


我們正處于人工智能新時代的風口浪尖,正從單模態大步邁向多模態 AI 時代。在 Jina AI,我們的 MLOps 平臺幫助企業和開發者加速整個應用開發的過程,在這一范式變革中搶占先機,構建起著眼于未來的應用程序。
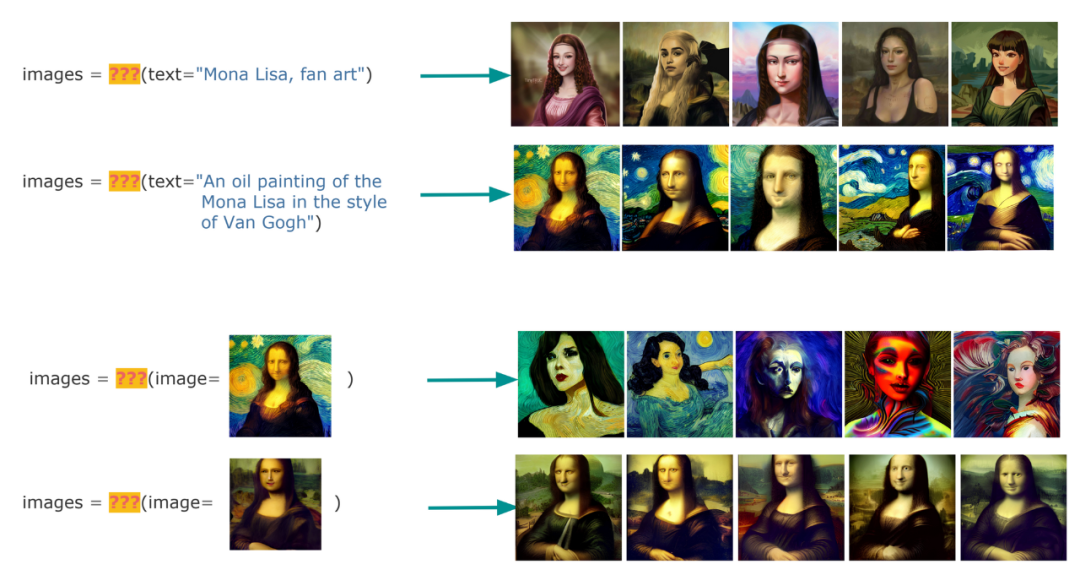
如果別人問到我們 Jina AI 是做什么的,我會有以下兩種回答。1. 面對 AI 研究員時,我會說:Jina AI 是一個跨模態和多模態數據的 MLOps 平臺;2. 面向從業者和合作伙伴時,我會說:Jina AI 是用于神經搜索和生成式 AI 應用的 MLOps 平臺。
但無論用哪種方式來介紹 Jina AI,大多數人對于這幾個詞語都是比較陌生的。
跨模態、多模態
神經搜索、生成式 AI
你可能聽說過”非結構化數據“,但什么是“多模態數據”呢?你可能也聽說過“語義搜索”,那“神經搜索”是什么新鮮玩意兒呢?可能更加令你困惑的是,Jina AI 為什么要將這四個概念混在一起,開發一個 MLOps 框架來囊括所有這些概念呢?
