 PyTorch的簡單實現
PyTorch的簡單實現
1.必要的 PyTorch 背景
- PyTorch 是一個建立在 Torch 庫之上的 Python 包,旨在加速深度學習應用。
- PyTorch 提供一種類似 NumPy 的抽象方法來表征張量(或多維數組),它可以利用 GPU 來加速訓練。
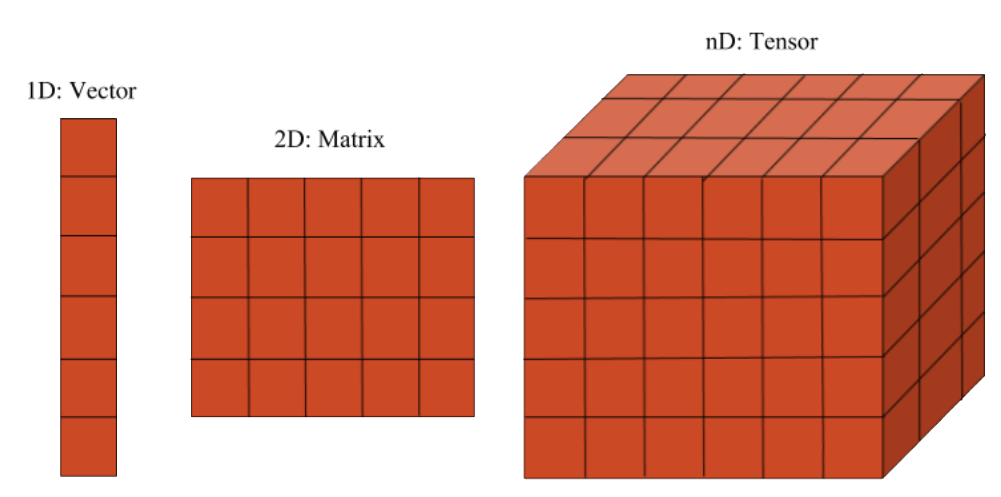
1.1 PyTorch 張量
PyTorch 的關鍵數據結構是張量,即多維數組。其功能與 NumPy 的 ndarray 對象類似,如下我們可以使用 torch.Tensor() 創建張量。如果你需要一個兼容 NumPy 的表征,或者你想從現有的 NumPy 對象中創建一個 PyTorch 張量,那么就很簡單了。
#構建 2-D pytorch tensor
pytorch_tensor = torch.Tensor(10, 20,20)
print("type: ", type(pytorch_tensor), " and size: ", pytorch_tensor.shape )
#將pytorch tensor 轉為 numpy array:
numpy_tensor = pytorch_tensor.numpy()
print("type: ", type(numpy_tensor), " and size: ", numpy_tensor.shape)
#將numpy array 轉為 Pytorch Tensor:
pytorch_tensor = torch.Tensor(numpy_tensor)
print("type: ", type(pytorch_tensor), " and size: ", pytorch_tensor.shape)
1.2 PyTorch vs. NumPy
PyTorch 并不是 NumPy 的簡單替代品,但它實現了很多 NumPy 功能。其中有一個不便之處是其命名規則,有時候它和 NumPy 的命名方法相當不同。我們來舉幾個例子說明其中的區別:
#張量創建
t = torch.rand(2, 4, 3, 5)
a = np.random.rand(2, 4, 3, 5)
#張量分割
a = t.numpy()
pytorch_slice = t[0, 1:3, :, 4] #取t中的元素
numpy_slice = a[0, 1:3, :, 4]
#張量
Maskingt = t - 0.5
pytorch_masked = t[t > 0]
numpy_masked = a[a > 0]
#張量重塑
pytorch_reshape = t.view([6, 5, 4])
numpy_reshape = a.reshape([6, 5, 4])
1.3 PyTorch 變量
- PyTorch 張量的簡單封裝
- 幫助建立計算圖
- Autograd(自動微分庫)的必要部分
- 將關于這些變量的梯度保存在 .grad 中

結構圖:

計算圖和變量:在 PyTorch 中,神經網絡會使用相互連接的變量作為計算圖來表示。PyTorch 允許通過代碼構建計算圖來構建網絡模型;之后 PyTorch 會簡化估計模型權重的流程,例如通過自動計算梯度的方式。
舉例來說,假設我們想構建兩層模型,那么首先要為輸入和輸出創建張量變量:
#將 PyTorch Tensor 包裝進 Variable 對象中:
from torch.autograd import Variable
import torch.nn.functional as F
x = Variable(torch.randn(4, 1), requires_grad=False)
y = Variable(torch.randn(3, 1), requires_grad=False)
#我們把 requires_grad 設置為 True,表明我們想要自動計算梯度,這將用于反向傳播中以優化權重。
#現在我們來定義權重:
w1 = Variable(torch.randn(5, 4), requires_grad=True)
