 人工智能會改變EDA嗎?
人工智能會改變EDA嗎?
近年來,人工智能(AI)與機器學習 (ML) 已經在諸多應用領域取得了突破。而在傳統的半導體領域,研究者們也探索了基于機器學習的芯片設計新方法。這些新算法通常會最先反映在芯片設計工具上,也就是我們常說的EDA工具。因此,這一研究方向通常可以被稱為ML for hardware design,或者ML for EDA(嚴格來說前者的范圍更大一些)。有時也稱做智能化的EDA算法或者智能的IC設計方法。 本文將介紹ML for EDA這一EDA領域的熱門研究方向。這一方向涉及到機器學習,數據結構與算法,電路設計與制造等基礎知識,是典型的交叉研究方向。我們將從EDA的背景知識開始,介紹什么是ML for EDA, 為什么我們研究ML for EDA,該研究方向早期一些代表性的工作,當前商業化的進程,其他相關的研究方向,以及ML for EDA可能面臨的挑戰。
01什么是EDA? – EDA與芯片設計基礎
芯片在我們的生活中無處不在。芯片的設計與實現涉及一個復雜的流程。以數字芯片為例,假設設計團隊從已經完成的Verilog/VHDL代碼出發,標準設計流程至少還要包括邏輯綜合(logic synthesis),布局規劃 (floorplan),時鐘樹綜合(CTS),布局布線(placement & routing)等步驟。除此之外我們還需要進行大量的仿真和驗證工作。在這個過程中,工程師需要權衡功耗,頻率,面積等多個設計目標,同時還要確保制造出的芯片將正確運行各種功能。另外隨著摩爾定律的進展,當下大規模的芯片已經可以包含超過 100 億個晶體管。考慮到這種流程與設計的復雜性,幾乎所有設計團隊都需要商業EDA工具來輔助完成整個芯片設計。因此,如果我們把整個半導體產業比作一座金礦,EDA工具則也許可以被看做挖礦的鏟子。在美國頻繁限制半導體出口的當下,本身市值并不大的EDA產業越來越為人們所重視。
EDA的全稱為Electronic Design Automation,即電子設計自動化。經過幾十年的發展,EDA工具已經被用于芯片設計與制造流程的方方面面。EDA工具的質量將會影響最終芯片的質量(功耗,頻率,面積)以及設計效率(產品上市時間)。因此,EDA算法研究者的目標通常至少包括兩方面,一是芯片優化效果(功耗,頻率,面積),二是EDA工具本身的效率(總耗時=工具單次運行時間* 使用該工具的次數)。 