") TransGeo:第一種用于交叉視圖圖像地理定位的純Transformer方法
TransGeo:第一種用于交叉視圖圖像地理定位的純Transformer方法
主要內(nèi)容:
提出了第一種用于交叉視圖圖像地理定位的純Transformer方法,在對齊和未對齊的數(shù)據(jù)集上都實(shí)現(xiàn)了最先進(jìn)的結(jié)果,與基于CNN的方法相比,計(jì)算成本更低,所提出的方法不依賴于極坐標(biāo)變換和數(shù)據(jù)增強(qiáng),具有通用性和靈活性。
論文出發(fā)點(diǎn):
基于CNN的交叉視圖圖像地理定位主要依賴于極坐標(biāo)變換,無法對全局相關(guān)性進(jìn)行建模,為了解決這些限制,論文提出的算法利用Transformer在全局信息建模和顯式位置信息編碼方面的優(yōu)勢,還進(jìn)一步利用Transformer輸入的靈活性,提出了一種注意力引導(dǎo)的非均勻裁剪方法去除無信息的圖像塊,性能下降可以忽略不計(jì),從而降低了計(jì)算成本,節(jié)省下來的計(jì)算可以重新分配來提高信息patch的分辨率,從而在不增加額外計(jì)算成本的情況下提高性能。
這種“關(guān)注并放大”策略與觀察圖像時(shí)的人類行為高度相似。
圖像地理定位(名詞解釋):
基于圖像的地理定位旨在通過檢索GPS標(biāo)記的參考數(shù)據(jù)庫中最相似的圖像來確定查詢圖像的位置,其應(yīng)用在大城市環(huán)境中改善具有大的噪聲GPS和導(dǎo)航,在Transformer出現(xiàn)之前,通常使用度量學(xué)習(xí)損失來訓(xùn)練雙通道CNN框架,但是這樣交叉視圖檢索系統(tǒng)在街道視圖和鳥瞰視圖之間存在很大的領(lǐng)域差距,因?yàn)镃NN不能明確編碼每個(gè)視圖的位置信息,之后為了改善域間隙,算法在鳥瞰圖像上應(yīng)用預(yù)定義的極坐標(biāo)變換,變換后的航空圖像具有與街景查詢圖像相似的幾何布局,然而極坐標(biāo)變換依賴于與兩個(gè)視圖相對應(yīng)的幾何體的先驗(yàn)知識,并且當(dāng)街道查詢在空間上未在航空圖像的中心對齊時(shí),極坐標(biāo)轉(zhuǎn)換可能會失敗。
Contribution:
提出了第一種基于Transformer的方法用于交叉視圖圖像地理定位,無需依賴極坐標(biāo)變換或數(shù)據(jù)增強(qiáng)。
提出了一種注意力引導(dǎo)的非均勻裁剪策略,去除參考航空圖像中的大量非信息補(bǔ)丁以減少計(jì)算量,性能下降可忽略不計(jì),通過將省下來的計(jì)算資源重新分配到信息patch的更高圖像分辨率進(jìn)一步提高了性能。
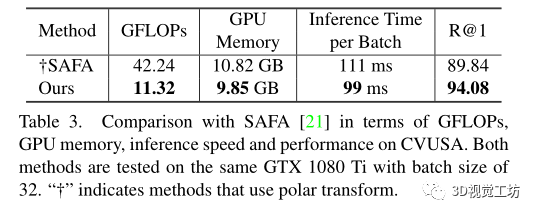
與基于CNN的方法相比,在數(shù)據(jù)集上的最先進(jìn)性能具有更低的計(jì)算成本、GPU內(nèi)存消耗和推理時(shí)間。
網(wǎng)絡(luò)架構(gòu):
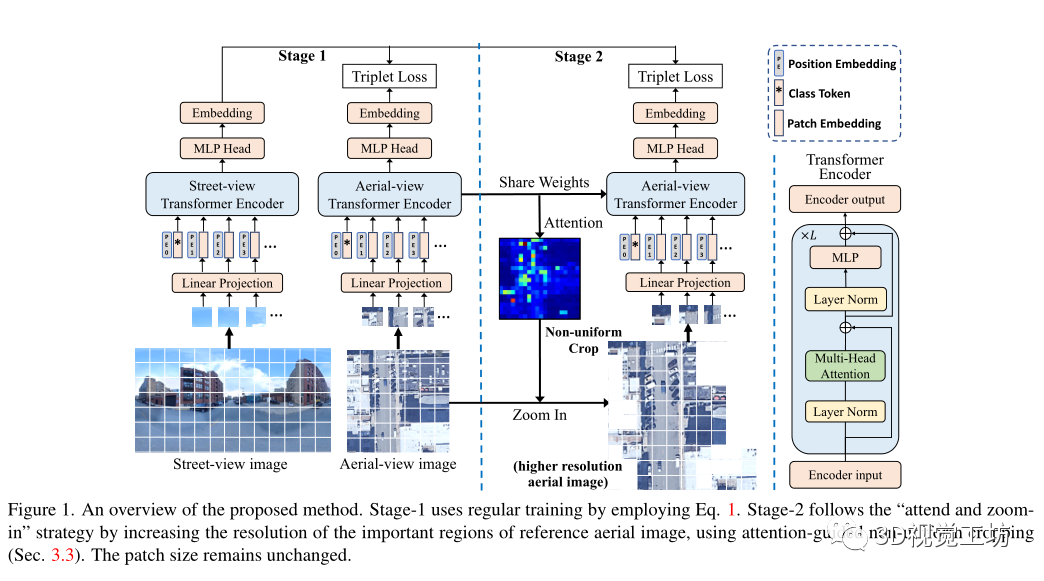

