 SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks 深層網絡連體視覺跟蹤的演變
SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks 深層網絡連體視覺跟蹤的演變
論文:https://arxiv.org/pdf/1812.11703.pdf
程序:https://github.com/PengBoXiangShang/SiamRPN_plus_plus_PyTorch
摘要
基于孿生網絡的跟蹤器將跟蹤表述為目標模板和搜索區域之間的卷積特征互相關。然而孿生網絡的算法不能利用來自深層網絡(如 resnet-50或更深層)的特征,與先進的算法相比仍然有差距。
在文章中我們證明了核心原因是孿生網絡缺乏嚴格的平移不變性。我們突破了這一限制,通過一個簡單而有效的空間感知采樣策略,成功地訓練了一個具有顯著性能提升的基于ResNet網絡的孿生跟蹤器。此外,我們還提出了一種新的模型體系結構來執行分層和深度聚合,這不僅進一步提高了計算的準確性,而且還減小了模型的尺寸。我們在五個大型跟蹤基準上獲得了結果,包括OTB2015、VOT2018、UAV123、LASOT和TrackingNet。
該論文主要解決的問題是將深層基準網絡ResNet、Inception等網絡應用到基于孿生網絡的跟蹤網絡中。在SiameseFC算法之后,很多的基于孿生網絡的跟蹤算法都使用淺層的類AlexNet作為基準特征提取器,直接使用預訓練好的深層網絡反而會導致跟蹤算法精度的下降。
1.介紹
在平衡精度和速度方面,即使是性能好的孿生跟蹤器,如SiamRPN,在OTB2015等跟蹤基準上仍與現有技術有顯著差距。所有這些跟蹤都在類似于AlexNet的架構上構建了自己的網絡,并多次嘗試訓練具有更復雜架構(如ResNet)的孿生網絡,但沒有性能提升。在這種觀察的啟發下,我們對現有的孿生追蹤器進行了分析,發現其核心原因是絕對平移不變性(strict translation invariance)的破壞。由于目標可能出現在搜索區域的任何位置,因此目標模板的學習特征表示應該保持空間不變性,并且我們進一步從理論上發現,在新的深層體系結構中,只有AlexNet的zero-padding才能滿足這種空間不變性要求。
我們引入了一種采樣策略來打破孿生跟蹤器的空間不變性限制。我們成功地訓練了一個基于SiamRPN的跟蹤器,使用ResNet作為主干網絡。利用ResNet結構,提出了一種基于層的互相關運算特征聚合結構(a layer-wise feature aggravation structure),該結構有助于跟蹤器從多個層次的特征中預判出相似度圖。通過對孿生網絡結構的交叉相關分析,發現其兩個網絡分支在參數個數上存在高度不平衡,因此我們進一步提出了一種深度可分離的相關結構,它不僅大大減少了目標模板分支中的參數個數,而且使模型的訓練過程更加穩定。此外,還觀察到一個有趣的現象,即相同類別的對象在相同通道上具有較高的響應,而其余通道的響應則被抑制。正交特性也可以提高跟蹤性能。
綜上所述,本文的主要貢獻如下:
1.我們對Siam進行了深入的分析,并證明在使用深網絡時,精度的降低是由于絕對平移不變性的破壞。
