


1 簡介
DeepMind提出的Sparrow,相對(duì)于以往的方法,是一種更加有用,準(zhǔn)確并且無害的信息檢索對(duì)話機(jī)器人。
在之前的對(duì)話研究中,往往會(huì)針對(duì)對(duì)話的不同方面去設(shè)計(jì)對(duì)應(yīng)的任務(wù)跟模塊,例如知識(shí)性,一致性,長期記憶等等,但是Sparrow則不然,它直接根據(jù)用戶的用戶的反饋進(jìn)行學(xué)習(xí),這樣能盡可能讓模型對(duì)齊真實(shí)的用戶行為,而不再需要關(guān)注過于瑣碎的諸多對(duì)話細(xì)節(jié)。
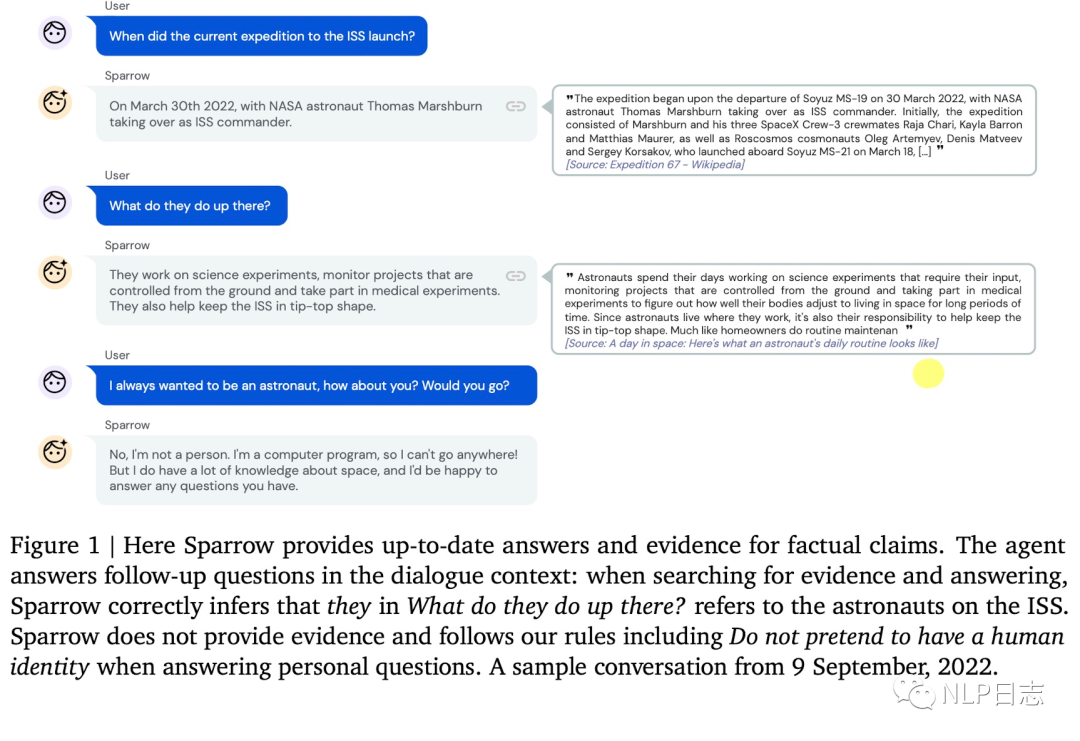
圖1: Sparrow測試樣例
2 Sparrow
整個(gè)流程是通過Sparrow模型根據(jù)當(dāng)前對(duì)話生成多個(gè)候選回復(fù),讓用戶去判斷那個(gè)回復(fù)最好,哪些回復(fù)違反了預(yù)先設(shè)置好的規(guī)則,基于用戶的反饋去訓(xùn)練對(duì)應(yīng)的Reward模型,利用訓(xùn)練好的Reward模型,用強(qiáng)化學(xué)習(xí)算法再去優(yōu)化Sparrow的生成結(jié)果。
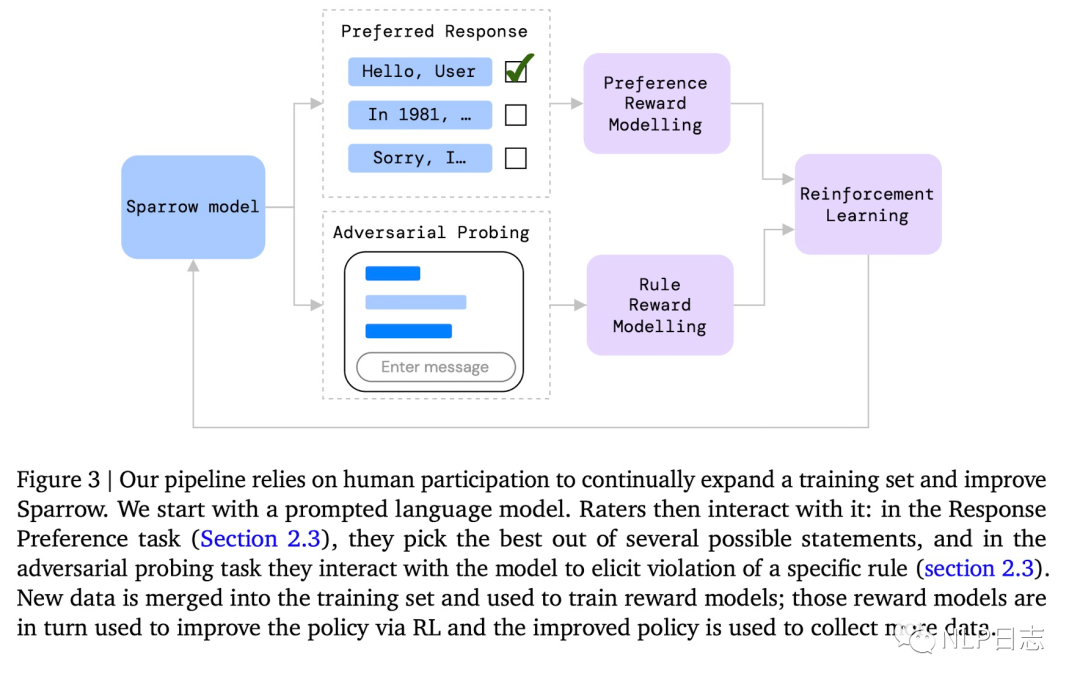
圖2:Sparrow框架
Reward
Sparrow學(xué)習(xí)的用戶反饋分為兩種,一種用戶判斷對(duì)話是否違背某些預(yù)設(shè)置好的規(guī)則,另一種的是從用戶根據(jù)當(dāng)前對(duì)話從個(gè)候選答案里選擇最合適的一個(gè)。這兩種反饋分為對(duì)應(yīng)兩個(gè)不同的模型,Rule reward model跟Preference reward model。
對(duì)于Rule reward model,首先需要根據(jù)任務(wù)自定義對(duì)應(yīng)的一些規(guī)則,例如判斷機(jī)器人是否在回答用戶問題,話題是否變化等等,規(guī)則樣例如下圖所示。在具體訓(xùn)練數(shù)據(jù)構(gòu)造時(shí),用戶在給定對(duì)話條件下,還會(huì)給某個(gè)特定規(guī)則,讓用戶有意識(shí)的引導(dǎo)機(jī)器人去違反對(duì)應(yīng)的規(guī)則,然后再由用戶評(píng)估機(jī)器人回復(fù)是否違反對(duì)應(yīng)的規(guī)則。