w2 = Variable(torch.randn(3, 5), requires_grad=True)
#訓練模型:
def model_forward(x):
return F.sigmoid(w2 @ F.sigmoid(w1 @ x))
print (w1)
print (w1.data.shape)
print (w1.grad) #gradient梯度
輸出為:
tensor([[-0.8571, 1.3199, -0.5086, 0.7253],
[ 0.5370, 0.2830, -0.2245, -1.0154],
[-0.9083, -0.8636, 0.3927, 0.5870],
[ 0.2461, -0.0415, 1.9505, -0.1105],
[ 0.7191, -0.9653, 0.3059, -1.1343]])
torch.Size([5, 4])
None
1.4 PyTorch 反向傳播
這樣我們有了輸入和目標、模型權重,那么是時候訓練模型了。我們需要三個組件:
- 損失函數:描述我們模型的預測距離目標還有多遠;
- 優化算法:用于更新權重;
- 反向傳播步驟:
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F
x = Variable(torch.randn(4, 1), requires_grad=False)
y = Variable(torch.randn(3, 1), requires_grad=False)
w1 = Variable(torch.randn(5, 4), requires_grad=True)
w2 = Variable(torch.randn(3, 5), requires_grad=True)
def model_forward(x):
return F.sigmoid(w2@ F.sigmoid(w1@ x))
#損失函數:描述我們模型的預測距離目標還有多遠;
criterion = nn.MSELoss()
#優化算法:用于更新權重;
optimizer = optim.SGD([w1, w2], lr=0.001) #隨機最速下降法 (SGD)
#反向傳播步驟:
for epoch in range(10):
loss = criterion(model_forward(x), y)
optimizer.zero_grad() #將先前的梯度清零
loss.backward() #反向傳播
optimizer.step() #應用這些梯度
1.5 PyTorch CUDA 接口
PyTorch 的優勢之一是為張量和 autograd 庫提供 CUDA 接口。使用 CUDA GPU,你不僅可以加速神經網絡訓練和推斷,還可以加速任何映射至 PyTorch 張量的工作負載。
你可以調用 torch.cuda.is_available() 函數,檢查 PyTorch 中是否有可用 CUDA。
cuda_gpu = torch.cuda.is_available()
if (cuda_gpu):
print("Great, you have a GPU!")
else:
print("Life is short -- consider a GPU!")
如果有GPU,.cuda()之后,使用 cuda 加速代碼就和調用一樣簡單。如果你在張量上調用 .cuda(),則它將執行從 CPU 到 CUDA GPU 的數據遷移。如果你在模型上調用 .cuda(),則它不僅將所有內部儲存移到 GPU,還將整個計算圖映射至 GPU。
要想將張量或模型復制回 CPU,比如想和 NumPy 交互,你可以調用 .cpu()。
cuda_gpu = torch.cuda.is_available()
if (cuda_gpu):
print("Great, you have a GPU!")
else:
print("Life is short -- consider a GPU!")