2.我們提出了一種采樣策略以打破空間不變性限制,成功訓練了基于ResNet架構的孿生跟蹤器。
3.提出了一種基于層次的互相關操作特征聚集結構,該結構有助于跟蹤器根據多層次學習的特征預測相似度圖。
我們提出了一個深度可分離的相關結構來增強互相關,從而產生與不同語義相關的多重相似度圖。
在上述理論分析和技術貢獻的基礎上,我們開發了一種高效的視覺跟蹤模型,在跟蹤精度方面更為先進。同時以35 fps的速度高效運行。我們稱它為SiamRPN++,在五個大的跟蹤基準上持續獲得跟蹤結果,包括OTB2015、VOT2018、UAV123、LASOT和TrackingNet。此外,我們還提出了一種使用MobileNet主干網的快速跟蹤器,該主干網在以70 fps的速度運行時有良好的實時性能。
2.相關工作
RPN詳細介紹:https://mp.weixin.qq.com/s/VXgbJPVoZKjcaZjuNwgh-A
SiamFC詳細介紹:https://mp.weixin.qq.com/s/kS9osb2JBXbgb_WGU_3mcQ
SiamRPN詳細介紹:https://mp.weixin.qq.com/s/pmnip3LQtQIIm_9Po2SndA
3.深層孿生網絡跟蹤算法
如果使用更深層次的網絡,基于孿生網絡的跟蹤算法的性能可以顯著提高。然而僅僅通過直接使用更深層的網絡(如ResNet)來訓練孿生跟蹤器并不能獲得預期的性能改進。我們發現其根本原因主要是由于孿生追蹤器的內在限制。
3.1 孿生網絡跟蹤分析
基于孿生網絡的跟蹤算法將視覺跟蹤作為一個互相關問題,并從具有孿生網絡結構的深層模型中學習跟蹤相似性圖,一個分支用于學習目標的特征表示,另一個分支用于搜索區域。
目標區域通常在序列的第一幀中給出,可以看作是一個模板z。目標是在語義嵌入空間Φ(·)中從后續幀x中找到相似的區域(實例):
f(z,x)=\\phi(z)×\\phi(x)+b_i
其中b是偏移量。
這個簡單的匹配函數自然意味著孿生網絡跟蹤器有兩個內在的限制。
1.孿生跟蹤器中使用的收縮部分和特征抽取器對絕對平移不變性有內在的限制。
f(z,x[\\Delta\\tau_j])=f(z,x)[\\Delta\\tau_j]
確保了有效的訓練和推理。
2.收縮部分對結構對稱性有著內在的限制,即:
f(z,x)=f(x,z)
適用于相似性學習。即如果將搜索區域圖像和模板區域圖像進行互換,輸出的結果應該保持不變。
通過詳細的分析,我們發現防止使用深網絡的孿生跟蹤器的核心原因與這兩個方面有關。具體來說,一個原因是深層網絡中的填充會破壞絕對平移不變性。另一個是RPN需要不對稱的特征來進行分類和回歸。我們將引入空間感知抽樣策略來克服第一個問題,并在3.4中討論第二個問題。
絕對平移不變性只存在于no padding的網絡中,如修改后的AlexNet。以前基于孿生的網絡設計為淺層網絡,可以滿足這一限制。然而,如果使用的網絡被新型網絡如ResNet或MobileNet所取代,padding將不可避免地使網絡更深入,從而破壞了絕對平移不變性限制。我們的假設是,違反這一限制將導致學習到空間偏移。例如SiamFC在訓練方法時正樣本都在正中心,網絡逐漸會學習到樣本中正樣本分布的情況,圖像的中心會有更大的權重。