這篇文章就是為了幫助大家更好地理解 Jina AI 到底是做什么的,以及我們為什么要做這些。首先,“人工智能已從單模態 AI 轉向了多模態 AI”,這一點已成為行業共識,如下圖所示:
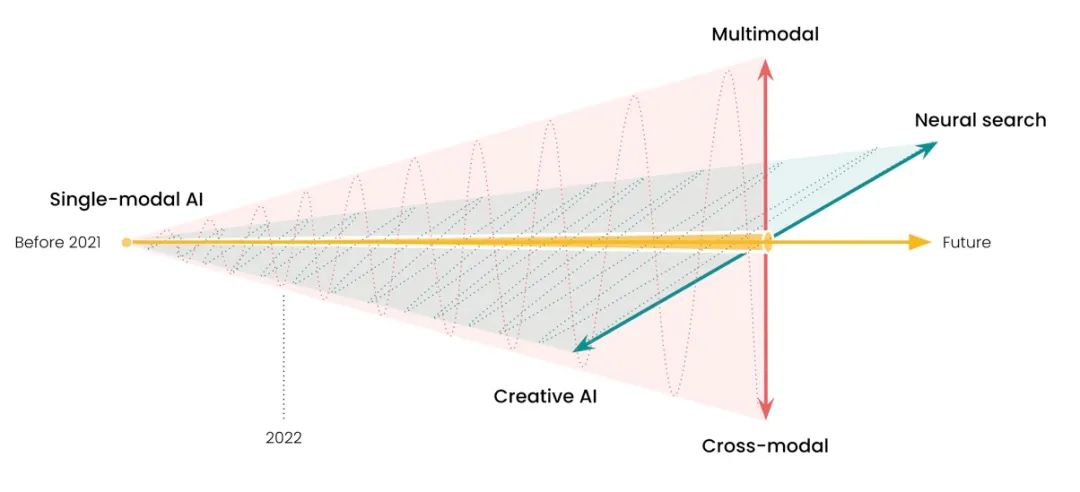
Jina AI 愿景中的未來 AI 應用
在 Jina AI,我們的產品囊括了跨模態、多模態、神經搜索和生成式 AI,涵蓋了未來 AI 應用的很大一部分。我們的 MLOps 平臺幫助企業和開發者加速整個應用開發的過程,在這一范式轉變中搶占先機,構建起著眼于未來的應用程序。
在接下來的文章里,我們將回顧單模態 AI 的發展歷程,看看這種范式轉變是如何在我們眼下悄然發生的。
單模態人工智能
在計算機科學中,“模態”大致意思是“數據類型”。所謂的單模態 AI,就是將 AI 應用于一種特定類型的數據。這在早期的機器學習領域非常普遍。直至今日,你在看機器學習相關的論文時,單模態 AI 依然占據著半壁江山。
自然語言處理
我們從自然語言處理(NLP)開始回顧。早在 2010 年,我就發表了一篇關于 Latent Dirichlet Allocation(LDA)模型的改進 Gibbs sampling(吉布斯抽樣)算法的論文。

Efficient Collapsed Gibbs Sampling For Latent Dirichlet Allocation, 2010
一些資深的機器學習研究人員可能還記得 LDA,這是一種用于建模文本語料庫的參數貝葉斯模型。它將單詞“聚類”成主題,并將每個文檔表示為主題的組合。因此有人稱其為“主題模型”
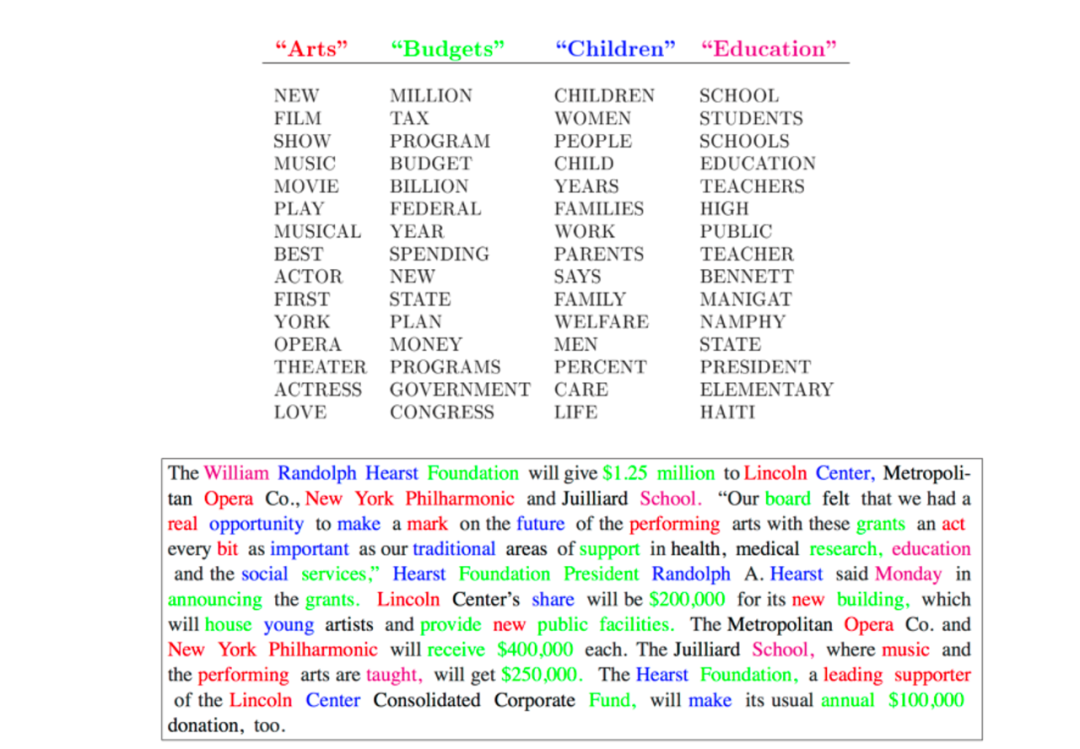
