

最近用文本來引導(dǎo)圖像編輯取得了非常大的進(jìn)展以及關(guān)注度,特別是基于去噪擴(kuò)散模型如 StableDiffusion 或者 DALLE 等。但是基于 GAN 的文本 - 圖像編輯依舊有一些問題等待解決,例如經(jīng)典的 StyleCILP 中針對(duì)每一個(gè)文本必須要訓(xùn)練一個(gè)模型,這種單文本對(duì)單模型的方式在實(shí)際應(yīng)用中是不方便的。
本文我們提出 FFCLIP 并解決了這個(gè)問題,針對(duì)靈活的不同文本輸入,F(xiàn)FCLIP 只需要一個(gè)模型就能夠?qū)D片進(jìn)行相應(yīng)的編輯,無需針對(duì)每個(gè)文本重新訓(xùn)練模型,并且在多個(gè)數(shù)據(jù)集上都取得了非常不錯(cuò)的效果。
論文簡(jiǎn)要概述
利用文本對(duì)圖像進(jìn)行編輯的相關(guān)研究非常火熱,最近許多研究都基于去噪擴(kuò)散模型來提升效果而少有學(xué)者繼續(xù)關(guān)注 GAN 的相關(guān)研究。本文基于經(jīng)典的 StyleGAN 和 CLIP 并提出語義調(diào)制模塊,從而對(duì)不同的文本僅需要單個(gè)模型就可以進(jìn)行文本 - 圖像編輯。
本文首先利用已有的編碼器將需要編輯的圖像轉(zhuǎn)換到 StyleGAN 的 語義空間中的潛在編碼 w,再通過提出的語義調(diào)制模塊對(duì)該隱編碼進(jìn)行自適應(yīng)的調(diào)制。該語義調(diào)制模塊包括語義對(duì)齊和語義注入模塊,首先通過注意力機(jī)制對(duì)齊文本編碼和 GAN 的隱編碼之間的語義,再將文本信息注入到對(duì)齊后的隱編碼中,從而保證該隱編碼擁有文本信息從而達(dá)到利用文本編輯圖像能力。 不同于經(jīng)典的 StyleCLIP 模型,我們的模型無需對(duì)每個(gè)文本單獨(dú)訓(xùn)練一個(gè)模型,一個(gè)模型就可以響應(yīng)多個(gè)文本從而對(duì)圖像做有效的編輯,所以我們的模型成為 FFCLIP-Free Form Text-Driven Image Manipulation。同時(shí)我們的模型在經(jīng)典的教堂,人臉以及汽車數(shù)據(jù)集上都取得了非常不錯(cuò)的效果。

論文鏈接:
https://arxiv.org/pdf/2210.07883.pdf
代碼鏈接:
https://github.com/KumapowerLIU/FFCLIP
背景和啟示最近,描述用戶意圖的自由文本提示已被用于編輯 StyleGAN 潛在空間以進(jìn)行圖像編輯操作 [1、2]。一句話(例如,‘Blue’)或短語(例如,‘Man aged 10’)作為輸入,這些方法通過調(diào)制 StyleGAN 潛在空間中的潛在編碼來相應(yīng)地編輯所描述的圖像屬性。 精確的文本 - 圖像編輯依賴于 StyleGAN 的視覺語義空間與 CLIP 的文本語義空間之間的精確潛在映射。