if cuda_gpu:
x = x.cuda()
print(type(x.data))
else:
x = x.cpu()
print(type(x.data))
我們來定義兩個函數(訓練函數和測試函數)來使用我們的模型執行訓練和推斷任務。該代碼同樣來自 PyTorch 官方教程,我們摘選了所有訓練/推斷的必要步驟。
對于訓練和測試網絡,我們需要執行一系列動作,這些動作可直接映射至 PyTorch 代碼:
- 我們將模型轉換到訓練/推斷模式;
- 我們通過在數據集上成批獲取圖像,以迭代訓練模型;
- 對于每一個批量的圖像,我們都要加載數據和標注,運行網絡的前向步驟來獲取模型輸出;
- 我們定義損失函數,計算每一個批量的模型輸出和目標之間的損失;
- 訓練時,我們初始化梯度為零,使用上一步定義的優化器和反向傳播,來計算所有與損失有關的層級梯度;
- 訓練時,我們執行權重更新步驟。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import torch.nn.functional as F
x = Variable(torch.randn(4, 1), requires_grad=False)
y = Variable(torch.randn(3, 1), requires_grad=False)
w1 = Variable(torch.randn(5, 4), requires_grad=True)
w2 = Variable(torch.randn(3, 5), requires_grad=True)
def model_forward(x):
return F.sigmoid(w2@ F.sigmoid(w1@ x))
#損失函數:描述我們模型的預測距離目標還有多遠;
criterion = nn.MSELoss()
#優化算法:用于更新權重;
optimizer = optim.SGD([w1, w2], lr=0.001) #隨機最速下降法 (SGD)
#反向傳播步驟:
for epoch in range(10):
loss = criterion(model_forward(x), y)
optimizer.zero_grad() #將先前的梯度清零
loss.backward() #反向傳播
optimizer.step() #應用這些梯度
cuda_gpu = torch.cuda.is_available()
if (cuda_gpu):
print("Great, you have a GPU!")
else:
print("Life is short -- consider a GPU!")
if cuda_gpu:
x = x.cuda()
print(type(x.data))
else:
x = x.cpu()
print(type(x.data))
def train(model, epoch, criterion, optimizer, data_loader):
model.train()
for batch_idx, (data, target) in enumerate(data_loader):
#enumerate() 函數用于將一個可遍歷的數據對象(如列表、元組或字符串)組合為一個索引序列,
#同時列出數據和數據下標,一般用在 for 循環當中
if cuda_gpu:
data, target = data.cuda(), target.cuda()
model.cuda()
data, target = Variable(data), Variable(target)
output = model(data)
optimizer.zero_grad() #將先前的梯度清零
loss = criterion(output, target)
loss.backward() #應用這些梯度
optimizer.step()
if (batch_idx+1) % 400 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f}'.format(
epoch, (batch_idx+1) * len(data), len(data_loader.dataset),
100. * (batch_idx+1) / len(data_loader), loss.data[0]))
def test(model, epoch, criterion, data_loader):
model.eval()#eval() 函數用來執行一個字符串表達式,并返回表達式的值。
#output = model(data)
test_loss = 0
correct = 0
for data, target in data_loader:
test_loss += criterion(output, target).data[0]
pred = output.data.max(1)[1] #獲取最大對數概率指標
correct += pred.eq(target.data).cpu().sum()
test_loss /= len(data_loader) #損失函數已經超過批量大小
acc = correct / len(data_loader.dataset)
print('
Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)
'.format(
test_loss, correct, len(data_loader.dataset), 100. * acc))
return (acc, test_loss)
2. 使用 PyTorch 進行數據分析
使用 torch.nn 庫構建模型
使用 torch.autograd 庫訓練模型
將數據封裝進 torch.utils.data.Dataset 庫
使用 NumPy interface 連接你的模型、數據和你最喜歡的工具
在查看復雜模型之前,我們先來看個簡單的:簡單合成數據集上的線性回歸,我們可以使用 sklearn 工具生成這樣的合成數據集。
from sklearn.datasets import make_regression
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
sns.set()
x_train, y_train, W_target = make_regression(n_samples=100, n_features=1, noise=10, coef = True)
df = pd.DataFrame(data = {'X':x_train.ravel(), 'Y':y_train.ravel()})
sns.lmplot(x='X', y='Y', data=df, fit_reg=True)
plt.show()
