") DPU發(fā)展的關(guān)鍵技術(shù)是什么
DPU發(fā)展的關(guān)鍵技術(shù)是什么
2023年1月7日,中國(guó)信息通信研究院聯(lián)合開(kāi)放數(shù)據(jù)中心委員會(huì)發(fā)布了《DPU發(fā)展分析報(bào)告(2022年)》。
DPU 將成為下一代芯片技術(shù)競(jìng)爭(zhēng)的高地。作為數(shù)據(jù)中心繼 CPU 和GPU之后的"第三顆主力芯片",DPU的演進(jìn)也經(jīng)歷了從眾核CPUNP、FPGA+CPU到ASIC+CPU的多個(gè)發(fā)展階段或者技術(shù)演進(jìn)。
基于CPU/NP、FPGA+CPU的硬件架構(gòu)分別具備軟件可編程和硬件可編程的靈活優(yōu)勢(shì),在DPU發(fā)展的初期尤其受到互聯(lián)網(wǎng)云廠商大廠自研方案的青睞,在快速迭代和靈活定制方面有比較明顯的收益。
然而,隨著網(wǎng)絡(luò)帶寬的快速增長(zhǎng),網(wǎng)絡(luò)接入帶寬迅速?gòu)?0G、25G演進(jìn)到了100G、200G之后,基于CPU/NP和FPGA+CPU這類硬件架構(gòu)的DPU除了在性能上難以為繼以外,在成本和功耗上則有更大的挑戰(zhàn)。基于ASIC+CPU的硬件架構(gòu)則是結(jié)合了ASIC和CPU二者的優(yōu)勢(shì),即將通用處理器的可編程靈活性與專用的加速引擎相結(jié)合,正在成為最新的產(chǎn)品趨勢(shì)。
業(yè)界的頭部廠商N(yùn)VIDIA、Intel和AMD(收購(gòu)Pensando)的DPU架構(gòu)都采用了這種架構(gòu)路線。
從DPU 芯片的實(shí)現(xiàn)角度看,以 ASIC+CPU 的硬件架構(gòu)為例,CPU的研發(fā)更多的是以系統(tǒng)級(jí)芯片的方式集成第三方成熟的CPU多核IP,不同DPU廠商的核心競(jìng)爭(zhēng)壁壘在于專用加速引擎的硬件實(shí)現(xiàn)上。由于DPU是數(shù)據(jù)中心中所有服務(wù)器的流量入口,并以處理報(bào)文的方式處理數(shù)據(jù),在網(wǎng)絡(luò)芯片領(lǐng)域積累更多的廠商將更有優(yōu)勢(shì)。
(一)RDMA高速網(wǎng)絡(luò)技術(shù)1、RDMA的技術(shù)背景
傳統(tǒng)TCP/IP協(xié)議棧在處理報(bào)文轉(zhuǎn)發(fā)的過(guò)程當(dāng)中,從用戶態(tài)到內(nèi)核協(xié)議棧再經(jīng)過(guò)網(wǎng)卡轉(zhuǎn)發(fā)出去這個(gè)過(guò)程中,要觸發(fā)多次CPU的上下文切換,發(fā)生多次的內(nèi)存拷貝,由于多次數(shù)據(jù)拷貝,轉(zhuǎn)發(fā)延時(shí)一直較高,隨著網(wǎng)絡(luò)帶寬的提升,傳統(tǒng)內(nèi)核處理報(bào)文的方式已經(jīng)無(wú)法滿足更高帶寬,更低延時(shí)的業(yè)務(wù)需求。
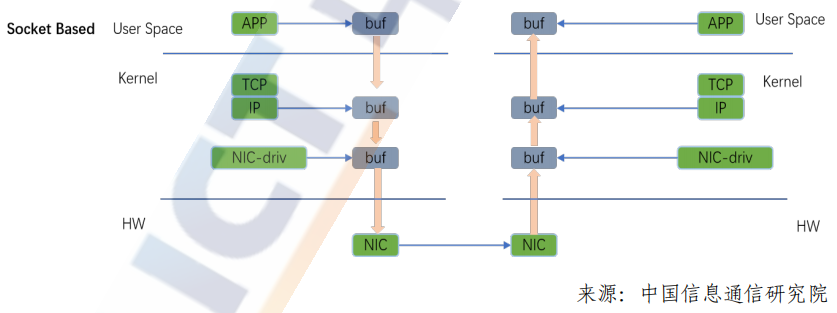