我們通過在帶有padding的網絡上進行模擬實驗來驗證我們的假設。移位定義為數據擴充中均勻分布產生的大平移范圍。我們的模擬實驗如下。首先,在三個單獨的訓練實驗中,目標被放置在具有不同shift range(0、16和32)的中心。Shift為正樣本距離中心點的距離。在收斂后,我們將測試數據集上生成的熱圖集合起來,然后將結果顯示在圖1中。
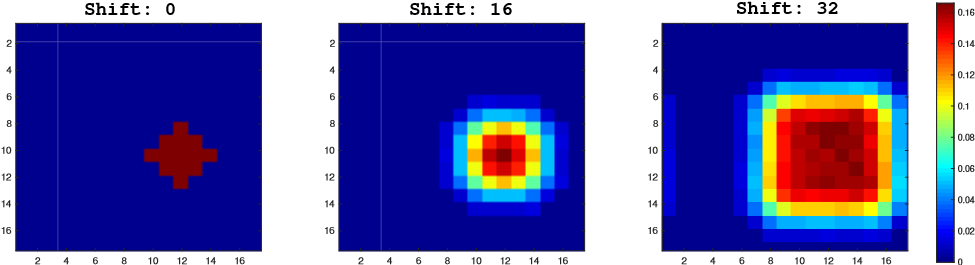
圖1. 當使用不同的隨機翻譯時,可視化正樣本的先驗概率。在±32像素內隨機平移后,分布變得更均勻。
在shift-0模擬中存在很強的中心偏移,只有中心位置具有較大的響應值,邊界區域的概率降為零。另外兩個模擬表明,增加位移范圍(shift range)將逐漸增加圖中響應的范圍。分析表明32-shift的總熱圖更接近于測試對象的位置分布。因此空間感知抽樣策略有效地緩解了填充網絡對嚴格平移不變性的破壞。
為了避免對物體產生中心偏差,我們采用空間感知采樣策略,在訓練過程中,不再把正樣本塊放在圖像正中心,而是按照均勻分布的采樣方式讓目標在中心點附近進行偏移。用ResNet50主干訓練SiamRPN。

圖2.隨機平移對VOT數據集的影響。
如圖2所示,在VOT2018上 0-shift的EAO只有0.14,適當增加shift可以提高EAO(將算法的魯棒性和準確性結合起來的一個綜合指標)。Shift=64時EAO最高。
3.2 基于ResNet的孿生網絡跟蹤算法
基于以上分析,我們消除了對中心位置的學習偏差,任何現成的網絡(如MobileNet,ResNet)都可以用于視覺跟蹤。此外,還可以自適應地構造網絡拓撲結構,揭示深度網絡的視覺跟蹤性能。
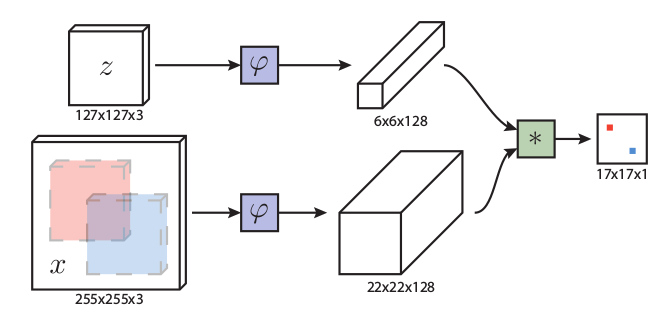
在本小節中,我們將討論如何將深度網絡傳輸到我們的跟蹤算法中,實驗主要集中在ResNet-50 。原來的ResNet有32 pix的大stride,不適合密集的孿生網絡預測。如圖3所示,我們通過修改conv4和conv5塊以獲得單位空間步幅,將后兩個塊的有效步幅從16像素和32像素減少到8像素,并通過擴大卷積增加其感受野。在每個塊輸出端附加一個額外的1×1卷積層,將通道減少到256。

圖3.我們提出的框架的插圖。給定目標模板和搜索區域,網絡通過融合多個SiamRPN塊的輸出來輸出密集預測。每個SiamRPN塊都顯示在右側。
由于所有層的填充都保持不變,模板特征的空間大小增加到15,這給相關模塊帶來了沉重的計算負擔。因此,我們裁剪中心的7×7區域作為模板特征,其中每個特征單元仍然可以捕獲整個目標區域。
在SiamRPN的基礎上,我們將互相關層(cross correlation layers)和全卷積層組合成頭模塊(head module) 用于計算分類分數(用S表示)和邊界框回歸器(用B表示)的頭模塊。SiameseRPN塊用P表示。此外可以微調ResNet將提高性能,通過將ResNet提取器的學習速率設置為比RPN小10倍可以更好的用于跟蹤任務。與傳統的孿生方法不同,深層網絡的參數以端到端的方式進行聯合訓練。這是第一個在深度孿生網絡(>20層)上實現端到端學習的視覺跟蹤算法。