x_torch = torch.FloatTensor(x_train)
y_torch = torch.FloatTensor(y_train)
y_torch = y_torch.view(y_torch.size()[0], 1)

PyTorch 的 nn 庫中有大量有用的模塊,其中一個就是線性模塊。如名字所示,它對輸入執行線性變換,即線性回歸。
from sklearn.datasets import make_regression
import seaborn as sns #seaborn能夠快速的繪制圖表
import pandas as pd
import matplotlib.pyplot as plt
sns.set() #seaborn繪圖命令
#x_train為樣本特征,y_train為樣本輸出,W_target為回歸系數,共100個樣本,每個樣本1個特征
x_train, y_train, W_target = make_regression(n_samples=100, n_features=1, noise=10, coef = True)
#make_regression:生成回歸模型數據
#n_samples:生成樣本數 n_features:樣本特征數 noise:樣本隨機噪音 coef:是否返回回歸系數
df = pd.DataFrame(data = {'X':x_train.ravel(), 'Y':y_train.ravel()})
#DataFrame類似excel,是一種二維表,可以存放數值、字符串等
sns.lmplot(x='X', y='Y', data=df, fit_reg=True)# lmplot是用來繪制回歸圖的 fit_reg:是否顯示擬合的直線
plt.show() #顯示圖像
x_torch = torch.FloatTensor(x_train) #類型轉換,將list,numpy轉化為tensor
y_torch = torch.FloatTensor(y_train)
y_torch = y_torch.view(y_torch.size()[0], 1) #view(n,m):排成n行m列
#PyTorch 的 nn 庫中有大量有用的模塊,其中一個就是線性模塊。
#如名字所示,它對輸入執行線性變換,即線性回歸。
class LinearRegression(torch.nn.Module):
def __init__(self, input_size, output_size):
super(LinearRegression, self).__init__()#super():對繼承自父類的屬性進行初始化,用父類的初始化方法來初始化繼承的屬性
self.linear = torch.nn.Linear(input_size, output_size)
#torch.nn.Linear(in_features,out_features,bias = True)對傳入數據應用線性變換:y=Ax+b
#參數:in_features:每個輸入樣本的大小 out_features:每個輸出樣本的大小
def forward(self, x):
return self.linear(x)
model = LinearRegression(1, 1) #__init__中input_size=1,output_size=1
criterion = torch.nn.MSELoss() #均方差損失函數
#構建一個optimizer對象。這個對象能夠保持當前參數狀態并基于計算得到的梯度進行參數更新
optimizer = torch.optim.SGD(model.parameters(), lr=0.1) #隨機最速下降法(SGD) lr:學習率
for epoch in range(50):
data, target = Variable(x_torch), Variable(y_torch) #Variable變量
output = model(data)
optimizer.zero_grad()#將先前的梯度清零
loss = criterion(output, target)
loss.backward()#反向傳播
optimizer.step()#應用這些梯度
predicted = model(Variable(x_torch)).data.numpy()#擬合曲線
#現在我們可以打印出原始數據和適合 PyTorch 的線性回歸。
plt.plot(x_train, y_train, 'o', label='Original data')#原數據點
plt.plot(x_train, predicted, label='Fitted line')#擬合曲線
plt.legend() #圖片為默認格式
plt.show() #顯示

為了轉向更復雜的模型,我們下載了 MNIST 數據集至「datasets」文件夾中,并測試一些 PyTorch 中可用的初始預處理。PyTorch 具備數據加載器和處理器,可用于不同的數據集。數據集下載好后,你可以隨時使用。你還可以將數據包裝進 PyTorch 張量,創建自己的數據加載器類別。
批大小(batch size)是機器學習中的術語,指一次迭代中使用的訓練樣本數量。批大小可以是以下三種之一:
- batch 模式:批大小等于整個數據集,因此迭代和 epoch 值一致;
- mini-batch 模式:批大小大于 1 但小于整個數據集的大小。通常,數量可以是能被整個數據集整除的值。
- 隨機模式:批大小等于 1。因此梯度和神經網絡參數在每個樣本之后都要更新。
train_loader = torch.utils.data.DataLoader(
datasets.MNIST("data",train=True, download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_num_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST("data",train=False, transform=transforms.Compose([ #transforms.Compose把兩個步驟整合到一起
transforms.ToTensor(),
#ToTensor()將shape為(H, W, C)的nump.ndarray或img轉為shape為(C, H, W)的tensor,
#其將每一個數值歸一化到[0,1],其歸一化方法比較簡單,直接除以255即可。
transforms.Normalize((0.1307,), (0.3081,))
#Normalize():先將輸入歸一化到(0,1),再使用公式”(x-mean)/std”,將每個元素分布到(-1,1)
])),
3. PyTorch 中的 LeNet 卷積神經網絡(CNN)