這里我們強調了EDA工具的使用次數,因為芯片設計不是一次完成的。通常工程師需要多次迭代各個設計步驟直至達成設計目標。每一次迭代,工程師可以修改工具參數或者芯片設計,并重新運行EDA工具,以期更好的芯片效果。對于大規模的芯片設計,僅執行部分設計流程每次即可花費數天至數周時間。因此,迭代次數越多,花費在EDA工具上的時間越多,最終流片以及產品上市日期就會越晚。后文將會介紹,很多ML for EDA工作的原理就是減少迭代次數,盡快讓芯片質量收斂到設計目標。
02什么是ML for EDA?– 預測與優化
近年來,我們看到越來越多的ML for EDA方向的探索。如下圖 [1] 所統計,發表在代表性EDA會議(DAC, ICCAD,ASP-DAC, ...)與期刊(TCAD)的相關工作數量逐年增加。
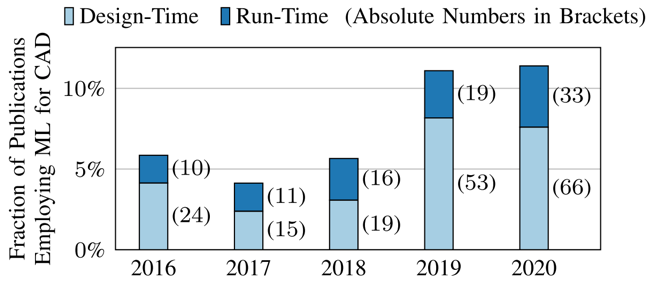
圖1 歷年發表的ML for EDA論文數量呈增加趨勢 [1] 這些ML for EDA的方法在芯片設計流程中的作用大體可以分為預測(prediction)與優化(optimization)兩大方面。下面我們分別舉例來介紹這兩類應用。 預測類工作通常使用ML模型對芯片優化的最終目標進行早期快速預測。利用ML模型的預測,設計師可以減少對耗時的EDA工具的使用,而直接預測EDA工具運行后的大致效果。基于ML預測,設計者可以及時調整設計參數。換句話說,ML模型通過快速預測EDA工具的行為,減少了運行EDA工具的次數。 一個典型的預測類工作例子就是,使用CNN模型在芯片繞線之前對(繞線后將會產生的)DRC熱點(hotspot)進行提前預測 [2]。DRC熱點指的是繞線后違反設計規則的區域。通過預測,EDA工具可以提前設法修改布局,避免未來階段將會產生的DRC熱點。這個工作可以類比于用CNN進行圖像分類或者語義分割,其中芯片版圖類似于圖片,而需要預測的DRC熱點位置類似于圖片上需要分割的區塊。
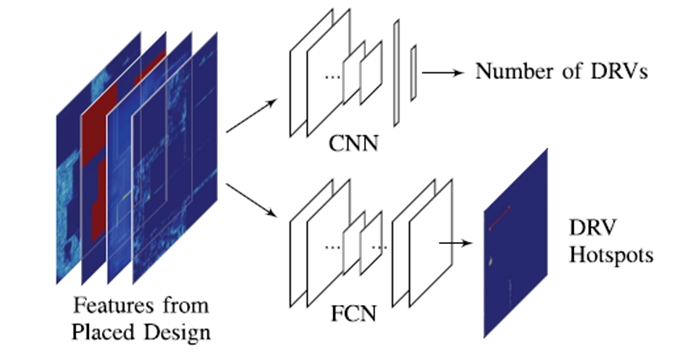
