


前言
作為后端開發(fā),我們經常需要設計數(shù)據(jù)庫表。整理了21個設計MySQL表的經驗準則,分享給大家,大家看完一定會有幫助的。
1.命名規(guī)范
數(shù)據(jù)庫表名、字段名、索引名等都需要命名規(guī)范,可讀性高(一般要求用英文),讓別人一看命名,就知道這個字段表示什么意思。
比如一個表的賬號字段,反例如下:
acc_no,1_acc_no,zhanghao
正例:
account_no,account_number
- 表名、字段名必須使用小寫字母或者數(shù)字,禁止使用數(shù)字開頭,禁止使用拼音,并且一般不使用英文縮寫。
-
主鍵索引名為
pk_字段名;唯一索引名為uk_字段名;普通索引名則為idx_字段名。
2.選擇合適的字段類型
設計表時,我們需要選擇合適的字段類型,比如:
-
盡可能選擇存儲空間小的字段類型,就好像數(shù)字類型的,從
tinyint、smallint、int、bigint從左往右開始選擇 -
小數(shù)類型如金額,則選擇
decimal,禁止使用float和double。 -
如果存儲的字符串長度幾乎相等,使用
char定長字符串類型。 -
varchar是可變長字符串,不預先分配存儲空間,長度不要超過5000。 -
如果存儲的值太大,建議字段類型修改為
text,同時抽出單獨一張表,用主鍵與之對應。 -
同一表中,所有
varchar字段的長度加起來,不能大于65535. 如果有這樣的需求,請使用TEXT/LONGTEXT類型。
3. 主鍵設計要合理
主鍵設計的話,最好不要與業(yè)務邏輯有所關聯(lián)。有些業(yè)務上的字段,比如身份證,雖然是唯一的,一些開發(fā)者喜歡用它來做主鍵,但是不是很建議哈。主鍵最好是毫無意義的一串獨立不重復的數(shù)字,比如UUID,又或者Auto_increment自增的主鍵,或者是雪花算法生成的主鍵等等;
4. 選擇合適的字段長度
先問大家一個問題,大家知道數(shù)據(jù)庫字段長度表示字符長度還是字節(jié)長度嘛?
其實在mysql中,
varchar和char類型表示字符長度,而其他類型表示的長度都表示字節(jié)長度。比如char(10)表示字符長度是10,而bigint(4)表示顯示長度是4個字節(jié),但是因為bigint實際長度是8個字節(jié),所以bigint(4)的實際長度就是8個字節(jié)。
我們在設計表的時候,需要充分考慮一個字段的長度,比如一個用戶名字段(它的長度5~20個字符),你覺得應該設置多長呢?可以考慮設置為 username varchar(32)。字段長度一般設置為2的冪哈(也就是2的n次方)。’;
5,優(yōu)先考慮邏輯刪除,而不是物理刪除
什么是物理刪除?什么是邏輯刪除?
- 物理刪除:把數(shù)據(jù)從硬盤中刪除,可釋放存儲空間
-
邏輯刪除:給數(shù)據(jù)添加一個字段,比如
is_deleted,以標記該數(shù)據(jù)已經邏輯刪除。
物理刪除就是執(zhí)行delete語句,如刪除account_no =‘666’的賬戶信息SQL如下:
deletefromaccount_info_tabwhereaccount_no='666';
邏輯刪除呢,就是這樣:
updateaccount_info_tabsetis_deleted=1whereaccount_no='666';
為什么推薦用邏輯刪除,不推薦物理刪除呢?