現在我們從頭開始創建第一個簡單神經網絡。該網絡要執行圖像分類,識別 MNIST 數據集中的手寫數字。這是一個四層的卷積神經網絡(CNN),一種分析 MNIST 數據集的常見架構。該代碼來自 PyTorch 官方教程,你可以在這里(http://pytorch.org/tutorials/)找到更多示例。
- 我們將使用 torch.nn 庫中的多個模塊:
- 線性層:使用層的權重對輸入張量執行線性變換;
- Conv1 和 Conv2:卷積層,每個層輸出在卷積核(小尺寸的權重張量)和同樣尺寸輸入區域之間的點積;
- Relu:修正線性單元函數,使用逐元素的激活函數 max(0,x);
- 池化層:使用 max 運算執行特定區域的下采樣(通常 2x2 像素);
- Dropout2D:隨機將輸入張量的所有通道設為零。當特征圖具備強相關時,dropout2D 提升特征圖之間的獨立性;
- Softmax:將 Log(Softmax(x)) 函數應用到 n 維輸入張量,以使輸出在 0 到 1 之間。
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.conv1 = nn.Conv2d(1,10,kernel_size=5) #輸入和輸出通道數分別為1和10
self.conv2 = nn.Conv2d(10,20,kernel_size=5) #輸入和輸出通道數分別為10和20
self.conv2_drop = nn.Dropout2d() #隨機選擇輸入的信道,將其設為0
self.fc1 = nn.Linear(320,50) #輸入的向量大小和輸出的大小分別為320和50
self.fc2 = nn.Linear(50,10)
def forward(self,x):
x = F.relu(F.max_pool2d(self.conv1(x),2)) #卷積--最大池化層--relu
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)),2)) #卷積--dropout--最大池化--relu
x = x.view(-1, 320) #view(n,m):排成n行m列
x = F.relu(self.fc1(x)) #fc--relu
x = F.dropout(x, training=self.training) #dropout
x = self.fc2(x)
return F.log_softmax(x, dim=1)
#創建 LeNet 類后,創建對象并移至 GPU:
model = LeNet()
model.cuda()#沒有GPU則用model.cpu()代替model.cuda()
print ('MNIST_net model:
')
print (model)
輸出:
MNIST_net model:
LeNet(
(conv1): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1))
(conv2_drop): Dropout2d(p=0.5)
(fc1): Linear(in_features=320, out_features=50, bias=True)
(fc2): Linear(in_features=50, out_features=10, bias=True)
)
import os
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
import torch.nn.functional as F
cuda_gpu = torch.cuda.is_available()
def train(model, epoch, criterion, optimizer, data_loader):
model.train()
for batch_idx, (data, target) in enumerate(data_loader):
#enumerate() 函數用于將一個可遍歷的數據對象(如列表、元組或字符串)組合為一個索引序列,
#同時列出數據和數據下標,一般用在 for 循環當中
if cuda_gpu:
data, target = data.cuda(), target.cuda()
model.cuda()
data, target = Variable(data), Variable(target)
output = model(data)
optimizer.zero_grad() #將先前的梯度清零
loss = criterion(output, target)
loss.backward() #應用這些梯度
optimizer.step()
if (batch_idx+1) % 400 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f}'.format(
epoch, (batch_idx+1) * len(data), len(data_loader.dataset),
100. * (batch_idx+1) / len(data_loader), loss.data[0]))
def test(model, epoch, criterion, data_loader):
model.eval()#eval() 函數用來執行一個字符串表達式,并返回表達式的值
test_loss = 0
correct = 0
for data, target in data_loader:
if cuda_gpu:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
output = model(data)
test_loss += criterion(output, target).item() #items()將字典中的每個項分別做為元組,添加到一個列表中形成一個新的列表容器
pred = output.data.max(1)[1] #獲取最大對數概率指標
correct += pred.eq(target.data).cpu().sum()
test_loss /= len(data_loader) #損失函數已經超過批量大小
acc = correct / len(data_loader.dataset)
print('
Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)
'.format(
test_loss, correct, len(data_loader.dataset), 100. * acc))
return (acc, test_loss)
batch_num_size = 64
#DataLoader數據加載器,結合了數據集和取樣器,并且可以提供多個線程處理數據集
