 S公司的微服務“失敗”之旅
S公司的微服務“失敗”之旅
背景介紹
S公司是一家數據服務公司,有 20 000 多名客戶使用公司的軟件,公司使用 API 收集和清理客戶的數據。S 公司提供的產品如下圖所示。


微服務是當今主流的架構模式之一。S 公司的系統進行了一次微服務改造,并取得了不錯的效果。
重構后的規模:400 private repos;70 different services(workers)。
取得的收益:
visibility(可見性)。在微服務架構中,非常方便對每個服務進行監控(sysdig、htop、iftop 等)。
微服務大大降低了配置和構建部署成本。
消除了在現有服務中附加不同功能的誘惑。
產生了很多對外依賴很少的服務:僅僅需要從隊列里讀取和處理數據,然后發送結果即可。非常適合小團隊協同工作。
定位問題變得容易。可以對每一個 microworker 進行 Datadog 式的監控,如下圖所示
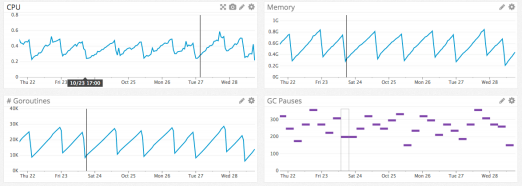
比如,類似于內存泄漏的問題,可以很容易將問題范圍縮小到 50~100 行代碼內。
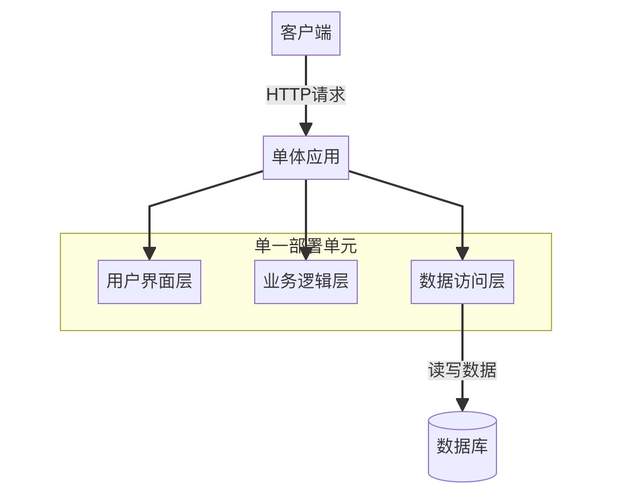
簡單地講,微服務是一種面向服務的軟件體系結構,其中服務端的應用程序是通過組合許多單一用途、低占用空間的網絡服務而成的。其優點是改進的模塊化減少了測試負擔,可以更好地進行功能組合,環境隔離和開發團隊具備自主權。經常與之拿來對比的是單體架構,在單體架構中,大量的功能存在于單個服務中,作為單個單元進行測試、部署和擴展。
另外,操作復雜度和負載都很高的產品一般都會選擇微服務架構,它使基礎結構更加靈活、可擴展性強,并且更易于監控。
但不幸的事情發生了,當重構完成兩年以后,團隊沒有更快地交付,而是陷入了“爆炸性”的復雜性中,架構的優點變成了負擔。隨著速度的下降,失敗率激增,團隊也變得不堪重負。
系統處理流程概述
S公司的客戶數據基礎設施每秒可接收數十萬個事件,并將它們轉發給合作伙伴的 API,即服務端 destination。目前,有超過一百種類型的 destination,如 Google Analytics, Optimizely,或自定義 Webhook。
幾年前,架構相對簡單,一個API 即可接收事件并將其轉發到分布式消息隊列。事件是由 Web 或移動應用程序生成的 JSON 對象,其中包含有關用戶及其操作的信息。
一旦請求失敗,有時會嘗試在稍后的時間再次發送該事件。有些失敗可以安全重試,有些則不行。可重試錯誤是指那些 destination 不做任何更改就可以接受的錯誤,如 HTTP 500、速率限制和超時。不可重試錯誤是指可以確信 destination 永遠不會接受的請求,如具有無效憑證或缺少必需字段的請求。
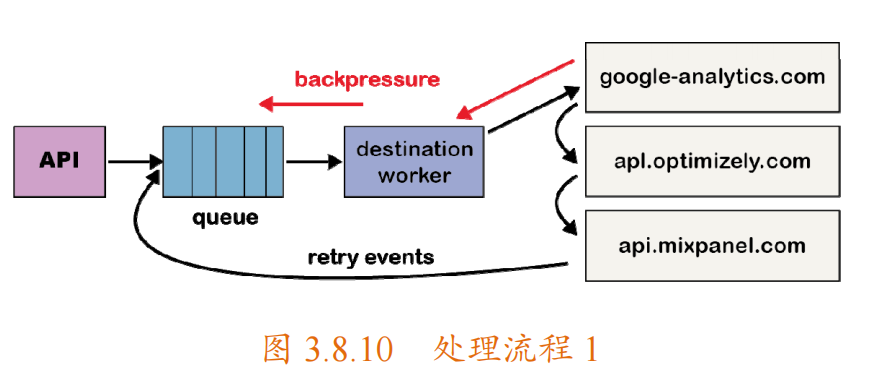
此時,單個隊列既包含最新的事件,也包含跨越所有destination 的可能有多次重試的事件,這會導致“隊頭阻塞”。也就是說,在這種特殊情況下,如果一個 destination 變慢或下降,則重試將會導致隊列擁擠,從而導致所有 destination 的延遲。
假設destinationX 遇到了一個臨時問題,每個請求都由于超時而出錯。現在,這不僅會創建大量尚未到達 destinationX 的積壓請求,而且還會將每個失敗事件放回隊列中進行重試,如下圖所示。雖然系統將自動伸縮以響應增加的負載,但隊列深度的突然增加將超過系統的伸縮能力,從而導致最新事件的延遲。