RDMA 是一種遠(yuǎn)程直接內(nèi)存訪問(wèn)技術(shù),它將數(shù)據(jù)直接從一臺(tái)計(jì)算機(jī)的內(nèi)存?zhèn)鬏數(shù)搅硪慌_(tái)計(jì)算機(jī)的內(nèi)存,數(shù)據(jù)從一端主機(jī)的內(nèi)存通過(guò)DMA方式從網(wǎng)卡轉(zhuǎn)發(fā)出去,到另一端通過(guò)網(wǎng)卡DMA直接寫入另一端主機(jī)的內(nèi)存,整個(gè)數(shù)據(jù)傳輸過(guò)程無(wú)須操作系統(tǒng)以及CPU參與,這種CPU/內(nèi)核協(xié)議棧的bypass技術(shù)通過(guò)硬件網(wǎng)卡實(shí)現(xiàn),可以滿足未來(lái)網(wǎng)絡(luò)對(duì)高帶寬、低延時(shí)的需求,并進(jìn)一步釋放CPU的計(jì)算資源。?RDMA技術(shù)具有以下特點(diǎn):
CPU卸載:用戶態(tài)應(yīng)用程序通過(guò)調(diào)用IB verbs接口直接訪問(wèn)遠(yuǎn)程主機(jī)的內(nèi)存,可以對(duì)遠(yuǎn)程內(nèi)存執(zhí)行讀取、寫入、原子操作等多種操作,而且無(wú)須兩端主機(jī)CPU參與。
內(nèi)核旁路:RDMA采用基于verbs的編程方式,不同于socket編程方式,需要用戶態(tài)與內(nèi)核態(tài)的切換,應(yīng)用程序可以直接在用戶態(tài)調(diào)用RDMA的verbs接口,消除上下文切換帶來(lái)的額外開(kāi)銷,并實(shí)現(xiàn)了額內(nèi)核系統(tǒng)旁路。
零拷貝:本端應(yīng)用程序內(nèi)存數(shù)據(jù)通過(guò)網(wǎng)卡DMA直接發(fā)送到遠(yuǎn)端網(wǎng)卡,遠(yuǎn)端網(wǎng)卡通過(guò)DMA方式直接寫入對(duì)端內(nèi)存,整個(gè)過(guò)程中消除了傳統(tǒng)TCP/IP傳輸方式的多次內(nèi)存拷貝的過(guò)程,實(shí)現(xiàn)內(nèi)存零拷貝,進(jìn)一步降低整個(gè)網(wǎng)絡(luò)延時(shí)。
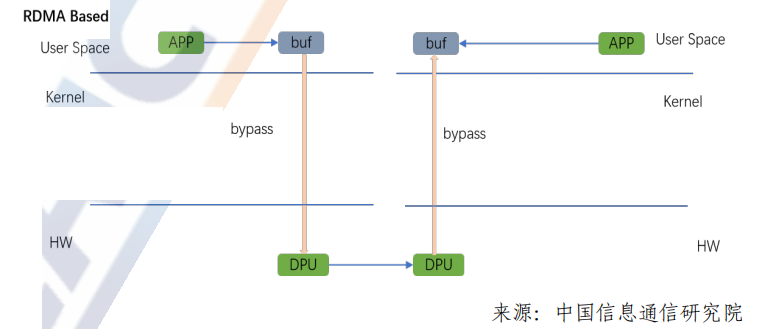
為了達(dá)到RDMA在高性能和低延時(shí)上的技術(shù)優(yōu)勢(shì),RDMA有高的技術(shù)門檻,需要端到端的擁塞控制來(lái)避免擁塞和降低網(wǎng)絡(luò)延時(shí)。實(shí)現(xiàn)端到端的高性能RDMA網(wǎng)絡(luò)需要考慮:
1)網(wǎng)絡(luò)收斂比。進(jìn)行數(shù)據(jù)中心網(wǎng)絡(luò)架構(gòu)設(shè)計(jì)時(shí),從成本和收益兩方面來(lái)考慮,多數(shù)會(huì)采取非對(duì)稱帶寬設(shè)計(jì),即上下行鏈路帶寬不一致,交換機(jī)的收斂比簡(jiǎn)單說(shuō)就是總的輸入帶寬除以總的輸出帶寬;
