 圖數據切分與模型數據載入的問題解析
圖數據切分與模型數據載入的問題解析
什么是 GNN/圖神經網絡?
圖神經網絡是一類 ”用于處理可以表示為圖的數據“ 的人工神經網絡。我們通常能看到的例子有: 社交網絡的商品的推薦,蛋白質三維結構的預測和芯片設計優化等等。到目前為止,之所以圖神經網絡能夠攻克了這些涉及領域比較核心的問題,包括其涉及的理論知識, 模型設計,benchmark 數據集效果驗證等等一系列工作, 都能反映出了它結合圖數據表達的能力和神經網絡模型泛化的能力。
那我們又要基于什么樣的前提,在 GNN 的范疇開始我們自己的探索和應用呢? 我希望通過對兩個“假設”的描述 ,讓大家更了解這個前沿技術背后的動機。
第一個假設:關于數據樣本的分布、頻率和空間位置表示
6 年前,谷歌 AI 趣味實驗的一個展示平臺上 有一個機器學習任務非常吸引我。他們當時的目標是通過?叫聲分辨出?的種類。最左邊所有的小圖片,每一個代表北美一種?類叫聲的聲紋信息, 右邊則是我們找到的對應的“鴛鴦”的照片。這個機器學習可視化項目,通過不使用標記訓練的 t-SNE,將高維聲紋信息轉換為二維的空間位置來展示數據 并且驗證了相似的種群有相似的叫聲這個假設。
放在現在來看,我們有理由相信。當時研究人員的夢想 是可以用深度學習的模型去解決的, ?類有成千上萬種,一種?的不同叫聲也有很大的差別, 只要我們有大量的數據樣本和標簽可以去做訓練,這個事情就是可行的。
我們知道深度學習,能解決這樣直觀但又復雜的事情, 恰恰是因為我們認定了這樣的假設; 并且著眼于如何處理大量的數據,使用更深層、更精妙的神經網絡模型設計,來自動挖掘出數據的規律,并最終給出判斷。
假設二:一個種群有一個大致的活動范圍
假如我們把問題換做:我想知道在哪一個城市可以聽到這樣的?叫聲呢? 解答這個問題的方法是使用圖算法。我們可以看到數據中記錄的位置信息,屬于地理位置的不同區塊; 根據數據采集的密度決定區塊的大小,把小的區塊與種群關聯, 再用社群發現的算法,得出不同物種的空間分布。
這個生物地理的問題,其實給定另一個假設,即一個種群有一個大致的活動范圍。只不過這樣的假設比之前樣本特征分布的假設,更加容易以一種顯式的方式體現。趨向于普遍事實的“假設”是可以被作為數據存儲下來的, 比如我們常說的知識圖譜中的三元組關系是對某一個事實關系的描述一樣。
圖神經網絡
而圖神經網絡模型,恰恰是在這兩個前提假設的融合之上建立的。如果我們也能夠確信,我們手上的數據蘊含了這樣的假設, 即樣本特征分布的假設與邏輯關系的假設, 我們一定可以去嘗試,并且有信心能構建出有效的 GNN 模型。
回到今天的主題,當我們有數據集需要做模型訓練時,我們是如何對其進行訓練集、驗證集測試集的切分? 我們又是怎樣對大到無法放入內存的數據進行分批次的訓練?