從 2008 年到 2012 年,主題模型一直是 NLP 社區中最有效和最受歡迎的模型之一——它的火熱程度相當于當時的 BERT/Transformer。每年在頂級 ML/NLP 會議上,許多論文都會擴展或改進原始模型。但今天回過頭來看,它是一個相當 "淺層學習"的模型,采用的是一次性的語言建模方法。它假定單詞是由多叉分布的混合物生成的。這對某些特定的任務來說是有意義的,但對其他任務、領域或模式來說卻不夠通用。
早在 2010-2020 年,像這樣的一次性方法是 NLP 研究的常態。研究人員和工程師開發了專門的算法,每種算法雖然都擅長解決一項任務,但是也僅僅只能解決一項任務:
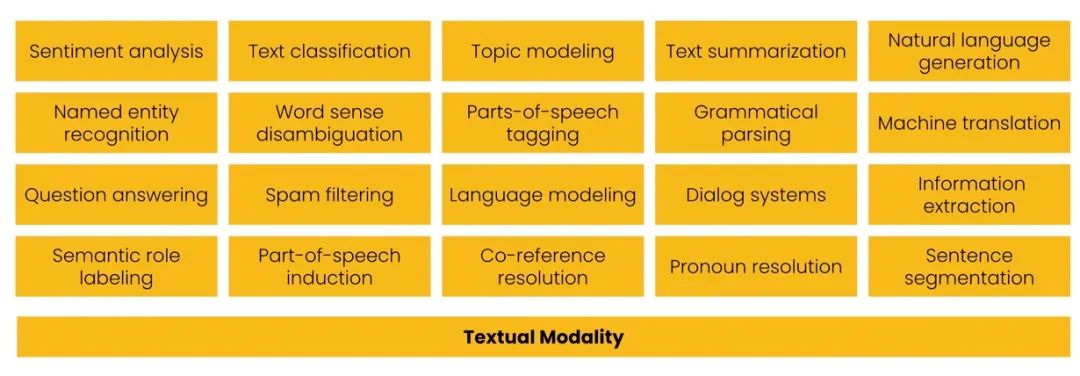
最常見的20種NLP任務
相較于 NLP 領域,我進入計算機視覺 (CV) 領域要晚一些。2017 年在 Zalando 時,我發表了一篇關于 Fashion-MNIST 數據集 的論文。該數據集是 Yann LeCun 1990 年原始 MNIST 數據集(一組簡單的手寫數字,用于對計算機視覺算法進行基準測試)的直接替代品。原始 MNIST 數據集對于許多算法來說過于簡單 —— 邏輯回歸、決策樹等淺層學習算法樹和支持向量機可以輕松達到 90% 的準確率,留給深度學習算法發揮的空間很小。

Fashion-mnist:用于基準機器學習算法的新型圖像數據集示例,2017

Fashion-mnist:用于基準機器學習算法的新型圖像數據集論文,2017
Fashion-MNIST 提供了一個更具挑戰性的數據集,使研究人員能夠探索、測試和衡量其算法。時至今日,超過 5,000 篇學術論文在分類、回歸、去噪、生成等方面的研究中都還引用了 Fashion-MNIST,可見其價值所在。
