


導讀
這項工作旨在提高視覺Transformer(ViT)的效率。雖然ViT在每一層中使用計算代價高昂的自注意力操作,但我們發現這些操作在層之間高度相關——這會導致產生很多不必要計算的冗余信息。基于這一觀察,我們提出了SKIPAT方法,該方法利用前面層的自注意力計算來近似在一個或多個后續層的注意力。為了確保在層之間重用自注意力塊而不降低性能,我們引入了一個簡單的參數函數,該函數在計算速度更快的情況下能表現出優于基準Transformer的性能。我們在圖像分類和ImageNet-1K上的自我監督學習、ADE20K上的語義分割、SIDD上的圖像去噪以及DAVIS上的視頻去噪中展示了我們方法的有效性。我們在所有這些任務中都在相同或更高的準確度水平下實現了提高模型吞吐量。
背景

Performance of SKIPAT across 5 different tasks.
Transformer架構已經成為一個重要且影響深遠的模型系列,因為它簡單、可擴展,并且應用廣泛。雖然最初來自自然語言處理(NLP)領域,但隨著視覺transformer(ViT)的出現,這已成為計算機視覺領域的標準架構,在從表示學習、語義分割、目標檢測到視頻理解等任務中獲得了各種最先進(SoTA)性能。
然而,transformer的原始公式在輸入令牌(token)數量方面具有二次計算復雜度。鑒于這個數字通常從圖像分類的14^2到圖像去噪的128^2 = 16K不等,內存和計算的這一限制嚴重限制了它的適用性。目前有三組方法來解決這個問題:第一組利用輸入令牌之間的冗余,并通過高效的抽樣簡單地減少計算,例如丟棄或合并冗余令牌。然而,這意味著ViT的最終輸出不是空間連續的,因此不能超出圖像級別(image-level)的應用,如語義分割或目標檢測。第二組方法旨在以低成本計算近似注意力,但通常以性能降低為代價。最后,另一組工作旨在將卷積架構與transformer合并,產生混合架構。雖然這些方法提高了速度,但它們并沒有解決二次復雜度的基本問題,并且通常會引入過多的設計選擇(基本上是transformer和CNN的聯合)。
在這項工作中,我們提出了一種新穎的、迄今為止未經探索的方法:利用計算速度快且簡單的參數函數來逼近transformer的計算代價高的塊。為了得出這個解決方案,我們首先詳細地分析了ViT的關鍵多頭自注意力(MSA)塊。通過這項分析,我們發現CLS令牌對空間塊的注意力在transformer的塊之間具有非常高的相關性,從而導致許多不必要的計算。這啟發了我們的方法利用模型早期的注意力,并將其簡單地重用于更深的塊——基本上是“跳過”后續的SA計算,而不是在每一層重新計算它們。
基于此,我們進一步探索是否可以通過重用前面層的表示來跳過整一層的MSA塊。受ResneXt的深度卷積的啟發,我們發現一個簡單的參數函數可以優于基準模型性能——在吞吐量和FLOPs的計算速度方面更快。我們的方法是通用的,可以應用于任何上下文的ViT:上圖顯示,我們的跳過注意力(SKIPAT)的新型參數函數在各種任務、數據集和模型大小上都能實現與基準transformer相比更優的精度與效率。
綜上所述,我們的貢獻如下所示:
我們提出了一種新型的插件模塊,可以放在任何ViT架構中,以減少昂貴的O(n^2)自注意力計算復雜度。
我們在ImageNet、Pascal-VOC2012、SIDD、DAVIS和ADE20K數據集上實現了在吞吐量指標上的最SOTA性能,并獲得了同等或更高的準確度。
我們的方法在沒有下游準確度損失的情況下,自監督預訓練時間能減少26%,并且在移動設備上展示了優越的延遲,這都證明了我們方法的普適性。
我們分析了性能提升的來源,并對我們的方法進行了大量的實驗分析,為提供可用于權衡準確度和吞吐量的模型系列提供了支持。
方法