比如當(dāng)文本提示是 “驚喜”,我們首先在視覺語義空間中識(shí)別其相關(guān)的語義子空間(即 “表情”,因?yàn)轶@喜屬于表情這個(gè)屬性)。找到與文本相對(duì)應(yīng)的語義子空間后,文本會(huì)告訴我們隱編碼的變化方向,從讓隱編碼從當(dāng)前的表情變化到驚喜的表情。 TediGAN [1] 和 StyleCLIP [2] 等開創(chuàng)性研究憑經(jīng)驗(yàn)預(yù)先定義了哪個(gè)潛在視覺子空間對(duì)應(yīng)于目標(biāo)文本提示嵌入(即 TediGAN 中的特定屬性選擇和 StyleCLIP 中的分組映射)。這種經(jīng)驗(yàn)識(shí)別限制了給定一個(gè)文本提示,他們必須訓(xùn)練相應(yīng)的編輯模型。 不同的文本提示需要不同的模型來調(diào)制 StyleGAN 的潛在視覺子空間中的潛在代碼。雖然 StyleCLIP 中的全局方向方法沒有采用這樣的過程,但參數(shù)調(diào)整和編輯方向是手動(dòng)預(yù)定義的。為此,我們有理由來探索如何通過顯性的文本自動(dòng)的找到隱性的視覺語義子空間,從而達(dá)到單個(gè)模型就可以應(yīng)對(duì)多個(gè)文本。 在這篇論文中,我們提出了 FFCLIP-Free Form CLIP,它可以針對(duì)不同的文本自動(dòng)找到相對(duì)應(yīng)視覺子空間。FFCLIP 由幾個(gè)語義調(diào)制模塊組成,這些語義調(diào)制模塊把 StyleGAN 潛在空間 中的潛在編碼 和文本編碼 e 作為輸入。 語義調(diào)制模塊由一個(gè)語義對(duì)齊模塊和一個(gè)語義注入模塊組成。語義對(duì)齊模塊將文本編碼 e 作為 query,將潛在編碼 w 作為 key 和 Value。然后我們分別在 position 和 channel 維度上計(jì)算交叉注意力,從而得到兩個(gè)注意力圖。 接著我們使用線性變換將當(dāng)前的視覺空間轉(zhuǎn)換到與文本對(duì)應(yīng)的子空間,其中線性變換參數(shù)(即平移和縮放參數(shù))是基于這兩個(gè)注意力圖計(jì)算的。通過這種對(duì)齊方式,我們可以自動(dòng)的為每個(gè)文本找到相應(yīng)的視覺子空間。最后,語義注入模塊 [3] 通過之后的另一個(gè)線性變換修改子空間中的潛在代碼。 從 FFCLIP 的角度來看,[1, 2] 中子空間經(jīng)驗(yàn)選擇是我們?cè)谡Z義對(duì)齊模塊中線性變換的一種特殊形式。他們的組選擇操作類似于我們的縮放參數(shù)的二進(jìn)制值,以指示 w 的每個(gè)位置維度的用法。另一方面,我們觀察到 空間的語義仍然存在糾纏的現(xiàn)象,經(jīng)驗(yàn)設(shè)計(jì)無法找到 StyleGAN 的潛在空間和 CLIP 的文本語義空間之間的精確映射。 相反,我們的語義對(duì)齊模塊中的縮放參數(shù)自適應(yīng)地修改潛在代碼 w 以映射不同的文本提示嵌入。然后通過我們的平移參數(shù)進(jìn)一步改進(jìn)對(duì)齊方式。我們?cè)诨鶞?zhǔn)數(shù)據(jù)集上評(píng)估我們的方法,并將 FFCLIP 與最先進(jìn)的方法進(jìn)行比較。結(jié)果表明,F(xiàn)FCLIP 在傳達(dá)用戶意圖的同時(shí)能夠生成更加合理的內(nèi)容。