如果放在 GNN 的場景下,我們需要考慮的是,如何切分圖數據集,又如何為 GNN 模型分批加載子圖。要知道在研究和應用上,GNN 是機器學習領域最火熱的方向,各式各樣的理論和方法層出不窮。有一點可以確信的是,無論從理論還是工程方面,這兩個步驟并沒有太高深,卻也是 GNN 項目中比較重要的部分。
我也會在最后通過 TigerGraph 云實例,演示我們的圖機器學習工作臺,并在一個運用 GAT 模型進行反欺詐檢測的 Demo 中,展示這兩個步驟的作用。
圖數據切分
首先,我們來討論如何對圖數據進行切分:
對于有監督機器學習模型,我們對樣本的變量都會有一個獨立同分布的假設。通過這個假設我們可以隨機的按比例去切分訓練集和驗證集,用于調整模型的擬合,并在測試集上觀察泛化的效果。或者可以按照時間發生的先后順序去切分, 因為我們希望新的數據的特征同樣能被模型識別到。然而通常來說,一定會遇到樣本的分布發生變化; 樣本存在分組; 有標記樣本數量的平衡性等現象。
按照統計經驗的方式切分,模型會在真實的數據上發生變化,影響了實際業務的判斷。而這樣的現象,當我們用圖的思維去構建數據時,會更加顯而易?的發現。可以假設一個生活中的例子來構建一個圖機器學習任務:
我們希望通過人群訪問地理位置的記錄去預測場所的標簽。這似乎與之前的種群分類的問題很像, 但顯然我們不能直接通過之前的圖算法給出結論: 因為標簽本身是有含義的,并且每個地點可能有多個標簽。
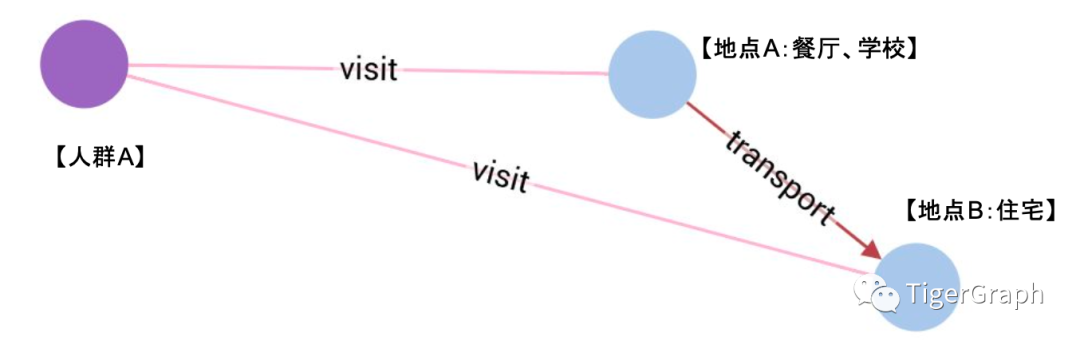
那如果我們為傳統機器學習的模型提供圖特征呢? 比如我們把【人群】的特征,歸并到【地理位置】中去, 我們會在切分數據的時候發現一系列的問題。可能我們會發現訓練集中【人群】的多少,訪問時間段等信息與【場所】沒有太強的相關性 ;或者在驗證集上【地理位置】的特征的分布發生了偏移; 更重要的,我們如何保證測試集上新的數據,【地理位置】更新的生命周期,涉及到的【訪問】關系 不會顯著減少? 我們嘗試各種方法:延?樣本的時間跨度、在數據集上做交叉驗證,縮短模型上線后的運行周期,甚至嘗試剔除【人群】相關的變量。
這顯然不是我們希望看到的,在【人群】這類特征上來看,按時間切分顯然是不合適的。
我們是否應該重新考慮修改圖模型本身呢? 答案是肯定的,我們可以嘗試把人群的特征作為【地理位置】間【轉移】的關系進行建模。這樣,我們的選擇就變多了:我們可以首先得到一個同構圖,人群移動的信息就被包含在了地點之間【轉移】的關系里面,就像種群遷移一樣。我們還可以將轉移所需的時間,作為距離和關聯性的特征,也放在邊關系里。試想騎手們在趕單子和上了一天班的你坐地鐵回家,一定會產生不同的分布。甚至,我們還可以建立多條關系比如所有早高峰,午餐高峰等不同時間段的統計等等。這樣構成的網絡,就包含了【人群】帶來的真正有用的信息。
回到剛剛的切分數據的問題本身,我們可以思考一下為什么需要【地理位置】的標簽呢? 其中一個最直接的原因是,大部分的地理位置標簽我們是沒法直接拿到的,并且也正是我們希望模型給出預測的。
比如開辟一個新地塊的【地理位置】標簽,或者說 【人群】活動較少的地方這些【地理位置】的標簽,就不會像大家常去的有 POI 的地方容易拿到標簽。在這種情況下,按照地理位置的”活躍度“切分數據,恰恰是最合理的。
那么對于可以表示為圖的數據,還有哪些切分方式呢?
