


HLS最全知識庫
副標題-FPGA高層次綜合HLS(二)-Vitis HLS知識庫
高層次綜合(High-level Synthesis)簡稱HLS,指的是將高層次語言描述的邏輯結構,自動轉換成低抽象級語言描述的電路模型的過程。
對于AMD Xilinx而言,Vivado 2019.1之前(包括),HLS工具叫Vivado HLS,之后為了統一將HLS集成到Vitis里了,集成之后增加了一些功能,同時將這部分開源出來了。Vitis HLS是Vitis AI重要組成部分,所以我們將重點介紹Vitis HLS。
官方指南:
https://docs.xilinx.com/r/_lSn47LKK31fyYQ_PRDoIQ/root
重要術語
LUT 或 SICE
LUT 或 SICE是構成了 FPGA 的區域。它的數量有限,當它用完時,意味著您的設計太大了!
BRAM 或 Block RAM
FPGA中的內存。在 Z-7010 FPGA上,有 120 個,每個都是 2KiB(實際上是 18 kb)。
Latency延遲
- 設計產生結果所需的時鐘周期數。
- 循環的延遲是一次迭代所需的時鐘周期數。
Initiation Interval (or II, or Interval間隔)
- 在接受新數據之前必須執行的時鐘周期數。
這與延遲不同!如果函數是流水線的,許多數據項會同時流過它。延遲是一個數據項被推入后彈出的時間,而時間間隔決定了數據可以被推入的速率。
- 循環的間隔是可以開始循環迭代的最大速率,以時鐘周期為單位。
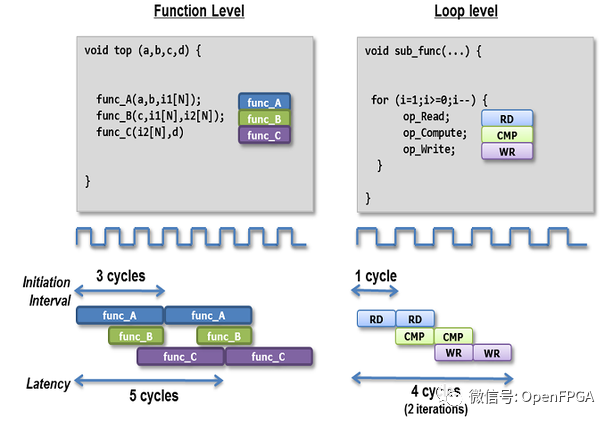
上圖中,左邊是函數右邊是循環,左邊的時間間隔(接收新數據之前)是3個時鐘周期,右邊循環的間隔則是一個時鐘周期;對于左邊的延遲是這個函數產生結果的時鐘周期數,是func_C運行完畢產生的周期數,為5個時鐘周期,右邊循環的延遲是一次迭代所需的時鐘數,是4個時鐘周期。
上面的概念非常重要,要不然下面的一些指令作用也看不懂~
重要的指令
這是在實際使用過程中重要的指令列表(不是全部)。
-
Functions-函數
-
loops-循環
-
Various-所有都適合
-
Arrays-數組
-
parameters-參數
| 指令 | 適用范圍 | 描述 |
|---|---|---|
| PIPELINE 流水線指令 | Functions, loops | 簡單解釋就是使輸入更頻繁地傳遞給函數或循環。流水線后的函數或循環可以每 N 個時鐘周期處理一次新輸入,其中 N 是啟動間隔(Initiation Interval)。'II' 默認為 1,是 HLS 應針對的啟動間隔(即嘗試將新數據項輸入管道的速度應該多快)。 |
| UNROLL | loops | 創建循環的因子副本,讓其并行執行(如果滿足數據流依賴性)。但是會浪費資源(以資源換取速度)。盡可能將程序展開以提高速度。 |
| ALLOCATION | Various | 限制某事物的實例數。例如,如果只想在另一個函數toplevel中獲得函數foo的三個副本,請使用位置toplevel、限制設置為3、實例設置為foo、類型設置為“function”的分配。這也適用于特定的運算。 |
| ARRAY_MAP | Arrays | 將多個較小的陣列映射成一個較大的陣列,以犧牲訪問時間為代價來節省訪問邏輯或 BRAM。'instance' 可以設置為任何未使用的名稱。ARRAY_MAP 對同一個實例使用多個 來告訴 HLS 創建一個名為“instance”的新數組,其中包含所有較小的數組。保留“偏移”未設置。請注意,有些人在將三個或更多初始化數組映射到單個 RAM 時遇到了此指令引起的錯誤。如果在仿真和實現的設計之間遇到行為差異,請嘗試刪除此指令。 |
| ARRAY_PARTITION | Arrays | 將一個大數組拆分為多個較小的數組(與ARRAY_MAP相反)。這對于增加并行訪問的可能性很有用。如果“type”是“block”,則源數組將分成block。如果它是“cyclic”,那么元素將被交錯到目標數組中。在這兩種情況下,“factor因子”都是要創建的較小數組的數量。如果 'type' 是 'complete' 則忽略 'factor' 并且陣列被完全分割成組件寄存器,因此不使用任何 Block RAM。 |
| DATAFLOW | Functions | 見下文 |
