") 無需實例或類級別3D模型的對新穎物體的6D姿態(tài)追蹤
無需實例或類級別3D模型的對新穎物體的6D姿態(tài)追蹤
摘要
大家好,今天為大家?guī)淼奈恼率荁undleTrack: 6D Pose Tracking for Novel Objectswithout Instance or Category-Level 3D Models 跟蹤RGBD視頻中物體的6D姿態(tài)對機器人操作很重要。然而,大多數(shù)先前的工作通常假設目標對象的CAD 模型,至少類別級別,可用于離線訓練或在線測試階段模板匹配。
這項工作提出BundleTrack,一個通用的新對象的 6D 姿態(tài)跟蹤框架,它不依賴于實例或類別級別的 3D 模型。
它結合了最新視頻分割和魯棒特征提取的深度學習,以及具有記憶功能的姿勢圖優(yōu)化實現(xiàn)時空一致性。
這使得它能進行長期、低漂移在各種具有挑戰(zhàn)性的場景下的6D姿態(tài)跟蹤,測試了包括重大遮擋和物體運動的場景。
在2個公開數(shù)據(jù)集上的大量實驗表明,BundleTrack顯著優(yōu)于最先進的類別級別6D 跟蹤或動態(tài)SLAM 方法。
比較時反對依賴于對象實例 CAD 的最新方法模型,盡管提出了可比的性能方法的信息需求減少。
一個高效的在 CUDA 中的實現(xiàn)提供了實時性能。整個框架運行速度達10Hz。


背景與貢獻
本文有以下貢獻:
1.一個全新的6D物體姿態(tài)算法,不需要實例或類級別的CAD模型用于訓練或測試階段。該算法可立即用于新穎物體的6D姿態(tài)跟蹤
2.在NOCS數(shù)據(jù)集上的創(chuàng)下全新記錄,將以往的表現(xiàn)從33.3%大幅度提升到87.4%。在YCBInEOAT數(shù)據(jù)集上也達到了跟目前基于CAD模型的領先方法se(3)-TrackNet相近的表現(xiàn)。特別值得注意的是,與以往state of art的6D物體姿態(tài)跟蹤方法相比,BundleTrack并不需要類級別的物體進行訓練,也不需要測試階段物體的CAD模型作模板匹配,減少了很多假設。
3.首次將具有記憶功能的位姿圖優(yōu)化引入6D物體姿態(tài)跟蹤。除了相鄰幀的匹配還能夠借助帶記憶功能的歷史幀解決特征匹配不足和跟蹤漂移問題。以MaskFusion為例的tracking-via-reconstruction方法經(jīng)常因為任何一幀微小錯誤的姿態(tài)估計進行錯誤的全局模型構建融合,進而繼續(xù)影響接下來的全局模型到觀測點云的匹配,造成不可逆轉的跟蹤漂移。而BundleTrack則不存在此類問題。
4.高效的CUDA編碼,使得本來計算量龐大的位姿優(yōu)化圖能在線實時運行,達到10Hz。足夠用于AR/VR,視覺反饋控制操縱,物體級SLAM或動態(tài)場景下的 SLAM等
