 神經渲染技術在自動駕駛領域應用
神經渲染技術在自動駕駛領域應用

大家好,我是郭建非,是3DNR團隊的負責人與 tech leader。
在本文中,我將為大家介紹團隊過去一年中圍繞「神經渲染技術在自動駕駛領域應用」的一些思考和研究成果。并且向大家展示團隊自研的現實級三維重建/編輯/仿真渲染框架——neuralsim 的部分階段性成果。該框架將在不久的將來完成開源。
1、自動駕駛傳感器仿真,是落地的下一步棋
1.1、為什么需要自動駕駛傳感器仿真?
近年來,自動駕駛技術發展突飛猛進,很多在實驗室中的實驗性項目已經逐步走向市場大眾。然而時至今日,自動駕駛技術仍然難以做到完全無人,甚至無法保證基本的安全性。究其根本,在于真實道路環境無限豐富,無法被窮舉、預測,存在著大量難以預測的邊界難例(Hard Corner Case)。
為了解決這個問題,大量自動駕駛公司通過海量路測來提高對邊界難例的覆蓋率,企圖通過遍歷這些危險場景來提高自動駕駛系統的實際安全性能。然而,想要通過路測來獲得足夠多的邊界難例,往往需要付出巨大的代價:難例的觸發效率呈邊際效應遞減,而每一次觸發都有可能導致一起重大交通事故。 這些客觀條件都在限制著我們利用真實車輛在真實世界中完成海量路測和邊界難例的覆蓋挖掘,而通過「仿真測試」以低成本獲得邊界難例數據逐漸被認為是解決自動駕駛落地難的不二法門。 早期的仿真測試主要針對決策規劃模塊進行,然而邊界難例不止存在于決策規劃系統中,感知系統也仍然存在無窮無盡的邊界難例。 2016年,一輛搭載著自動駕駛系統的汽車徑直撞向了一輛半掛卡車,駕駛員當場殞命。事后調查分析,自動駕駛系統誤以為白色的卡車車廂是明亮的天空,導致避障算法失效并產生災難性后果。足以窺見針對感知系統的傳感器數據仿真有時甚至比決策規劃仿真更為重要。
1.2、基于神經渲染的重建、編輯與傳感器仿真框架
目前已有諸如 VTD、51 SimOne、NVIDIA DRIVE Sim 等針對感知系統的仿真和測試平臺。這些平臺大多基于游戲引擎,利用基于物理渲染的傳統圖形學管線進行仿真渲染。然而,這種傳統方法存在一系列問題。
由于圖形和當前游戲管線的技術限制,構建超真實的 3D 場景成本高昂,自動化程度低,需要大量人力的介入,且周期較長。針對這個問題,部分方案引入攝影測量等傳統 3D 重建技術,來重建真實城市道路場景,但受限于自動駕駛真實數據本身的特點,難以完成全場景的稠密重建和高質量的真實渲染,需要進行人為二次修正和加工。此外,也有通過過程生成等 3D 圖形技術,實現自動化生成城市場景的方式,但這種方式同樣在復雜性、真實度上都和真實駕駛場景存在較大差異。
為此,3DNR團隊(基礎算法)聯合商湯絕影團隊(業務拓展優化),構建了一套直接利用真實車端數據的隱式重建和編輯仿真方案。我們的方案將實車采集的多視圖像、激光雷達數據轉化為神經網絡表示的3D場景庫和3D數字資產庫,基于隱表面神經體渲染技術,能夠渲染以假亂真的相機圖像、激光雷達點云,實現「現實級」三維重建和仿真。并且,場景中的要素能夠自由地組合控制、軌跡編輯,泛化出新的場景,通過批量仿真渲染,可以產生高一致性的2D/3D傳感器數據和2D/3D/4D語義真值標注,以服務于感知系統的測試和訓練,邁向自動駕駛數據閉環。我們致力于通過直接實現盡可能全自動的、高一致性的三維重建,大大減少渲染仿真數據與真實場景的領域差異,通過 sim≈real 的思路直接避免 sim2real 的 gap。
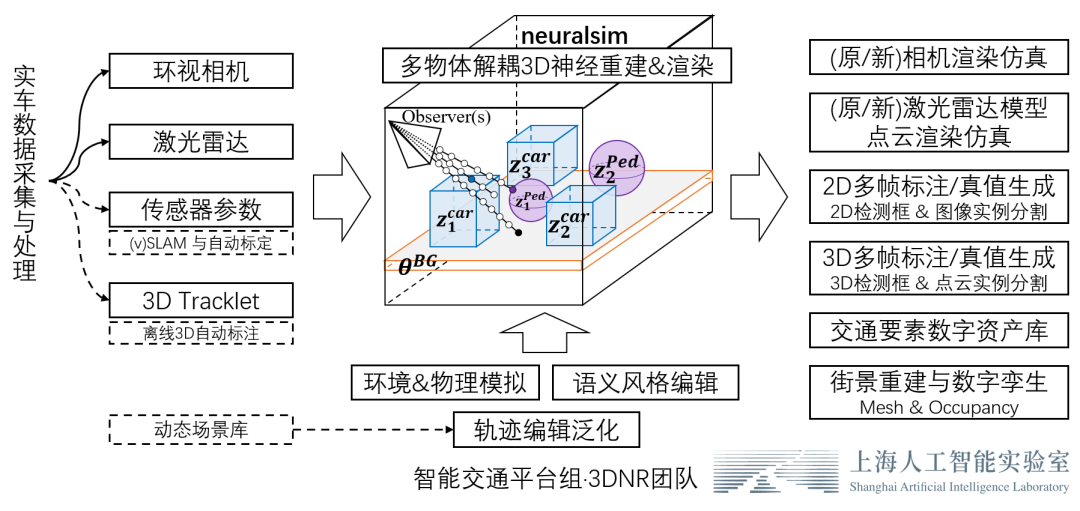
整體工作思路
在下文中,我將依次按照「照片級前背景聯合重建」「高效的傳感器仿真&語義真值仿真」「場景編輯與數據閉環」 三個章節的順序來介紹我們的工作。

