 一次JVM GC長暫停的排查過程
一次JVM GC長暫停的排查過程
背景
在高并發下,Java 程序的 GC 問題屬于很典型的一類問題,帶來的影響往往會被進一步放大。不管是「GC 頻率過快」還是「GC 耗時太長」,由于 GC 期間都存在 Stop The World 問題,因此很容易導致服務超時,引發性能問題。
事情最初是線上某應用垃圾收集出現 Full GC 異常的現象,應用中個別實例 Full GC 時間特別長,持續時間約為 15~30 秒,平均每 2 周左右觸發一次;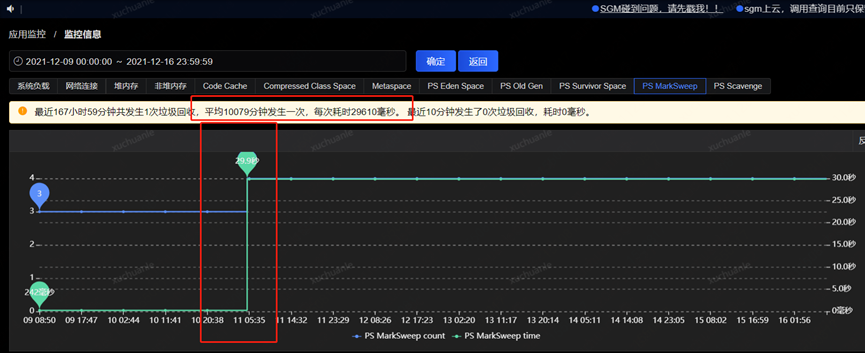
JVM 參數配置 “-Xms2048M –Xmx2048M –Xmn1024M –XX:MaxPermSize=512M”
排查過程
?分析 GC 日志