2)ECMP等價(jià)哈希均衡。當(dāng)前數(shù)據(jù)中心網(wǎng)絡(luò)多采用Fabric架構(gòu),并采用ECMP來(lái)構(gòu)建多條等價(jià)負(fù)載均衡的鏈路,通過(guò)設(shè)置擾動(dòng)因子,采用 HASH 選擇一條鏈路來(lái)轉(zhuǎn)發(fā)是簡(jiǎn)單的,但這個(gè)過(guò)程中卻沒(méi)有考慮到所選鏈路本身是否有擁塞。ECMP并沒(méi)有擁塞感知的機(jī)制,只是將流分散到不同的鏈路上轉(zhuǎn)發(fā),對(duì)于已經(jīng)產(chǎn)生擁塞的鏈路來(lái)說(shuō),很可能加劇鏈路的擁塞;
3)Incast流量模型,Incast是多打一的通信模式,在數(shù)據(jù)中心云化的大趨勢(shì)下這種通信模式常常發(fā)生,尤其是那些以Scale-Out方式實(shí)現(xiàn)的分布式存儲(chǔ)和計(jì)算應(yīng)用,包括EBS云存儲(chǔ)、AI集群、高性能數(shù)據(jù)庫(kù)、Hadoop、MapReduce、HDFS等;
4)無(wú)損網(wǎng)絡(luò)交換機(jī)的流量控制、QoS和擁塞控制機(jī)制以及相應(yīng)的水線設(shè)置,能夠讓RDMA得到規(guī)模部署且廣泛應(yīng)用的就需要RDMA的擁塞控制算法支撐。在Fabric網(wǎng)絡(luò)復(fù)雜、多路徑的場(chǎng)景下,伴隨著多打一、突發(fā)等情況的出現(xiàn),是擁塞控制算法讓RDMA的高性能得以充分展現(xiàn),為RDMA的高性能保駕護(hù)航。
端到端擁塞控制算法的基本原理是依托擁塞節(jié)點(diǎn)交換機(jī)對(duì)出向?報(bào)文的 ECN標(biāo)記,目的端通過(guò)ECN標(biāo)記處理反饋 CNP使得源端進(jìn)行速率調(diào)節(jié),從而達(dá)到解決擁塞的目的。
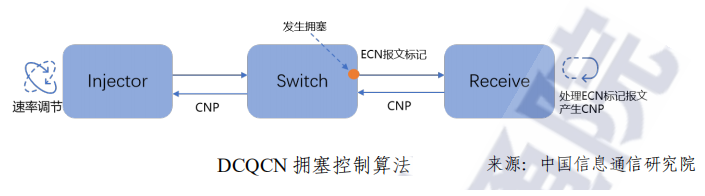
隨著RDMA技術(shù)的普及,不同的云廠商用戶結(jié)合不同的業(yè)務(wù)場(chǎng)景和網(wǎng)絡(luò)環(huán)境提出了多種擁塞控制算法,比較有代表的算法有被業(yè)界?大規(guī)模驗(yàn)證過(guò)的DCOCN算法,阿里提出的HPCC算法,以及谷歌提?出的TIMELY和Swift算法等。不同的用戶或者業(yè)務(wù)場(chǎng)景有不同擁塞控制算法的需求。因此,DPU芯片需要支持多種擁塞控制算法,或者能夠一步到位支持擁塞控制算法的可編程能力。
2、RDMA的應(yīng)用價(jià)值
RDMA對(duì)比傳統(tǒng)TCP傳輸方式在提升吞吐,降低CPU占用、降低延時(shí)方面均有明顯的優(yōu)勢(shì)。后摩爾時(shí)期尤其是在網(wǎng)絡(luò)進(jìn)入100G甚至200G以上的帶寬情況下,傳統(tǒng)TCP協(xié)議棧內(nèi)核轉(zhuǎn)發(fā)完全無(wú)法滿足性能要求,隨著網(wǎng)絡(luò)技術(shù)的演進(jìn),高吞吐、低延時(shí)的RDMA技術(shù)將承擔(dān)基礎(chǔ)的網(wǎng)絡(luò)傳輸功能,進(jìn)一步提升數(shù)據(jù)中心整體算力。