我們可以看到 OGB這個專?為GNN模型準備的公開數據集,規范了一些切分方式。之前提到的人群遷移的這個例子,就是借鑒了這個數據集中【產品分類任務】的構建關系和切分的方法。當然從實際出發,我們也可以用不同的方式切分數據集,讓他們同時落在一張圖或者完全不相關的圖上。這些切分方法,其實并沒有在意樣本的數據分布是否均勻和時間發生的順序,而是根據實際情況出發,在建立關聯關系的過程中,顯示的把邏輯表述出來,數據本身的變化和無法及時獲取的問題得以規避。最終,我們把發現分布的事交給各式各樣的圖神經網絡模型,發揮他們不同的泛化能力。
總結一下,在圖上做機器學習的任務,“切分數據” 這一步驟的目的,并非為了讓模型更容易訓練, 而是讓模型訓練的邏輯假設更加清晰,樣本主體的特征保持穩定,模型結果更容易驗證,并且最終投入生產應用。
模型數據載入
接下來,我們來看一下在訓練階段 GNN模型對我們的數據載入有哪些要求。
從基本的模塊來看,圖神經網絡模型和其他神經網絡模型一樣可以堆疊層數,但通常會有一個置換等變層。這一層的目標,就是收集模型訓練樣本的鄰居,把他們的信息傳遞過來。根據模型的不同,可能是單跳的鄰居,也可能是多跳的鄰居。聚合時,可以用固定權重去聚合這些信息,也可以是一個參數的形式來學習鄰居之間的重要程度。
從這個過程來看,圖神經網絡,和其它一般的神經網絡不一樣的是: 如果我們的輸入是圖片、聲音和文字這樣的高維數據,我們可以想方設法做一些預處理來減少輸入維度。而對于組成網絡的數據而言,因為我們的初衷是希望盡可能地學習到圖拓撲結構。我們很難在模型以外預處理他們(雖然也是有辦法的)。
這就導致像 Pytorch / Tensorflow 這樣的框架需要去做除了計算以外的事情,比如特征索引和鄰居索引的工作。
從數據集的?度來看,我們必須正視拓撲結構對 GNN 模型架構的影響。大批量數據集本身,是沒有辦法放入一臺機器的內存中的。對于深度學習,分批次的載入數據到更快的計算單元的內存(GPU), 是讓深度學習模型的訓練擴展到大量數據至關重要的步驟。而大型的圖數據集,尤其是密度很高的圖數據集, 我們還需要額外的處理方式:比如通過鄰居采樣的方式去規避鄰域爆炸的問題。
當然,不是將數據進行分批就一勞永逸了。我們仍需要考慮數據傳輸效率問題。舉一個 PyTorch 的數據載入模塊 DataLoader 為例,這個圖表模擬了模型在進行分批訓練時,當載入速度(比如2秒)和批次消耗速度(比如每個批次的正向和反向傳播只需要 100 毫秒) 相差過大時,整體的訓練速度會比平衡時慢兩倍多。