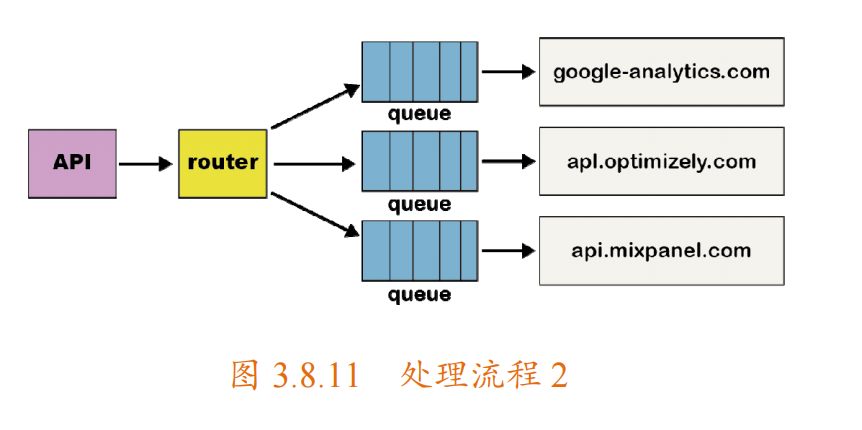
為了解決“隊頭阻塞”問題,該團隊為每個 destination 都創建了單獨的服務和隊列。這個新的體系結構包括一個額外的路由器進程,該進程接收入站事件并將事件的副本分發到每個選定的 destination 中,如下圖所示。現在,如果一個 destination 出現問題,則只有它的隊列會阻塞,其他 destination 不會受到影響。這種微服務風格的體系結構將 destination 彼此隔離,這在 destination 經常發生問題時,至關重要。
產生的問題
共享庫多版本問題。隨后,系統又增加了 50 多個新的 destination,這就意味著有 50個新的 repo。為了減輕開發和維護這些代碼庫的負擔,團隊創建了共享庫,來處理公共轉換和功能(如 HTTP 請求處理)。然而,一個新的問題出現了。對這些共享庫的測試和部署更改會影響所有的 destination,此時必須測試和部署幾十個服務。在時間緊迫的情況下,工程師只會在單個目標的代碼庫中包含這些庫的更新版本。這樣一來,隨著時間的推移,這些共享庫的版本開始在不同的目標代碼庫中出現不同的分支版本,原本擁有的在每個目標代碼庫之間減少自定義的優勢開始不復存在。最終,它們都使用了這些共享庫的不同版本。本可以構建一些工具來自動進行更改,但此時,不僅開發人員的工作效率受到了影響,還遇到微服務架構的其他問題。
負載模式問題。每個服務都有不同的負載模式,其中一些服務每天處理少量事件,而另一些服務每秒處理數千個事件。對于處理少量事件的 destination,當出現意外的負載峰值時,操作員將不得不手動擴展服務,以滿足需求。
伸縮調優問題。雖然確實實現了自動伸縮,但每個服務都有不同的 CPU 和內存資源組合,使得自動伸縮配置的調優更像是藝術而不是科學。destination 的數量繼續快速增加,團隊平均每個月增加三個 destination,這意味著有了更多的 repo、隊列和服務。
管理開銷。當服務個數超過 140 個時,對團隊來說管理所有服務是一筆巨大的開銷。團隊每天睡不好覺,最常見的場景就是線上工程師處理負載峰值。
退回到單體
最終,團隊決定拋棄這些微服務和repo,并重新將服務并到一起。然而,退回到單體服務非常困難。如果所有 destination 都有一個單獨的隊列,那么所有工程師都必須檢查每個隊列的工作,這會給 destination 服務增加一層復雜性。為了解決這個問題,系統新增了一種“離心機(Centrifuge)”組件,并將所有 destination 進行了合并,如下圖所示。
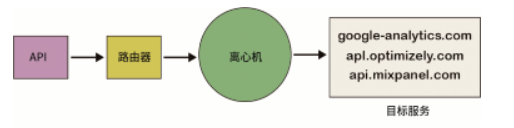
同時,還需要將所有repo 進行合并。一旦所有 destination 的代碼存在于一個 repo 中,它們就可以合并為一個服務。這樣,開發人員的生產率大大提高了,不再需要部署 140 多個服務來改變一個共享庫,一個工程師在幾分鐘內就可以部署這項服務,這一變化也有利于運維。由于所有 destination 都位于一個服務中,因此很好地混合了 CPU 和內存密集型 destination,這使得利用擴展服務來滿足需求變得非常容易。由于大型工作池可以吸收負載峰值,因此團隊不必再為處理少量負載的 destination 進行分頁。
一些犧牲
雖然已取得了巨大的改進,然而其中也有些“犧牲”。
故障隔離困難。由于所有東西都在一個單體中運行,如果一個 destination 中引入了導致服務崩潰的 bug,那么所有 destination 的服務都會崩潰。雖然已經有全面的自動化測試,但是測試無法完全保障。后續演進的方向是設計一種更健壯的方法,以防止單個 destination導致整個服務癱瘓,同時仍將所有 destination 保持在一個單體中。