RDMA 憑借其高吞吐、低延時(shí)、CPU旁路、適應(yīng)性廣、技術(shù)成熟等特點(diǎn),已經(jīng)成為數(shù)據(jù)中心基礎(chǔ)服務(wù)的一個(gè)重要組成部分,承載著多種不同的業(yè)務(wù)類型,并且隨著網(wǎng)絡(luò)技術(shù)以及應(yīng)用的發(fā)展,RDMA的應(yīng)用將進(jìn)一步擴(kuò)大。
(二)數(shù)據(jù)面轉(zhuǎn)發(fā)技術(shù)
隨著網(wǎng)絡(luò)流量的指數(shù)增長(zhǎng),基于硬件數(shù)據(jù)面轉(zhuǎn)發(fā)技術(shù)越來(lái)越受到關(guān)注,在傳統(tǒng)交換機(jī)和路由器上已經(jīng)成熟應(yīng)用的數(shù)據(jù)面轉(zhuǎn)發(fā)技術(shù)也被應(yīng)用到了DPU領(lǐng)域。在數(shù)據(jù)面硬件轉(zhuǎn)發(fā)技術(shù)中,基本的硬件處理架構(gòu)有兩種:基于NP的run-to-completion(RTC)架構(gòu)和pipeline架構(gòu)。
1、基于NP的RTC轉(zhuǎn)發(fā)架構(gòu)
通用RTC(Real-Time Clock)處理器轉(zhuǎn)發(fā)模型,報(bào)文進(jìn)入后,經(jīng)過(guò)調(diào)度分發(fā)器后,被分配到一個(gè)報(bào)文處理引擎上處理。RTC是一種非搶占機(jī)制,當(dāng)報(bào)文進(jìn)入該處理引擎后,根據(jù)轉(zhuǎn)發(fā)需求進(jìn)行處理,直到處理結(jié)束退出。
在RTC架構(gòu)中,每個(gè)處理器上都是標(biāo)準(zhǔn)的馮諾依曼架構(gòu),包括:程序計(jì)數(shù)器(PC)、指令存儲(chǔ)器、譯碼器、寄存器堆、邏輯運(yùn)算單元(ALU),其中指令存儲(chǔ)器多個(gè)核之間共享。通常報(bào)文處理流程通過(guò)C語(yǔ)言或微碼編程后,會(huì)被編譯成一系列的指令執(zhí)行。由于轉(zhuǎn)發(fā)需求和報(bào)文長(zhǎng)度不同,每個(gè)報(bào)文在處理器內(nèi)部的處理時(shí)間差異很大。
2、Pipeline轉(zhuǎn)發(fā)架構(gòu)
Pipeline架構(gòu)中,整個(gè)處理流程被拆分成多個(gè)不同的處理階段,對(duì)應(yīng)到不同的步驟,每一級(jí)轉(zhuǎn)發(fā)處理可以做成專用的硬件處理單元。當(dāng)?shù)谝粋€(gè)報(bào)文執(zhí)行完第一個(gè)步驟,進(jìn)入第二個(gè)步驟時(shí),第二個(gè)報(bào)文可以進(jìn)入流水線中的第一個(gè)步驟進(jìn)行處理。
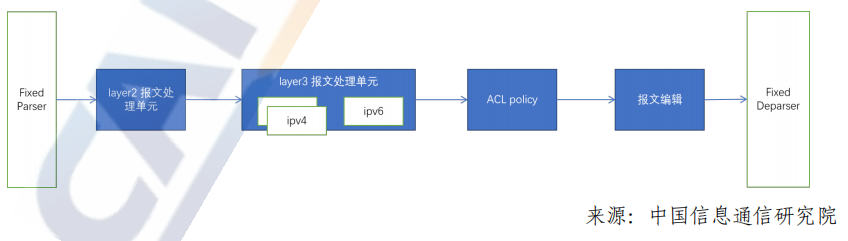
根據(jù)業(yè)務(wù)需求,將轉(zhuǎn)發(fā)流程拆分成多個(gè)處理步驟,每個(gè)步驟中只執(zhí)行特定的邏輯處理,主要應(yīng)用在數(shù)據(jù)中心交換機(jī)上,比如:Broadcom TD系列。