#在訓練模型時使用到此函數,用來把訓練數據分成多個小組,此函數每次拋出一組數據
#直至把所有的數據都拋出。就是做一個數據的初始化
#此函數的參數:
#dataset:包含所有數據的數據集
#batch_size :每一小組所包含數據的數量
#Shuffle : 是否打亂數據位置,當為Ture時打亂數據,全部拋出數據后再次dataloader時重新打亂
train_loader = torch.utils.data.DataLoader(
datasets.MNIST("data",train=True, download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_num_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST("data",train=False, transform=transforms.Compose([ #transforms.Compose把兩個步驟整合到一起
transforms.ToTensor(),
#ToTensor()將shape為(H, W, C)的nump.ndarray或img轉為shape為(C, H, W)的tensor,
#其將每一個數值歸一化到[0,1],其歸一化方法比較簡單,直接除以255即可。
transforms.Normalize((0.1307,), (0.3081,))
#Normalize():先將輸入歸一化到(0,1),再使用公式”(x-mean)/std”,將每個元素分布到(-1,1)
])),
batch_size=batch_num_size, shuffle=True)
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.conv1 = nn.Conv2d(1,10,kernel_size=5) #輸入和輸出通道數分別為1和10
self.conv2 = nn.Conv2d(10,20,kernel_size=5) #輸入和輸出通道數分別為10和20
self.conv2_drop = nn.Dropout2d() #隨機選擇輸入的信道,將其設為0
self.fc1 = nn.Linear(320,50) #輸入的向量大小和輸出的大小分別為320和50
self.fc2 = nn.Linear(50,10)
def forward(self,x):
x = F.relu(F.max_pool2d(self.conv1(x),2)) #卷積--最大池化層--relu
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)),2)) #卷積--dropout--最大池化--relu
x = x.view(-1, 320) #view(n,m):排成n行m列
x = F.relu(self.fc1(x)) #fc--relu
x = F.dropout(x, training=self.training) #dropout
x = self.fc2(x)
return F.log_softmax(x, dim=1)
#創建 LeNet 類后,創建對象并移至 GPU:
model = LeNet()
if cuda_gpu:
model.cuda()#沒有GPU則用model.cpu()代替model.cuda()
print ('MNIST_net model:
')
print (model)
#要訓練該模型,我們需要使用帶動量的 SGD,學習率為 0.01,momentum 為 0.5。
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr = 0.005, momentum = 0.9)
#僅僅需要 5 個 epoch(一個 epoch 意味著你使用整個訓練數據集來更新訓練模型的權重)
#我們就可以訓練出一個相當準確的 LeNet 模型。這段代碼檢查可以確定文件中是否已有預訓練好的模型
#有則加載;無則訓練一個并保存至磁盤
epochs = 5
if (os.path.isfile('pretrained/MNIST_net.t7')):
print ('Loading model')
model.load_state_dict(torch.load('pretrained/MNIST_net.t7', map_location=lambda storage, loc: storage))
acc, loss = test(model, 1, criterion, test_loader)
else:
print ('Training model')
for epoch in range(1, epochs + 1):
train(model, epoch, criterion, optimizer, train_loader)
acc, loss = test(model, 1, criterion, test_loader)
torch.save(model.state_dict(), 'pretrained/MNIST_net.t7')
若無預訓練模型,輸出:
Training model
Test set: Average loss: 0.1348, Accuracy: 9578/10000 (0%)
Test set: Average loss: 0.0917, Accuracy: 9703/10000 (0%)
Test set: Average loss: 0.0746, Accuracy: 9753/10000 (0%)
Test set: Average loss: 0.0659, Accuracy: 9795/10000 (0%)
Test set: Average loss: 0.0553, Accuracy: 9828/10000 (0%)
現在我們來看下模型。首先,打印出該模型的信息。打印函數顯示所有層(如 Dropout 被實現為一個單獨的層)及其名稱和參數。同樣有一個迭代器在模型中所有已命名模塊之間運行。當你具備一個包含多個「內部」模型的復雜 DNN 時,這有所幫助。在所有已命名模塊之間的迭代允許我們創建模型解析器,可讀取模型參數、創建與該網絡類似的模塊。
print ("Internal models:")
for idx, m in enumerate(model.named_modules()):
print(idx, "->", m)
print ("-------------------------------------------------------------------------")
輸出:
Internal models:
0 -> ('', LeNet(
(conv1): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1))