SKIPAT framework.
引言
Vision Transformer
設x ∈ R^(h×w×c) 為一張輸入圖像,其中h × w是空間分辨率,c是通道數。首先將圖像分成n = hw/p^2個不重疊的塊,其中p × p是塊大小。使用線性層將每個塊投影到一個embedding zi ∈ R^d 中,從而得到分塊的圖像:

Transformer Layer
Transformer的每一層由多頭自注意力(MSA)塊和多層感知機(MLP)塊組成。在MSA塊中,Zl?1 ∈ R^(n×d),首先被投影到三個可學習embeddings {Q, K, V } ∈ R^(n×d)中。注意力矩陣A的計算公式如下:
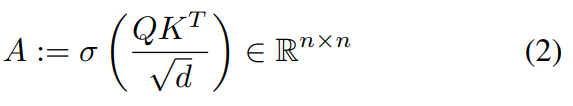
MSA中的“多頭”是指考慮h個注意力頭,其中每個頭是一個n × d/h 矩陣的序列。使用線性層將注意頭重新投影回n × d,并與值矩陣結合,公式如下所示:
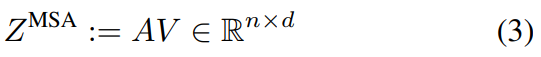
然后,將MSA塊的輸出表示輸入到MLP塊,該塊包括兩個由GeLU激活分隔的線性層。在給定層l處,表示通過transformer塊的計算流程如下:

MSA和MLP塊都具有帶層正則化(LN)的殘差連接。雖然transformer的每一層中的MSA塊均是學習互不依賴的表示,但在下一小節中,我們將展示這些跨層間存在高度相關性。
啟發: 層相關性分析
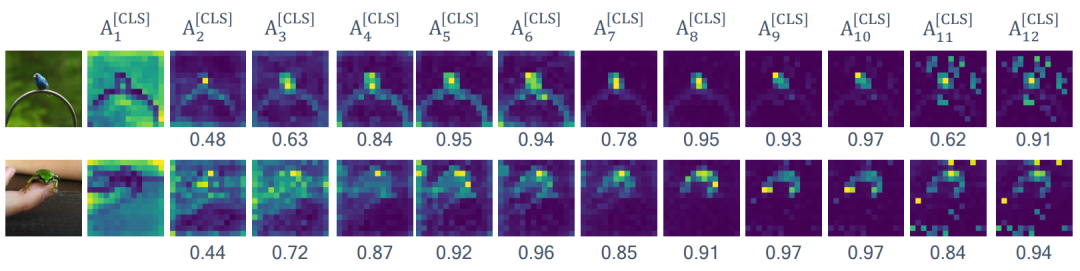
Attention correlation.
ViT中的MSA塊將每個塊與每個其他塊的相似性編碼為n × n注意力矩陣。這個運算符具有O(n^2)復雜度(公式2)的計算成本。隨著ViT的擴展,即隨著n的增加,計算復雜度呈二次增長,使得這個操作成為性能瓶頸。最近的NLP工作表明,SoTA語言模型中相鄰層之間的自注意力具有非常高的相關性。這引發了一個問題 -在視覺transformer是否真的需要每一層都計算自注意力?

