 貼吧低代碼高性能規則引擎設計
貼吧低代碼高性能規則引擎設計
本文首先介紹了規則引擎的使用場景,引出貼吧規則引擎。從組件、變量、規則、處置四個模塊介紹了規則引擎的組成部分,同時對最終規則文件的編譯過程做了詳細介紹。為了做到低代碼,在規則配置上做到平臺化,非研發同學即可完成。增加新的變量也只需要在變量平臺進行簡單操作,無需額外的代碼提交。另外框架層面支持并行和異步的封裝,在服務調用上也盡量做到減少代碼,提高研發同學的效率。最后文章對貼吧規則引擎做了總結,也提供了一些常見的使用場景和思路。
01
背景
百度貼吧是一個擁有10多年歷史的UGC產品,在業務迭代中難免會有很多業務邏輯的代碼,其中一部分業務邏輯用if-else等硬編碼的形式開發,一部分引入了配置文件,通過配置文件的規則去執行不同的業務邏輯。在某些運營活動或權益規則中,需要頻繁增加或者更改一些規則,這部分規則經常變動的部分就需要規則引擎來統一管理。
規則引擎是一種專注于業務規則的服務,它可以將業務規則從代碼中剝離出來,使用預先定義好的語義規范來實現這些剝離出來的業務規則。規則引擎通過接受輸入的數據,進行業務規則的評估,并做出業務決策。
因為規則引擎將復雜的業務邏輯從業務代碼中剝離出來,所以可以顯著降低業務邏輯實現難度;同時,剝離的業務規則使用規則引擎實現,這樣可以使多變的業務規則變的可維護,配合規則引擎提供的良好的業務規則設計器,不用編碼就可以快速實現復雜的業務規則,同樣,即使是完全不懂編程的運營或者產品人員,也可以使用圖形化的界面來自定義規則,實現代碼一樣的效果。
下面對一些需要使用規則引擎的場景進行舉例:
1、單規則迭代
用戶標簽->包含A關鍵詞->權益A
用戶標簽->包含A關鍵詞->權益A
->包含B關鍵詞->權益B
用戶標簽->身份豁免策略/機器賬號->包含A關鍵詞->權益A
->包含B關鍵詞->權益B
用戶標簽->A模型結果大于1 ->豁C類用戶->包含A關鍵詞->權益C
可見隨著業務的發展,需要不斷的調整權益規則,這部分如果硬編碼寫死在代碼中,需要頻繁上線,增加了工作量,并且隨著業務邏輯的增多,后期維護成本增高。 2、持續接入新的能力除了目前的字符串比較能力,一般的規則引擎還會接入各種各樣的模型能力,一般通過RPC的形式請求不同的服務,隨著接入的服務越來越多,可以組合的規則也是成倍的增長;
比如新接入圖片模型識別后,所有圖片識別的結果會過其他相關的模型,相關的模型調用邏輯就增加了一倍;
又如接入了某些模型,要根據模型的分數做相應的處理調整,需要頻繁的改動分值對應的處置手段,同時為了應對突發的場景,也需要頻繁的更改規則。
這些操作如果沒有一個自動化的規則引擎,就需要把大量的規則邏輯寫在代碼里,經過長時間的迭代,規則變得非常臃腫,無論對后續的開發還是定位問題的效率都會帶來問題。
02
貼吧規則引擎組成部分
貼吧規則引擎要做到規則靈活可配,無需研發介入,就需要盡可能的把包含判斷邏輯的部分全部下放到平臺,通過平臺的勾選對規則進行實現。