- 為什么不推薦使用物理刪除,因為恢復數(shù)據(jù)很困難
- 物理刪除會使自增主鍵不再連續(xù)
- 核心業(yè)務表 的數(shù)據(jù)不建議做物理刪除,只適合做狀態(tài)變更。
6. 每個表都需要添加這幾個通用字段如主鍵、create_time、modifed_time等
表必備一般來說,或具備這幾個字段:
- id:主鍵,一個表必須得有主鍵,必須
- create_time:創(chuàng)建時間,必須
- modifed_time/update_time: 修改時間,必須,更新記錄時,需要更新它
- version : 數(shù)據(jù)記錄的版本號,用于樂觀鎖,非必須
- remark :數(shù)據(jù)記錄備注,非必須
- modified_by :修改人,非必須
- creator :創(chuàng)建人,非必須
7. 一張表的字段不宜過多
我們建表的時候,要牢記,一張表的字段不宜過多哈,一般盡量不要超過20個字段哈。筆者記得上個公司,有伙伴設計開戶表,加了五十多個字段。。。
如果一張表的字段過多,表中保存的數(shù)據(jù)可能就會很大,查詢效率就會很低。因此,一張表不要設計太多字段哈,如果業(yè)務需求,實在需要很多字段,可以把一張大的表,拆成多張小的表,它們的主鍵相同即可。
當表的字段數(shù)非常多時,可以將表分成兩張表,一張作為條件查詢表,一張作為詳細內容表 (主要是為了性能考慮)。
8. 盡可能使用not null定義字段
如果沒有特殊的理由, 一般都建議將字段定義為 NOT NULL 。
為什么呢?
-
首先,
NOT NULL可以防止出現(xiàn)空指針問題。 -
其次,
NULL值存儲也需要額外的空間的,它也會導致比較運算更為復雜,使優(yōu)化器難以優(yōu)化SQL。 -
NULL值有可能會導致索引失效 -
如果將字段默認設置成一個空字符串或常量值并沒有什么不同,且都不會影響到應用邏輯, 那就可以將這個字段設置為
NOT NULL。
9. 設計表時,評估哪些字段需要加索引
首先,評估你的表數(shù)據(jù)量。如果你的表數(shù)據(jù)量只有一百幾十行,就沒有必要加索引。否則設計表的時候,如果有查詢條件的字段,一般就需要建立索引。但是索引也不能濫用:
-