CKA analysis of A^[CLS] and Z^MSA across different layers of pretrained ViT-T/16.
為了回答這個問題,我們分析了ViT不同層之間自注意力圖的相關性。如本節圖1所示,來自類別token的自注意力圖A^[CLS]在中間層特別具有高度相關性。A^[CLS]l?1和A^[CLS]l 之間的余弦相似度可以高達0.97。其他token embeddings 也表現出類似的行為。我們通過計算每對i,j∈L的A^[CLS]i和A^[CLS]j之間的Centered Kernel Alignment(CKA)來定量分析ImageNet-1K驗證集的所有樣本之間的相關性。CKA度量網絡中間層獲得的表示之間的相似性,其中CKA的值越高則表示它們之間的相關性越高。從本節圖2中,我們發現ViT-T在A^[CLS]之間具有高度性,特別是第三層到第十層。
Feature correlation
在ViT中,高相關性不僅局限于A^[CLS],MSA塊的表示Z^MSA也在整個模型中顯示出高度相關性。為了分析這些表示之間的相似性,我們計算每對i,j∈L的Z^MSAi和Z^MSAj之間的CKA。我們從從本節圖2中觀察到,Z^MSA在模型的相鄰層之間也具有很高的相似性,特別是在較早的層,即從第2層到第8層。
利用 Skipping Attention 提升效率
基于我們對transformer中MSA不同塊之間具有高度相似性的觀察,我們建議利用注意力矩陣和MSA塊的表示之間的相關性來提高視覺transformer的效率。與在每層單獨計算MSA操作(公式3)相反,我們探索了一種利用不同層之間依賴關系的簡單且有效的策略。
我們建議通過重用其相鄰層的特征表示來跳過transformer的一個或多個層中的MSA計算。我們將此操作稱為Skip Attention(SKIPAT)。由于跳過整個MSA塊的計算和內存效益大于僅跳過自注意力操作 O(n^2d+nd^2) vs. O(n^2d),因此在本文中我們主要關注前者。我們引入了一個參數函數,而不是直接重用特征,換句話說,就是將來源MSA塊的特征復制到一個或多個相鄰MSA塊。參數函數確保直接重用特征不會影響這些MSA塊中的平移不變性和等價性,并充當強大的正則化器以提高模型泛化性。
SKIPAT parametric function
設 Φ:R^(n×d) → R^(n×d)表示將l?1層的MSA塊映射到l層的參數函數,作為Z?^MSA l:=Φ(Z^MSA l?1)。在這里,Z?^MSA l是Z^MSA l的近似值。參數函數可以是簡單的單位函數,其中Z^MSA l?1能被直接重用。我們使用Z^MSA l?1作為l處的MLP塊的輸入,而不是在l處計算MSA操作。當使用單位函數時,由于l處沒有MSA操作,因此在注意力矩陣中的token間關系不再被編碼,這會影響表示學習。為了減輕這一點,我們引入了SKIPAT參數函數,用于對token之間的局部關系進行編碼。SKIPAT參數函數由兩個線性層和中間的深度卷積(DwC)組成,計算公式如下所示:

SKIPAT framework
SKIPAT 是一種可以被納入任何 transformer 架構的框架,我們通過大量實驗對比結果充分地證明了這一點。根據架構的不同,可以在 transformer 的一層或多層中跳過 MSA 操作。在 ViT 中,我們觀察到來自 MSA 塊(Z^MSA )的表示在第 2 層到第 7 層之間有很高的相關性,所以我們在這些層中使用 SKIPAT 參數函數。這意味著我們將 Z^MSA2 作為輸入傳遞給 SKIPAT 參數函數,并在 3-8 層中跳過 MSA 操作。相反,來自 SKIPAT 參數函數輸出的特征被用作 MLP 塊的輸入。表示的計算流現在被修改為:
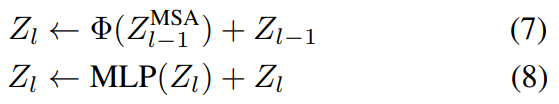
由于 MSA 和 MLP 塊中存在殘留連接,第 3 層到第 8 層的 MLP 塊需要獨立地學習表示,不能從計算圖中刪除。值得注意的是,使用 SKIPAT 后 ViT 的總層數不變,但 MSA 塊的數量減少了。
Complexity: MSA vs. SKIPAT
自注意力操作包括三個步驟。首先,將token embeddings 投射到query、key和value embeddings,其次,計算注意力矩陣 A,它是 Q 和 K 的點積,最后,計算輸出表示作為 A 和 V 的點積。這導致了計算復雜度為 O(4nd^2 + n^2d)。由于 d ? n,所以 MSA 塊的復雜度可以降低到 O(n^2d)。
SKIPAT 參數函數由兩個線性層和一個深度卷積操作組成,計算復雜度為 O(2nd^2 + r^2nd),其中 r × r 是 DwC 操作的內核大小。由于 r^2 ? d,所以 SKIPAT 的整體復雜度可以降低到 O(nd^2)。因此,當 n 隨著 transformer 的擴大而增加時,SKIPAT 的 FLOPs值 比 MSA 塊更少,即 O(nd^2) < O(n^2d)。
實驗