但正如主題模型只適用于 NLP,Fashion-MNIST 也只適用于計算機視覺。它的缺陷在于,數據集中幾乎沒有任何信息可以用來研究其他模式。如果梳理2010-2020年間最常見的20個CV任務,你會發現,幾乎所有任務都是單一模式的。同樣的,它們每一個都涵蓋了一個特定的任務,但也僅僅涉及一項任務:
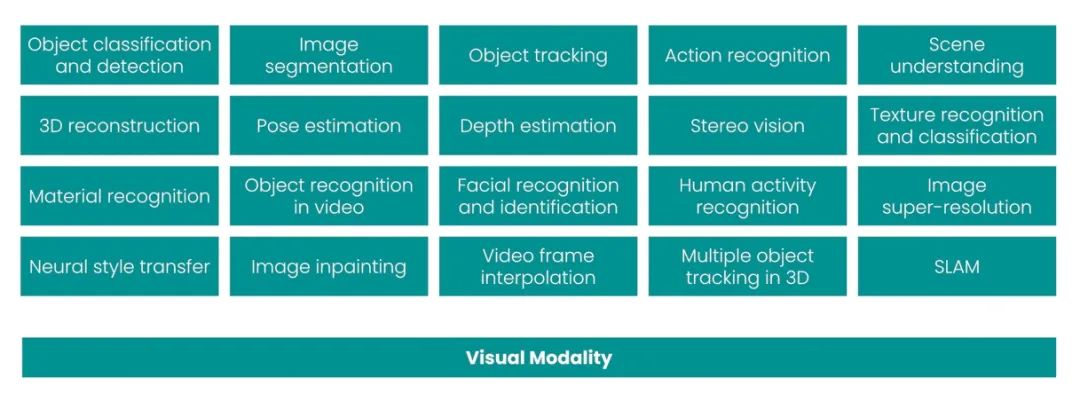
最常見的 20 個 CV 任務
語音和音頻
針對語音和音頻機器學習遵循相同的模式:算法是為圍繞音頻模態的臨時任務而設計的。他們各自執行一項任務,而且只執行一項任務,但現在都在一起執行:
最常見的 20 項音頻處理任務
我對多模態 AI 方面最早的嘗試之一是我在 2010 年發表的一篇論文,當時我建立了一個貝葉斯模型,對視覺、文本和聲音 3 種模態進行聯合建模。經過訓練后,它就能完成兩項跨模式的檢索任務:從聲音片段中找到最匹配的圖像,反之亦然。我給這兩個任務起了一個很賽博朋克的名字:“Artificial Synesthesia,人機聯覺”。

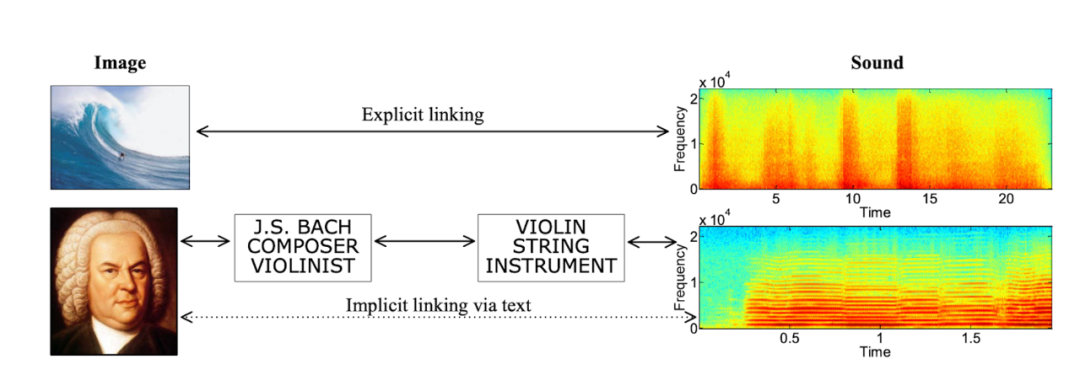
Toward Artificial Synesthesia: Linking Images and Sounds via Words, 2010
邁向多模態人工智能
從上面的例子中,我們可以看到所有的單模態 AI 算法都有兩個共同的弊端:
任務只針對一種模態(例如文本、圖像、音頻等)。
知識只能從一種模態中學習,并應用在這一模式中(即視覺算法只能從圖像中學習,并應用于圖像)。
在上文中,我已經討論了文本、圖像、音頻。還有其他模式,例如 3D、視頻、時間序列,也應該被考慮在內。如果我們把來自不同模態的所有任務可視化,我們會得到一個下面立方體,其中各模態正交排列:
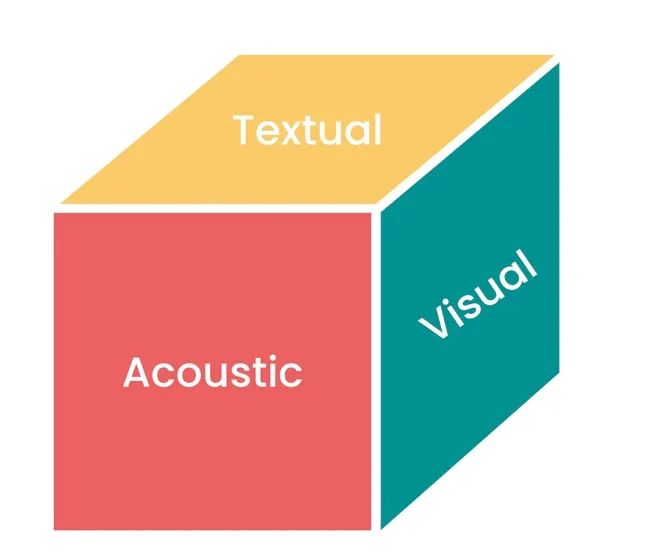
以一個立方體來表示單模態之間的關系,可以假定每個面代表一個單獨模態的任務
然而,多模態 AI 就像將這個立方體重新粘合成一個球體,最重要的不同點在于它抹去了不同模態之間的界限,其中:
任務在多種模式之間共享和傳輸(因此一種算法可以處理圖像,文本和音頻)
知識是從多種模式中學習并應用于多種模式(因此一個算法可以從文本數據中學習并將其應用于視覺數據。
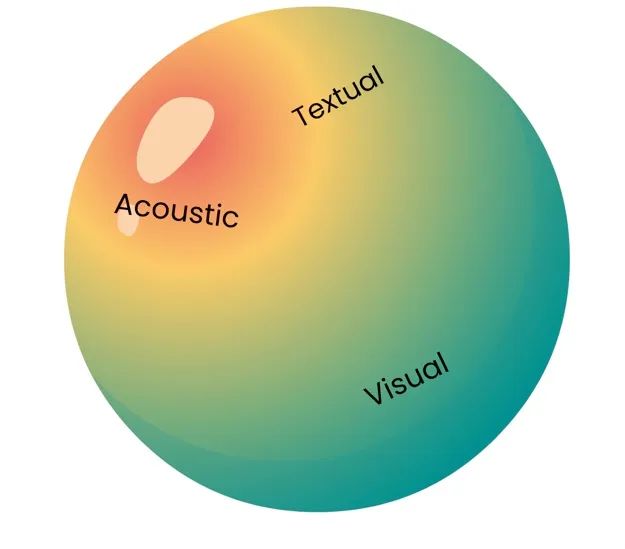
多模態人工智能
多模態 AI 的崛起可歸功于兩種機器學習技術的進步:表征學習和遷移學習。
表征學習:讓模型為所有模態創建通用的表征。
遷移學習:讓模型首先學習基礎知識,然后在特定領域進行微調。
如果沒有表征學習和遷移學習的進步,想在通用數據類型上實行多模態是非常難以落地的,就像我 2010 年的那篇關于聲音-圖像的論文一樣,一切都是紙上談兵。
2021 年,我們看到了 CLIP,這是一個關聯圖像和文本之間對應關系的模型;2022 年,我們看到 DALL·E 2 和 Stable Diffusion,根據 prompts 文本生成對應高質量的圖像。
由此可見,范式的轉變已然開啟:未來我們必將看到越來越多的AI應用將超越單個模態,發展為多模態,并巧妙利用不同模態之間的關系。隨著模態之間的界限變得模糊,一次性的方法也不再適用了。
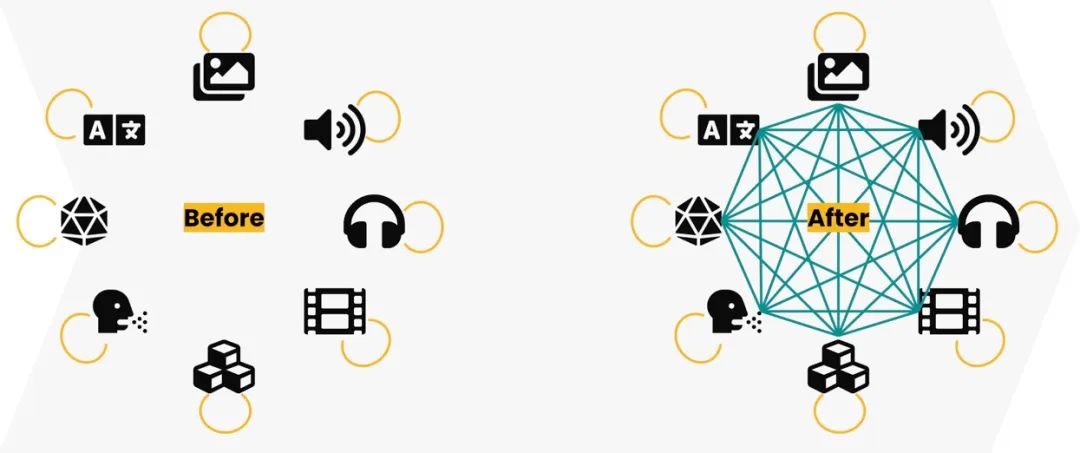
從單模態 AI 到多模態 AI 的范式轉變
搜索和生成的二元性
搜索和生成是多模態 AI 中的兩項基本任務。在多模態 AI 領域,搜索是指神經搜索,即使用深度神經網絡進行搜索。對于大多數人來說,這兩個任務是完全孤立的,并且它們已經被分開研究了很多年。但是,搜索和生成是緊密相連的,并且具有共同的二元性。為了理解這一點,我們可以看看下面的例子。