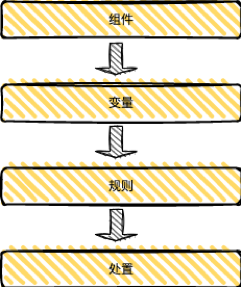
上圖為規則引擎整體的模塊劃分,主要分為四部分:
組件服務:組件服務是對第三方服務的封裝,比如調用圖片模型服務、調用帖子屬性等內容服務,一般是RPC調用;組件需要RD開發代碼,但是貼吧規則引擎的組件調用不摻雜業 務邏輯,僅僅是定義一個函數function,通過函數的入參調用第三方服務返回結果;
變量平臺:變量又稱算子,是配置規則的參數;變量分為業務調用時傳的入參、使用組件返回的結果等。貼吧規則引擎通過專用平臺管理變量,RD和PM均可以在平臺上配置變量;
規則引擎:規則引擎平臺涉及到了具體每一條規則,通過圖形化的界面生成規則,該平臺不需要RD介入,通過平臺化的操作生成具體的規則。
處置方法:該處置為RD定制化開發,針對帖子、用戶或其他場景的召回處置處理。一般定義一個rpc請求回調相關業務,處置方法因為是場景定制化的,所以這部分需要研發介入開發,但是處置方法更新的頻率非常低,一般都是復用已有的能力。
2.1組件服務
規則引擎所有配置的數據不可能都是上游參數傳遞,很多是通過調用第三方服務獲取;比如通過帖子id獲取的帖子詳情數據,通過用戶uid獲取用戶的擴展屬性,這里都需要調用第三方服務;
組件的開發非常簡單,只需要聲明一個函數,并實現其靜態方法。為了后續的性能考慮,函數聲明時可以指定sync(串行)、async(異步)、parallel(并行)三種執行方式,貼吧規則引擎會在調度的時候按照類型,使用更高效的方式執行對應的方法。
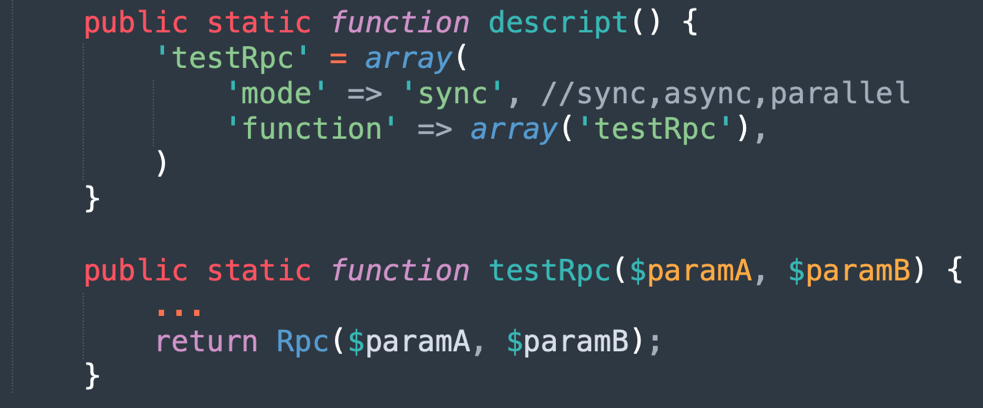
圖中給出了一個demo組件,可以看出組件是不關注業務的,可以自定義入參和返回值,具體調用函數的入口及參數也不需要額外關注,更符合lib庫或者util方法的實現方式,這種組件的好處是開發簡單,解耦業務邏輯,增加組件的復用性,同時也降低了研發同學的工作量。
另外對于mode的工作模式,分為以下三類,具體的實現都是框架實現,組件的開發方不需要關注:
sync:同步調用,使用的時候串行執行,函數間是阻塞的;
async:異步調用,定義function的時候分為before、after兩組方法。Before階段為發起rpc請求,等待第三方服務回調后執行after方法,可以應對好耗時的服務接入。
parallel:并行模式,屬于同一層級的parallel 函數并行執行,類似于多線程或者golang的goroutine模式,目前貼吧的規則引擎采用php開發,不具備多線程的相關能力,所以這里并行是在before組裝rpc參數,通過curl_multi統一發起并行請求,在after函數取到結果。
以上能力在規則引擎框架上已經封裝,組件的研發RD只需要關注PRC的實現即可,根據函數的定義框架實現并行或者異步的調用。
2.2 變量平臺
變量或者算子就是規則引擎中做規則判斷使用的參數,比如用戶名、帖子id、用戶等級、帖子內容、模型識別的結果等,這部分的內容越多,規則引擎可以創建規則的『素材』越多;