3.3 分層聚合
利用像ResNet 50這樣的深層網絡,可以聚合不同的深度層。直觀地說,視覺跟蹤需要豐富的表示,從低到高,從小到大,從細到粗的分辨率。即使在卷積網絡中有深度的特征,單獨的層是不夠的。復合和聚合這些特征可以提高識別和定位。
在以前的文獻中,僅使用像AlexNet這樣的淺層網絡,多層特性不能提供多元的特征表示。然而,考慮到感受野的變化很大,ResNet中的不同層更有意義。淺層特征主要集中在顏色、形狀等低級信息上,對于定位是必不可少的,而缺乏語義信息;深層特征具有豐富的語義信息,在運動模糊、大變形等挑戰場景中有利于定位。我們假設使用這種豐富的層次信息對于跟蹤任務是有幫助的。
在我們的網絡中,多分支特征被提取出來共同推斷目標定位。對于ResNet 50,我們探索從 后三個殘差模塊(residual blocks)中提取的多級特性,以進行分層聚合。我們將這些輸出特征分別稱為F3(z)、F4(z) 和F5(z)。如圖3所示,conv3、 conv4、conv5的輸出分別輸入三個SiamRPN模塊。由于三個RPN模塊的輸出尺寸具有相同的空間分辨率,因此直接在RPN輸出上采用加權求和。加權融合層結合了所有的輸出。
S_{all}=\\sum^5_{l=3}\\alpha_i×S_l,B_{all}=\\sum^5_{l=3}\\beta×B_l
S——分類,B——回歸。

圖4 不同互相關層的圖示。(a)交叉相關(XCorr)層預測目標模板和搜索區域之間的單通道相似度圖。(b)向上通道互相關(UP-XCorr)層通過在SiamRPN中將一個具有多個獨立XCorr層的重卷積層級聯而輸出多通道相關特征。(c)深度相關(DW-XCorr)層預測模板和搜索塊之間的多通道相關特征。
組合權重被分開用于分類和回歸,因為它們的域是不同的。權重與網絡一起進行端到端優化離線。與以前的論文相比,我們的方法沒有明確地結合卷積特征,而是分別學習分類器和回歸。請注意,隨著骨干網絡的深度顯著增加,我們可以從視覺語義層次結構的充分多樣性中獲得實質性效果。
3.4 深度交叉相關
互相關模塊是嵌入兩個分支信息的核心操作。SiamFC 利用交叉相關層獲得目標定位的單通道響應圖。在SiamRPN 中,通過添加巨大的卷積層來擴展通道(UP-XCorr),交叉相關被擴展為嵌入更高級別的信息,例如anchors。巨大的up-channel模塊嚴重影響參數分布的不平衡(即RPN模塊包含20M參數,而特征提取器在SiamRPN中僅包含4M參數),這使得SiamRPN中的訓練優化變得困難。
在本小節中,我們提出了一個輕量級互相關層,名為Depth wise Cross Correlation(DW-XCorr),以實現有效的信息關聯。DW-XCorr層包含的參數比SiamRPN中使用的UP-XCorr少10 倍,而性能卻很高。

圖5. conv4中深度相關輸出的通道。conv4中共有256個通道,但是在跟蹤過程中只有少數通道具有高響應。因此我們選擇第148,222,226通道作為演示,圖中為第2,第3,第4行。第一行包含來自OTB數據集的六個對應搜索區域。不同的通道代表不同的語義,第148通道對汽車有很高的響應,而對人和人臉的反應很低。第222和第226通道分別對人和面部有很高的反應。