索引也不要建得太多,一般單表索引個數(shù)不要超過
5個。因為創(chuàng)建過多的索引,會降低寫得速度。 - 區(qū)分度不高的字段,不能加索引,如性別等
- 索引創(chuàng)建完后,還是要注意避免索引失效的情況,如使用mysql的內置函數(shù),會導致索引失效的
- 索引過多的話,可以通過聯(lián)合索引的話方式來優(yōu)化。然后的話,索引還有一些規(guī)則,如覆蓋索引,最左匹配原則等等。。
假設你新建一張用戶表,如下:
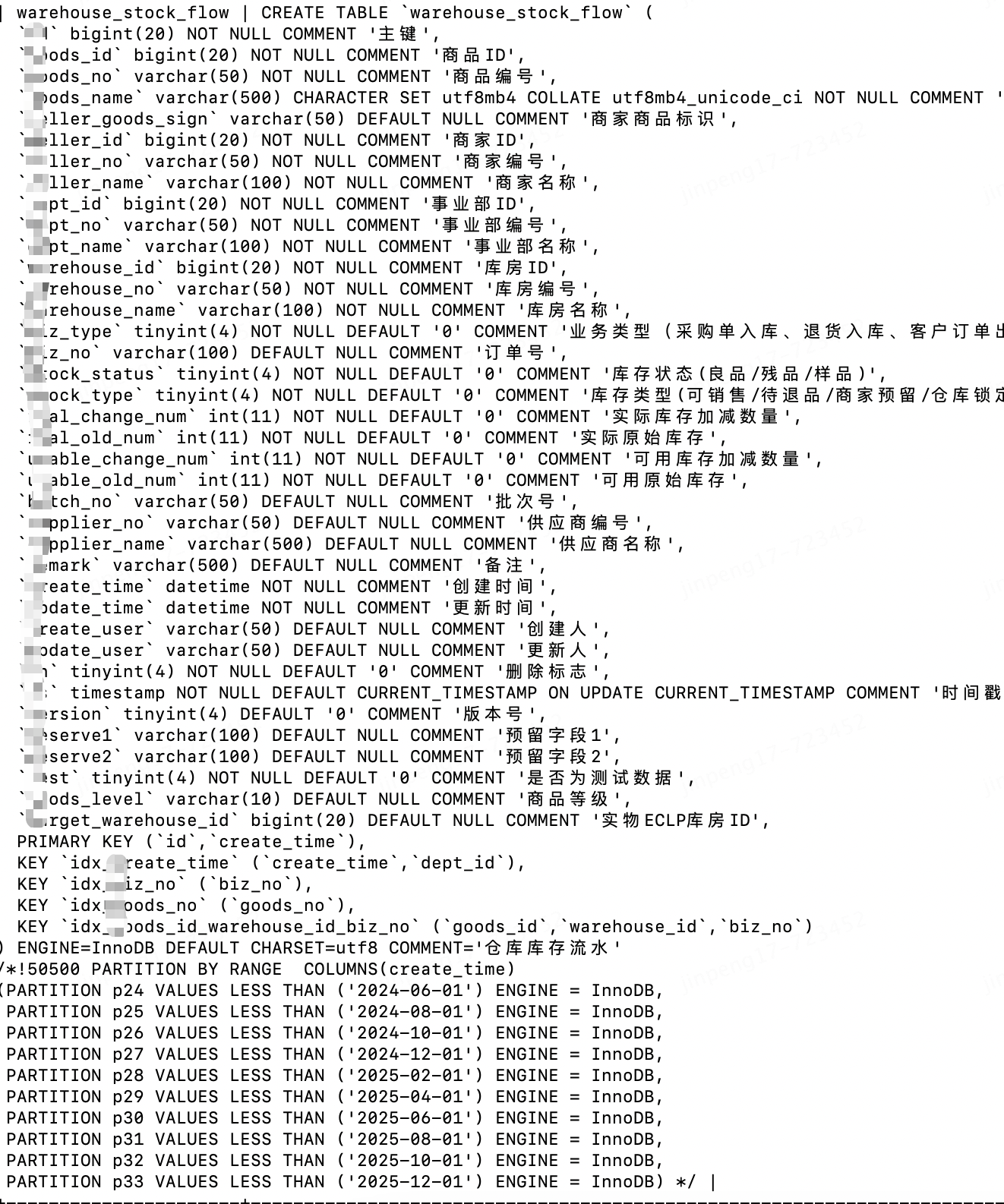
CREATETABLEuser_info_tab(
`id`int(11)NOTNULLAUTO_INCREMENT,
`user_id`int(11)NOTNULL,
`age`int(11)DEFAULTNULL,
`name`varchar(255)NOTNULL,
`create_time`datetimeNOTNULL,
`modifed_time`datetimeNOTNULL,
PRIMARYKEY(`id`)
)ENGINE=InnoDBDEFAULTCHARSET=utf8;
對于這張表,很可能會有根據(jù)user_id或者name查詢用戶信息,并且,user_id是唯一的。因此,你是可以給user_id加上唯一索引,name加上普通索引。
CREATETABLEuser_info_tab(
`id`int(11)NOTNULLAUTO_INCREMENT,
`user_id`int(11)NOTNULL,
`age`int(11)DEFAULTNULL,
`name`varchar(255)NOTNULL,
`create_time`datetimeNOTNULL,
`modifed_time`datetimeNOTNULL,
PRIMARYKEY(`id`),
KEY`idx_name`(`name`)USINGBTREE,
UNIQUEKEYun_user_id(user_id)
)ENGINE=InnoDBDEFAULTCHARSET=utf8;
10. 不需要嚴格遵守 3NF,通過業(yè)務字段冗余來減少表關聯(lián)
什么是數(shù)據(jù)庫三范式(3NF),大家是否還有印象嗎?