| INLINE | Functions | 該指令不是將函數視為單個硬件單元,而是在每次調用 HLS 時將函數內聯。這是以硬件為代價增加了潛在的并行性。如果 'recursive' 為真,則內聯函數調用的所有函數也被視為標有 INLINE。 |
| INTERFACE | Function,parameters | 告訴 HLS 如何在函數之間傳遞參數。這在頂層函數中至關重要,因為它定義了設計的引腳排列。在 EMBS 中,我們有一個應該堅持使用的模板(上圖)。 |
| LATENCY | Functions, loops | HLS 通常會嘗試在綜合時實現最小延遲。如果使用此指令指定更大的最小延遲,HLS 將“pad out”函數或循環并減慢一切。這有助于資源共享(減少資源),并且對于創建延遲很有用。如果 HLS 無法達到要求的延遲,它將發出警告。 |
| LOOP_FLATTEN | loops | 將嵌套循環展平為單個循環。應用于 最里面的 循環。如果成功,將生成更快的硬件代碼。 |
| LOOP_TRIPCOUNT | loops | 如果循環具有可變的循環邊界,HLS 將不知道它需要多少次迭代。這意味著它無法為設計延遲提供明確的值。這允許我們為設計指定循環的最小、平均和最大行程計數(迭代次數)。這只會影響報告,不會影響硬件代碼生成。 |
| RESOURCE | Various | 這用于指定應使用特定硬件資源來實現源代碼元素。指定是否應使用 BRAM 或 LUT 實現ARRAY。見下文詳解。 |
任意精度類型
可以在 HLS 中使用普通的 C 類型(int、 char等)變量。但是,設計中的常用的寄存器并不完全需要 4、8 或 16 位寬,那么可以使用任意精度類型來準確定義需要多寬的數據類型,而不是接受這種低效率的通用定義。
下面展示了如何使用 C 和 C++ 風格的任意精度類型。我們建議使用 C++,除非有特定的理由不這樣做。
在 C 中:
包含
| uint5 x | 無符號整數,5 位寬 |
|---|---|
| int19 x | 有符號整數,19 位寬 |
在 C++ 中:
包含
| ap_uint<5> x | 無符號整數,5 位寬 |
|---|---|
| ap_int<19> x | 有符號整數,19 位寬 |
按照上面的設置應該能夠正常打印任意精度類型,但是如果在調試過程中得到奇怪的值,請先使用printf調用to_int():
ap_uint<23>myAP;
printf("%d
",myAP.to_int());
復位行為
在 HLS 中,所有靜態和全局變量都被初始化為零(如果給定了初始化值,則初始化為其他值)。這包括 RAM,其中每個元素都被清除為零。然而,這種初始化只發生在 FPGA 首次編程時。任何后續處理器復位都不會觸發初始化過程。
如果需要清除設備的內部狀態,那么應該包含某種復位協議(根據復位狀態處理所需要的程序)。
AXI 從接口和 AXI 主接口
可以在 HLS 組件中使用兩個接口,即 AXI Slave 和 AXI Master。
-
AXI Slave:ARM 內核使用此接口來啟動和停止 HLS 組件。他們還可以使用此接口來讀取和寫入相對少量的用戶定義值。
-
AXI Master:如果需要更大量的共享數據,HLS 組件可以使用 AXI Master 接口啟動事務以從主系統內存讀取和寫入數據。
可以通過toplevel在 HLS 組件中為函數指定參數并將指令附加到這些參數來定義所需的接口。下面顯示了一個只有從接口的組件:
帶有AXI Slave的 HLS 組件
uint32toplevel(uint32*arg1,uint32*arg2,uint32*arg3,uint32*arg4){
#pragmaHLSINTERFACEs_axiliteport=arg1bundle=AXILiteSregister
#pragmaHLSINTERFACEs_axiliteport=arg2bundle=AXILiteSregister
#pragmaHLSINTERFACEs_axiliteport=arg3bundle=AXILiteSregister
#pragmaHLSINTERFACEs_axiliteport=arg4bundle=AXILiteSregister
#pragmaHLSINTERFACEs_axiliteport=returnbundle=AXILiteSregister