變量的來源分為三個部分:
(1)平臺預定義的變量:比如一些常量數字或者特定字符串,這部分內容比較固定,變動較少。
(2)業務入參:業務在請求規則引擎的時候可以把盡可能多的參數變量傳遞過來,除了帖子、用戶、吧相關的數據,還可以把用戶ip、ua等各種數據一并傳遞,這些數據在變量的平臺化界面上可以做簡單的篩選或者摘取,生成新的變量。

如圖舉例:input是一個完成的業務請求的變量,取input中的title生成testTitle變量,這樣就可以單獨使用testTitle做一些規則上的判斷。
(3)組件調用:在組件的部分已經定義了具體的方法,該方法類似于lib庫或者util,具體的請求的入口在變量平臺實現,入參就是其他變量。

如圖舉例:testRPC是定義的組件,其中入參是testTitle變量,返回的大結果作為一個testRPC變量。
后面可以對testRPC變量做具體的拆分,比如testRPC中的data.score作為一個單獨的變量,用score這個變量做后面的規則定義。
整體來說,input是上游傳過來的基礎變量。對入參變量的整理和過濾可以生成額外的基礎變量;使用基礎參數(比如帖子id),通過rpc調用,可以生成擴展的結果;對結果的提取可以生成額外的第二級變量;進一步對二級變量繼續調用服務,可以生成更多的變量:比如通過圖片模型結果過一些文本模型,但是隨著層級的變深,整體服務呈現多級依賴關系,這也增加了整體的系統耗時。
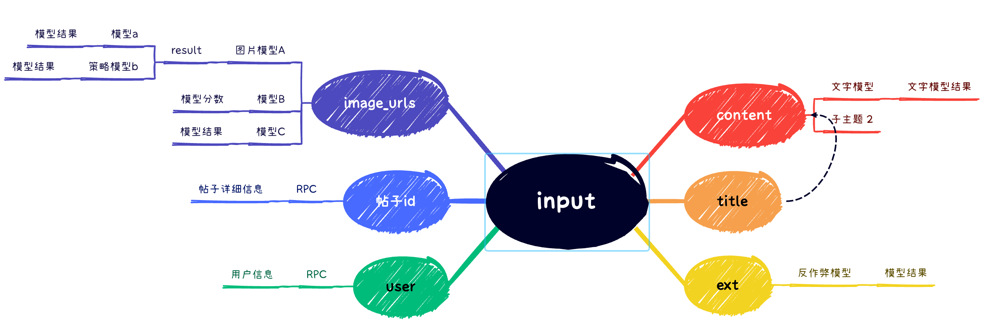
對于入參或者RPC請求結果的處理,全部可以在變量平臺上進行操作,變量平臺定義了規則引擎可以使用的變量及具體的實現方式。因為變量平臺支持編輯代碼,所以一般的變量都可以直接在變量平臺編輯完成,而對相對復雜的模型調用,則可以封裝通用的util方法,之后在變量平臺直接使用這些方法。
2.3 規則引擎平臺
組件是一個個簡單的util靜態方法,通過入參及調用組件生成擴展的變量;自此進行規則判斷的『素材』準備好了,接下來需要使用這些變量配置規則,而核心的規則引擎平臺就是使用這些變量,生成規則。
規則引擎目前支持的運算規則:
規則運算符:目前支持變量值與常量的比較,包含基本的>,<,>=,<=,==,!=多種比較方式;另外不僅可以直接使用變量,對于數組類型的變量,還可以直接使用了變量的計數count,對于string類型,可以使用變量的長度len做參數直接進行判斷。
詞表比較:判斷某個詞是否在詞表中是一個比較常用的規則;規則引擎平臺支持本地詞表與遠程詞表;遠程詞表為了解決詞表量級太大的問題。
字符與詞表的比較包括精確匹配,包含、不包含、前綴匹配及后綴匹配幾種方式,基本覆蓋了常見的使用方式。
粒度控制判斷:為了判斷某個調整在一段時間內的出現次數,平臺支持配置變量的出現次數統計。