Patch Embedding:

Class Token:
最后一層輸出的類token被送到一個(gè)MLP頭以生成最終的分類向量,使用最終輸出向量作為嵌入特征,并使用上面說的損失對其進(jìn)行訓(xùn)練。
可學(xué)習(xí)的位置嵌入:
位置嵌入被添加到每個(gè)token以保持位置信息,采用了可學(xué)習(xí)的位置嵌入,這是包括class token在內(nèi)的所有(N+1)token的可學(xué)習(xí)矩陣,可學(xué)習(xí)的位置嵌入使雙通道Transformer能夠?qū)W習(xí)每個(gè)視圖的最佳位置編碼,而無需任何關(guān)于幾何對應(yīng)的先驗(yàn)知識,因此比基于CNN的方法更通用和靈活。
多頭注意力:
Transformer編碼器內(nèi)部架構(gòu)是L個(gè)級聯(lián)的基本Transformer,關(guān)鍵組成部分是多頭注意力塊,它首先使用三個(gè)可學(xué)習(xí)的線性投影將輸入轉(zhuǎn)換為查詢、鍵和值,表示為Q、K、V,維度為D,然后將注意力輸出計(jì)算為
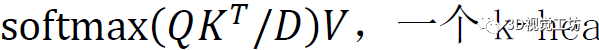
,一個(gè)k-head注意力塊用k個(gè)不同的head對Q、k、V進(jìn)行線性投影,然后對所有k個(gè)head并行執(zhí)行attention,輸出被連接并投影回模型維度D,多頭注意力可以模擬從第一層開始的任意兩個(gè)標(biāo)記之間的強(qiáng)全局相關(guān)性,這在CNN中是不可能學(xué)習(xí)的,因?yàn)榫矸e的接受域有限。
Attention引導(dǎo)的非均勻裁剪:
當(dāng)尋找圖像匹配的線索時(shí),人類通常會第一眼找到最重要的區(qū)域,然后只關(guān)注重要的區(qū)域并放大以找到高分辨率的更多細(xì)節(jié),把“關(guān)注并放大”的思想用在交叉圖像地理定位中可能更有益,因?yàn)閮蓚€(gè)視圖只共享少量可見區(qū)域,一個(gè)視圖中的大量區(qū)域,例如鳥瞰圖中的高樓屋頂,在另一個(gè)視圖可能看不見,這些區(qū)域?qū)ψ罱K相似性的貢獻(xiàn)微不足道,可以去除這些區(qū)域以減少計(jì)算和存儲成本,然而重要的區(qū)域通常分散在圖像上,因此CNN中的均勻裁剪不能去除分散的區(qū)域,因此提出了注意力引導(dǎo)的非均勻裁剪