}
而下面是一個同時具有從接口和主接口的組件:
具有從屬和主接口的 HLS 組件
uint32toplevel(uint32*ram,uint32*arg1,uint32*arg2,uint32*arg3,uint32*arg4){
#pragmaHLSINTERFACEm_axiport=ramoffset=slavebundle=MAXI
#pragmaHLSINTERFACEs_axiliteport=arg1bundle=AXILiteSregister
#pragmaHLSINTERFACEs_axiliteport=arg2bundle=AXILiteSregister
#pragmaHLSINTERFACEs_axiliteport=arg3bundle=AXILiteSregister
#pragmaHLSINTERFACEs_axiliteport=arg4bundle=AXILiteSregister
#pragmaHLSINTERFACEs_axiliteport=returnbundle=AXILiteSregister
}
請注意,可以為從接口添加和刪除參數,并更改它們的數據類型,只需記住也要更新關聯#pragmaS。HLS 將相應地更新組件的驅動程序。
PS:主數據類型:由于 AXI 主接口會連接到 32 位寬的 RAM,因此在指定 AXI 主接口時應始終使用 32 位數據類型。
一旦決定了的接口,應該能夠依靠 Vivado 自動化連線來連接一切。
請注意,返回端口的 pragma 很重要!
#pragmaHLSINTERFACEs_axiliteport=returnbundle=AXILiteSregister
//端口=返回包=AXILiteS寄存器
即使不使用函數的返回值,此 pragma 也會告訴 HLS 將 start、stop、done 和 reset 信號捆綁到 AXI Slave 接口中的控制寄存器中。因此,這將生成相應的驅動程序函數來啟動和停止生成的 IP 內核。如果不包含此 pragma,則 HLS 將為這些信號生成簡單的連線,并且 IP 內核將無法直接被 ARM 內核控制。
多種類型的 AXI Master
Vitis HLS在從同一主AXI端口復制值并將其解釋為不同類型時非常挑剔。
例如,以下 memcpy 可能會導致“Stored value type does not match pointer operand type! (存儲值類型與指針操作數類型不匹配!)” ,嘗試將 RAM 視為uint32 和float類型時,綜合過程中將會產生 LLVM 錯誤:
voidtoplevel(uint32*ram){
#pragmaHLSINTERFACEm_axiport=ramoffset=slavebundle=MAXI
uint32u_values[10];
floatf_values[10];
memcpy(u_values,ram,40);
memcpy(f_values,ram+10,40);
}
為了正確強制從 RAM 中復制數據的類型信息,可以使用union,如下所示:
typedefunion{
uint32u;
floatf;
}ram_t;
voidtoplevel(ram_t*ram){
#pragmaHLSINTERFACEm_axiport=ramoffset=slavebundle=MAXI
uint32u_values[10];
floatf_values[10];
for(inti=0;ifor(inti=0;i
此外,只要循環邊界從零開始(并且是固定的),HLS應該足夠聰明,將其視為類似于memcpy的突發傳輸-在綜合過程中查找“推斷MAXI端口上長度為X的總線突發讀取”來證實這一點。
強制和阻止使用 Block RAM
HLS 會自動將大部分ARRAY轉換為 BRAM。這通常很有用,因為寄存器ARRAY在 LUT(FPGA 空間)方面非常昂貴。但是,FPGA 的 BRAM 數量有限。BRAM 也只有 2 個訪問端口。這意味著在任何時候最多有兩個并行進程可以訪問 RAM。這可能會限制設計的并行性潛力。
如果HLS使用的是不希望使用的BRAM,則將類型設置為COMPLETE且維度設置為1的指令array_PARTITION應用于數組。這將迫使它從寄存器中生成數組。這會占用大量的FPGA空間(LUT),所以要節約!