FFCLIP
圖 1 所展示的就是我們的整體框架。FFCLIP 首先通過預(yù)訓(xùn)練好的 GAN inversion 編碼器和文本編碼器得到圖像和文本的潛在編碼,其中圖像的潛在編碼則是之前提到的 StyleGAN 視覺語義空間 中的 w,而文本編碼則是 。我們和 StyleCLIP 一樣采用 e4e GAN inversion 編碼器 [4] 和 CLIP 中的文本編碼器來分別得到相應(yīng)的潛在編碼。接著我們將 和 w 作為調(diào)制模塊的輸入并輸出得到 w 的偏移量 ,最后將 與原始的 w 相加并放入預(yù)訓(xùn)練好的 StyleGAN 中得到相應(yīng)的結(jié)果。
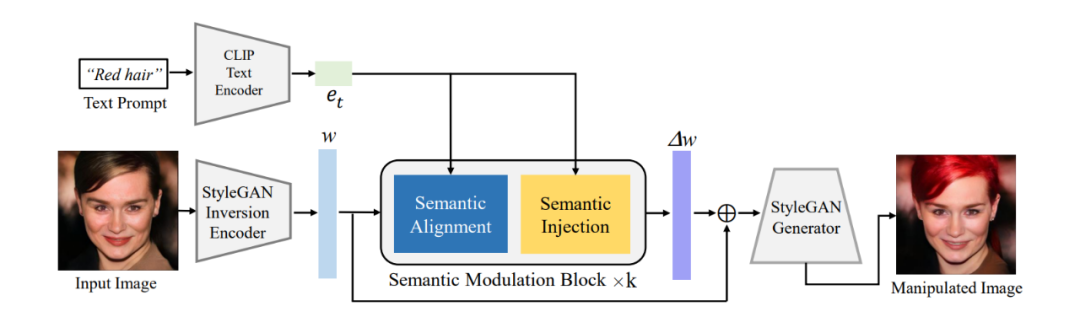
▲圖1. 整體框架圖
下圖二就是我們的語義調(diào)制模塊。在語義對(duì)齊模塊中(Semantic Alignment),我們可以清晰地看到我們將 設(shè)置為 Key 和 Value 并將 設(shè)置為 Query 來計(jì)算兩個(gè)注意力圖,這兩個(gè)注意力圖的大小分別是 18×1 以及 512×512。接著我們將 18×1 的注意力圖當(dāng)作線性變換中縮放系數(shù) S,我們計(jì)算該注意力圖的過程如下:
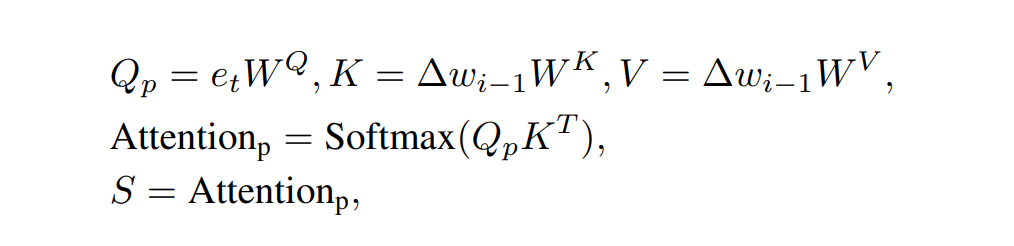
同時(shí)我們將 512×512 的注意力圖與 Value 相乘以后再經(jīng)過 Pooling 操作得到顯性變換中的平移系數(shù) T。我們計(jì)算該注意力圖的過程如下:
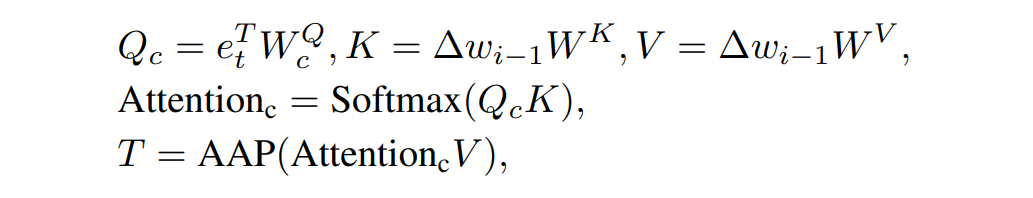
擁有了平移和縮放系數(shù)后,我們就可以通過線性變換為當(dāng)前文本找到相對(duì)應(yīng)的視覺子空間,計(jì)算步驟如下:
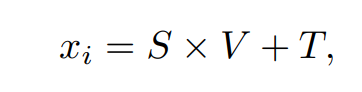
其中 是我們第 i 個(gè)語義調(diào)制模塊的輸出結(jié)果。由于 的大小是 18×512,所以 18×1 和 512×512 的注意力圖分別是在 的 position 和 channel 兩個(gè)維度上進(jìn)行注意力圖的計(jì)算,這個(gè)操作類似于 Dual Attention [5]。
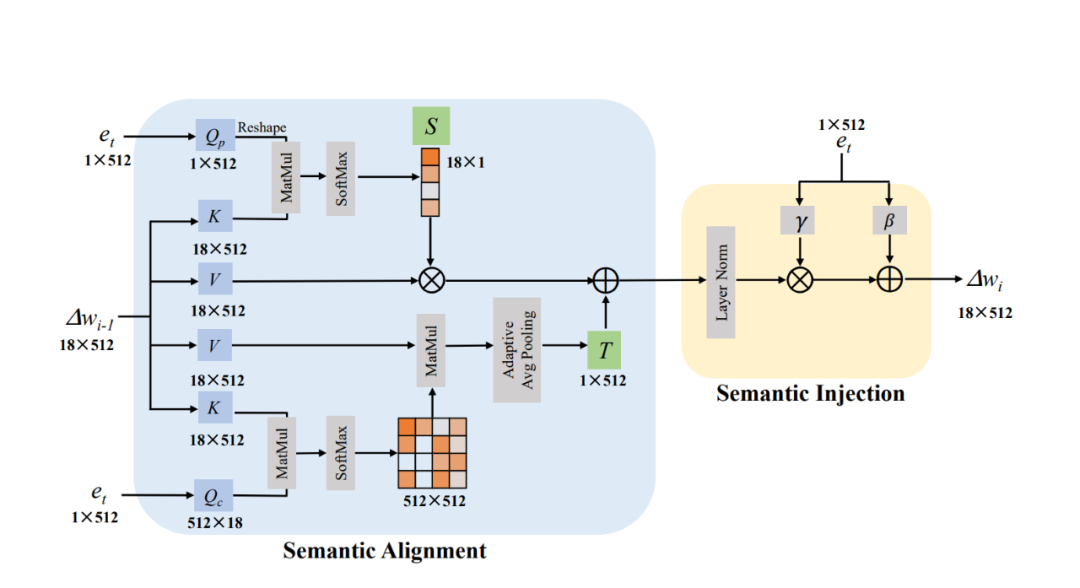
▲圖2. 語義調(diào)制模塊 我們通過以上的操作可以得到與文本對(duì)應(yīng)的視覺子空間,緊接著我們采用類似 AdaIN 的方式,將文本信息注入到這個(gè)空間中,從而得到最后的結(jié)果,我們稱這個(gè)操作為語義注入模塊(Semantic Injection)。整個(gè)模塊的實(shí)現(xiàn)步驟如下:
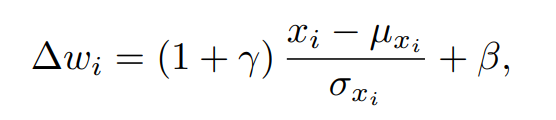