GC 日志它記錄了每一次的 GC 的執行時間和執行結果,通過分析 GC 日志可以調優堆設置和 GC 設置,或者改進應用程序的對象分配模式。
這里 Full GC 的 reason 是 Ergonomics,是因為開啟了 UseAdaptiveSizePolicy,jvm 自己進行自適應調整引發的 Full GC。
這份日志主要體現 GC 前后的變化,目前為止看不出個所以然來。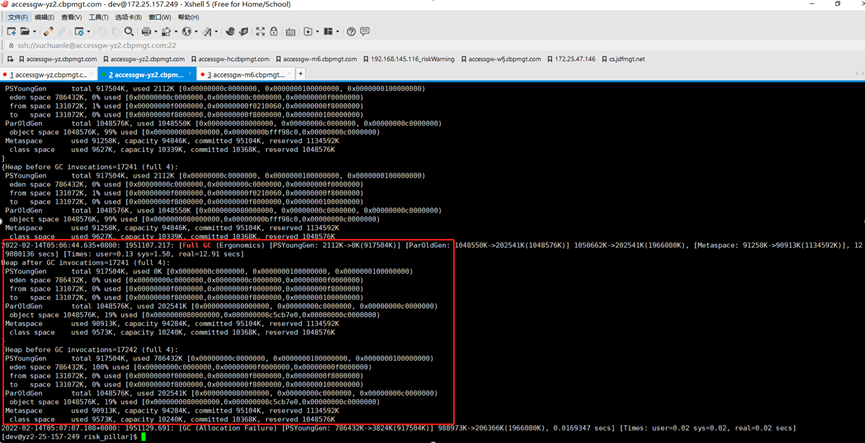
開啟 GC 日志,需要添加如下 JVM 啟動參數:
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/export/log/risk_pillar/gc.log
常見的 Young GC、Full GC 日志含義如下: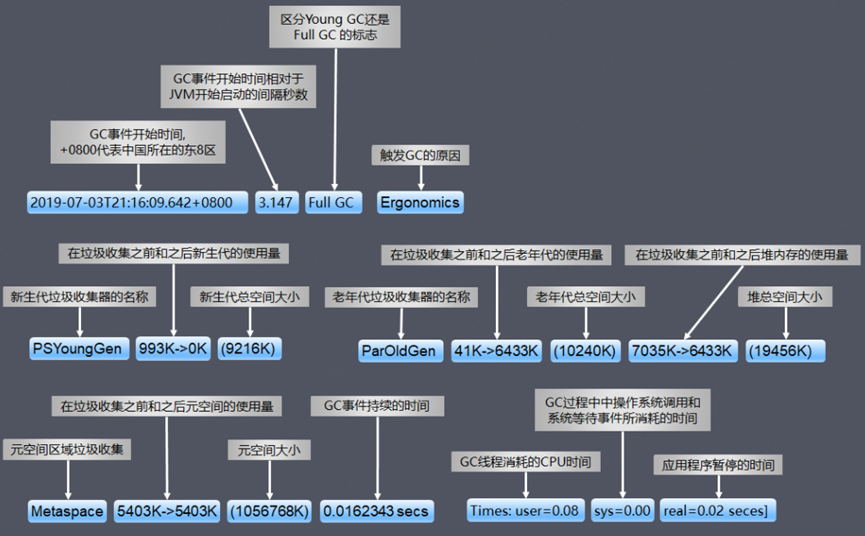