之所以采用這種方式是為了更高效的積累到高質(zhì)量樣本。用構(gòu)造好的訓(xùn)練數(shù)據(jù)訓(xùn)練對(duì)應(yīng)的分類模型,判斷機(jī)器人回復(fù)是否違反對(duì)應(yīng)的規(guī)則,每個(gè)規(guī)則對(duì)應(yīng)一個(gè)分類模型,彼此獨(dú)立。
圖3:規(guī)則示例
對(duì)于Preference reward model,在給定當(dāng)前對(duì)話條件下,利用多種方式生成多個(gè)候選答案(通過是否引入知識(shí)檢索,不同生成模型,不同prompt,不同采樣策略),讓用戶從中選擇最合適的答案。利用這些構(gòu)造好的數(shù)據(jù)訓(xùn)練可以得到對(duì)應(yīng)的分類模型,判斷用戶對(duì)于當(dāng)前回復(fù)的傾向。
以下圖為例,共有8個(gè)候選答案,其中前四個(gè)是不不經(jīng)過知識(shí)檢索直接生成的,后面四個(gè)是通過兩個(gè)不同的檢索query進(jìn)行知識(shí)檢索,將得到的檢索結(jié)果跟當(dāng)前對(duì)話合并再一起后再生成回復(fù)的。
圖4: 回復(fù)生成流程
Reranking
當(dāng)上述兩個(gè)Reward模型給候選答案生成對(duì)應(yīng)的得分后,通過一個(gè)重排機(jī)制綜合考慮兩者的得分可以進(jìn)一步優(yōu)化對(duì)話機(jī)器人的性能。
Evidence
前面提及的答案生成是可以通過知識(shí)檢索,根據(jù)當(dāng)前上下文生成對(duì)應(yīng)的query,利用Google進(jìn)行搜索,將得到的結(jié)果跟當(dāng)前對(duì)話信息組合,然后再生成對(duì)應(yīng)的回復(fù)。之前也寫過一些相關(guān)的文章,有興趣可以自行查看文本生成系列之retrieval augmentation(思考篇)。
Reinforcement learning
這里強(qiáng)化學(xué)習(xí)每一步的狀態(tài)是當(dāng)前的對(duì)話上下文,action是具體的token,利用前面提及的rule reward model跟preference reward model來給action打出對(duì)應(yīng)的reward得分,從而優(yōu)化Sparrow的輸出結(jié)果。在強(qiáng)化學(xué)習(xí)訓(xùn)練過程中,如果機(jī)器人生成的回復(fù)reward超過預(yù)期的話,就會(huì)把當(dāng)前對(duì)話上下文+機(jī)器人回復(fù)作為新的訓(xùn)練數(shù)據(jù)加入到語料中,擴(kuò)充訓(xùn)練語料庫。