要強制 HLS 使用 BRAM,請將指令BIND_STORAGE集應用到 RAM_2P。(添加時按下幫助按鈕可查看所有各種選項的說明)。
該 ARRAY_MAP 指令(見上文)可以通過自動將多個較小的數組放入一個較大的數組來幫助節省 Block RAM。
當更改 HLS 時
當更改 HLS 代碼時,請執行以下步驟以確保bitfile已更新,方便進行正確地測試。
-
1、重新運行綜合。
-
2、重新導出 IP 核。
-
3、在 Vivado 中,它應該已經注意到了變化,并且會出現一條消息說“IP Catalog is out-of-date”。a、如果沒有,請單擊 IP Status,然后單擊重新運行報告
b、單擊刷新 IP 目錄
c、在 IP Status面板中,應選擇 toplevel IP。單擊 Upgrade 選項。
-
4、在“Generate Output Products”對話框中,單擊“Generate”。
-
5、單擊生成比特流。
-
6、導出硬件到 Vitis。
-
7、在 Vitis 中重新編程 FPGA 并運行軟件。
現在應該明白了為什么測試和仿真如此重要了!
循環優化
在 HLS 中,可以將指令應用于循環以指示它展開或流水線。考慮以下循環:
myloop:for(inti=0;i
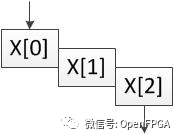
默認情況下,HLS 將按順序執行循環的每次迭代。它的執行將如下所示:

如果循環的每次迭代需要 10 個時鐘周期,那么循環總共需要 30 個周期才能完成。
如果我們給這個循環 PIPELINE 指令,那么 HLS 將嘗試在元素 0 完成之前開始計算元素 1,從而創建一個PIPELINE。這意味著循環的整體執行時間會更短,但代價是更復雜的控制邏輯和更多的寄存器來存儲中間數據。循環如下所示:
只有在沒有阻止此優化的依賴項時,它才能執行此操作。考慮以下代碼:
intlastVal;
for(inti=0;i
在此示例中,循環被迫按順序執行,因為在下一次循環迭代開始時需要在循環體末尾使用計算出的值。PIPELINE 仍然會試圖加快速度,但不會大幅加快。
最后,如果我們給循環 UNROLL 指令,那么 HLS 將嘗試并行執行循環的迭代。這需要更多的硬件,但速度非常快。在我們的示例中,整個循環只需要 10 個周期。
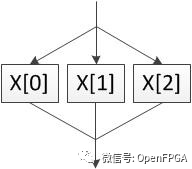
這要求循環的元素之間沒有數據依賴關系。例如,如果 doSomething() 保留一個執行次數的全局計數器,則此依賴項將阻止 UNROLL 指令工作。
請注意,UNROLL默認情況下會嘗試展開循環的所有迭代。這可能會導致非常大的設計!為了使事情更合理,可以設置UNROLL的FACTOR參數來告訴工具要創建多少副本。
應用UNROLL后,最好在分析視圖中查看它是否實際應用。成功展開的設計在分析視圖中將非常“垂直”,表示同一列中的操作同時發生。如果視圖仍然非常“水平”且有很多列,那么很可能是數據依賴項阻止了展開。可以嘗試通過單擊操作來確定是什么阻止了展開。該工具將繪制箭頭以顯示輸入的內容和輸出的內容。請記住,BlockRAM 一次只能進行兩次訪問,因此,如果有一個大型ARRAY,而這些工具是從 BlockRAM 制作的,則展開或流水線操作最多只能創建 2 個副本。可以告訴工具不要使用帶有ARRAY_PARTITION指令的塊RAM。這可以快得多,但要使用更多的硬件資源。
數據流優化
如果沒有使用限制資源的指令(例如 ALLOCATION 指令),HLS 會尋求最小化延遲并提高并發性。但是數據依賴性可以限制這一點。例如,訪問數組的函數或循環必須在完成之前完成對數組的所有讀/寫訪問,這就阻止了下一個消耗數據的函數或循環啟動。
函數或循環中的操作可能會 在前一個函數或循環完成其所有操作之前開始操作。
HLS指定數據流優化時:
-
分析順序函數或循環之間的數據流。
這允許函數或循環并行運行,從而減少延遲并提高 RTL 設計的吞吐量,但以增加硬件資源為代價。嘗試一下DATAFLOW ,看看它是否對設計有幫助。
找不到 'crt1.o' 錯誤
當試圖在實驗室硬件以外的機器上運行測試時,可能會收到一個錯誤,抱怨它找不到“crt1.o”。如果是這樣,就需要為項目設置自定義鏈接器標志。
單擊頂部菜單中的“Project”,然后單擊Project Settings。在此框中,單擊左側的“Simulation”,然后將以下內容粘貼到“Linker Flags”框中:
-B"/usr/lib/x86_64-linux-gnu/"
我的循環有???latency估計!