- 第一范式:對屬性的原子性,要求屬性具有原子性,不可再分解;
- 第二范式:對記錄的唯一性,要求記錄有唯一標識,即實體的唯一性,即不存在部分依賴;
- 第三方式:對字段的冗余性,要求任何字段不能由其他字段派生出來,它要求字段沒有冗余,即不存在傳遞依賴;
我們設計表及其字段之間的關系, 應盡量滿足第三范式。但是有時候,可以適當冗余,來提高效率。比如以下這張表
| 商品名稱 | 商品型號 | 單價 | 數(shù)量 | 總金額 |
|---|---|---|---|---|
| 手機 | 華為 | 8000 | 5 | 40000 |
以上這張存放商品信息的基本表。總金額這個字段的存在,表明該表的設計不滿足第三范式,因為總金額可以由單價*數(shù)量得到,說明總金額是冗余字段。但是,增加總金額這個冗余字段,可以提高查詢統(tǒng)計的速度,這就是以空間換時間的作法。
當然,這只是個小例子哈,大家開發(fā)設計的時候,要結合具體業(yè)務分析哈。
11. 避免使用MySQL保留字
如果庫名、表名、字段名等屬性含有保留字時,SQL語句必須用反引號來引用屬性名稱,這將使得SQL語句書寫、SHELL腳本中變量的轉義等變得非常復雜。
因此,我們一般避免使用MySQL保留字,如select、interval、desc等等
12. 不搞外鍵關聯(lián),一般都在代碼維護
什么是外鍵呢?
外鍵,也叫
FOREIGN KEY,它是用于將兩個表連接在一起的鍵。FOREIGN KEY是一個表中的一個字段(或字段集合),它引用另一個表中的PRIMARY KEY。它是用來保證數(shù)據(jù)的一致性和完整性的。
阿里的Java規(guī)范也有這么一條:
【強制】不得使用外鍵與級聯(lián),一切外鍵概念必須在應用層解決。
我們?yōu)槭裁床煌扑]使用外鍵呢?
- 使用外鍵存在性能問題、并發(fā)死鎖問題、使用起來不方便等等。每次做
DELETE或者UPDATE都必須考慮外鍵約束,會導致開發(fā)的時候很難受,測試數(shù)據(jù)造數(shù)據(jù)也不方便。- 還有一個場景不能使用外鍵,就是分庫分表。
13. 一般都選擇INNODB存儲引擎
建表是需要選擇存儲引擎的,我們一般都選擇INNODB存儲引擎,除非讀寫比率小于1%, 才考慮使用MyISAM 。
有些小伙伴可能會有疑惑,不是還有MEMORY等其他存儲引擎嗎?什么時候使用它呢?其實其他存儲引擎一般除了都建議在DBA的指導下使用。
我們來復習一下這MySQL這三種存儲引擎的對比區(qū)別吧:
| 特性 | INNODB | MyISAM | MEMORY |
|---|---|---|---|
| 事務安全 | 支持 | 無 | 無 |
| 存儲限制 | 64TB | 有 | 有 |
| 空間使用 | 高 | 低 | 低 |
| 內存使用 | 高 | 低 | 高 |
| 插入數(shù)據(jù)速度 | 低 | 高 | 高 |
| 是否支持外鍵 | 支持 | 無 | 無 |
14. 選擇合適統(tǒng)一的字符集。
數(shù)據(jù)庫庫、表、開發(fā)程序等都需要統(tǒng)一字符集,通常中英文環(huán)境用utf8。
MySQL支持的字符集有utf8、utf8mb4、GBK、latin1等。
- utf8:支持中英文混合場景,國際通過,3個字節(jié)長度
- utf8mb4: 完全兼容utf8,4個字節(jié)長度,一般存儲emoji表情需要用到它。
- GBK :支持中文,但是不支持國際通用字符集,2個字節(jié)長度
- latin1:MySQL默認字符集,1個字節(jié)長度
15. 如果你的數(shù)據(jù)庫字段是枚舉類型的,需要在comment注釋清楚
如果你設計的數(shù)據(jù)庫字段是枚舉類型的話,就需要在comment后面注釋清楚每個枚舉的意思,以便于維護
正例如下:
`session_status`varchar(2)COLLATEutf8_binNOTNULLCOMMENT'session授權態(tài)00:在線-授權態(tài)有效01:下線-授權態(tài)失效02:下線-主動退出03:下線-在別處被登錄'
反例:
`session_status`varchar(2)COLLATEutf8_binNOTNULLCOMMENT'session授權態(tài)'
并且,如果你的枚舉類型在未來的版本有增加修改的話,也需要同時維護到comment后面。
16.時間的類型選擇
我們設計表的時候,一般都需要加通用時間的字段,如create_time、modified_time等等。那對于時間的類型,我們該如何選擇呢?