(conv2_drop): Dropout2d(p=0.5)
(fc1): Linear(in_features=320, out_features=50, bias=True)
(fc2): Linear(in_features=50, out_features=10, bias=True)
))
1 -> ('conv1', Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1)))
2 -> ('conv2', Conv2d(10, 20, kernel_size=(5, 5), stride=(1, 1)))
3 -> ('conv2_drop', Dropout2d(p=0.5))
4 -> ('fc1', Linear(in_features=320, out_features=50, bias=True))
5 -> ('fc2', Linear(in_features=50, out_features=10, bias=True))
你可以使用 .cpu() 方法將張量移至 CPU(或確保它在那里)。或者,當 GPU 可用時(torch.cuda. 可用),使用 .cuda() 方法將張量移至 GPU。你可以看到張量是否在 GPU 上,其類型為 torch.cuda.FloatTensor。如果張量在 CPU 上,則其類型為 torch.FloatTensor。
t = torch.rand(2, 4, 3, 5)
print (type(t.cpu().data))
if torch.cuda.is_available():
print ("Cuda is available")
print (type(t.cuda().data))
else:
print ("Cuda is NOT available")
輸出:
Cuda is available
如果張量在 CPU 上,我們可以將其轉換成 NumPy 數組,其共享同樣的內存位置,改變其中一個就會改變另一個。
import torch
t = torch.rand(2, 4, 3, 5)
if torch.cuda.is_available():
try:
print(t.data.numpy())
except RuntimeError as e:
"你不能將GPU張量轉換為numpy數組,你必須將你的權重tendor復制到cpu然后得到numpy數組"
print(type(t.cpu().data.numpy()))
print(t.cpu().data.numpy().shape)
print(t.cpu().data.numpy())
現在我們了解了如何將張量轉換成 NumPy 數組,我們可以利用該知識使用 matplotlib 進行可視化!我們來打印出個卷積層的卷積濾波器。
import os
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
import torch.nn.functional as F
cuda_gpu = torch.cuda.is_available()
def train(model, epoch, criterion, optimizer, data_loader):
model.train()
for batch_idx, (data, target) in enumerate(data_loader):
#enumerate() 函數用于將一個可遍歷的數據對象(如列表、元組或字符串)組合為一個索引序列,
#同時列出數據和數據下標,一般用在 for 循環當中
if cuda_gpu:
data, target = data.cuda(), target.cuda()
model.cuda()
data, target = Variable(data), Variable(target)
output = model(data)
optimizer.zero_grad() #將先前的梯度清零
loss = criterion(output, target)
loss.backward() #應用這些梯度
optimizer.step()
if (batch_idx+1) % 400 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)] Loss: {:.6f}'.format(
epoch, (batch_idx+1) * len(data), len(data_loader.dataset),
100. * (batch_idx+1) / len(data_loader), loss.data[0]))
def test(model, epoch, criterion, data_loader):
model.eval()#eval() 函數用來執行一個字符串表達式,并返回表達式的值
test_loss = 0
correct = 0
for data, target in data_loader:
if cuda_gpu:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
output = model(data)
test_loss += criterion(output, target).item() #items()將字典中的每個項分別做為元組,添加到一個列表中形成一個新的列表容器
pred = output.data.max(1)[1] #獲取最大對數概率指標
correct += pred.eq(target.data).cpu().sum()
test_loss /= len(data_loader) #損失函數已經超過批量大小
acc = correct / len(data_loader.dataset)
print('
Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)
'.format(
test_loss, correct, len(data_loader.dataset), 100. * acc))
return (acc, test_loss)
batch_num_size = 64
#DataLoader數據加載器,結合了數據集和取樣器,并且可以提供多個線程處理數據集
#在訓練模型時使用到此函數,用來把訓練數據分成多個小組,此函數每次拋出一組數據
#直至把所有的數據都拋出。就是做一個數據的初始化
#此函數的參數:
#dataset:包含所有數據的數據集
#batch_size :每一小組所包含數據的數量
#Shuffle : 是否打亂數據位置,當為Ture時打亂數據,全部拋出數據后再次dataloader時重新打亂
train_loader = torch.utils.data.DataLoader(