有時,HLS 綜合報告將包含?而不是給出最小和最大延遲的值。這是因為設計中至少有一個循環是數據相關的,即它循環的次數取決于 HLS 無法知道的數據值。
例如,下面的代碼:
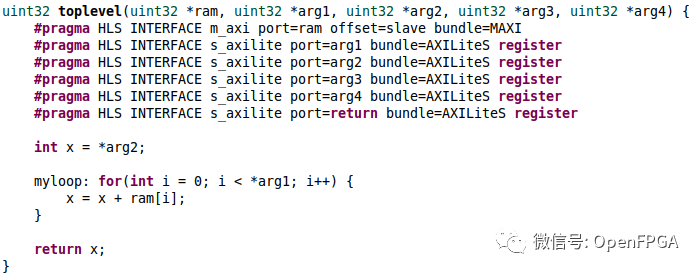
當綜合在綜合報告中給出以下內容:
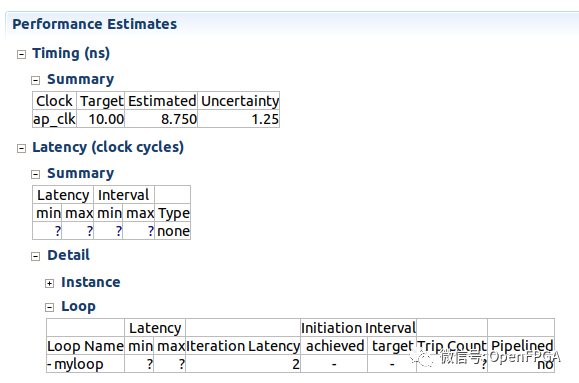
如果我們檢查代碼,它將來自ram的元素相加,但要相加的元素的確切數量來自用戶,作為arg1參數輸入。因此,HLS無法提前知道該硬件執行需要多長時間,因為每次運行時它都是可變的。這就是上面我們說的運行時依賴于數據。生成的硬件將正常工作,我們只是無法預測運行需要多長時間。查看循環的細節,HLS仍然可以告訴我們循環的延遲是2,換句話說,它不知道它將迭代多少次,但每次迭代將花費2個時鐘周期。
一般來說,應該盡量避免這種情況。如果 HLS 無法預測最壞的情況,那么它會過于“謹慎”,并且它可能會制造比我們需要的更大的硬件。此外,不能展開具有可變循環邊界的循環。
一些算法從根本上是依賴于數據的,如果這種情況無法避免,那么可以通過將LOOP_TRIPCOUNT指令添加到循環中來告訴 HLS ,假設循環將進行給定次數的迭代,但這僅用于報告目的。生成的硬件將完全相同,但HLS將在循環迭代該次數的假設下生成延遲數。這意味著延遲數字不“正確”,但這仍然有助于了解其他優化是否具有總體積極效果。
定點類型
當需要使用小數運算但又不想支付使用浮點的大量硬件成本時,定點類型很有用。Vitis HLS 用戶指南(https://www.xilinx.com/support/documentation/sw_manuals/xilinx2020_2/ug1399-vitis-hls.pdf)中詳細描述了定點類型,下面是一個簡短示例:
定點示例
#include
C標準數學函數(在math.h中)僅針對浮點實現,但Xilinx在hls_math.h中提供了某些函數的定點實現。在hls::命名空間下;例如:hls::sqrt()、hls::cos()和hls::sin()。
此外,以下賽靈思示例代碼顯示了另一種定點平方根實現,在某些情況下可能更有效。
fxp_sqrt.h
#ifndef__FXP_SQRT_H__
#define__FXP_SQRT_H__
#include
voidfxp_sqrt(ap_ufixed&result,ap_ufixed&in_val)
{
enum{QW=(IW1+1)/2+(W2-IW2)+1};//derivemaxrootwidth
enum{SCALE=(W2-W1)-(IW2-(IW1+1)/2)};//scale(shift)toadjinitialremainervalue
enum{ROOT_PREC=QW-(IW1%2)};
assert((IW1+1)/2<=?IW2);?//?Check?that?output?format?can?accommodate?full?result
???ap_uintq=0;//partialsqrt
ap_uintq_star=0;//diminishedpartialsqrt
ap_ints;//scaledremainderinitializedtoextractedinputbits
if(SCALE>=0)
s=in_val.range(W1-1,0)<else
s=((in_val.range(W1-1,0)>>(0-(SCALE+1)))+1)>>1;
//Non-restoringsquare-rootalgorithm
for(inti=0;i<=?ROOT_PREC;?i++)?{
??????if(s>=0){
s=2*s-(((ap_int(q)<else{
s=2*s+(((ap_int(q_star)<"extraiteration"method
if(s>0)
q=q+1;