整體成果概覽2、照片級前背景聯合隱式三維重建2.1、多幀多模態多視圖三維重建我們可以直接利用實車采集數據,實現對真實街景的前背景聯合三維重建。為了方便與學界業界交流對比,我們直接使用 waymo 公開的學術開源數據集 waymo-perception 數據集進行效果展示。
waymo-perception 數據集包含約800個訓練集序列,我們挑選了其中3-4個序列進行展示;每個序列長度200幀左右,我們使用序列原始數據中的 前向、左前、右前 3個機位的環視相機圖像數據 和頂部激光雷達數據,以及對應的傳感器內外參數據、自車位姿數據進行多視圖三維重建。 以 waymo perception - 405841xx 序列為例:

waymo perception -segment405841xx
原始數據(節選)真值
我們的多視圖重建方法主要利用多幀圖像數據進行;激光雷達數據主要是為地面的高度和三維結構補充必要的消歧信息,因此并不要求激光雷達涵蓋相機的全部視野。對于我們使用的 waymo-perception 數據集而言,在上圖中也可以看到,如果將激光雷達點云投射到相機圖像中,激光雷達點云只涵蓋了圖像下半部分的視野。
下面的視頻展示了該場景下我們的隱式三維重建的質量和神經渲染的效果。可以看到,我們的方法能夠實現以假亂真的三維重建和渲染質量。
如果場景中包含動態要素(如他車、行人),大多數傳統的針對純靜態場景的多視圖重建工作將不再適用。但是,如果說「沒有街景背景不能稱作自動駕駛」,那么「沒有豐富的前景物體參與交通更不能被稱之為自動駕駛」。
因此,我們顯式地區分構建了整體的靜態背景和動態前景兩套3D表征,并設計了一套高效的多物體可微渲染框架。并且,我們通過預先針對前景物體類別構建3D類別先驗的方式,解決了前景少視角重建的病態問題,實現了只依賴三維跟蹤檢測框標注(3D Tracklet)、無需2D圖像分割標注,即可對場景中的前景和背景進行聯合的隱式三維重建。
以 waymo perception - 767010xxx 序列為例:

waymo perception-segment 767010xx
原始數據(節選)真值 在下面的視頻中可以看到,即使面對包含動態前景物體的復雜街景數據序列,我們可以在前景和背景均達到較高的重建質量和渲染效果。
下面的視頻中,展示了在更多的 waymo-perception 序列場景下,我們的方法在完整重建后再回放渲染的效果:
2.2、背景新視角合成
除了回放再渲染外,驗證重建質量的另一個重要方式是新視角合成(Novel View Synthesis)。在下面的視頻中,展示了讓自車在重建好的場景中自由地螺旋穿梭前進時的多模態傳感器渲染仿真效果:
2.3、前景新視角合成不止背景,重建好的前景也可以進行新視角合成,如下圖所示:
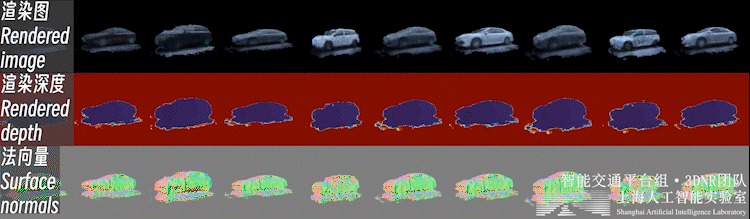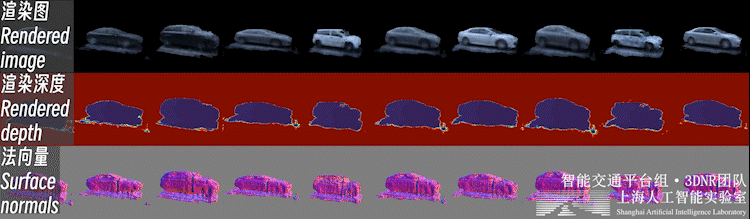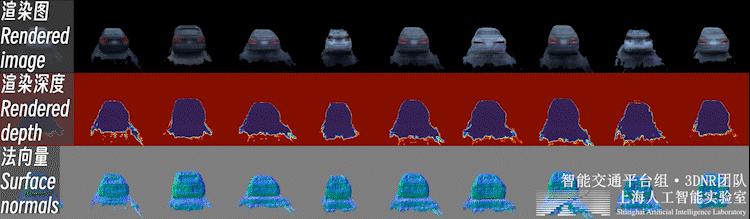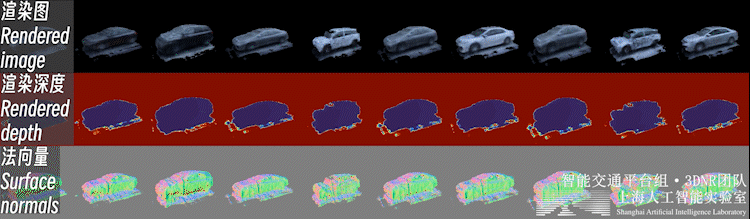
自動駕駛場景下,前景物體普遍面臨觀測視角少、不均勻的問題。直接對前景物體從頭開始(learn from scratch)的三維重建是個高度病態的問題。
因此,我們利用開源類別泛化多視數據集,預先構建了三維生成模型(3DGAN),構建了車輛、行人等交通參與要素的3D形狀與外觀的類別先驗。這樣的生成模型可以理解為一個 「實例個數=∞」 的數字資產庫(i.e. 每一個隨機噪聲對應一個獨特實例)。
之后,即可利用三維生成模型的逆向過程,在這個數字資產庫中可微地 “檢索” 出一個符合實際觀測的實例,完成少視角重建過程,如下圖所示。

在我們的實際應用中,上述前景重建過程和背景的重建是同時進行的。得益于先前構建的3D類別先驗,我們的方法能夠只依賴3D跟蹤檢測框標注進行前背景聯合重建,而不需要圖像實例分割。 3、高效的傳感器仿真和語義真值仿真不同于 NeRF 原始的體密度 (Volume density)形狀表達,我們選擇和拓展了 對仿真編輯和圖形引擎更友好的 SDF 隱表面表示 (e.g. NeuS),使得場景的3D幾何表示有明確的表面定義和深度概念。
在下圖中,我們利用相機對隱表面神經渲染得到的深度,直接對相機2D像素升維得到3D點云,然后將每一幀的相機圖像對應的3D點云拼接在一起,進行可視化展示。可以看到,我們的隱表面神經渲染技術具有較高的多視一致性。

利用重建得到的高一致性的3D場景幾何與3D場景外觀,我們得以仿真高度真實的新傳感器的數據。
3.1、相機模型仿真渲染利用重建好的場景,我們可以仿真渲染新的相機模型的圖像。在下圖中,展示了我們將 waymo 序列原相機的 51° 的視場角逐漸提升到 109°,并加上一定的超廣角畸變后,對一個109°視場角的超廣角相機模型進行仿真渲染。