?進一步查看服務器性能指標
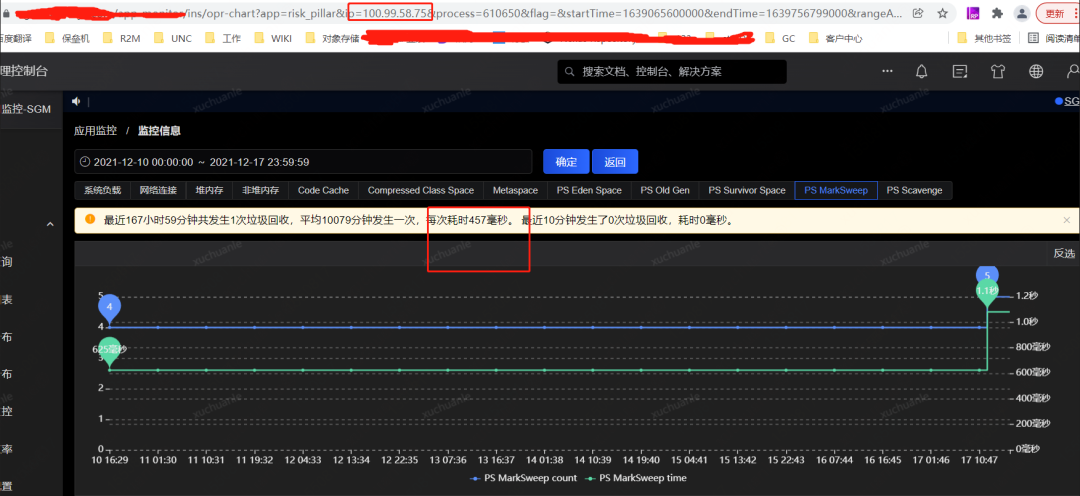
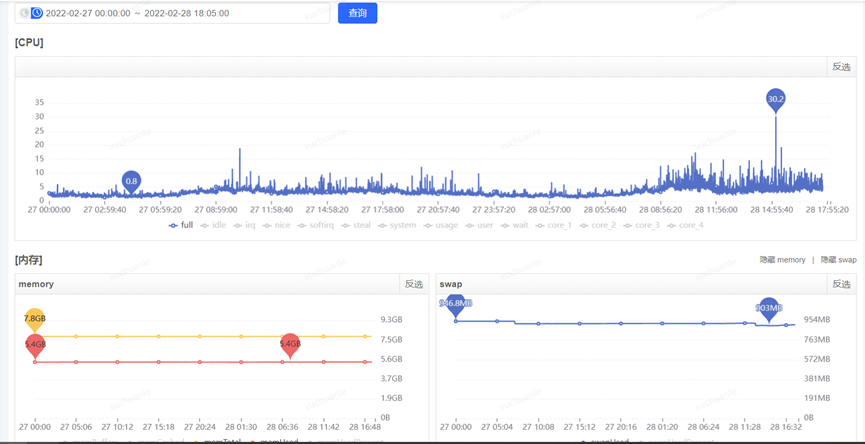
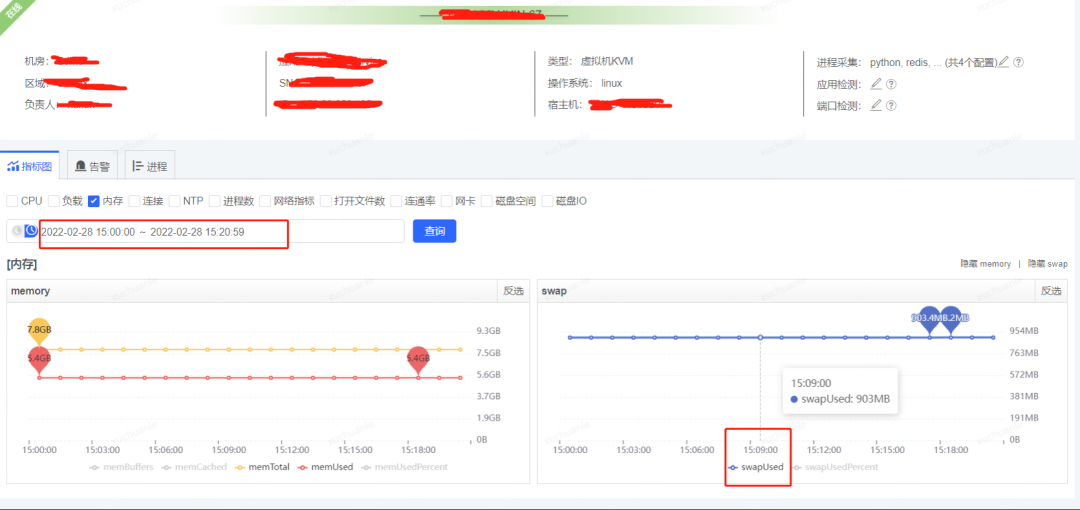
獲取到了 GC 耗時的時間后,通過監控平臺獲取到各個監控項,開始排查這個時點有異常的指標,最終分析發現,在 5.06 分左右(GC 的時點),CPU 占用顯著提升,而 SWAP 出現了釋放資源、memory 資源增長出現拐點的情況(詳見下圖紅色框,橙色框中的變化是因修改配置導致,后面會介紹,暫且可忽略)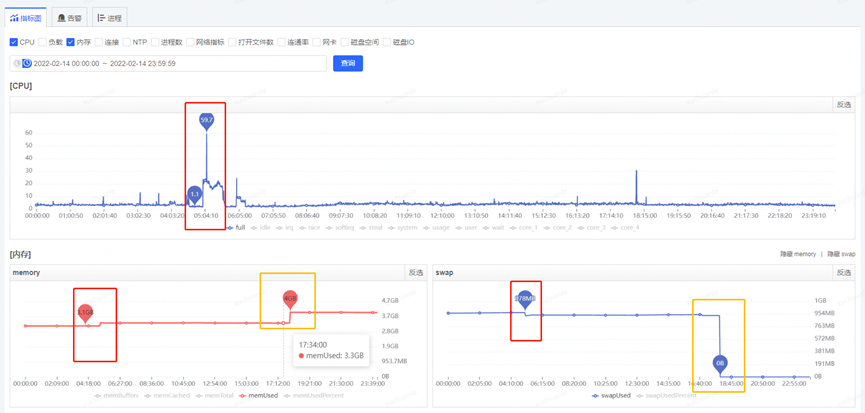
JVM 用到了swap?是因為 GC 導致的 CPU 突然飆升,并且釋放了 swap 交換區這部分內存到 memory?