圖2 預測類方法舉例:使用CNN對DRC熱點進行預測 [2] 相比于預測類工作,優化類工作需要做得更多。這里說的優化是一種比較寬泛的概念,指的是直接解決一些EDA問題。事實上大量EDA問題本質都是對于芯片在一定約束下的優化問題,而很多傳統EDA算法是大家多年積累的(對這些問題的)優秀啟發式解法。那么優化類ML方法追求的是比傳統EDA算法更優或者更快的解法。這個解法可以幫助生成真實精確的芯片設計結果。 一個典型的優化類例子就是谷歌使用強化學習(Reinforcement Learning)進行macro 擺放(placement)[3]。通過強化學習算法,這個工作可以類比于AlphaGo進行圍棋落子,其中芯片版圖類似于圍棋棋盤,而每一個macro元件的擺放位置類似于圍棋每次最佳的落子位置。
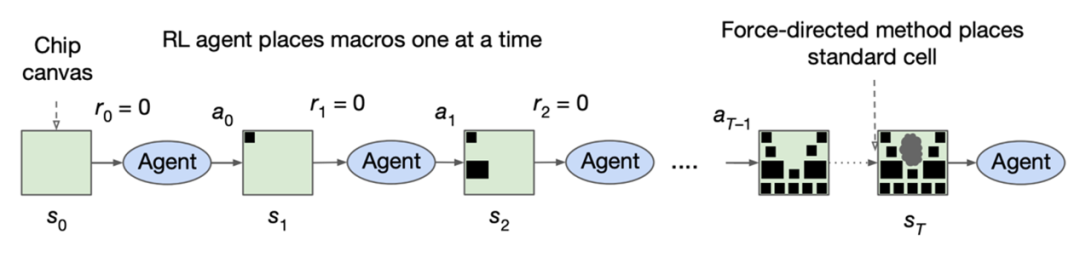
圖3 優化類方法舉例:使用強化學習進行macro擺放 [3] 按照這種不太嚴格的分類方式,預測類ML方法能夠減少EDA算法的使用次數,從而提高芯片設計效率。而優化類ML方法能夠幫助生成更快或更好的設計。如果想要完全取代某些傳統EDA算法,我們需要的是優化類方法。當然像布局布線這樣包括百萬元件的大規模優化問題,想直接取代傳統EDA方法是困難的。目前我們看到更多的是ML方法融入EDA框架,起到重要的輔助性作用 [4]。
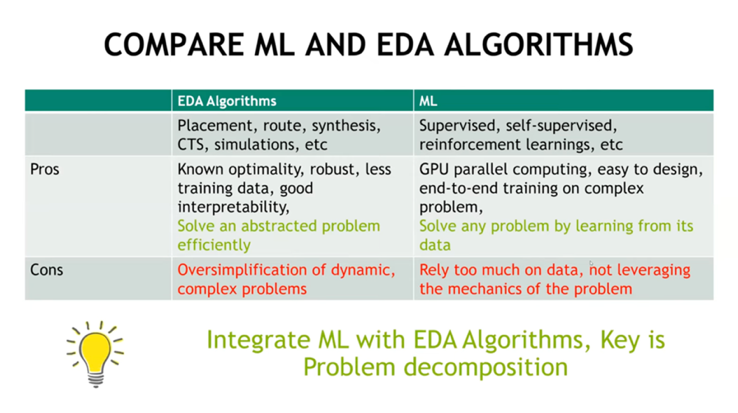
圖4 EDA和ML方法的比較:應該將ML融入EDA方法 [4]
03為什么研究ML for EDA?
在深入介紹其他工作之前,一個需要回答的問題是,為什么我們要研究ML for EDA?換句話說,ML for EDA相比傳統EDA算法有什么核心優勢嗎?這里嘗試提供一種簡單化的解釋 [5]。
如背景中介紹,設計流程分為多個階段。在大部分階段,EDA工具很難直接去優化最終的設計目標,因為最終的設計目標只有在整個流程走完之后才會確定。于是EDA工具只能對最終的設計目標進行一個粗略估計。舉例來說,布局(placement)算法可能會優化總線長(HPWL)與擁塞(congestion),但這個優化目標這并不總能反映最終的設計目標(最終芯片的功耗,頻率,面積,DRC熱點,等等)。 因此,除非每次都走完漫長的設計流程,不然前期的EDA工具并不能準確知道自己的解是否夠好。為了保證設計收斂,一種策略是使用保守的早期估計,以給后期階段留足余地(margin)。但這顯然會犧牲芯片質量。另一種策略是不斷調整參數進行反復多次迭代,以期獲得更好的芯片質量。而這非常依賴專業設計師的經驗,并且會花費大量設計時間。 