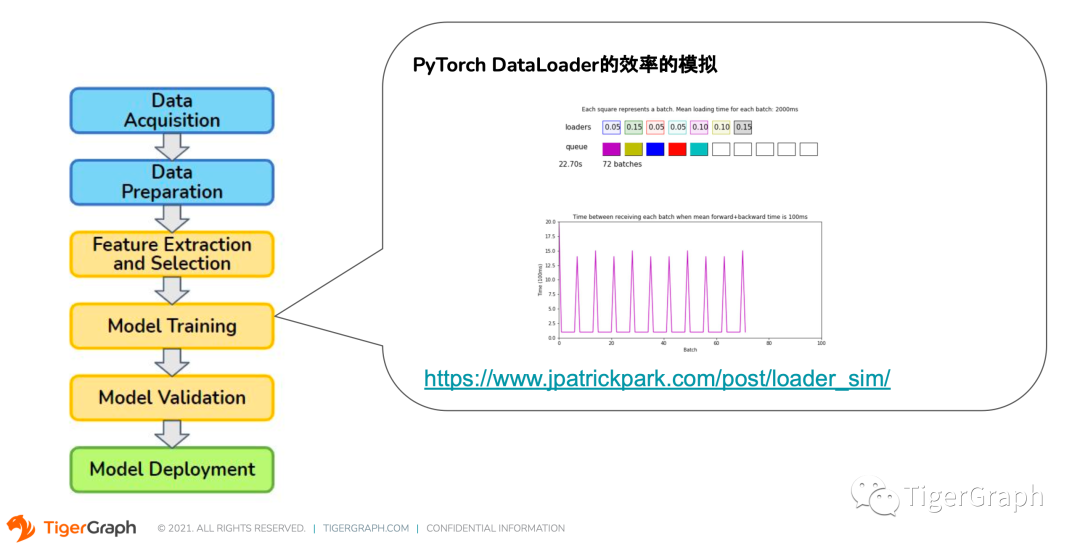
如果說,我的載入速度能降到700 毫秒, 但是我開了 7 個 worker,這樣的話就可以把消耗和載入速度平衡了。我們還要考慮每個批次的載入速度差異,差異過大,即使有很多worker 和管道,也會降低訓練的速度。這樣看來,在關聯信息的圖上做這樣的控制,保證批次數據的載入速度和穩定性也是十分重要的。
從架構層面看,我們會發現特征索引和圖的索引是 GNN 模型中不可避免的工作。
我們看到 PyG(基于PyTorch的圖神經網絡架構 ) 在對 GNN 的實例描述中,提及了這樣幾點發現:
● 獲取具有足夠 CPU DRAM 來同時存儲圖形和特征,是非常具有挑戰性的;
● 使用數據并行性進行訓練,需要在每個計算節點中復制圖特征和圖拓撲;
● 圖和特征很容易就超過了單臺機器的內存。
因此他們額外抽象出了 FeatureStore, GraphStore 這樣遠程的抽象層,由開發者決定如何連接提供有效的圖特征采樣的外部存儲。作為同時具有擴展性和計算性能的圖數據庫,我們也明白這是TigerGraph需要出力的地方, 并同時達到一個實時的、安全的、穩定的、更方便獲取特征的平臺,加速整個 GNN 項目的演化和上線。
審核編輯:劉清
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100715 -
機器學習
+關注
關注
66文章
8406瀏覽量
132566 -
GNN
+關注
關注
1文章
31瀏覽量
6335
原文標題:GNN課程詳解:圖數據切分與模型數據載入
文章出處:【微信號:TigerGraph,微信公眾號:TigerGraph】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
用2630與2530通信時,CC2630最大一個數據包最大數據載荷是多少啊?
純干貨分享:切分測徑儀的2個安裝位置詳解
為什么采用切分測徑儀應用于切分螺紋鋼生產?
切分軋制線迎來新設備 切分測徑儀保駕護航
中文分詞研究難點-詞語切分和語言規范
UART串口與LWIP以太網問題解析
數據庫及其應用習題與真題解析
基于特征切分和隨機森林的異常點檢測模型
GTC 2023:多模態短視頻模型推理優化方案解析





 工商網監
工商網監
評論