有了多模態 AI,使用文本或圖像來搜索圖像數據集就非常簡單:
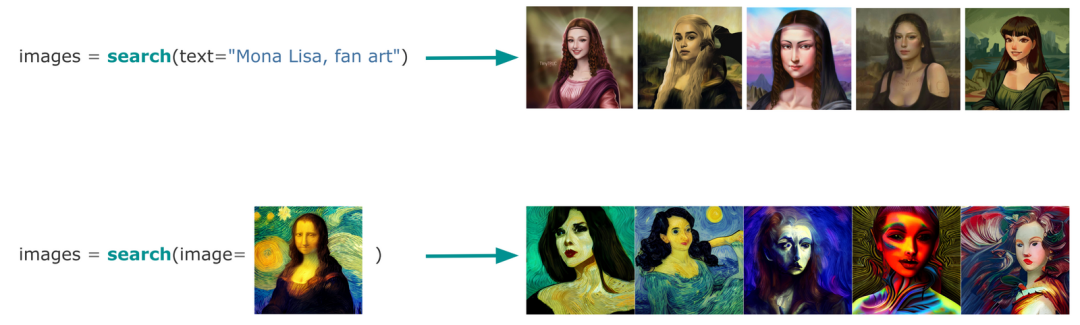
搜索:找到你需要的
創作是類似的。你從文本提示中創建一個新圖像,或者通過豐富/修復現有圖像來創建新圖像:
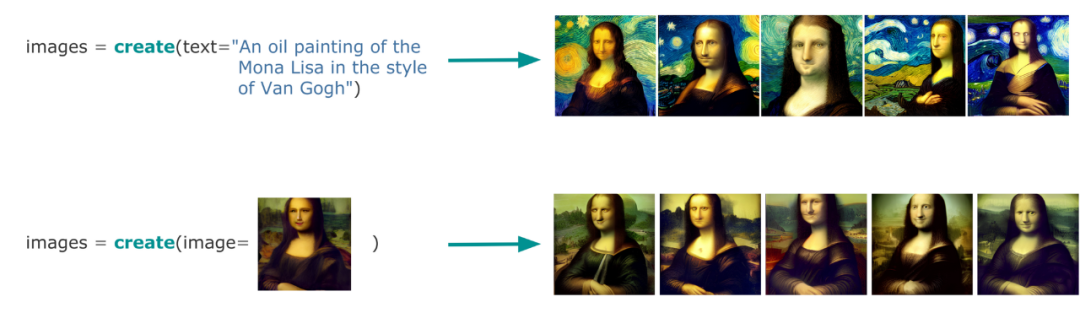
生成:制作你需要的
當把這兩個任務組合在一起并屏蔽掉它們的函數名時,你可以看到這兩個任務沒有區別。兩者都接收和輸出相同的數據類型。唯一的區別是,搜索是找到你需要的東西,而生成是制造你需要的東西。
DNA 是一個很好的類比:一旦你有了一個生物體的 DNA,就可以構建系統發生樹,并尋找已知最古老、最原始的源頭。另一方面,你可以將 DNA 注入卵子并創造新的東西。
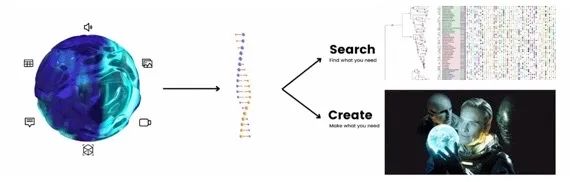
左:多模態人工智能框架下的搜索與創造的二元性
右:《異形:契約》電影海報
類似于哆啦A夢和瑞克,他們都擁有令人羨慕的超能力。但他們的不同在于哆啦A夢在他的口袋里尋找現有的物品,而瑞克則從他的車間創造了新東西。

哆啦A夢代表神經搜索,而瑞克代表生成式 AI
搜索和生成的二元性也帶來了一個有趣的思想實驗:想象一下,當生活在一個所有圖像都由人工智能生成,而不是由人類構建的世界里。我們還需要(神經)搜索嗎?或者說,我們還需要將圖像嵌入到向量中,再使用向量數據庫對其進行索引和排序嗎?