ML for EDA算法的特點是它是由數據驅動的方法。通過學習已有的設計數據,早期使用ML預測可以獲得更準確的最終優化目標,作為重要的早期反饋(early feedback)。于是預測類ML方法打通了不同設計階段之前的障礙。而對于優化類ML方法,強化學習類型的方法通過探索巨大的設計空間,有可能獲得比傳統啟發式算法更優的解。另外,一些ML方法可以學到工程師的優化經驗,減少了對工程師經驗的依賴。最后,ML方法在預測時通常非常快,所以如果不是規模太大,ML方法通常在運行速度上比傳統方法會有數量級上的優勢。
04代表性的ML for EDA研究工作
事實上ML for EDA的工作遠遠不止前文介紹的兩個例子。而這些工作可以通過多種方法進行分類。
如果我們根據ML應用的階段或步驟分類,ML已經被研究者嘗試用于絕大部分設計階段。根據相關文章的總結 [1],應用ML模型的階段可以包括1. 高階綜合(HLS)與設計空間搜索(DSE),2. 邏輯綜合,3. 物理設計(從布局規劃到布線),4. 光刻與制造,5. 驗證與測試。除開數字電路之外,一些ML研究也對模擬電路的布局布線有一些嘗試。
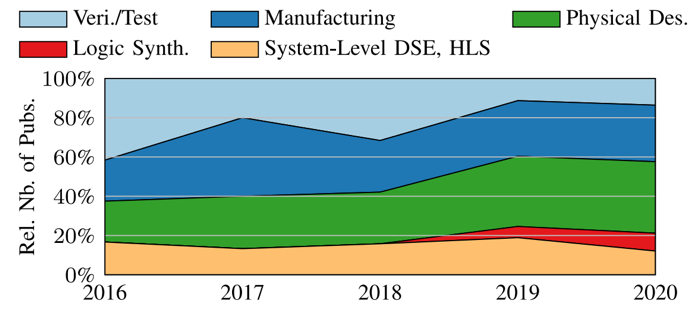
圖5歷年應用在不同設計階段的ML for EDA論文比例 [1] 如果我們根據ML預測或優化的目標分類,ML已經被研究者嘗試用于大部分芯片優化目標,包括但不限于1.功耗(power),2.頻率與延遲(delay or slack),3.面積與線長,4.擁塞(congestion)與規則檢查(DRC),5.電壓降(IR drop)與串擾(crosstalk), 6. 可制造性(Manufacturability)。 以下嘗試簡單列舉一些具體的ML for EDA工作。篇幅所限,顯然難以窮盡。因此同類型里盡量列舉較早期且較高引用的工作。對于更新更完整的ML for EDA工作總結,讀者可以參考論文 [1] 或視頻 [4]。 對于FPGA平臺,在高階綜合(HLS)階段,有工作訓練ML模型來預測最終的FPGA資源的利用率以及是否時序收斂 [6]。其中預測的FPGA資源包括RAM,FF,LUT和DSP等。ML模型是MLP或XGBoost。ML模型的輸入,輸出,使用階段如下圖所示。
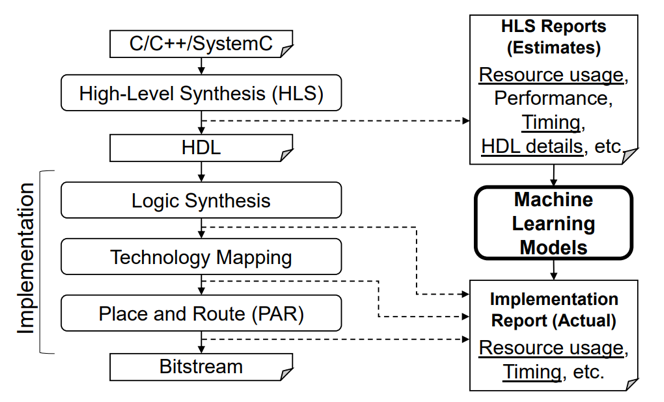