Match-Action Pipeline架構(gòu)也是一種業(yè)界常用的pipeline架構(gòu)為,與固化Pipeline架構(gòu)相比,每個(gè)步驟中可根據(jù)業(yè)務(wù)生成靈活的查表信息,根據(jù)查表結(jié)果,對(duì)報(bào)文進(jìn)行相應(yīng)的邏輯處理,如下圖所示。
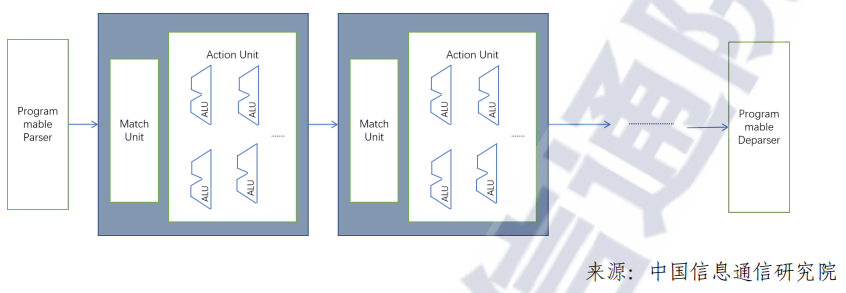
在性能上,固化Pipeline架構(gòu)近乎定制化ASIC,相比于可編程Pipeline架構(gòu),吞吐更高,時(shí)延更低,邏輯處理單元復(fù)雜度更低?與可編程Pipeline相比,固化Pipeline,不支持可編程和新的業(yè)務(wù)添加。而可編程MA架構(gòu)可以保留一部分靈活可拓展性,在資源允許的情況下,支持新業(yè)務(wù)拓展。
3、Pipeline vs RTC
Pipeline 和 RTC 作為兩個(gè)主流轉(zhuǎn)發(fā)架構(gòu),RTC架構(gòu)在轉(zhuǎn)發(fā)業(yè)務(wù)中表項(xiàng)出豐富的靈活性,但隨著網(wǎng)絡(luò)流量的不斷增加,Pipeline架構(gòu)表現(xiàn)出相對(duì)優(yōu)勢(shì):
在性能方面,1)在相同處理性能下,RTC架構(gòu)中通常采用多核多線程,來(lái)提高轉(zhuǎn)發(fā)性能,由于多線程面積占比較高(每個(gè)線程獨(dú)立維護(hù)相應(yīng)的寄存器信息),報(bào)文進(jìn)入處理器的調(diào)度和多核報(bào)文調(diào)度轉(zhuǎn)發(fā)邏輯資源面積較大,導(dǎo)致芯片面積和功耗通常為Pipeline架構(gòu)的數(shù)倍。2)由于多核處理器訪問(wèn)內(nèi)存,導(dǎo)致帶寬壓力較大。為提高轉(zhuǎn)發(fā)性能,內(nèi)存會(huì)被復(fù)制多份,降低內(nèi)存訪問(wèn)沖突,導(dǎo)致內(nèi)存占用率很高。
時(shí)延方面,在Pipeline架構(gòu)下,不同步驟中的memory資源靜態(tài)分配,報(bào)文在轉(zhuǎn)發(fā)過(guò)程中執(zhí)行的指令信息提前預(yù)知。和 RTC 架構(gòu)相比,能夠大大降低由于讀寫/查表沖突帶來(lái)的時(shí)延,通常 pipeline架構(gòu)對(duì)報(bào)文的處理時(shí)延是 RTC 架構(gòu)的數(shù)十分之一。
從功耗、性能、面積的角度考慮,DPU跟隨網(wǎng)絡(luò)流量需求變化(業(yè)務(wù)需求不斷豐富、網(wǎng)絡(luò)時(shí)延敏感、功耗要求更低),基于可編程Pipeline的硬件架構(gòu)更符合DPU加速硬件報(bào)文轉(zhuǎn)發(fā)的發(fā)展方向。
(三)網(wǎng)絡(luò)可編程技術(shù)