對于某些使用頻次較少的運算規則,平臺不在功能上進行統一支持,但是可以通過修改變量來支持。比如想判斷變量A的sin值大于Z,可以在變量平臺新配置一個變量B,它的定位為sin(A),然后在規則引擎上使用B這個變量做判斷,就解決了某些特殊的計算方式。
對于判斷邏輯,目前支持if條件判斷,switch多分支判斷,確定召回,確定豁免四種方式,基本囊括了常用的判斷邏輯。
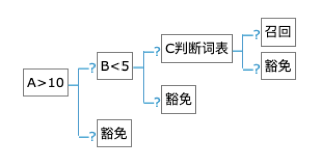
△簡單的策略配置demo
2.4處置方法
處置方法是針對不同的業務場景召回的個性化處置邏輯,這部分需要RD開發代碼,做個性化的處理;比如命中召回后返回true or false或者命中的規則號或者回調特殊標記。
處置方法添加的頻率不會很高,基本固定對帖子、用戶或者各個場景有1-2個處置方法即可,后續的多個規則直接復用處置方法。
GEEK TALK
03
規則引擎實現原理
規則引擎最終生成是一個包含所有規則邏輯的代碼塊,代碼塊在規則引擎框架中運行;生成的代碼塊類似研發開發的代碼:代碼的邏輯依舊是定義變量、使用變量做條件判斷(規則)、命中召回的處置。
1. 變量
這部分比較容易理解,就是2.2部分;將所有定義的變量取出來,當然因為變量之間是遞歸依賴的,所以當變量中需要其他變量時,會遞歸獲取內容,直到獲取常量或沒有依賴為止,最后倒序輸出為代碼片段。
2. 規則文件生成
每一條規則在存儲上都是一個json串,存儲形式為一個nodeTree。其中一個node節點存儲了類型:判斷節點、召回節點、豁免節點以及多組(switch)判斷節點。其中召回節點和豁免節點是程序判斷的終止位置,當執行到召回節點時會加載規則引擎對應的處置方法。判斷節點是整個規則引擎的核心,包含對應的變量與比較方式。其中比較方式有數字比較、字符串比較及詞表比較。比如內容中是否包含關鍵詞“AB”,則在判斷節點上選取內容變量,比較方式為詞表包含,詞表內容為“AB”。
在規則文件的設計上,采用nodeTree的方式,既能方便后續擴展node的屬性和類型,又通過父子節點樹的方式多層級的表示復雜的if、switch邏輯,層級可以無限深。
在新的規則上線時,將nodeTree文件從數據庫中全部導出,生成全部的規則文件。規則文件依賴的變量已經在變量文件中全部定義好,剩下的工作就是將變量與規則進行組裝,生成最終的可執行代碼。
另外對于某些特殊的需求,需要對白名單中的uid或者類型進行全部策略豁免。對于此類需求可以修改所有的規則,增加前置判斷邏輯,但是此操作需要對現有的全部規則及增量規則都修改,且在規則執行中會增加額外的判斷邏輯,增加整體規則引擎的執行耗時,所以除了普通的規則外,貼吧規則引擎增加了全局規則區。全局規則區相當于所有規則的前置條件,具體配置的規則為普通的node判斷節點,當全局的所有規則判斷均為true時才會依次執行具體的普通規則,這樣對于想全局豁免的需求,只需要簡單配置全局規則即可,不需要修改具體的詳細規則。
3. 生成可執行規則文件