圖6HLS階段對FPGA 資源利用率進行預測 [6] 同樣在HLS階段,ML可以進行設計空間探索(DSE)[7]。基本的方法就是用ML模型的預測結果指導每一次采樣,然后根據采樣結果重新訓練ML模型,反復循環直至采樣的設計獲得足夠好的結果。這里用到的ML模型是隨機森林(RF)。這類探索任務也并不僅限于高階綜合。例如熱門的用ML對EDA工具調參問題也屬于相似的空間搜索任務。
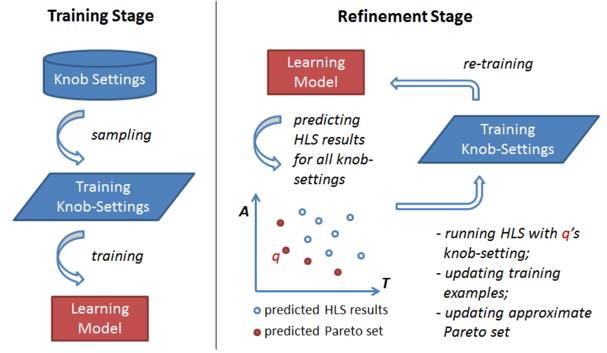
圖七 用ML(隨機森林)進行設計空間探索(DSE)[7] 在RTL階段,ML可以用于對邏輯綜合后的功耗進行快速估計 [8]。換句話說,ML模型在設計早期進行快速功耗模擬。ML模型的輸入是芯片每個周期所有RTL信號的翻轉值(1代表信號翻轉,0代表在該周期信號不變),而輸出是芯片每個周期的總功耗。選取這個輸入是因為芯片的動態功耗與邏輯門的翻轉率正相關。這個工作 [1] 嘗試了包括線性回歸,PCA降維,CNN的各類基礎ML模型。
圖八 用ML模型(CNN或線性模型)來模擬每周期的芯片功耗 [8] 在邏輯綜合階段,ML模型可以用于對邏輯綜合這一步驟的流程進行選擇 [9]。這里ML模型被訓練來預測最適合當前芯片設計的synthesis transformation的組合。該工作把各種transformation的組合方式編碼成二維矩陣,然后用CNN模型來進行處理,預測它們屬于是好流程還是壞流程。
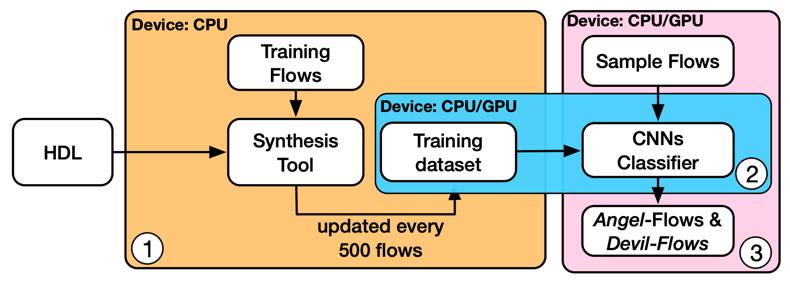
圖9 用ML(CNN模型)選擇合適的邏輯綜合流程 [9] 在物理設計(從布局規劃到布線)階段,一開始提到的macro擺放和DRC熱點預測兩個例子都屬于這個階段的工作。另外一個例子是對芯片上的電壓降(IR drop)分布進行預測 [10]。類似于之前的例子,CNN模型可以預測IR drop過高的熱點(hotspot)。這里模型的輸入是瞬時的功耗分布。需要預測的IR drop與區域內的瞬時的功耗成正相關。
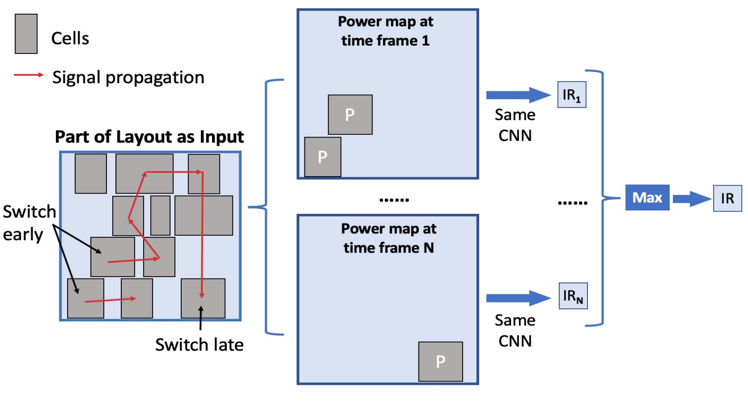
圖10 用ML(CNN模型)預測電壓降(IR drop)熱點 [10] 除了以上這些用于數字電路的工作,對于模擬電路的探索也非常多。一個例子是直接使用ML生成對模擬電路繞線的指導(guidance) [11]。這里使用的ML模型是變分自編碼器(VAE)。這個VAE模型的輸入來源于模擬電路完成布局后,繞線之前的版圖。