在以算力為中心的時(shí)代,網(wǎng)絡(luò)邊緣設(shè)備已經(jīng)從柜頂交換機(jī)延展到DPU,DPU已經(jīng)成為數(shù)據(jù)中心內(nèi)部網(wǎng)絡(luò)連接計(jì)算、存儲(chǔ)的新的接入節(jié)?點(diǎn),面對(duì)不斷變化的網(wǎng)絡(luò)業(yè)務(wù)需求和自定義網(wǎng)絡(luò)擴(kuò)展能力的需要,支持網(wǎng)絡(luò)可編程技術(shù)成為DPU應(yīng)用于新一代數(shù)字基礎(chǔ)設(shè)施的關(guān)鍵技術(shù)因素。
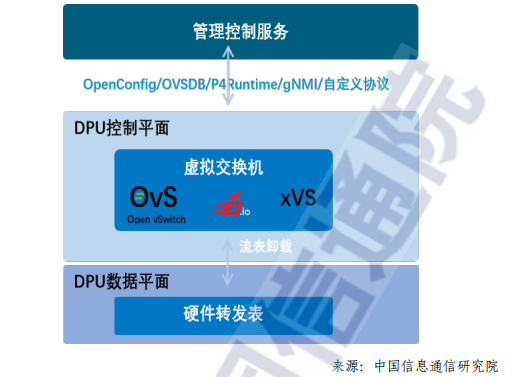
DPU上網(wǎng)絡(luò)可編程技術(shù)主要包括控制平面網(wǎng)絡(luò)可編程技術(shù)和數(shù)據(jù)平面網(wǎng)絡(luò)可編程技術(shù),其中控制平面網(wǎng)絡(luò)可編程技術(shù)主要應(yīng)用于DPU 內(nèi)部的通用系統(tǒng)級(jí)芯片上,而數(shù)據(jù)平面網(wǎng)絡(luò)可編程技術(shù)則主要應(yīng)用在硬件加速器部分。
目前DPU數(shù)據(jù)平面網(wǎng)絡(luò)可編程技術(shù)主要包括基于快速流表和基于P4流水線兩種常見(jiàn)技術(shù)。
(四)開(kāi)放網(wǎng)絡(luò)及DPU軟件生態(tài)
由于DPU芯片的發(fā)展還處于早期階段,DPU的軟件生態(tài)也處于萌芽狀態(tài)。目前,市場(chǎng)上主流的開(kāi)放網(wǎng)絡(luò)及 DPU 軟件生態(tài)主要有Linux 基金會(huì)宣布的開(kāi)放可編程基礎(chǔ)設(shè)施——OPI項(xiàng)目、由 Intel 驅(qū)動(dòng)主導(dǎo)的 IPDK 框架、Nvidia DPU的開(kāi)源軟件開(kāi)發(fā)框架 DOCA、開(kāi)放數(shù)據(jù)中心委員會(huì)開(kāi)展的無(wú)損網(wǎng)絡(luò)項(xiàng)目等。
DPU 作為數(shù)據(jù)中心基礎(chǔ)設(shè)施的一顆重要芯片,擁有一個(gè)社區(qū)驅(qū)動(dòng)的、基于標(biāo)準(zhǔn)的開(kāi)放生態(tài)系統(tǒng),以開(kāi)放的形式定義DPU標(biāo)準(zhǔn)可編程基礎(chǔ)設(shè)施生態(tài),對(duì)DPU的長(zhǎng)期發(fā)展至關(guān)重要。
一個(gè)富有生命力的DPU的軟件生態(tài)需要具備條件為提供一個(gè)基于開(kāi)放社區(qū)的DPU軟件堆棧以及用戶驅(qū)動(dòng),且與供應(yīng)商無(wú)關(guān)的軟件框架和架構(gòu)。支持既有的DPU開(kāi)源應(yīng)用程序生態(tài)系統(tǒng),包括DPDK,OVS,SPDK 等已經(jīng)在用戶側(cè)有廣泛應(yīng)用的開(kāi)源應(yīng)用軟件。