對于MySQL來說,主要有date、datetime、time、timestamp 和 year。
-
date :表示的日期值, 格式
yyyy-mm-dd,范圍1000-01-01 到 9999-12-31,3字節(jié) -
time :表示的時間值,格式
hhss,范圍-83859 到 83859,3字節(jié) -
datetime:表示的日期時間值,格式
yyyy-mm-dd hhss,范圍1000-01-01 0000到9999-12-31 2359```,8字節(jié),跟時區(qū)無關 -
timestamp:表示的時間戳值,格式為
yyyymmddhhmmss,范圍1970-01-01 0001到2038-01-19 0307,4字節(jié),跟時區(qū)有關 -
year:年份值,格式為
yyyy。范圍1901到2155,1字節(jié)
推薦優(yōu)先使用datetime類型來保存日期和時間,因為存儲范圍更大,且跟時區(qū)無關。
17. 不建議使用Stored procedure (包括存儲過程,觸發(fā)器) 。
什么是存儲過程
已預編譯為一個可執(zhí)行過程的一個或多個SQL語句。
什么是觸發(fā)器
觸發(fā)器,指一段代碼,當觸發(fā)某個事件時,自動執(zhí)行這些代碼。使用場景:
- 可以通過數(shù)據(jù)庫中的相關表實現(xiàn)級聯(lián)更改。
- 實時監(jiān)控某張表中的某個字段的更改而需要做出相應的處理。
- 例如可以生成某些業(yè)務的編號。
- 注意不要濫用,否則會造成數(shù)據(jù)庫及應用程序的維護困難。