規則引擎的前期編譯工作需要生成可以執行的代碼,這部分就是將圖形化配置的規則與變量進行組合,優化整體的代碼執行邏輯,生成可執行的代碼,將文件下發到所有的線上機器。
其中變量文件是可以執行的php語法,規則為導出的json文件,需要將不同類型的文件進行組合,這里需要將不同文件源轉為同一種結構化數據。
對于原本是php語法的文件,貼吧規則引擎采用ply和yacc進行詞法和語法的解析,對php語法中array、函數、賦值、條件判斷、運算符等進行提取,轉為結構化的數據。
對于規則文件,因為是預先定義好的json nodeTree,包含的格式是有限可枚舉的,只要將每種類型與規則映射為結構化的字段,就可以將規則文件轉位目標結構化數據。
之后就是可執行文件的生成過程,具體需要以下步驟:
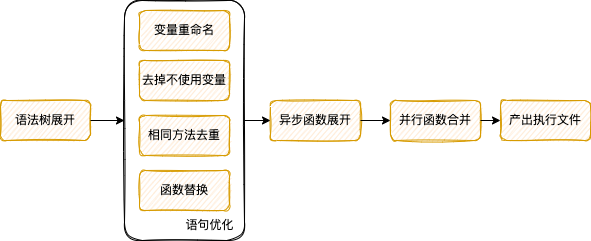
語法樹展開:通過遞歸調用,將函數嵌套展開。比如res = funA(funB($params))展開為 tmp1 = funB($params);res = funA(tmp1);展開后將高階函數展開成普通函數,方便后續的優化處理。
接下來就是語句優化部分:
將不同變量重名的部分自動增加_n后綴,避免變量的相互覆蓋;遍歷整體規則中使用的變量,如果存在變量從未使用過,從整體代碼中去除;對于定義了多遍重復的函數調用,整體去重只保留一份;對并行或者異步方法的函數組拆分成真正可執行的靜態方法。經過以上步驟,對將要生成的最終規則文件進行了初步的整理及優化。
在組件服務中提到了異步函數async;對于某些耗時非常高的模型服務,異步函數的作用是觸發調用后結束,等待第三方服務回調。
對于使用異步函數的情況,至少拆分成兩步,第一步發起觸發,第二步收到模型回調,取到該步驟的結果作為變量,所有依賴該變量的規則只能放到第二步執行。如果有函數依賴第二步的結果,則步驟會繼續增加,該函數取某變量的異步結果,發起服務請求,第三步回調收到結果;異步函數展開的作用是將所有無依賴的異步函數請求方法統一放在一起,并行請求,通過回調觸發執行第二步的規則邏輯。這樣貼吧規則引擎可以很方便的接入高耗時的模型服務。
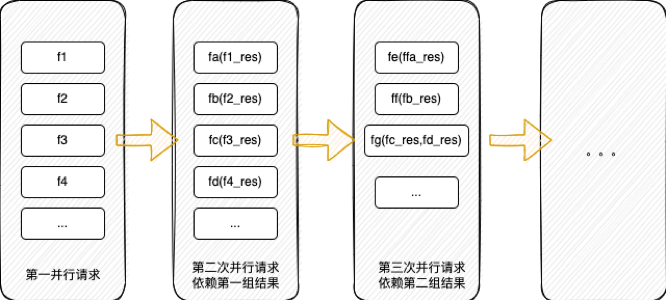
除了異步函數,還存在一種parallel并行調用的方式。由于規則引擎采用php的語言選型,沒有其他語言方便的多線程或者協程調用方式,對于無依賴的函數不能支持并行調用,所以在規則引擎的設計上通過curl_multil并行rpc調用服務的形式來減少耗時。
目前比較耗時的函數一般是請求數據庫服務或者第三方服務,這里將數據庫及第三方的調用全部封裝為http協議的形式,在策略文件調用上通過before方法整理入參,通過類似curl_multil的方法并行調用服務,取到結果后執行各自函數的after方法,整理函數對應的變量,這樣就將無依賴關系的調用進行了并行處理,整體降低了耗時。并行函數合并就是框架層面做的自動化合并,規則引擎的研發同學只需要簡單定義before和after方法,編譯階段就會自動將所有無依賴的函數before方法執行,組裝rpc請求。如果某些函數在before階段依賴其他服務的結果,那么這批函數將在第二次發起請求,即無任何依賴的函數先發起并行請求,依賴第一批結果的函數再發起第二次并行請求,以此類推,最大限度的使用并行調用的方式。