//Truncateexcessbitandassigntooutputformat
result.range(W2-1,0)=ap_uint(q>>1);
}
#endif
總結
這是《FPGA高層次綜合HLS》系列教程第二篇,后面會按照專題繼續更新,文章有什么問題,歡迎大家批評指正~感謝大家支持。
審核編輯 :李倩
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
FPGA
+關注
關注
1645
文章
22025
瀏覽量
617561
-
HLS
+關注
關注
1
文章
133
瀏覽量
24802
原文標題:總結
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
如何在Unified IDE中創建視覺庫HLS組件
組件開始,該組件可以導出為 XO 文件用于 Vitis 系統工程;這與“自上而下的流程”相反,后者從 Vitis 工程開始,然后將 HLS 組件導入該工程。我們將創建視覺庫示例“remap”,并在 Unified IDE 中執行每一步,而不是運行 Makefile 腳本
![的頭像]() 發表于 07-02 10:55
?443次閱讀
發表于 07-02 10:55
?443次閱讀

使用AMD Vitis Unified IDE創建HLS組件
這篇文章在開發者分享|AMD Vitis HLS 系列 1 - AMD Vivado IP 流程(Vitis 傳統 IDE) 的基礎上撰寫,但使用的是 AMD Vitis Unified IDE,而不是之前傳統版本的 Vitis HLS。
![的頭像]() 發表于 06-20 10:06
?909次閱讀
發表于 06-20 10:06
?909次閱讀
如何使用AMD Vitis HLS創建HLS IP
本文逐步演示了如何使用 AMD Vitis HLS 來創建一個 HLS IP,通過 AXI4 接口從存儲器讀取數據、執行簡單的數學運算,然后將數據寫回存儲器。接著會在 AMD Vivado Design Suite 設計中使用此 HLS
![的頭像]() 發表于 06-13 09:50
?590次閱讀
發表于 06-13 09:50
?590次閱讀

AI知識庫的搭建與應用:企業數字化轉型的關鍵步驟
隨著數字化轉型的加速,AI技術已經成為提升企業運營效率、優化客戶體驗、推動業務創新的重要工具。而AI知識庫作為企業智能化的基礎,發揮著至關重要的作用。通過構建高質量的知識庫,企業能夠更好地組織、管理
![的頭像]() 發表于 03-27 15:18
?433次閱讀
發表于 03-27 15:18
?433次閱讀
《AI Agent 應用與項目實戰》閱讀心得3——RAG架構與部署本地知識庫
應用。第六章深入探討了RAG架構的工作原理,該技術通過在推理過程中實時檢索和注入外部知識來增強模型的生成能力。RAG架構的核心是檢索器和生成器兩大模塊,檢索器負責從知識庫中找到與當前查詢相關的文檔片段,生成器
發表于 03-07 19:49
DeepSeek賦能,研華KB Insight引領工業知識管理革命
在面對制造業占比超80%的非結構化數據情況下,研華KB Insight知識管理平臺借助于DeepSeek多模態處理技術,搭建核心處理框架,將加速各類知識庫的建設與完善,為企業數字化轉型注入了強大動力。
![的頭像]() 發表于 03-07 14:29
?362次閱讀
發表于 03-07 14:29
?362次閱讀
技術融合實戰!Ollama攜手Deepseek搭建知識庫,Continue入駐VScode
Ollama、Deepseek-R1、AnythingLLM 搭建強大的本地個人知識庫,并詳細介紹 Continue 在 VScode 中的本地集成,帶你解鎖全新的技術應用體驗,開啟高效知識管理與開發
![的頭像]() 發表于 03-04 14:47
?644次閱讀
發表于 03-04 14:47
?644次閱讀
如何從零開始搭建企業AI知識庫?