對于MYSQL來說,存儲過程、觸發(fā)器等還不是很成熟, 并沒有完善的出錯記錄處理,不建議使用。
18. 1:N 關系的設計
日常開發(fā)中,1對多的關系應該是非常常見的。比如一個班級有多個學生,一個部門有多個員工等等。這種的建表原則就是:在從表(N的這一方)創(chuàng)建一個字段,以字段作為外鍵指向主表(1的這一方)的主鍵。示意圖如下:
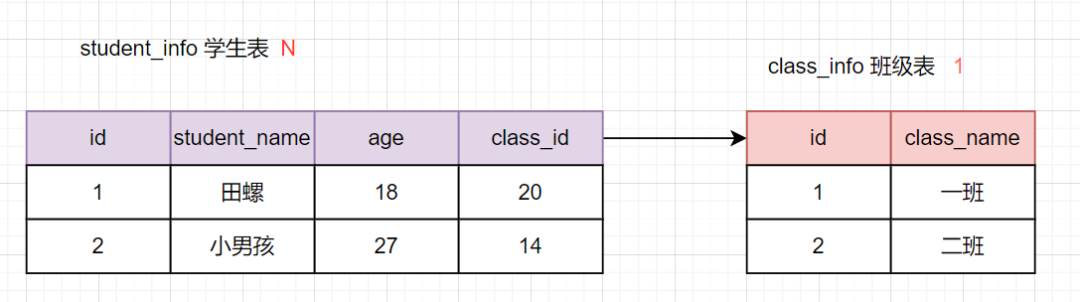
學生表是多(N)的一方,會有個字段class_id保存班級表的主鍵。當然,一班不加外鍵約束哈,只是單純保存這個關系而已。
有時候兩張表存在N:N關系時,我們應該消除這種關系。通過增加第三張表,把N:N修改為兩個 1:N。比如圖書和讀者,是一個典型的多對多的關系。一本書可以被多個讀者借,一個讀者又可以借多本書。我們就可以設計一個借書表,包含圖書表的主鍵,以及讀者的主鍵,以及借還標記等字段。
19. 大字段
設計表的時候,我們尤其需要關注一些大字段,即占用較多存儲空間的字段。比如用來記錄用戶評論的字段,又或者記錄博客內容的字段,又或者保存合同數(shù)據(jù)的字段。如果直接把表字段設計成text類型的話,就會浪費存儲空間,查詢效率也不好。
在MySQl中,這種方式保存的設計方案,其實是不太合理的。這種非常大的數(shù)據(jù),可以保存到mongodb中,然后,在業(yè)務表保存對應mongodb的id即可。
這種設計思想類似于,我們表字段保存圖片時,為什么不是保存圖片內容,而是直接保存圖片url即可。
20. 考慮是否需要分庫分表
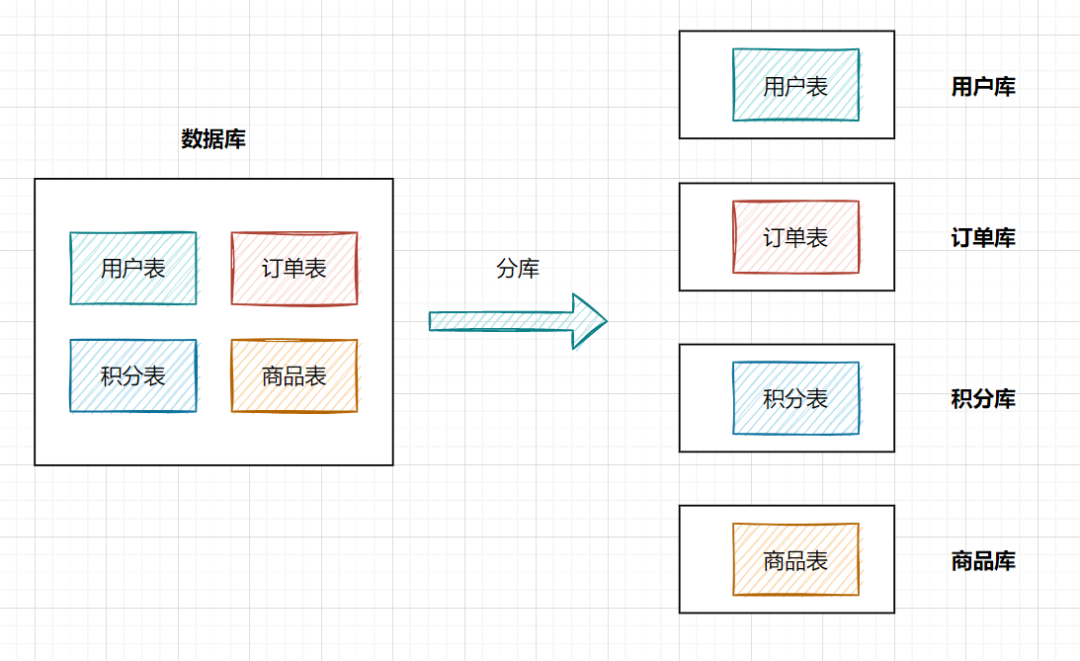
什么是分庫分表呢?
