越好,文本描述質量(在 y 軸中顯示的)也越好。 圖 3 的右側圖表揭示了恢復的文本質量和生成的圖像質量之間的關系:對于每個給定的文本,重建的文本描述(顯示在 x 軸上)越好,圖像質量(顯示在 y 軸上)就越好。
視為 y 的參考表示(reference presentation),并將最佳圖像量化為它與參考圖像的接近程度。實驗結果圖 3 中的左側圖表顯示了兩個數據集上圖像重建質量和描述文本質量之間的相關性。對于每個給定圖像,重建圖像質量(在 x 軸中顯示)越好,文本描述質量(在 y 軸中顯示的)也越好。 圖 3 的右側圖表揭示了恢復的文本質量和生成的圖像質量之間的關系:對于每個給定的文本,重建的文本描述(顯示在 x 軸上)越好,圖像質量(顯示在 y 軸上)就越好。
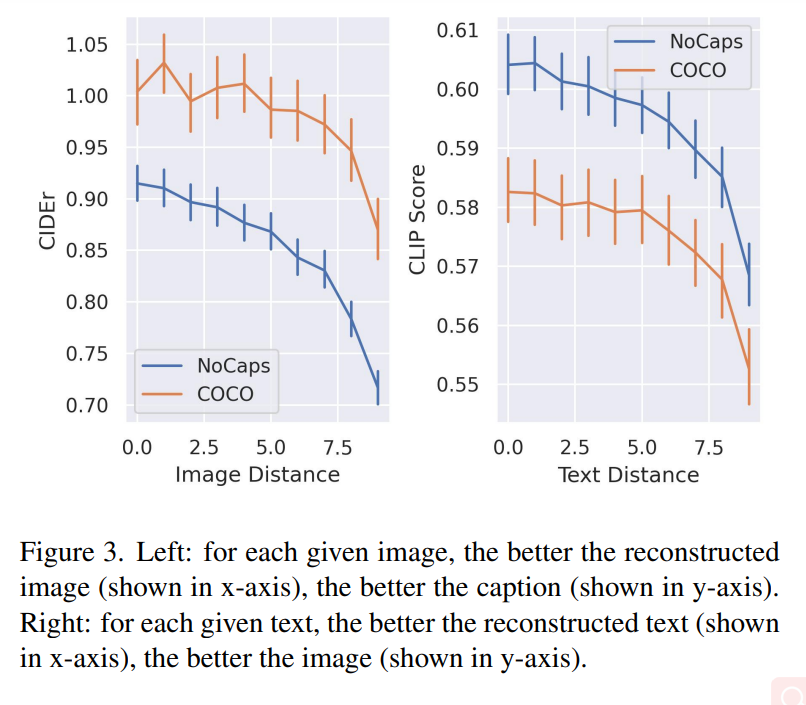
圖 4(a)和(b)顯示了圖像重建質量和基于源圖像的平均文本質量之間的關系。圖 4(c)和(d)顯示了文本距離(text distance)與重建圖像質量之間的相關性。
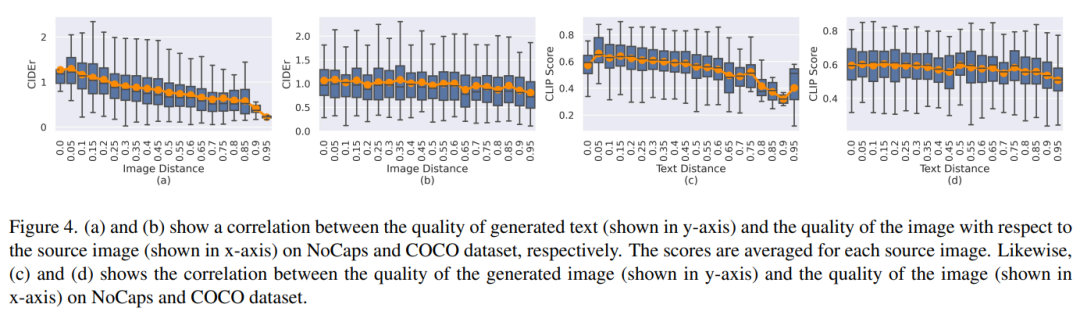
表 1 顯示出該研究的采樣方法在每個度量標準下都優于核采樣,模型的相對增益可以高達 7.7%。
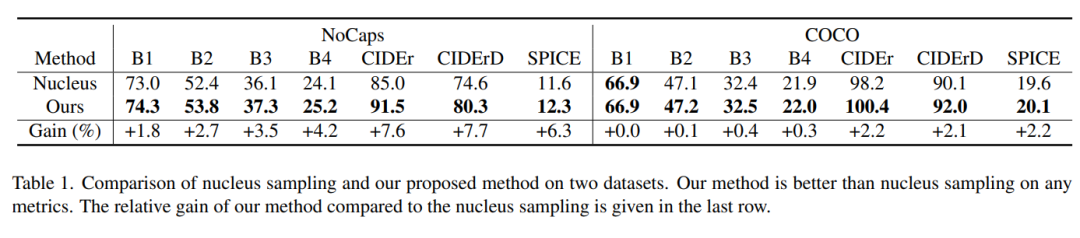
圖 5 顯示了兩個重建任務的定性示例。

審核編輯 :李倩
-
神經網絡
+關注
關注
42文章
4774瀏覽量
100890 -
圖像
+關注
關注
2文章
1087瀏覽量
40500 -
模型
+關注
關注
1文章
3265瀏覽量
48917
原文標題:DALL-E和Flamingo能相互理解嗎?三個預訓練SOTA神經網絡統一圖像和文本
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文說清楚什么是AI大模型
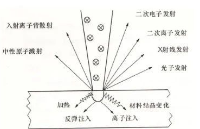
離子束與材料的相互作用
OpenAI推出AI視頻生成模型Sora
DAC8565和dac8555的管腳是pin對pin的,兩者能直接相互替換嗎?
膨體聚四氟乙烯e-PTFE透氣膜的IP防護等級要考濾哪些因素?

影響電感儲能特性的因素
愛芯元智推出邊端側智能SoCAX650N,讓視覺更智能
OpenAI發布圖像檢測分類器,可區分AI生成圖像與實拍照片
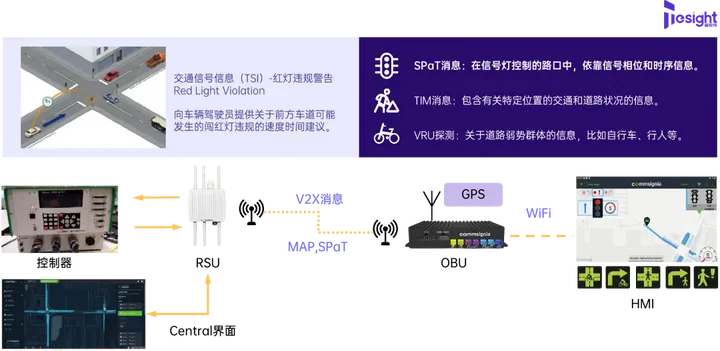
讓交通運輸更安全、更高效,人工智能可以做些什么?
sora模型怎么使用 sora模型對現實的影響
sora最新消息 sora是什么意思
sora系列是哪個公司的 sora視頻怎么用
OpenAI發布人工智能文生視頻大模型Sora
微軟封禁員工討論OpenAI DALL-E 3模型漏洞
CES亮點:AI賦能與產業創新 | DALL-E 3、SD等20+圖像生成模型綜述





 工商網監
工商網監
評論