在數字化轉型的浪潮中,企業逐漸意識到數據不僅是資源,更是驅動業務增長的“燃料”。然而,分散在郵件、文檔系統、本地硬盤甚至員工腦海中的知識,往往如同孤島般難以串聯。AI知識庫的出現,正試圖將這些碎片化
![的頭像]() 發表于 02-28 14:35
?823次閱讀
發表于 02-28 14:35
?823次閱讀
用騰訊ima和Deepseek建立個人微信知識庫
---基于騰訊混元大模型或Deepseek-r推理模型的個人知識庫。大模型是通才,知識庫是專家大模型的訓練數據無法實時更新,而你的知識庫可以動態補充最新信息。大模型對細分領
![的頭像]() 發表于 02-25 17:33
?1349次閱讀
發表于 02-25 17:33
?1349次閱讀

DeepSeek從入門到精通(2):0成本用DeepSeek(滿血版)搭建本地知識庫
我們身處數字化浪潮中,知識管理和利用的重要性與日俱增。擁有一個專屬的本地知識庫,能極大提升工作效率,滿足個性化需求。但對于技術小白來說,搭建這樣的知識庫不僅存在技術門檻,同時也意味著需要一定的成本投入。
![的頭像]() 發表于 02-23 15:34
?607次閱讀
發表于 02-23 15:34
?607次閱讀

基于華為云 Flexus 云服務器 X 搭建部署——AI 知識庫問答系統(使用 1panel 面板安裝)
???對于企業來講為什么需要華為云 Flexus X 來搭建自己的知識庫問答系統??? 【重塑知識邊界,華為云 Flexus 云服務器 X 引領開源問答新紀元!】 ???解鎖知識新動力,華為云
![的頭像]() 發表于 01-17 09:45
?1924次閱讀
發表于 01-17 09:45
?1924次閱讀

華為云 Flexus 云服務器 X 實例之 openEuler 系統下搭建 MaxKB 開源知識庫問答系統
及個人開發者快速構建高效、靈活的應用環境。本文將詳細介紹如何利用華為云 Flexus 云服務器 X 實例搭建基于 openEuler 系統的 MaxKB 開源知識庫問答系統,為企業內部的知識管理和信息檢索注入新的活力。 一、Flexus 云服務器 X 實例介紹 1.1 F
![的頭像]() 發表于 01-17 09:44
?1326次閱讀
發表于 01-17 09:44
?1326次閱讀
騰訊ima升級知識庫功能,上線小程序實現共享與便捷問答
近日,騰訊旗下的AI智能工作臺ima.copilot(簡稱ima)迎來了知識庫功能的重大升級。此次升級不僅增加了“共享知識庫”的新能力,還正式上線了“ima知識庫”小程序,為用戶帶來了更加便捷和高效
![的頭像]() 發表于 12-31 15:32
?1817次閱讀
發表于 12-31 15:32
?1817次閱讀
直播預告 大模型 + 知識庫(RAG):如何使能行業數智化?
。最近,有小伙伴留言稱工作中常遇到知識管理問題: 知識管理雜亂無章、查找費時費力,而且信息孤島嚴重、知識難以共享,團隊成員總是重復勞動 ;希望能安排一場直播介紹如何通過智能化手段解決知識
![的頭像]() 發表于 11-26 23:49
?716次閱讀
發表于 11-26 23:49
?716次閱讀

【實操文檔】在智能硬件的大模型語音交互流程中接入RAG知識庫
非常明顯的短板。盡管這些模型在理解和生成自然語言方面有極高的性能,但它們在處理專業領域的問答時,卻往往不能給出明確或者準確的回答。
這時就需要接一個專有知識庫來滿足產品專有和專業知識的回復需求,理論
發表于 09-29 17:12





 工商網監
工商網監

評論