在鳥瞰分支的最后一個(gè)transformer編碼器中使用注意力圖,它代表了每個(gè)token對最終輸出的貢獻(xiàn),由于只有class token對應(yīng)的輸出與MLP head連接,因此選擇class token與所有其他patch token之間的相關(guān)性作為注意力圖,并將其重塑為原始圖像形狀。
模型優(yōu)化:
為了在沒有數(shù)據(jù)增強(qiáng)的情況下訓(xùn)練Transformer模型,采用了正則化/泛化技術(shù)ASAM。在優(yōu)化損失時(shí)使用ASAM來最小化損失landscape的自適應(yīng)銳度使得該模型以平滑的損失曲率收斂以實(shí)現(xiàn)強(qiáng)大的泛化能力。
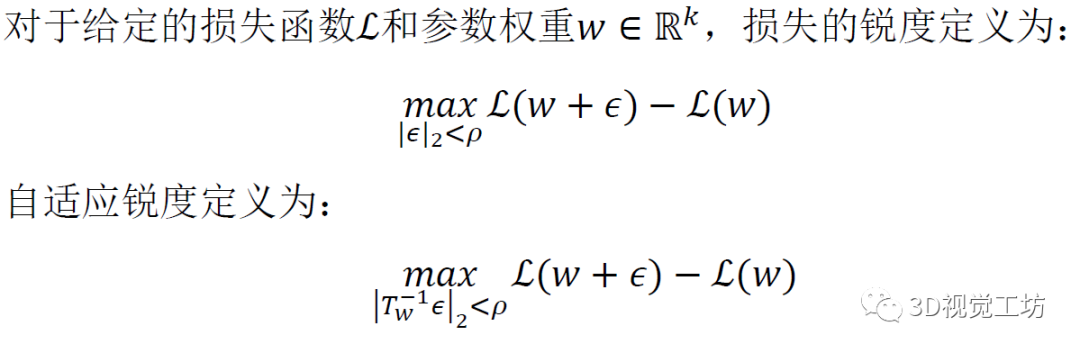
通過同時(shí)最小化的損失和自適應(yīng)銳度,能夠在不使用任何數(shù)據(jù)增強(qiáng)的情況下克服過擬合問題
實(shí)驗(yàn):
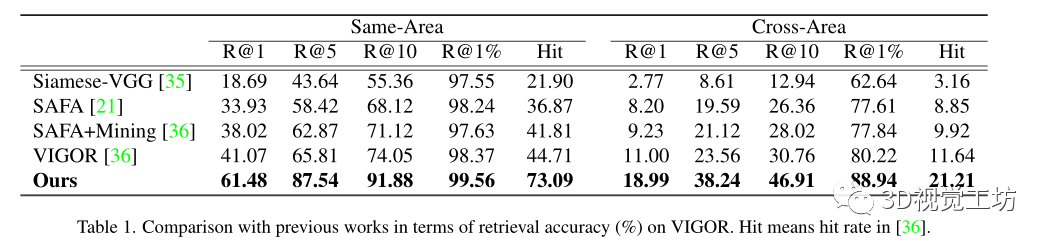
在兩個(gè)城市規(guī)模的數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),即CVUSA和VIGOR,分別代表了空間對齊和非對齊設(shè)置
評估度量:在top-k召回準(zhǔn)確率,表示為“R@k”,基于每個(gè)查詢的余弦相似度檢索嵌入空間中的k個(gè)最近參考鄰居,如果地面真實(shí)參考圖像出現(xiàn)在前k個(gè)檢索圖像中,則認(rèn)為其正確。
預(yù)測GPS位置和地面真實(shí)GPS位置之間的真實(shí)世界距離作為VIGOR數(shù)據(jù)集上的米級別的評估。
命中率,即覆蓋查詢圖像(包括地面真相)的前1個(gè)檢索參考圖像的百分比
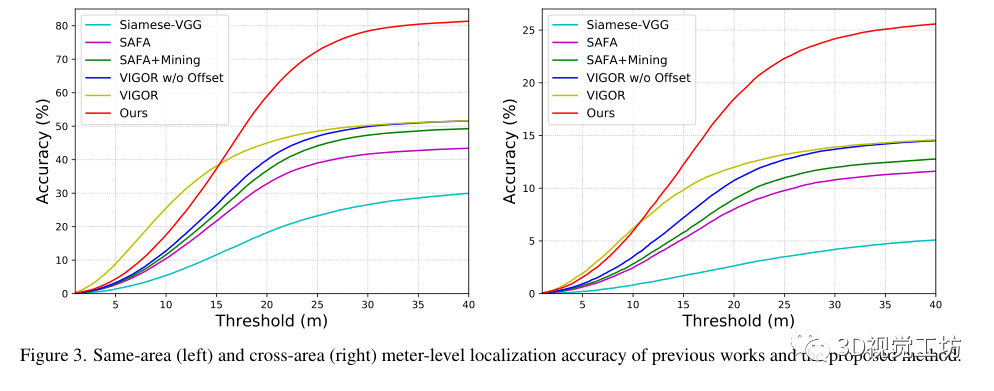