上圖展示的是分割mask的可視化效果:第一行和第二行分別是原始Vit-S模型和Vit-S + SKIPAT模型。顯而易見,Vit-S + SKIPAT模型對圖像中前景和背景的區分度顯著高于原始Vit-S模型。
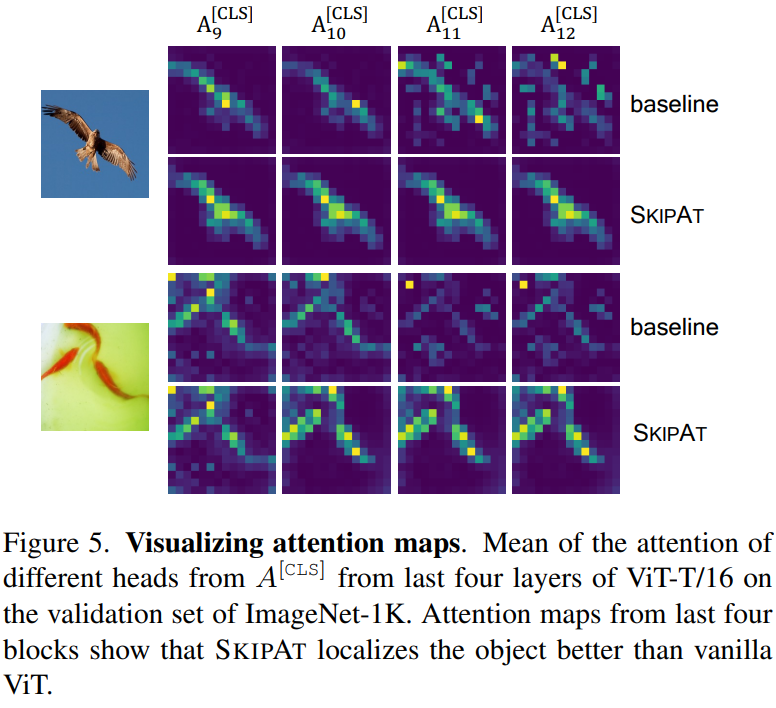
上圖展示的是注意力圖的可視化效果:對比原始Vit-S模型(baseline),Vit-S + SKIPAT模型對目標的定位能力有明顯提升。
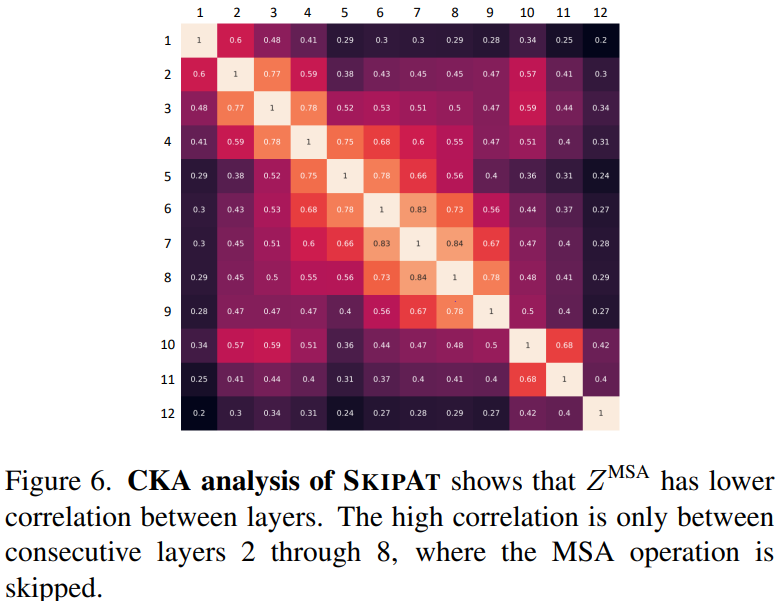
上圖展示的是特征圖和Z^MSA的相關性:從中可以清晰地觀察到在大多數不同層之間Z^MSA僅有較低的相關性。
圖象分類
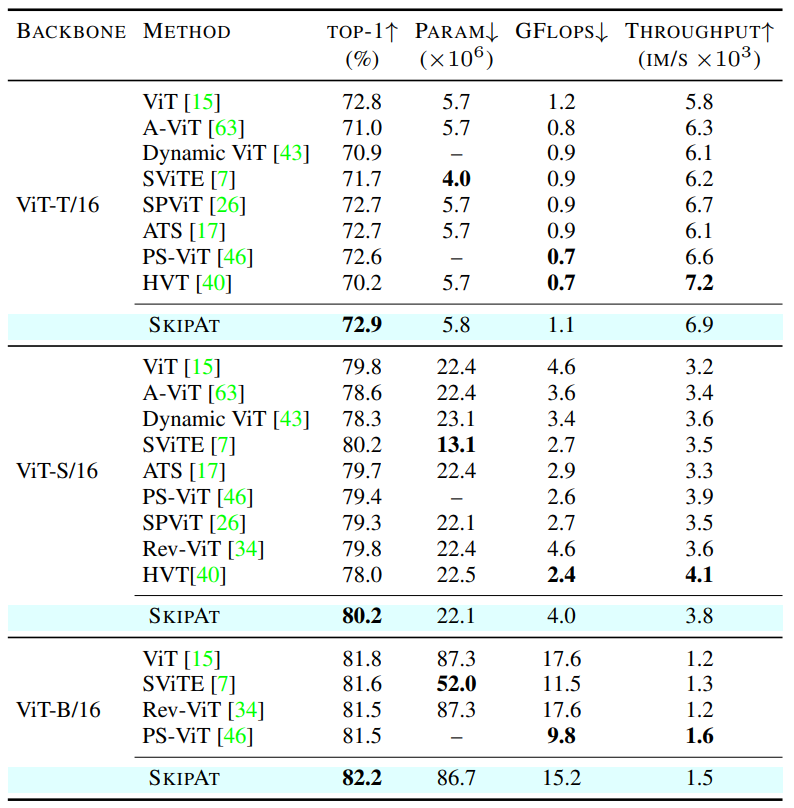
Image classification on ImageNet-1K.
自監督
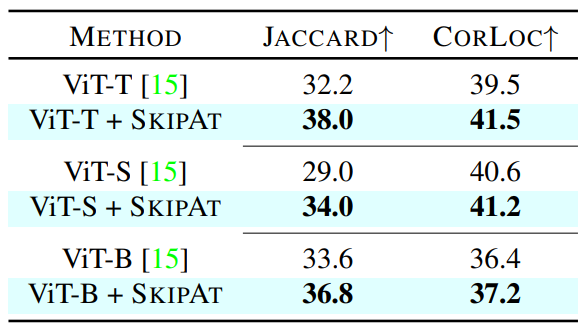
Unsupervised Segmentation and Object Localization on the validation set of Pascal VOC2012.
推理性能