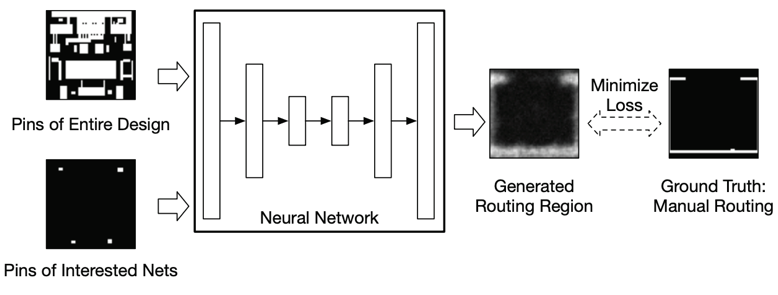
圖11 使用ML(VAE模型)輔助模擬電路繞線 [11] 設計完成后,為了進行芯片制造,需要生成***使用的掩膜(mask)。對于先進制程,在掩膜生成的過程中,為了在晶圓上得到和設計相同的圖形,光學鄰近校正(OPC)是一個重要步驟。ML可以用于進行OPC [12]。這個工作使用生成對抗網絡(GAN)來快速生成OPC后的掩膜。
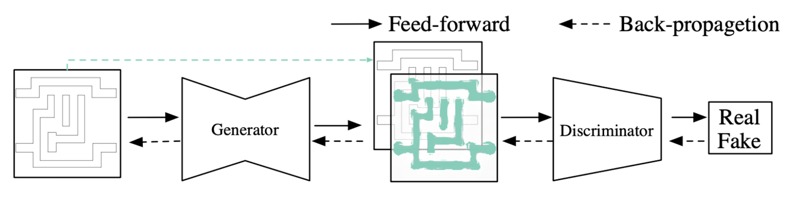
圖12 使用ML(GAN模型)進行光學鄰近校正(OPC)過程 [12] 另外為了提高制造良率(yield),需要進行光刻(lithography)熱點(hotspot)檢測。光刻熱點指的是制造后可能會出現短路或斷路的區域。ML可以用于預測光刻熱點 [13]。這個工作對每一塊輸入的芯片區域先進行離散余弦變換(DCT),然后使用CNN模型來判斷該區域是否為光刻熱點。
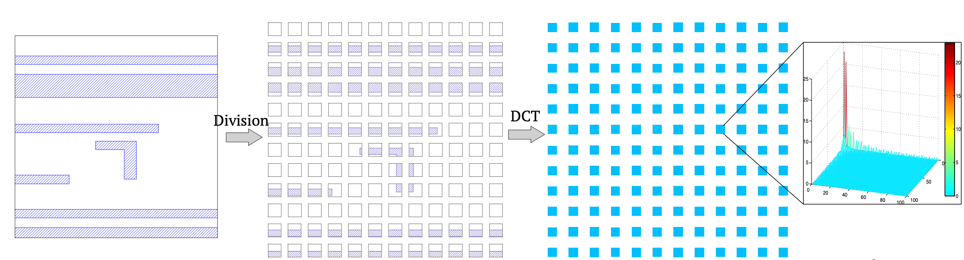
圖13 用ML(CNN模型)對光刻(lithography)熱點檢測 [13]
05代表性的ML for EDA商業探索
除了學術界的探索,在工業界,EDA公司和芯片設計公司也對ML for EDA的方向表現出了很大興趣。兩大EDA公司Cadence和Synopsys已經推出了融合了一些ML算法的商業產品。
例如Cadence公司的物理設計工具Innovus在新版本中已經里面集成了一些機器學習工具,比如說在布線(routing)前提供對(布線后)時序的更準確估計。這個ML功能似乎獲得了一些不錯的評價 [14]。另外之前有報道Cadence集成的sign-off工具Project Virtus(Voltus + Tempus)也使用了ML [15]。更有影響力的是Cadence的Cerebus工具,通過基于強化學習的ML模型來調整RTL-to-GDSII的設計流程,減少對人工設計師的依賴 [16]。不過作為相關從業人員,我們很難了解這個產品的技術細節,例如這里的強化學習算法是如何遷移到不同的芯片設計的。 類似的,Synopsys也在更早推出了DSO.ai工具,也是用強化學習的方法自動優化設計流程 [17]。