 圖像處理技術面臨哪些挑戰?
圖像處理技術面臨哪些挑戰?
當人類觀看圖像時,會感知物體、人物或景觀。當機器“查看”圖像時,他們看到的只是代表單個像素的數字。假設一個灰度圖像,每個像素由一個通常在0到255之間的數字表示,其中0表示黑色(無顏色),255表示白色(全強度)。0到255之間的任何一個都是灰色陰影,如下圖所示。
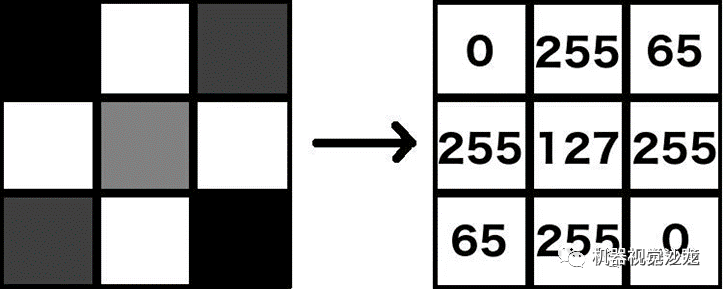
因此,對于任何要獲取圖像內容的機器來說,它必須以某種方式處理這些數字。
數據量大
正如上面所說,當涉及到圖像時,計算機得到的是很多數字,意味著需要大量的處理才能被理解。舉一個例子來說明圖像的數據量究竟有多大。如果是具有1920x1080分辨率的灰度(黑白)圖像,則表示該圖像由200萬個數字(1920*1080=2073600像素)描述,如果切換到彩色圖像,則一般需要三倍的數字。如果試圖分析來自視頻/攝像機流的圖像,假設幀率為30幀/秒(標準幀率),則每秒需要處理1.8億個數字(3*2073600*30=1.8億像素)。即使如今我們擁有強大的處理器和相對較大的內存,也是一個巨大的挑戰。更何況如今幾千萬甚至上億像素的Sensor越來越普及,且其幀率更是高達上百幀/秒。
信息丟失
數字化過程中的信息丟失是造成計算機視覺難度的另一個主要因素。圖像處理的本質是從3D世界(如果處理視頻流中的數據則是4D)投影到2D平面(即平面圖像)上獲取信息。這意味著在此過程中會丟失大量信息。人類的大腦可以非常出色的推斷出丟失的數據是什么,但是對于計算機來說卻是極其困難的挑戰。下圖顯示的是一個凌亂的房間。
人類可以很容易地看出,綠色健身球比桌子上的黑色平底鍋更大更遠。但是如果黑色平底鍋比綠色球占據更多的像素,機器應該如何推斷呢?這不是一件容易的事。當然,可以嘗試通過同時拍攝兩張照片并從中提取3D信息來模擬用兩只眼睛看到的方式,這被稱為立體視覺。然而,將圖像拼接在一起也不是一項微不足道的任務,因為同樣是一個開放的研究領域。
伴隨噪聲
數字化過程中經常伴隨著噪音。例如,沒有相機會拍攝出一個完美的不含噪聲的現實圖片,特別是當用手機上的相機進行拍照時,他們會通過調整強度等級,色彩飽和度等去嘗試捕捉美麗的世界。同時在圖像拍攝過程中肯能會出現“鏡頭光暈”的現象,人類可以輕松的判斷光暈后面是什么場景,而對于計算機來說確實非常困難。 雖然已經有很多去除光暈的算法,但是去除光暈的算法本身也是開放的領域。另外,在圖像壓縮的過程中會對圖像降低像素或者變換操作,而這樣的圖片對于人來說可以輕松的識別,而對于計算機,如果不告訴它壓縮變換的操作,它會當作壓縮后的圖像為原圖像進行識別,從而產生錯誤。

理解圖像含義困難
最后也是最重要的是就是對圖像內容的理解。對于機器來說,這絕對是計算機視覺環境中最難處理的事情。當人類觀看圖像時,會用累積的學習和記憶(稱為先驗知識)來分析它。例如,人類知道,可以坐在健身球上,而平底鍋通常用在廚房里,因為這些東西過去已經了解過。如果有一些東西看起來像天空中的平底鍋,很可能它不是平底鍋,因此可以進一步仔細檢查,以確定對象可能是什么。或者如果有人圍著綠球踢球,很可能是小孩子的球而不是健身球。但機器沒有這種知識。他們不了解的世界,不了解其中固有的復雜性,以及在數千年的進化中創造的眾多工具、商品、設備等。也許有一天機器將能夠獲得網絡并從那里了解有關對象的信息,但目前離這種情況很遠。
編輯:黃飛
-
圖像處理
+關注
關注
27文章
1289瀏覽量
56724 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
45980
原文標題:圖像處理技術難點
文章出處:【微信號:機器視覺沙龍,微信公眾號:機器視覺沙龍】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論