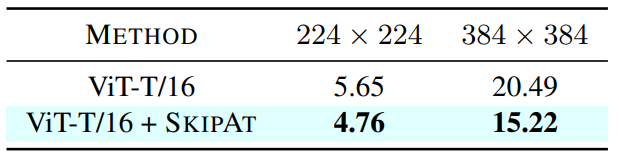
On-device latency (in msec) of vanilla ViT vs. SKIPAT.
語義分割
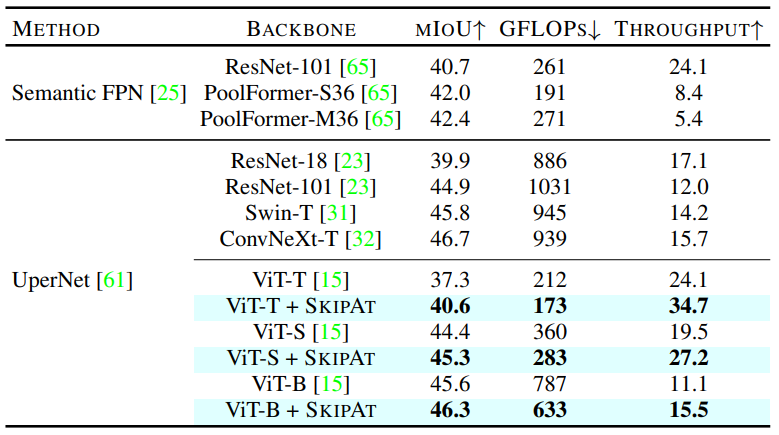
Semantic Segmentation results on ADE20K.
圖像去噪
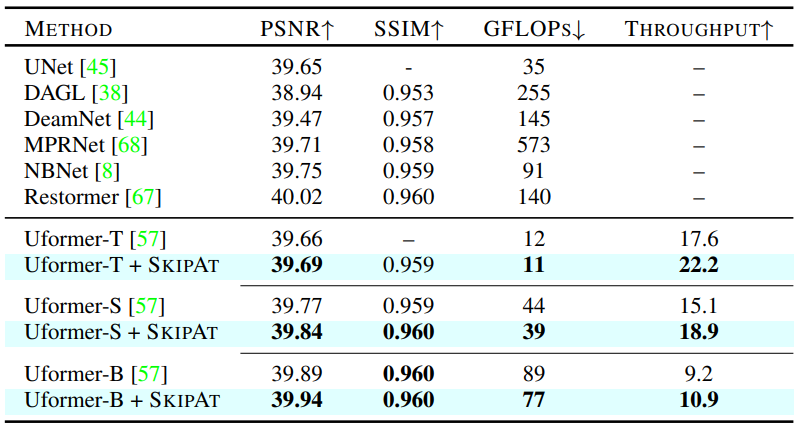
Image denoising on SIDD dataset using PSNR andSSIM as the evaluation metrics in the RGB space.
總結
我們提出了一種可以在任何 ViT 架構中即插即用的模塊 SKIPAT,用于減少昂貴的自注意力計算。SKIPAT 利用 MSA 塊之間的依賴性,并通過重用以前 MSA 塊的注意力表示來繞過注意力計算。此外,我們引入了一個簡單且輕量的參數函數,它不會影響 MSA 中編碼的歸納偏見。SKIPAT 函數能夠捕獲跨token之間的關系,在吞吐量和 FLOPs 指標上優于基線模型,同時我們在7 種不同的任務中充分地表現出SKIPAT的有效性。
審核編輯 :李倩
-
編碼
+關注
關注
6文章
969瀏覽量
55810 -
Transformer
+關注
關注
0文章
151瀏覽量
6528 -
自然語言處理
+關注
關注
1文章
628瀏覽量
14172
原文標題:即插即用!Skip-Attention:一種顯著降低Transformer計算量的輕量化方法
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
大模型推理顯存和計算量估計方法研究
輕量化5G網關和5gredcap網關有什么區別

潤和軟件破局昇騰310B輕量化難題

基于 HT for Web 的輕量化 3D 數字孿生數據中心解決方案
基于雙向塊浮點量化的大語言模型高效加速器設計
知行科技將與智駕大陸攜手打造輕量化城區領航產品
引領輕量化趨勢| 法法易輕量化充電槍通過2023版標準強檢測試

守護公路安全! 中海達推出輕量化監測簡易感知方案
一種信息引導的量化后LLM微調新算法IR-QLoRA

中海達推出輕量化監測簡易感知解決方案
自動駕駛中一直說的BEV+Transformer到底是個啥?

5G RedCap:輕量化5G技術引領物聯網新未來

5G輕量化網關是什么

輕量化IP制作與傳輸的變革之路-千視Judy專訪






 工商網監
工商網監

評論