最終生成的可執行的文件,基本的最小單元為name、func、param、cond四組字段組成。如果cond判斷條件為真,則name通過函數和入參數執行對應方法,產出值;該值又是其他單元的條件變量或者函數入參,這樣由上到下依次執行,完成了所有規則的執行。 仍然以上述demo策略為例:
最終生成了四組單元,基本格式如下:
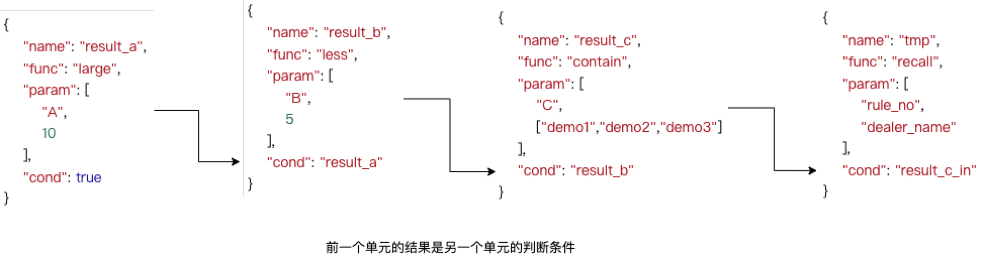
如圖所示,基于上述的規則,只需要四組基本單元,每一組通過函數計算結果,下一組的條件依賴結果的值,如果走到“召回”邏輯,則進行表示規則命中,返回對應的規則號及其處置方法,框架中根據處置方法執行對應的邏輯。
每一個規則都是上述基本單元組成,最終將nodeTree中的全部規則生成基本單元,文件下發到所有運行的機器上,至此完成了規則文件的產出與規則上線。
04
總結
貼吧規則引擎搭配圖形化的界面,非常方便非技術同學配置業務規則,將冗余的業務邏輯全部托管在規則引擎平臺上,無需代碼開發,即可上線或者修改規則。 另外框架層面將異步、并行等復雜邏輯進行了封裝,研發同學調用新的模型只需要按照模版修改簡單的參數整理及返回數據整理,即可完成并行或者異步的操作,減少規則引擎的執行耗時。對于變量結果的轉換,也可以通過變量管理平臺,在平臺上簡單的修改即可完成一些基本的整理邏輯,大大減少代碼的開發量。 通過規則引擎,可以靈活配置運營活動中的抽獎規則、用戶身份權益配置、商品價格等包含復雜業務邏輯判斷的部分,將規則抽象出來,解放研發同學的人力,同時規則在平臺上可以方便查找和定位,方便后續的維護。
審核編輯 :李倩
-
引擎
+關注
關注
1文章
361瀏覽量
22588 -
函數
+關注
關注
3文章
4338瀏覽量
62743 -
代碼
+關注
關注
30文章
4802瀏覽量
68740
原文標題:貼吧低代碼高性能規則引擎設計
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
低代碼在敏捷開發中的應用
鴻蒙原生頁面高性能解決方案上線OpenHarmony社區 助力打造高性能原生應用
使用AMD Versal AI引擎加速高性能DSP應用
澎峰科技高性能大模型推理引擎PerfXLM解析

CDC509高性能、低偏斜、低抖動、鎖相環(PLL)時鐘驅動器數據表

CDCM7005-SP高性能、低相位噪聲和低偏斜時鐘同步器數據表
國內低代碼平臺推薦--萬界星空科技低代碼平臺
非常實用的PCB布局布線規則,畫出美而高性能的板子

低代碼開發有哪些優勢?






 工商網監
工商網監
評論