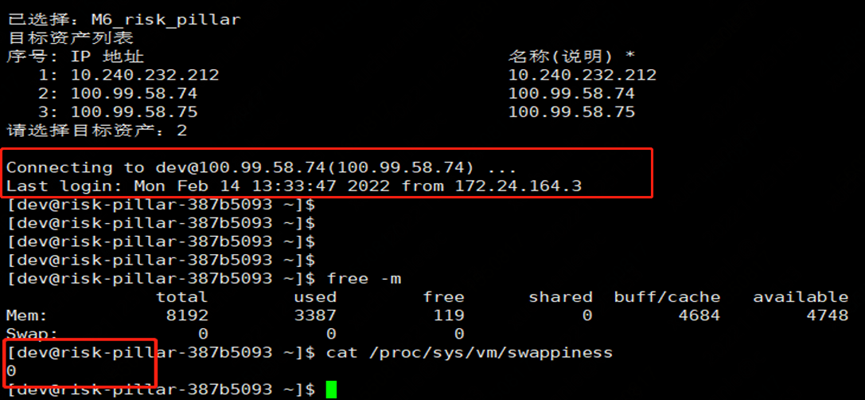
為了驗證 JVM 是否用到 swap,我們通過檢查 proc 下的進程內存資源占用情況
| for i in $(cd /proc;ls |grep "^[0-9]"|awk ' $0 >100') ;do awk '/Swap:/{a=a+$2} END {print '"$i"',a/1024"M"}' /proc/$i/smaps 2>/dev/null ; done | sort -k2nr | head -10 # head -10 表示 取出 前 10 個內存占用高的進程 # 取出的第一列為進程的 id 第二列進程占用 swap 大小 | | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ |
看到確實有用到 305MB 的 swap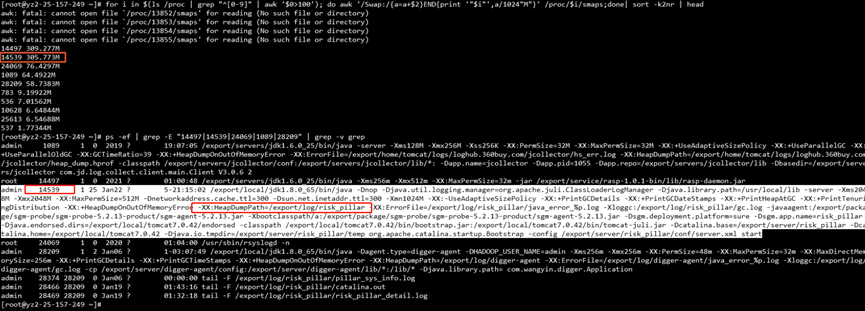
這里簡單介紹下什么是swap?
swap 指的是一個交換分區或文件,主要是在內存使用存在壓力時,觸發內存回收,這時可能會將部分內存的數據交換到 swap 空間,以便讓系統不會因為內存不夠用而導致 oom 或者更致命的情況出現。
當某進程向 OS 請求內存發現不足時,OS 會把內存中暫時不用的數據交換出去,放在 swap 分區中,這個過程稱為 swap out。
當某進程又需要這些數據且 OS 發現還有空閑物理內存時,又會把 swap 分區中的數據交換回物理內存中,這個過程稱為 swap in。
為了驗證 GC 耗時與 swap 操作有必然關系,我抽查了十幾臺機器,重點關注耗時長的 GC 日志,通過時間點確認到 GC 耗時的時間點與 swap 操作的時間點確實是一致的。
進一步查看虛擬機各實例 swappiness 參數,一個普遍現象是,凡是發生較長 Full GC 的實例都配置了參數 vm.swappiness = 30(值越大表示越傾向于使用 swap);而 GC 時間相對正常的實例配置參數 vm.swappiness = 0(最大限度地降低使用 swap)。
swappiness 可以設置為 0 到 100 之間的值,它是 Linux 的一個內核參數,控制系統在進 行 swap 時,內存使用的相對權重。