3.2、激光雷達模型仿真渲染 利用與現實高度一致的場景與物體的3D幾何形狀,我們可以對不同于原序列的新的激光雷達模型進行仿真渲染。在下面的視頻中,我們對重建好的 waymo-767010xxx 序列,仿真渲染8款不同于原序列的激光雷達模型的點云數據。這些新的激光雷達模型包括機械旋轉式、固態、棱鏡式等多種不同類型。 3.3、2D/3D/4D語義仿真得益于我們設計的多物體渲染框架,我們還能夠仿真產生多幀的2D/3D的語義真值標注。
根據相機渲染過程中,逐2D像素對應的3D光線和不同物體3D幾何的相交關系和順序,可以渲染產生圖像2D實例分割標注;同理,根據激光雷達渲染過程中,逐LiDAR光束和不同物體3D幾何的相交關系和順序,可以渲染產生激光雷達點云3D實例分割標注。
在下面的視頻中,針對重建好的 waymo-767010xxx 序列,展示了我們方法仿真渲染圖像、仿真渲染多幀圖像2D實例分割標注、仿真渲染多幀LiDAR 3D實例分割 (i.e. 4D語義標注)的效果:
3.4、高效渲染與仿真我們在神經體渲染底層技術棧中鋪設了若干基礎建設式的創新。我們吸納了分層局部隱式神經表征的思想,設計了分塊表征與塊間連續性保證算法,并利用自舉更新的占用格對體渲染中的光線采樣過程進行加速。這些創新除了讓我們達到前文所展示的重建質量外,還使得我們的神經渲染過程達到接近實時的效率。
下圖簡單展示了我們的重建方法的分塊表征以及可鼠標交互的實時神經渲染:

我們針對前景設計的3DGAN模型同樣實現了一套利用占用格的批量(batched)光線采樣加速算子,顯著提升了前背景多物體聯合渲染的效率。 4、場景編輯與數據閉環4.1、隨意的可控顯式/隱式編輯我們的方法將前景和背景都解耦地視作獨立的可渲染物體。因此,我們可以對場景中的任一物體模型進行隨意的操作和編輯,如下面視頻所示: 除了前面展示的針對場景中物體的顯式編輯方式外,我們也初步探索了在語義層面的風格化編輯,如下面視頻所示: 4.2、軌跡編輯與場景泛化結合動態場景庫和軌跡規劃算法,我們還可以對場景中的自車和他車進行更符合常理的編輯,即仿真新的駕駛行為。
在下面的視頻中,我們依次展示了「左車突然切入(cut in)」,「右車闖紅燈」,「前車急停追尾」 3種不同的場景編輯方式,渲染其在“平行宇宙” 中的虛擬交通事件。
以其中的「左車突然切入(cut in)」場景為例,下面這個視頻展示了對編輯后的場景的多模態傳感器仿真結果:(相機、深度傳感器、8款激光雷達模型)
在今后,我們可以更進一步地利用實車數據擴充3D場景庫、擴充前景數字資產庫,從而泛化出更多新的物體組合和場景序列。搭配前述 「一次重建、終身受用」的新相機、新激光雷達模型仿真渲染范式,我們的方案最終能夠按照給定的場景、給定的物體組合、給定的軌跡、給定的傳感器模型定制化地渲染出海量高度真實的傳感器數據和語義真值,從而逐漸達成我們構想的通過傳感器數據仿真大大提升自動駕駛測試效率和質量的愿景。 5、寫在最后神經渲染技術作為新興領域,成功地構建起了場景表征與成像過程之間的可微橋梁,能夠很好地結合不同領域的先驗知識,使得圖像相關的機器學習研究逐漸走向可解釋、可控可編輯的3D語義時代。我們堅信,不僅僅是自動駕駛,神經渲染技術將在越來越多的領域走向成熟應用。
我們3DNR團隊將繼續以自動駕駛數據閉環為理想目標,沿途下蛋挖掘攻關基礎學術關鍵點,并秉持開源和共享精神,與學界業界共同學習共同進步。
審核編輯 :李倩
-
傳感器
+關注
關注
2550文章
51041瀏覽量
753097 -
數據集
+關注
關注
4文章
1208瀏覽量
24690 -
自動駕駛
+關注
關注
784文章
13786瀏覽量
166399
原文標題:神經渲染技術在自動駕駛領域應用
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
一文聊聊自動駕駛測試技術的挑戰與創新

MEMS技術在自動駕駛汽車中的應用
人工智能的應用領域有自動駕駛嗎
自動駕駛技術的典型應用 自動駕駛技術涉及到哪些技術
FPGA在自動駕駛領域有哪些優勢?
FPGA在自動駕駛領域有哪些應用?
自動駕駛的傳感器技術介紹
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
華為自動駕駛技術怎么樣?
自動駕駛領域中,什么是BEV?什么是Occupancy?






 工商網監
工商網監
評論