最終我們的 FFCLIP 中一共堆疊了 4 個(gè)語義調(diào)制模塊,并最終得到最后的偏移量 。
實(shí)驗(yàn)結(jié)果


▲圖3. 視覺對(duì)比圖
如圖 3 所示,我們與 StyleCLIP [1],TediGAN [2] 以及 HairCLIP [3] 進(jìn)行了視覺上的對(duì)比:可以看到 FFCLIP 能夠更好的反應(yīng)文本的語義,并且生成更加真實(shí)的編輯圖像。同時(shí)相對(duì)應(yīng)的數(shù)值對(duì)比結(jié)果如下表所示,我們的方法無論是在客觀數(shù)值還是在主觀數(shù)值上都能取得最好的效果。
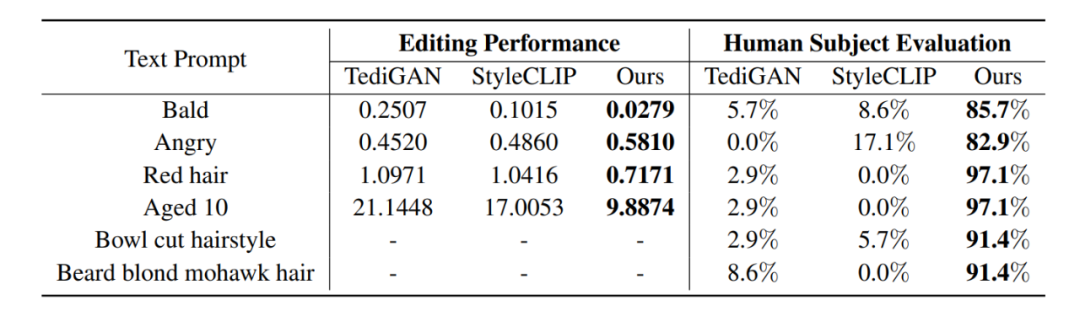
▲表1.數(shù)值對(duì)比
同時(shí)我們的方法還展現(xiàn)出了非好的魯棒性,F(xiàn)FCLIP 在訓(xùn)練中并未見過詞的組合而是用單個(gè)的單詞進(jìn)行訓(xùn)練,但是在測(cè)試中能夠很好的針對(duì)詞組的語義對(duì)圖像進(jìn)行編輯,視覺效果如圖 4 所示。

▲圖4. 詞組編輯
更多的實(shí)驗(yàn)結(jié)果和消融實(shí)驗(yàn)請(qǐng)看原文。
總結(jié)我們?cè)诒疚闹刑岢隽?FFCLIP,一種可以針對(duì)不同文本但只需要單個(gè)模型就能進(jìn)行有效圖像編輯的新方法。本文動(dòng)機(jī)是現(xiàn)有方法是根據(jù)已有的經(jīng)驗(yàn)來匹配當(dāng)前文本和 GAN 的語義子空間,因此一個(gè)編輯模型只能處理一個(gè)文本提示。我們通過對(duì)齊和注入的語義調(diào)制來改進(jìn)潛在映射。它有利于一個(gè)編輯模型來處理多個(gè)文本提示。多個(gè)數(shù)據(jù)集的實(shí)驗(yàn)表明我們的 FFCLIP 有效地產(chǎn)生語義相關(guān)和視覺逼真的結(jié)果。
審核編輯 :李倩
-
圖像
+關(guān)注
關(guān)注
2文章
1092瀏覽量
41009 -
模型
+關(guān)注
關(guān)注
1文章
3483瀏覽量
49966 -
文本
+關(guān)注
關(guān)注
0文章
119瀏覽量
17358
原文標(biāo)題:NIPS 2022 | 文本圖片編輯新范式:?jiǎn)蝹€(gè)模型實(shí)現(xiàn)多文本引導(dǎo)圖像編輯
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
把樹莓派打造成識(shí)別文本的“神器”!


阿里云通義開源長文本新模型Qwen2.5-1M
圖紙模板中的文本變量
如何在文本字段中使用上標(biāo)、下標(biāo)及變量

字節(jié)發(fā)布SeedEdit圖像編輯模型
利用OpenVINO部署Qwen2多模態(tài)模型
vim編輯器命令模式使用方法
vim編輯器如何使用
NVIDIA文本嵌入模型NV-Embed的精度基準(zhǔn)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論