") 使用VS2022對(duì)GPU進(jìn)行CUDA編程
使用VS2022對(duì)GPU進(jìn)行CUDA編程
在異構(gòu)計(jì)算架構(gòu)中,GPU與CPU通過(guò)PCIe總線連接在一起來(lái)協(xié)同工作,CPU所在位置稱(chēng)為為主機(jī)端(host),而GPU所在位置稱(chēng)為設(shè)備端(device),兩者優(yōu)勢(shì)互補(bǔ)。
CUDA作為GPU的編程模型,提供了對(duì)其他編程語(yǔ)言的支持,例如常用的C/C++,Python等。
下面在windows系統(tǒng)下,使用VS2022對(duì)GPU進(jìn)行CUDA編程。
開(kāi)始之前你需要準(zhǔn)備的硬件是:一塊GPU顯卡。并假設(shè)你已經(jīng)提前安裝了VS2022,而且具備一定的軟件編程經(jīng)驗(yàn)。
安裝CUDA
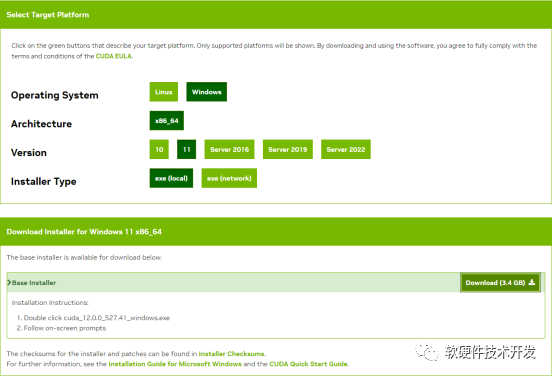
首先進(jìn)行CUDA編程模型的安裝,根據(jù)自己的系統(tǒng)情況到CUDA官網(wǎng)下載安裝包。下載完成后進(jìn)行安裝,過(guò)程很簡(jiǎn)單。
安裝完成后,“win+R”輸入cmd打開(kāi)終端后輸入:nvcc -V,檢驗(yàn)安裝是否成功。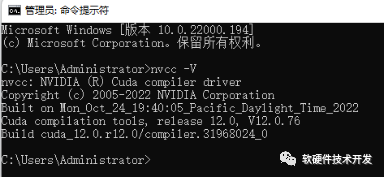
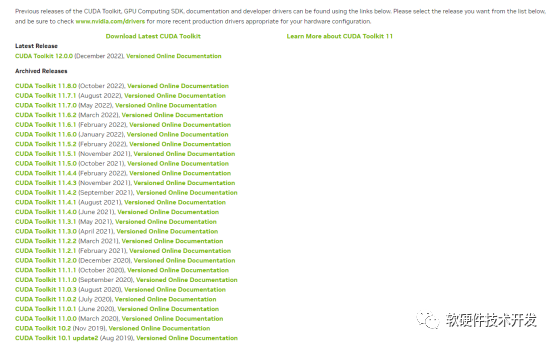
若需要下載以前的版本,你還可以點(diǎn)擊查看你需要下載的CUDA版本: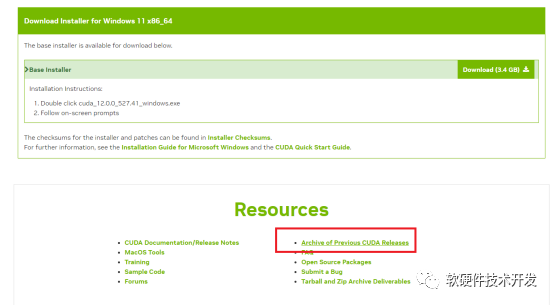
創(chuàng)建VS2022項(xiàng)目
CUDA安裝完成后,打開(kāi)VS2022創(chuàng)建新項(xiàng)目,選擇CUDA runtime。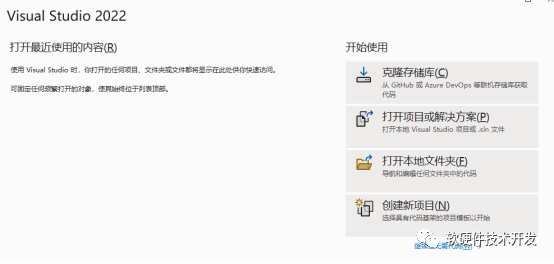
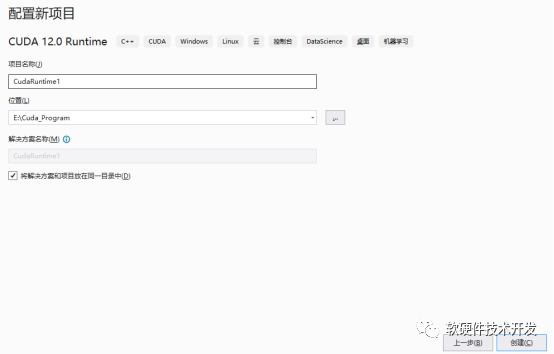
新建完成后有一個(gè)簡(jiǎn)單的例程,直接進(jìn)行調(diào)試即可看到下面的結(jié)果:
在CUDA中,用host指代CPU及其內(nèi)存,用device指代GPU及其內(nèi)存。
CUDA程序既包含host程序,又包含device程序,它們分別在CPU和GPU上運(yùn)行。
同時(shí),host與device之間可以進(jìn)行數(shù)據(jù)拷貝。
在CUDA中是通過(guò)函數(shù)類(lèi)型限定詞開(kāi)區(qū)別host和device上的函數(shù),主要的三個(gè)函數(shù)類(lèi)型限定詞如下:
__global__:在device上執(zhí)行,從host中調(diào)用(一些特定的GPU也可以從device上調(diào)用),返回類(lèi)型必須是void,不支持可變參數(shù),不能成為類(lèi)成員函數(shù)。
注意用__global__定義的kernel是異步的,這意味著host不會(huì)等待kernel執(zhí)行完就執(zhí)行下一步。
__device__:在device上執(zhí)行,僅可以從device中調(diào)用,不可以和__global__同時(shí)用。
__host__:在host上執(zhí)行,僅可以從host上調(diào)用,一般省略不寫(xiě),不可以和__global__同時(shí)用,但可和__device__,此時(shí)函數(shù)會(huì)在device和host都編譯。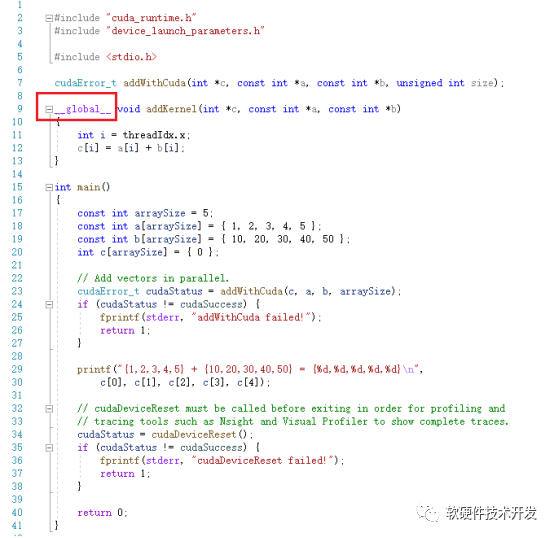