datasets.MNIST("data",train=True, download=True, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_num_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST("data",train=False, transform=transforms.Compose([ #transforms.Compose把兩個步驟整合到一起
transforms.ToTensor(),
#ToTensor()將shape為(H, W, C)的nump.ndarray或img轉為shape為(C, H, W)的tensor,
#其將每一個數值歸一化到[0,1],其歸一化方法比較簡單,直接除以255即可。
transforms.Normalize((0.1307,), (0.3081,))
#Normalize():先將輸入歸一化到(0,1),再使用公式”(x-mean)/std”,將每個元素分布到(-1,1)
])),
batch_size=batch_num_size, shuffle=True)
class LeNet(nn.Module):
def __init__(self):
super(LeNet,self).__init__()
self.conv1 = nn.Conv2d(1,10,kernel_size=5) #輸入和輸出通道數分別為1和10
self.conv2 = nn.Conv2d(10,20,kernel_size=5) #輸入和輸出通道數分別為10和20
self.conv2_drop = nn.Dropout2d() #隨機選擇輸入的信道,將其設為0
self.fc1 = nn.Linear(320,50) #輸入的向量大小和輸出的大小分別為320和50
self.fc2 = nn.Linear(50,10)
def forward(self,x):
x = F.relu(F.max_pool2d(self.conv1(x),2)) #卷積--最大池化層--relu
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)),2)) #卷積--dropout--最大池化--relu
x = x.view(-1, 320) #view(n,m):排成n行m列
x = F.relu(self.fc1(x)) #fc--relu
x = F.dropout(x, training=self.training) #dropout
x = self.fc2(x)
return F.log_softmax(x, dim=1)
#創建 LeNet 類后,創建對象并移至 GPU:
model = LeNet()
if cuda_gpu:
model.cuda()#沒有GPU則用model.cpu()代替model.cuda()
print ('MNIST_net model:
')
print (model)
#要訓練該模型,我們需要使用帶動量的 SGD,學習率為 0.01,momentum 為 0.5。
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr = 0.005, momentum = 0.9)
#僅僅需要 5 個 epoch(一個 epoch 意味著你使用整個訓練數據集來更新訓練模型的權重)
#我們就可以訓練出一個相當準確的 LeNet 模型。這段代碼檢查可以確定文件中是否已有預訓練好的模型
#有則加載;無則訓練一個并保存至磁盤
epochs = 5
if (os.path.isfile('pretrained/MNIST_net.t7')):
print ('Loading model')
model.load_state_dict(torch.load('pretrained/MNIST_net.t7', map_location=lambda storage, loc: storage))
acc, loss = test(model, 1, criterion, test_loader)
else:
print ('Training model')
for epoch in range(1, epochs + 1):
train(model, epoch, criterion, optimizer, train_loader)
acc, loss = test(model, 1, criterion, test_loader)
torch.save(model.state_dict(), 'MNIST_net.t7')
t = torch.rand(2, 4, 3, 5)
if torch.cuda.is_available():
try:
print(t.data.numpy())
except RuntimeError as e:
"你不能將GPU張量轉換為numpy數組,你必須將你的權重tendor復制到cpu然后得到numpy數組"
print(type(t.cpu().data.numpy()))
print(t.cpu().data.numpy().shape)
print(t.cpu().data.numpy())
data = model.conv1.weight.cpu().data.numpy()
print (data.shape)
print (data[:, 0].shape)
kernel_num = data.shape[0]
fig, axes = plt.subplots(ncols=kernel_num, figsize=(2*kernel_num, 2))
for col in range(kernel_num):
axes[col].imshow(data[col, 0, :, :], cmap=plt.cm.gray)
plt.show()

審核編輯:湯梓紅
-
python
+關注
關注
56文章
4792瀏覽量
84630 -
數組
+關注
關注
1文章
417瀏覽量
25939 -
pytorch
+關注
關注
2文章
808瀏覽量
13201
發布評論請先 登錄
相關推薦
Image Style Transfer pytorch方式實現的主要思路
通過Cortex來非常方便的部署PyTorch模型
簡化版的XLNet在PyTorch Wrapper實現
基于Cortex部署PyTorch模型
基于PyTorch的深度學習入門教程之PyTorch簡單知識

tensorflow和pytorch哪個更簡單?
基于PyTorch的卷積核實例應用
在PyTorch中搭建一個最簡單的模型
利用Arm Kleidi技術實現PyTorch優化






 工商網監
工商網監
評論