Synopsys的PrimeTime ECO工具也使用了ML模型。另外曾經的Mentor Graphics(現Siemens)也推出過使用基于ML預測的光學鄰近效應修正(OPC)工具。 除了EDA公司之外,谷歌和英偉達的研究團隊也積極探索了ML for EDA方向。這些是更偏研究性的工作。具體可以參考谷歌Jeff Dean和英偉達Bill Dally的相關主題演講。 而在國內,受美國半導體政策影響,近年來不少優秀的國產EDA初創公司涌現。一些公司也開始探索了ML在EDA領域的應用。例如某國內公司最近發布了基于機器學習技術與布局規劃工具,應該是將類似前文提到的谷歌macro擺放算法[1]實現了產品落地。個人認為這是一個比較有挑戰性的任務。
06其他與ML for EDA相關的研究
除去以上介紹到的工作,還有一些熱點研究方向也經常被大家歸類到ML for EDA的研究當中。但嚴格來說,個人認為這些方向也許不能完全屬于狹義的ML for EDA的范疇。
使用GPU對EDA算法進行加速是近年來非常火熱的研究方向。例如使用GPU加速布局過程 [18]。這些方法巧妙利用了EDA問題的優化過程與深度學習訓練過程的相似性。于是它們可以利用已有的深度學習框架,例如PyTorch,來進行基于GPU的快速優化。但這類方法不會去應用具體的ML模型,也沒有基于數據的訓練過程。
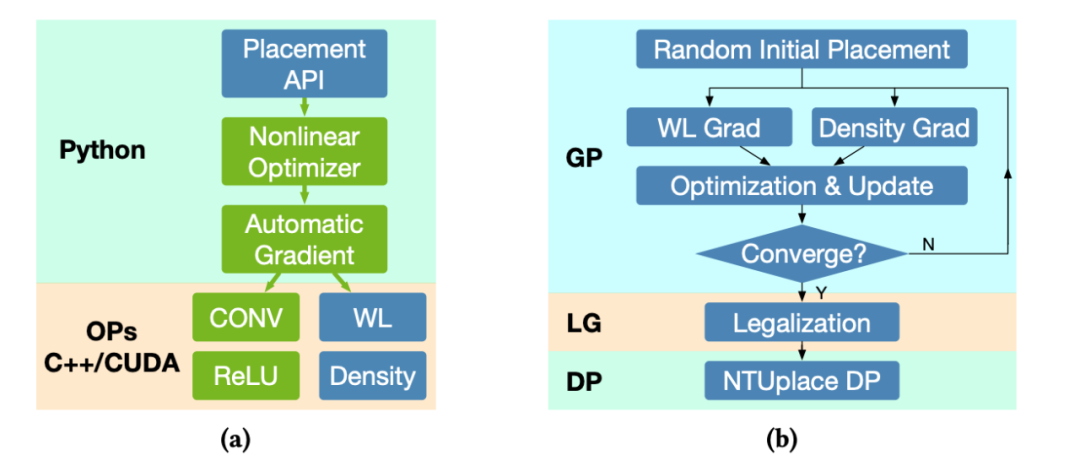
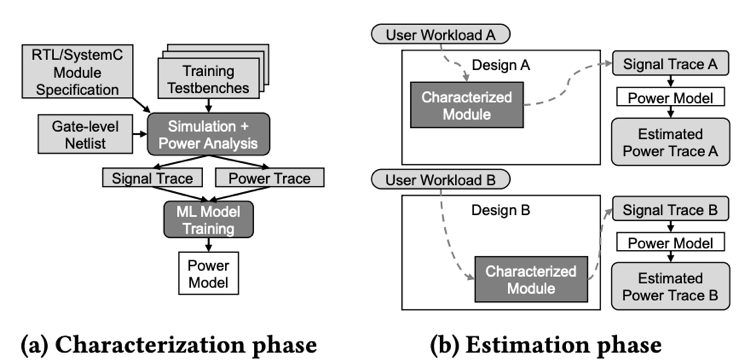
圖14 使用GPU加速芯片布局過程 [18] 另外一個常被歸類為ML for EDA的方向是:在芯片上實現ML模型,將它用于進行芯片運行時的監測,控制,或管理。例如利用ML方法,開發一個片上的實時功耗檢測工具 [19]。使用ML方法的目的是減少這個模型在芯片上的硬件開銷。嚴格意義上說,這更接近芯片設計而非EDA工具范疇,也許可以將它歸類到ML for hardware design的范疇。
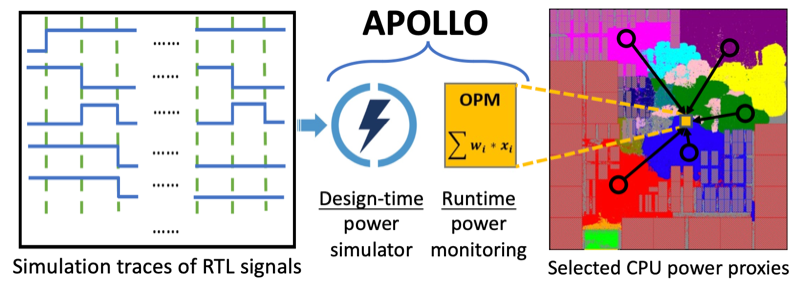
圖15 使用ML開發的高效片上功耗檢測模型 [19]
07ML for EDA面臨的挑戰
最后簡單總結一下 ML for EDA可能會面臨的一些挑戰。而針對這些挑戰,近年來大家也進行了一些嘗試。