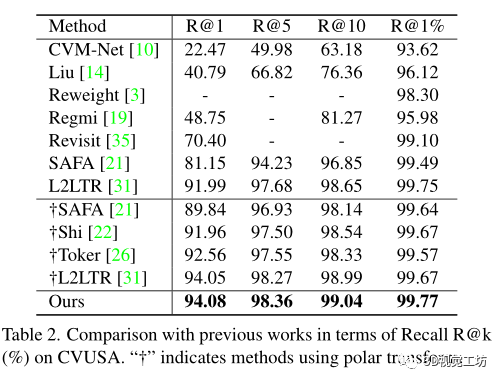
和之前SOTA方法SAFA在計(jì)算代價(jià)上的比較
總結(jié):
提出了第一種用于交叉視圖圖像地理定位的純Transformer方法,在對齊和未對齊的數(shù)據(jù)集上都實(shí)現(xiàn)了最先進(jìn)的結(jié)果,與基于CNN的方法相比,計(jì)算成本更低。
缺點(diǎn)是使用兩個(gè)管道,且patch選擇簡單地使用不可通過參數(shù)學(xué)習(xí)的注意力圖。
審核編輯 :李倩
-
圖像
+關(guān)注
關(guān)注
2文章
1085瀏覽量
40486 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24719 -
cnn
+關(guān)注
關(guān)注
3文章
352瀏覽量
22237
原文標(biāo)題:CVPR 2022 | TransGeo:第一種用于交叉視圖圖像地理定位的純Transformer方法
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
Mamba入局圖像復(fù)原,達(dá)成新SOTA
全球地理定位技術(shù)的發(fā)展歷程
如何使用圖像采集卡

自動(dòng)駕駛中一直說的BEV+Transformer到底是個(gè)啥?

SegVG視覺定位方法的各個(gè)組件
一種將NeRFs應(yīng)用于視覺定位任務(wù)的新方法

一種半動(dòng)態(tài)環(huán)境中的定位方法
一種無透鏡成像的新方法

機(jī)器學(xué)習(xí)中的交叉驗(yàn)證方法
地下金屬電纜故障定位儀的管線探測方法——每日了解電力知識

為什么UWB定位技術(shù)適用于室內(nèi)定位?
交叉導(dǎo)軌維護(hù)和保養(yǎng)的方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論