基于以上標(biāo)準(zhǔn)我們對(duì)現(xiàn)有的DPU軟件生態(tài)做比較,SONiC是由用戶驅(qū)動(dòng)的開(kāi)放網(wǎng)絡(luò)平臺(tái)項(xiàng)目。SONiC是由微軟于2016年發(fā)起,其所有軟件功能模塊都來(lái)自開(kāi)源生態(tài)。如下圖所示,SONiC通過(guò)將SAI 接口作為統(tǒng)一的硬件管理接口,由各廠商在SAI接口之下實(shí)現(xiàn)對(duì)應(yīng)硬件驅(qū)動(dòng),通過(guò)這樣的方式屏蔽不同廠商硬件之間的驅(qū)動(dòng)差異,使 SONiC軟件可以運(yùn)行在各種硬件設(shè)備中,形成白盒交換機(jī)統(tǒng)一的軟件生態(tài)。
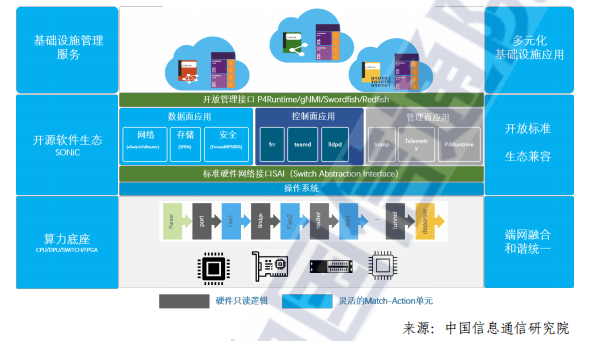
在P4 可編程和DPU的支持方面,SONiC先是通過(guò)PINS(P4 Integrated Network Stack)在 SDN 市場(chǎng)白盒交換機(jī)中落地了最佳實(shí)踐,得到了產(chǎn)業(yè)界的廣泛支持;之后又推出了 SONiC DASH (Disaggregated API for SONiC Hosts)版本,將SONiC在 SDN 交換機(jī)市場(chǎng)的最佳實(shí)踐引入到主機(jī)側(cè),實(shí)現(xiàn)了主機(jī)端與網(wǎng)絡(luò)白盒交換機(jī)統(tǒng)一的開(kāi)放網(wǎng)絡(luò)生態(tài),為DPU順利加入數(shù)字基礎(chǔ)設(shè)施的SDN網(wǎng)絡(luò)域打下了基礎(chǔ)。
審核編輯:陳陳
-
芯片技術(shù)
+關(guān)注
關(guān)注
1文章
159瀏覽量
17511 -
DPU
+關(guān)注
關(guān)注
0文章
357瀏覽量
24169 -
RDMA
+關(guān)注
關(guān)注
0文章
77瀏覽量
8945
原文標(biāo)題:引領(lǐng)DPU發(fā)展的關(guān)鍵技術(shù)
文章出處:【微信號(hào):架構(gòu)師技術(shù)聯(lián)盟,微信公眾號(hào):架構(gòu)師技術(shù)聯(lián)盟】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
新能源汽車電機(jī)驅(qū)動(dòng)關(guān)鍵技術(shù)及發(fā)展趨勢(shì)
遠(yuǎn)端射頻模塊關(guān)鍵技術(shù)創(chuàng)新及發(fā)展趨勢(shì)介紹
軟件無(wú)線電的功能結(jié)構(gòu)、關(guān)鍵技術(shù)和難點(diǎn)以及應(yīng)用和發(fā)展前景討論
5G發(fā)展道路中哪些射頻關(guān)鍵技術(shù)是繞不開(kāi)的?
推動(dòng)物聯(lián)網(wǎng)發(fā)展的十大關(guān)鍵技術(shù)
MIMO-OFDM中有哪些關(guān)鍵技術(shù)?
POE的關(guān)鍵技術(shù)有哪些?
明白VPP關(guān)鍵技術(shù)有哪些
視覺(jué)導(dǎo)航關(guān)鍵技術(shù)及應(yīng)用
LTE發(fā)展演進(jìn)及關(guān)鍵技術(shù)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論