答案是 NO。因為在觀察圖像之前,唯一代表圖像的 seed 和 prompts 是已知的,后果現在變成了前因。與經典的表示法相比,學習圖像是原因,表示法是結果。為了搜索圖像,我們可以簡單地存儲 seed(一個整數)和 prompts(一個字符串),這不過是一個好的老式 BM25 或二分搜索。當然,我們作為人類還是更偏愛由人類自己創造的藝術品,所以平行宇宙暫時還不是真正的現實。至于為什么我們更應該關注生成式 AI 的進展 —— 因為處理多模態數據的老方法可能已經過時了。
總結
我們正處于人工智能新時代的前沿,多模態學習將很快占據主導地位。這種類型的學習結合了多種數據類型和模態的學習,有可能徹底改變我們與機器互動的方式。到目前為止,多模態 AI 已經在計算機視覺和自然語言處理等領域取得了巨大成功。在未來,毋庸置疑的是,多模態 AI 將產生更大的影響。例如,開發能夠理解人類交流的細微差別的系統,或創造更逼真的虛擬助手。總而言之,未來擁有萬種可能,而我們才只接觸到冰山一角!
審核編輯:劉清
-
人工智能
+關注
關注
1806文章
48973瀏覽量
248745 -
機器學習
+關注
關注
66文章
8500瀏覽量
134479 -
LDA
+關注
關注
0文章
29瀏覽量
10810 -
nlp
+關注
關注
1文章
490瀏覽量
22588
原文標題:Jina AI創始人肖涵博士解讀多模態AI的范式變革
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
芯片行業的IP是什么?芯片 IP 公司到底是做什么的?

stm32的這些時鐘都是做什么的
MIPI CSI D-PHY寄存器中HS-SETTLE參數到底是做什么?
半導體行業是做什么的_誰是中國半導體龍頭
“電感飽和”到底是什么意思?
ip地址是做什么的
雙面金屬化聚丙烯膜電容到底是做什么用的?
芯片IP公司到底是做什么的?






 工商網監
工商網監

評論