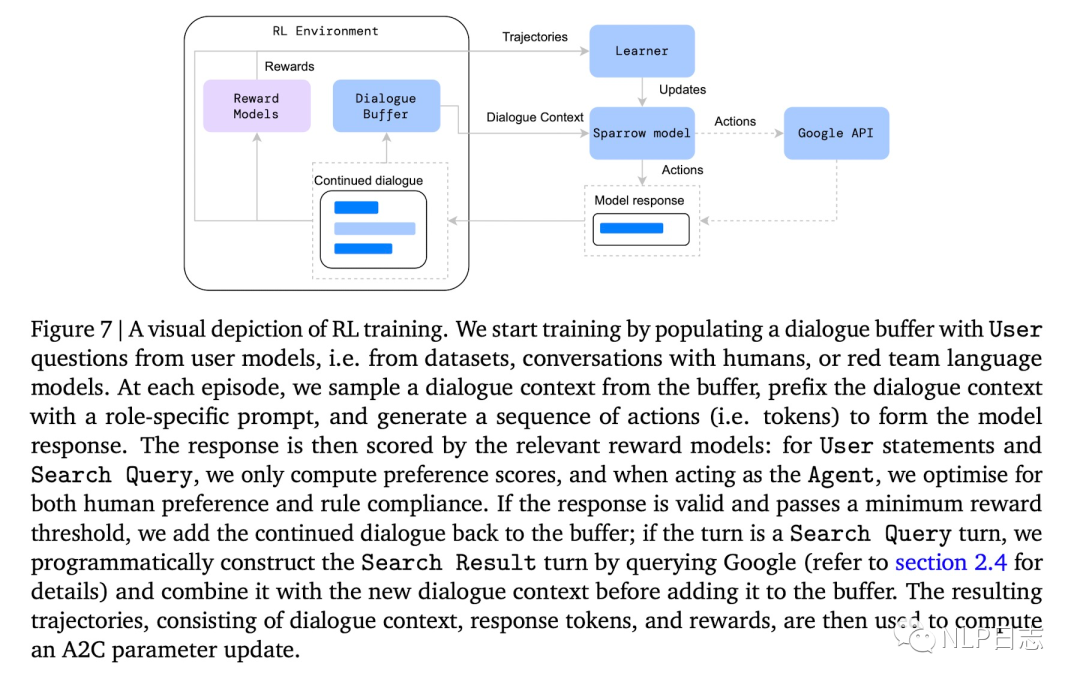
圖5: 強(qiáng)化學(xué)習(xí)流程
3 總結(jié)
個(gè)人認(rèn)為,Sparrow對(duì)話機(jī)器人,最大的特色在于直接對(duì)用戶的反饋進(jìn)行學(xué)習(xí),那樣就不需要為對(duì)話各種瑣碎細(xì)節(jié)去設(shè)計(jì)不同的模塊跟任務(wù),把決策權(quán)進(jìn)一步交給模型,讓模型自己去學(xué),而對(duì)于那些機(jī)器人可能學(xué)不好的地方,通過預(yù)先定義的規(guī)則去構(gòu)造對(duì)應(yīng)的訓(xùn)練數(shù)據(jù),讓模型自己去補(bǔ)全。By the way, 可以好好期待一波ChatGPT了。
審核編輯:劉清
-
機(jī)器人
+關(guān)注
關(guān)注
213文章
29777瀏覽量
213175
原文標(biāo)題:對(duì)話機(jī)器人之Sparrow
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
AI火爆 對(duì)話機(jī)器人將成為App之后的新入口?
電話機(jī)器人顯著提高回款效率,對(duì)催收幫助不言而喻。
智能打電話,機(jī)器人哪家比較好 如何選擇合適的電銷機(jī)器人
電銷機(jī)器人的優(yōu)點(diǎn)
電話機(jī)器人:電銷行業(yè)精準(zhǔn)篩選客戶的利器
華云天下智能電話機(jī)器人有哪些優(yōu)勢?
機(jī)器人簡介
機(jī)器人系統(tǒng)與控制需求簡介
設(shè)計(jì)一個(gè)能自由行走并且可以與人語音對(duì)話機(jī)器人的設(shè)計(jì)資料分享
電話機(jī)器人是什么?電銷機(jī)器人有什么用?有多少電話機(jī)器人品牌?
檢索式智能對(duì)話機(jī)器人開發(fā)實(shí)戰(zhàn)案例詳細(xì)資料分析概述
外呼對(duì)話機(jī)器人,自動(dòng)批量外呼、智能人機(jī)對(duì)話-漢云





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論