問題設置
對于需要6D跟蹤的物體,該方法不需要任何類級別的CAD模型或者當前物體的CAD模型。所需要的輸入只有(1)RGBD視頻;(2)初始掩碼,用于指定需要跟蹤的物體。該掩碼可以通過多種途徑獲得,例如語義分割,3D點云分割聚類,平面移除等等。該方法就能輸出跟蹤物體在相機前相對初始的 6D姿態(tài)變換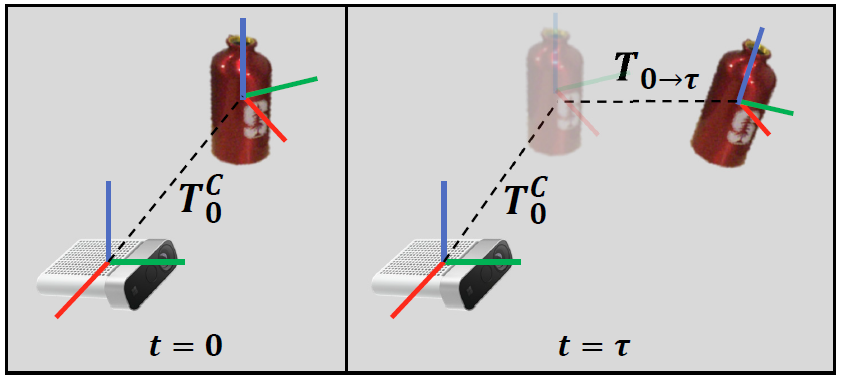
算法流程
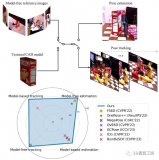
A. 方法總覽
當前觀察到的 RGB-D視頻流首先送到視頻分割模塊對目標物體提取ROI。分割后的圖片被裁剪、調整大小并發(fā)送到關鍵點檢測網(wǎng)絡來計算關鍵點和特征描述符。
一種數(shù)據(jù)關聯(lián)過程包括特征匹配和以 RANSAC 的方式進行修剪識別特征對應。基于這些特征匹配,當前幀與前一相鄰幀之間進行初步粗略匹配。
該比配可以用閉式求解,然后用于提供粗略兩個幀之間的轉換估計Tt~。在接下來的位姿圖優(yōu)化中,Tt~講用于初始化當前節(jié)點。為了確定位姿圖中的其余節(jié)點,我們從歷史保留的關鍵幀內存池中選擇不超過K個關鍵幀參與位姿圖優(yōu)化。選擇 K 而不用所有歷史幀是為了平衡效率與準確性權衡。
姿態(tài)圖邊包括稀疏特征和稠密點到平面的投影殘差,所有這些在 GPU 上并行計算。姿勢圖優(yōu)化步驟在線輸出當前時間戳優(yōu)化后姿態(tài)。通過檢查當前幀優(yōu)化后的姿態(tài)的視角,如果它來自新的視角,那么它將會存儲在內存池中,以備將來用作關鍵幀參與位姿圖優(yōu)化。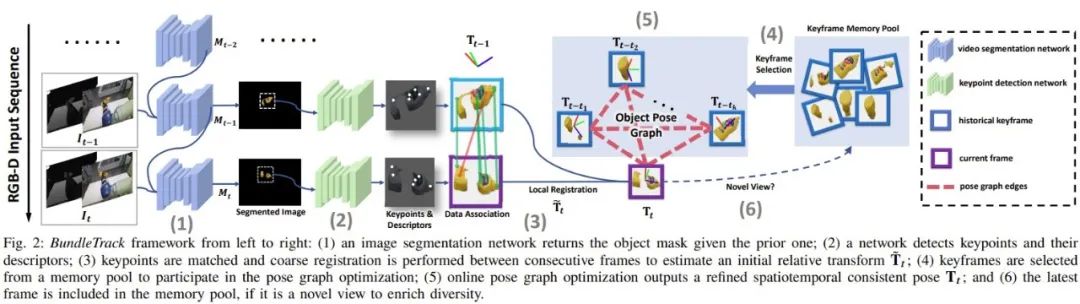
B.視頻分割
第一步是將對象的圖像區(qū)域從背景分割。先前的工作 MaskFusion 使用 Mask-RCNN 計算視頻每一幀中的對象掩碼。它對每個新幀獨立處理,效率較低并導致不連貫性。
為了避免這些限制,這項工作采用了現(xiàn)成的用于視頻對象分割的 transductive-VOS 網(wǎng)絡,只需要在Davis 2017和Youtube-VOS 數(shù)據(jù)集上預訓練,泛化到我們的測試場景,而不需要任何物體的CAD模型進行訓練。雖然當前的實現(xiàn)使用 transductive-VOS,本文所提出的整個框架不依賴于這個特定的網(wǎng)絡。
如果可以通過更簡單的方法計算對象掩碼意味著,例如在機械臂操縱場景下,利用前向運動學,計算機械臂的位置進行點云過濾操作場景,便可以替代視頻分割網(wǎng)絡模塊,更為簡單。
C. 特征點檢測,匹配和局部配準 局部匹配是在連續(xù)的當前幀和前一幀之間來計算初始粗略姿態(tài)估計 。