第一,訓練所需的芯片設計數據非常難以獲得。對于這個問題,一方面一些研究者開始提供公開的芯片設計數據集 [20]。另一方面,研究者探索了在保護數據隱私條件下的模型訓練,例如基于聯邦學習的方法 [21],或者對訓練數據進行一些加密。第二,開發和維護ML模型需要大量ML背景的工程師,而這對半導體公司來說并不容易。為了進一步提升自動化的程度,研究者探索了一些自動化的ML模型開發方法 [22]。這些工作一般基于深度學習領域已有的AutoML或者神經網絡架構搜索(NAS)方法,然后對特定問題進行一些定制化設計。第三,由于芯片設計與制程的差異,ML方法的準確性難以保證可遷移性。另外ML方法的安全可靠性也需要更多保證。已經有不少研究ML方法安全與可靠性的初步工作。論文 [23] 中提供了一些總結。第四,從實際工程角度,ML方法如何更好地融入現有的EDA工具與芯片設計流程。這一點也許需要研究者與工業界共同進行探索。
08結語
本文大致介紹了ML for EDA這一熱門研究方向。總體來說,ML方法在EDA領域提供的數據驅動的優勢是極其獨特的。考慮到這些特點,我個人確信更多的ML算法未來會融入芯片設計流程之中。但至于ML算法究竟會在未來的設計流程中占到多大比重,這當然取決于大家未來的探索與實踐。非常期待基于ML的新方法能夠推動EDA產業,特別是國產EDA產業的發展。
審核編輯 :李倩
-
芯片
+關注
關注
456文章
51155瀏覽量
426325 -
eda
+關注
關注
71文章
2785瀏覽量
173626 -
人工智能
+關注
關注
1794文章
47642瀏覽量
239690
原文標題:人工智能會改變EDA嗎?
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
嵌入式和人工智能究竟是什么關系?
《AI for Science:人工智能驅動科學創新》第6章人AI與能源科學讀后感
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
risc-v在人工智能圖像處理應用前景分析
人工智能ai4s試讀申請
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創新
報名開啟!深圳(國際)通用人工智能大會將啟幕,國內外大咖齊聚話AI
利用人工智能改變 PCB 設計







 工商網監
工商網監
評論