為實現此目的,采用conv-bn塊來調整每個殘差模塊(residual blocks)的特征以適應跟蹤任務。至關重要的是,bb的預測和基于anchor的分類都是不對稱的,這與SiamFC不同(見第3.1節)。為了對差異進行編碼,模板分支和搜索分支傳遞兩個非共享卷積層。然后,具有相同數量的通道的兩個特征圖按通道進行相關操作。附加另一個conv-bn-relu塊以融合不同的通道輸出。然后,附加用于分類或回歸輸出的最后一個卷積層。通過將互相關替換為深度相關,我們可以大大降低計算成本和內存使用。通過這種方式,模板和搜索分支上的參數數量得到平衡,從而使訓練過程更加穩定。
此外,有趣的現象如圖5所示。同一類別中的對象在相同的通道上具有高響應(第148通道中的車,第222通道中的人,以及第226通道中的人),而其余通道的響應被抑制。由于深度互相關產生的通道方式特征幾乎正交并且每個通道代表一些語義信息,因此可以理解該屬性。我們還使用上通道互相關分析熱圖,并且響應圖的解釋性較差。
4.實驗結果
4.1訓練集及評估
訓練
我們的架構的骨干網絡在ImageNet 上進行了預訓練,用于圖像標記,已經證明這是對其他任務的非常好的初始化。我們在COCO,ImageNet DET,ImageNet VID和YouTube-Bounding-Boxes數據集的訓練集上訓練網絡,并學習如何測量視覺跟蹤的一般對象之間相似性的一般概念。在訓練和測試中,我們使用單比例圖像,其中127個像素用于模板區域,255個像素用于搜索區域。
評估
我們專注于OTB2015 [46],VOT2018 [21]和UAV123 [31]上的短時單目標跟蹤。我們使用VOT2018-LT [21]來評估長時跟蹤任務。在長時跟蹤中,物體可能長時間離開視野或完全遮擋,這比短期跟蹤更具挑戰性。我們還分析了我們的方法在LaSOT [10]和TrackingNet [30]上的實驗,這兩個是最近才出現的單一目標跟蹤的benchmarks。
4.2 實施細節
網絡結構
在實驗中,我們按照DaSiamRPN進行訓練和設置。我們將兩個同級卷積層連接到減少步幅(stride-reduced)的ResNet-50(第3.2節),用5個anchors執行分類和邊界框回歸。將三個隨機初始化的1×1卷積層連接到conv3,conv4,conv5,以將特征尺寸減小到256。
優化
SiamRPN ++采用隨機梯度下降(SGD)進行訓練。我們使用8個GPU的同步SGD,每個小批量共128對(每個GPU 16對),需要12小時才能收斂。我們使用前5個時間段的0.001的預熱學習率來訓練RPN分支。在過去的15個時間段中,整個網絡都是端到端的訓練,學習率從0.005到0.0005呈指數衰減。使用0.0005的重量衰減和0.9的動量。訓練損失是分類損失和回歸的標準平滑L1損失的總和。
4.3 對比實驗
主干架構
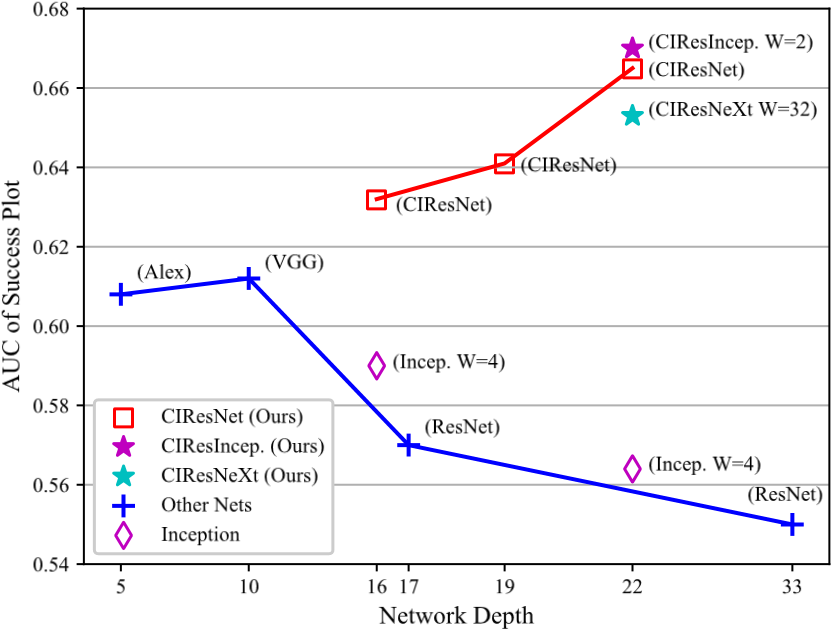