為此,在每個圖像上檢測到的關鍵點之間進行匹配用于6D姿態(tài)配準。不同于先前的工作 6PACK,6PACK依賴于在類別級別的 3D 模型上離線續(xù)聯(lián),學習固定數(shù)量的類別級語義關鍵點。
相反,本文中BundleTrack旨在提高泛化能力,而不是局限于某些實例或者類別。選擇 LF-Net進行特征點檢測是因為它令人滿意性能和推理速度之間的平衡。
它只需要對一般 2D 圖像進行訓練,例如此處使用的 ScanNet 數(shù)據(jù)集 ,并推廣到新的場景。該訓練過程不需要收集任何CAD模型,并且一旦訓練完成,在所有實驗中都不需要finetune。


主要結果
實驗在2個公開數(shù)據(jù)集上展現(xiàn)了優(yōu)越表現(xiàn)。NOCS是類級別的靜態(tài)桌面物體場景。YCBInEOAT是機器人操縱場景下的動態(tài)場景。值得注意的是,即使BundleTrack不需要任何CAD模型,反而遠超此前的state of art方法6PACK:從33.3%提升到87.4%。與實例級別的state of art方法se(3)-TrackNet相比,僅有微小的差距。
以下曲線圖反映了跟蹤漂移。BundleTrack的6D姿態(tài)跟蹤錯誤從視頻開始到結束幾乎不變。(左)旋轉錯誤隨時間變化。(右)平移錯誤隨時間變化。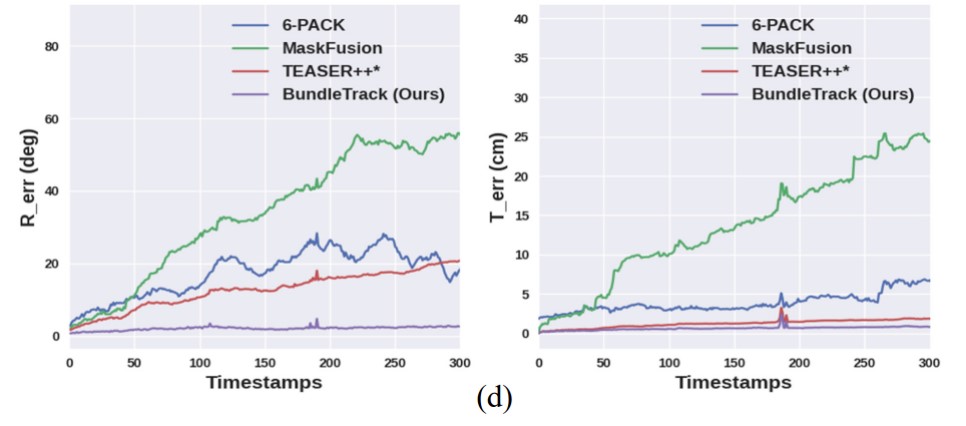
審核編輯:劉清
-
CAD
+關注
關注
17文章
1090瀏覽量
72450 -
SLAM
+關注
關注
23文章
423瀏覽量
31822 -
CUDA
+關注
關注
0文章
121瀏覽量
13620
原文標題:論文精讀|BundleTrack:無需實例或類級別3D模型的對新穎物體的6D姿態(tài)追蹤
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
Altium designer 6(AD6)建立器件簡易 3D 模型的方法
3D模擬飛機飛行串口
浩辰3D軟件入門教程:如何比較3D模型
AD的3D模型繪制功能介紹
浩辰3D的「3D打印」你會用嗎?3D打印教程
細數(shù)世界最新穎的幾大3D打印技術
一種基于深度神經(jīng)網(wǎng)絡的迭代6D姿態(tài)匹配的新方法
3D姿態(tài)估計 時序卷積+半監(jiān)督訓練
英偉達提出了同時對未知物體進行6D追蹤和3D重建的方法

基于未知物體進行6D追蹤和3D重建的方法

基于深度學習的3D點云實例分割方法
一個用于6D姿態(tài)估計和跟蹤的統(tǒng)一基礎模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論