緩存(內存中)效率變低。以前,由于每個 destination 都有一個服務,低流量 destination只有少數進程,這意味著它們控制平面數據的內存緩存將保持熱度。現在,由于緩存分散在3000 多個進程中,因此命中率大大降低。最后,考慮到實際的運營收益,接受了效率的損失。
更新一個依賴項的版本可能會破壞多個destination。雖然解決了之前多版本依賴的問題,但如果想使用庫的最新版本,則必須更新其他 destination。目前,通過全面的自動化測試套件,可以快速看到新老依賴版本的不同。
總結
引入微服務架構,并通過將destination 彼此隔離解決了管道中的性能問題。然而,當需要批量更新時,由于缺乏適當的工具來測試和部署微服務,因此結果反而使開發人員的生產力迅速下降。
在進行架構選擇時,并不存在絕對的好壞,是一個權衡的過程,需要從多個維度考慮。
新的架構是否能帶來新的復雜性,帶來的復雜性是否能被充分評估,以及如何應對,如上文提到的“共享多版本的問題”。
新架構下系統的運維成本是否增加,如果增加能否接受,如上文提到的“負載模式問題”。
在“享受”新架構帶來的好處的同時,能否真正掌控新架構,如上文提到的“伸縮調優問題”。
新的架構是否帶來管理開銷,成本能否接受,如上文提到的“管理開銷”問題。
架構設計的誤區
盲目追求模式和原則的滿足。并不是說模式和原則不重要,但它們不應該成為架構設計追求的唯一目標。盲目追求不必要的模式和原則的滿足,往往會給系統帶來不必要的復雜性,使其難以理解。
追趕潮流。新的架構形態層出不窮,令人眼花繚亂,學習到一種新的、“炫酷”的架構設計很容易有直接拿來應用的沖動。這樣做的后果往往是會與實際解決的問題脫節,為系統帶來不必要的負擔,甚至根本沒有解決任何問題。
面面俱到,沒有重點。決定不要什么比要什么更難。你會看到當某些架構設計文檔的模板時,高可用性、擴展性、可測試性……什么都想要,不做取舍。不同系統的側重點不同,這樣做的后果往往是顧此失彼,關鍵問題沒有得到解決。
忽視架構腐化。架構設計在整個軟件生命周期內,都需要守護及持續演進,否則架構及整個系統都難以擺脫逐步惡化,直至消亡或重寫的命運。
審核編輯 :李倩
-
應用程序
+關注
關注
37文章
3267瀏覽量
57686 -
架構設計
+關注
關注
0文章
31瀏覽量
6923 -
微服務
+關注
關注
0文章
137瀏覽量
7341
原文標題:S 公司的微服務“失敗”之旅
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
寶藏級微服務架構工具合集
NVIDIA NIM微服務登陸亞馬遜云科技
k8s微服務架構就是云原生嗎?兩者是什么關系
全新NVIDIA NIM微服務實現突破性進展
SSR與微服務架構的結合應用
微服務架構與容器云的關系與區別
入門級攻略:如何容器化部署微服務?
Proxyless的多活流量和微服務治理
NVIDIA NIM微服務帶來巨大優勢
借助NVIDIA NIM微服務助力可口可樂公司擴展生成式AI內容
采用OpenUSD和NVIDIA NIM微服務創建精準品牌視覺
全新 NVIDIA NeMo Retriever微服務大幅提升LLM的準確性和吞吐量
【算能RADXA微服務器試用體驗】Radxa Fogwise 1684X Mini 規格
Java微服務隨機掉線排查過程簡析






 工商網監
工商網監
評論