特征提取器的選擇至關重要,因為參數的數量和層的類型直接影響跟蹤器的內存消耗,速度和性能。我們比較了視覺跟蹤的不同網絡架構。圖6顯示了使用AlexNet,ResNet-18,ResNet-34,ResNet-50和MobileNet-v2作為主干的性能。我們畫出了在OTB2015上成功曲線的曲線下面積(AUC)相對于ImageNet的top1精度的性能。我們觀察到我們的SiamRPN ++可以從更深入的ConvNet中受益。
逐層特征聚合
為了研究分層特征聚合的影響,首先我們在ResNet-50上訓練三個具有單個RPN的變體。單獨使用conv4可以在EAO中獲得0.374的良好性能,而更深的層和更淺的層則會有4%的下降。通過組合兩個分支,conv4 和conv5獲得了改進,但是在其他兩個組合上沒有觀察到改善。盡管如此,魯棒性也增加了10%,這說明我們的追蹤器仍有改進的余地。在匯總所有三個層之后,準確性和穩健性都穩步提高,VOT和OTB的增益在3.1%和1.3%之間。總體而言,逐層特征聚合在VOT2018上產生0.414的 EAO分數,比單層基線高4.0%。
5.結論
在本文中,我們提出了一個統一的框架,稱為SiamRPN ++,用于端到端訓練深度連體網絡進行視覺跟蹤。我們展示了如何在孿生跟蹤器上訓練深度網絡的理論和實證證據。我們的網絡由多層聚合模塊組成,該模塊組合連接層次以聚合不同級別的表示和深度相關層,這允許我們的網絡降低計算成本和冗余參數,同時還導致更好的收斂。使用SiamRPN ++,我們實時獲得了VOT2018上先進的結果,顯示了SiamRPN ++的有效性。SiamRPN ++還在La-SOT和TrackingNet等大型數據集上實現了先進的結果,顯示了它的泛化性。
學習更多編程知識,請關注我的公眾號:

-
神經網絡
+關注
關注
42文章
4771瀏覽量
100719 -
視覺跟蹤
+關注
關注
0文章
11瀏覽量
8796
發布評論請先 登錄
相關推薦
雙目立體視覺原理大揭秘(二)
基于立體視覺的變形測量
雙目立體視覺的運用
雙目立體視覺在嵌入式中有何應用
基于預測的立體視覺_力反饋研究
自動跟蹤對稱電源:Tracking Regulated Po
FM跟蹤發射器FM Tracking Transmitter
圖像處理基本算法-立體視覺
基于信息熵的級聯Siamese網絡目標跟蹤方法
SiamFC:用于目標跟蹤的全卷積孿生網絡 fully-convolutional siamese networks for object tracking
SiamRPN:High Performance Visual Tracking with Siamese Region Proposal Network 孿生網絡
SA-Siam:用于實時目標跟蹤的孿生網絡A Twofold Siamese Network for Real-Time Object Tracking
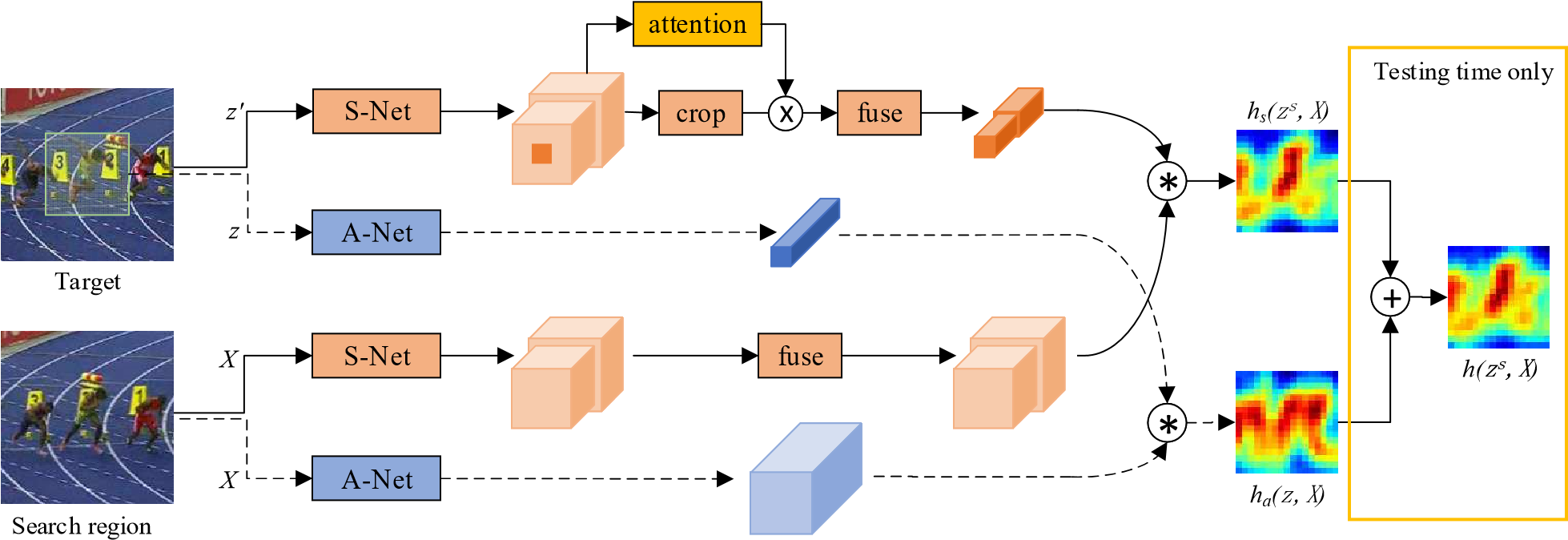
DW-Siam:Deeper and Wider Siamese Networks for Real-Time Visual Tracking 更寬更深的孿生網絡
傳輸豐富的特征層次結構以實現穩健的視覺跟蹤Transferring Rich Feature Hierarchies for Robust Visual Tracking






 工商網監
工商網監
評論