- 分庫:就是一個數(shù)據(jù)庫分成多個數(shù)據(jù)庫,部署到不同機器。
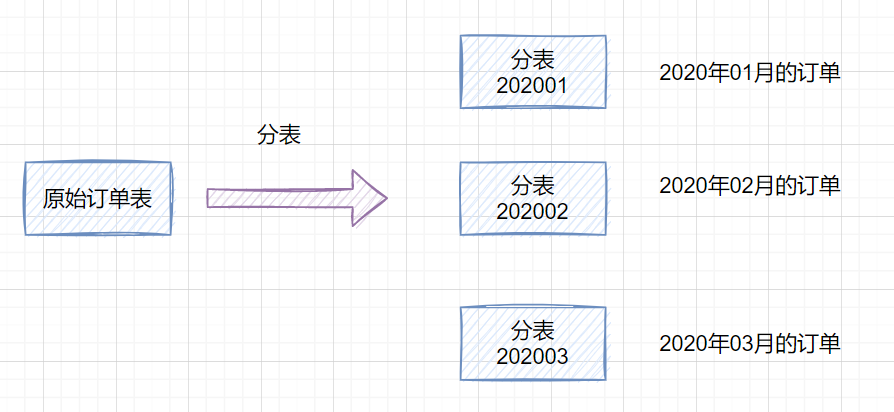
- 分表:就是一個數(shù)據(jù)庫表分成多個表。
我們在設計表的時候,其實可以提前估算一下,是否需要做分庫分表。比如一些用戶信息,未來可能數(shù)據(jù)量到達百萬設置千萬的話,就可以提前考慮分庫分表。
為什么需要分庫分表: 數(shù)據(jù)量太大的話,SQL的查詢就會變慢。如果一個查詢SQL沒命中索引,千百萬數(shù)據(jù)量級別的表可能會拖垮整個數(shù)據(jù)庫。即使SQL命中了索引,如果表的數(shù)據(jù)量超過一千萬的話,查詢也是會明顯變慢的。這是因為索引一般是B+樹結構,數(shù)據(jù)千萬級別的話,B+樹的高度會增高,查詢就變慢啦。
分庫分表主要有水平拆分、垂直拆分的說法,拆分策略有range范圍、hash取模。而分庫分表主要有這些問題:
- 事務問題
- 跨庫關聯(lián)
- 排序問題
- 分頁問題
- 分布式ID
21. sqL 編寫的一些優(yōu)化經驗
最后的話,跟大家聊來一些寫SQL的經驗吧:
-
查詢SQL盡量不要使用
select *,而是select具體字段 -
如果知道查詢結果只有一條或者只要最大/最小一條記錄,建議用
limit 1 -
應盡量避免在
where子句中使用or來連接條件 -
注意優(yōu)化
limit深分頁問題 -
使用
where條件限定要查詢的數(shù)據(jù),避免返回多余的行 -
盡量避免在索引列上使用
mysql的內置函數(shù) -
應盡量避免在
where子句中對字段進行表達式操作 -
應盡量避免在
where子句中使用!=或<>操作符 - 使用聯(lián)合索引時,注意索引列的順序,一般遵循最左匹配原則。
-
對查詢進行優(yōu)化,應考慮在
where 及 order by涉及的列上建立索引 - 如果插入數(shù)據(jù)過多,考慮批量插入
- 在適當?shù)臅r候,使用覆蓋索引
- 使用explain 分析你SQL的計劃
審核編輯 :李倩
-
SQL
+關注
關注
1文章
783瀏覽量
45246 -
數(shù)據(jù)庫
+關注
關注
7文章
3937瀏覽量
66374 -
MySQL
+關注
關注
1文章
866瀏覽量
28000
原文標題:21 個 MySQL 表設計的經驗準則
文章出處:【微信號:DBDevs,微信公眾號:數(shù)據(jù)分析與開發(fā)】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
MySQL數(shù)據(jù)庫是什么
從Delphi、C++ Builder和Lazarus連接到MySQL數(shù)據(jù)庫
使用插件將Excel連接到MySQL/MariaDB
MySQL數(shù)據(jù)庫的安裝
華為云 Flexus X 實例評測使用體驗——MySQL 安裝全過程 +MySQL 讀寫速度測試
數(shù)據(jù)庫數(shù)據(jù)恢復—Mysql數(shù)據(jù)庫表記錄丟失的數(shù)據(jù)恢復流程

MySQL還能跟上PostgreSQL的步伐嗎

MySQL編碼機制原理
適用于MySQL的dbForge架構比較
mysql磁盤碎片整理
Jtti:MySQL初始化操作如何設置root密碼

一文了解MySQL索引機制






 工商網監(jiān)
工商網監(jiān)

評論