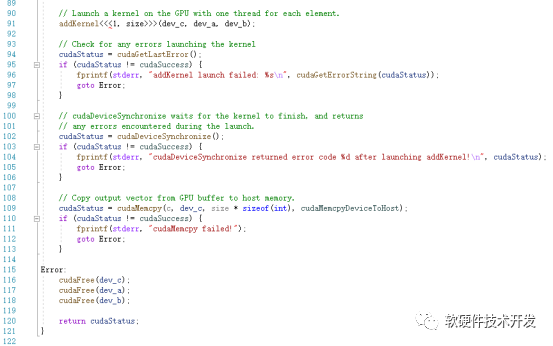
該例程雖然簡(jiǎn)單,也反映了典型的CUDA程序流程:
分配host內(nèi)存,并進(jìn)行數(shù)據(jù)初始化;
分配device內(nèi)存,并從host將數(shù)據(jù)拷貝到device上;
在device上調(diào)用CUDA的核函數(shù)(kernel)完成進(jìn)行并行計(jì)算;
將device上的運(yùn)算結(jié)果拷貝到host上;
釋放device和host上分配的內(nèi)存。
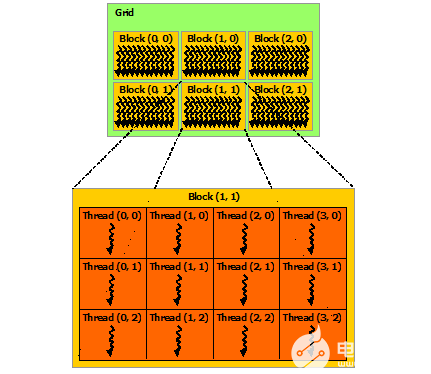
其中,kernel是在device上線程中并行執(zhí)行的函數(shù),核函數(shù)用__global__符號(hào)聲明,在調(diào)用時(shí)需要用<<
審核編輯:劉清
-
PCIE總線
+關(guān)注
關(guān)注
0文章
58瀏覽量
13366 -
python
+關(guān)注
關(guān)注
56文章
4792瀏覽量
84628 -
CUDA
+關(guān)注
關(guān)注
0文章
121瀏覽量
13620
原文標(biāo)題:安裝CUDA,并使用VS2022開(kāi)始CUDA編程
文章出處:【微信號(hào):雷達(dá)通信電子戰(zhàn),微信公眾號(hào):雷達(dá)通信電子戰(zhàn)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
有沒(méi)有大佬知道NI vision 有沒(méi)有辦法通過(guò)gpu和cuda來(lái)加速圖像處理
在K520上能使用兩個(gè)GPU進(jìn)行CUDA作業(yè)嗎
linux安裝GPU顯卡驅(qū)動(dòng)、CUDA和cuDNN庫(kù)
計(jì)算機(jī)組成原理 — GPU 圖形處理器 精選資料分享
VS2022破解vMicro
GPU高性能運(yùn)算之CUDA
NVIDIA GPU計(jì)算的關(guān)鍵技術(shù)解析
CUDA學(xué)習(xí)筆記第一篇:一個(gè)基本的CUDA C程序
CUDA簡(jiǎn)介: CUDA編程模型概述
國(guó)產(chǎn)GPU繞不開(kāi)的CUDA生態(tài)
使用CUDA進(jìn)行編程的要求有哪些
GPU平臺(tái)生態(tài),英偉達(dá)CUDA和AMD ROCm對(duì)比分析

介紹CUDA編程模型及CUDA線程體系





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論