? swappiness=0: 表示最大限度使用物理內存,然后才是 swap 空間
? swappiness=100: 表示積極的使用 swap 分區,并且把內存上的數據及時的交換到 swap 空間里面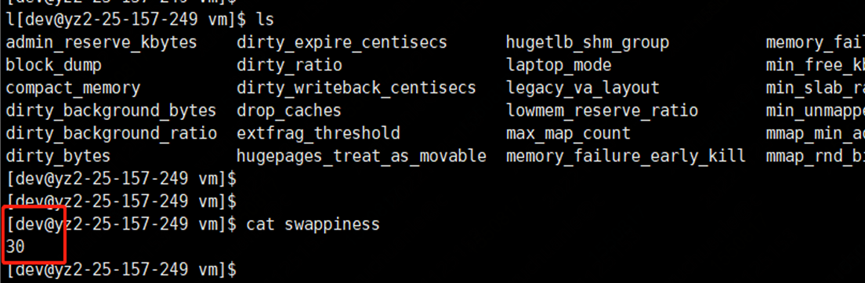
對應的物理內存使用率和 swap 使用情況如下
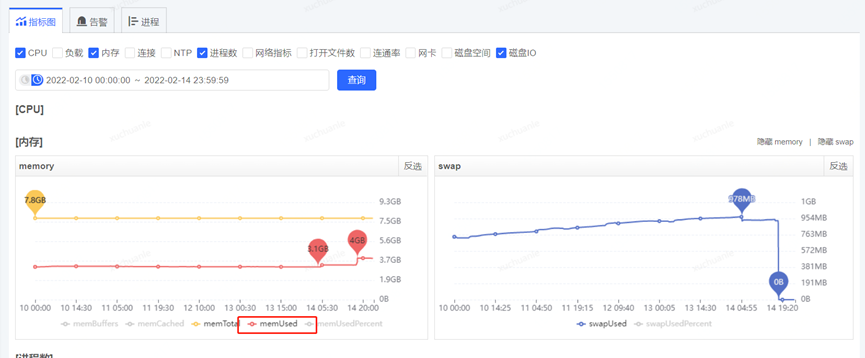
至此,矛頭似乎都指向了 swap。
?問題分析
當內存使用率達到水位線 (vm.swappiness) 時,linux 會把一部分暫時不使用的內存數據放到磁盤 swap 去,以便騰出更多可用內存空間;
當需要使用位于 swap 區的數據時,再將其換回內存中,當 JVM 進行 GC 時,需要對相應堆分區的已用內存進行遍歷;
假如 GC 的時候,有堆的一部分內容被交換到 swap 空間中,遍歷到這部分的時候就需要將其交換回內存,由于需要訪問磁盤,所以相比物理內存,它的速度肯定慢的令人發指,GC 停頓的時間一定會非常非常恐怖;
進而導致 Linux 對 swap 分區的回收滯后(內存到磁盤換入換出操作十分占用 CPU 與系統 IO),在高并發 / QPS 服務中,這種滯后帶來的結果是致命的 (STW)。
?問題解決
至此,答案似乎很清晰,我們只需嘗試把 swap 關閉或釋放掉,看看能否解決問題?
如何釋放 swap?
設置 vm.swappiness=0(重啟應用釋放 swap 后生效),表示盡可能不使用交換內存
a、 臨時設置方案,重啟后不生效
設置 vm.swappiness 為 0
sysctl vm.swappiness=0
查看 swappiness 值
cat /proc/sys/vm/swappiness
b、 永久設置方案,重啟后仍然生效
vi /etc/sysctl.conf
添加
vm.swappiness=0
關閉交換分區 swapoff –a
前提:首先要保證內存剩余要大于等于 swap 使用量,否則會報 Cannot allocate memory!swap 分區一旦釋放,所有存放在 swap 分區的文件都會轉存到物理內存上,可能會引發系統 IO 或者其他問題。
a、 查看當前 swap 分區掛載在哪?
b、 關停分區
關閉 swap 交換區后的內存變化見下圖橙色框,此時 swap 分區的文件都轉存到了物理內存上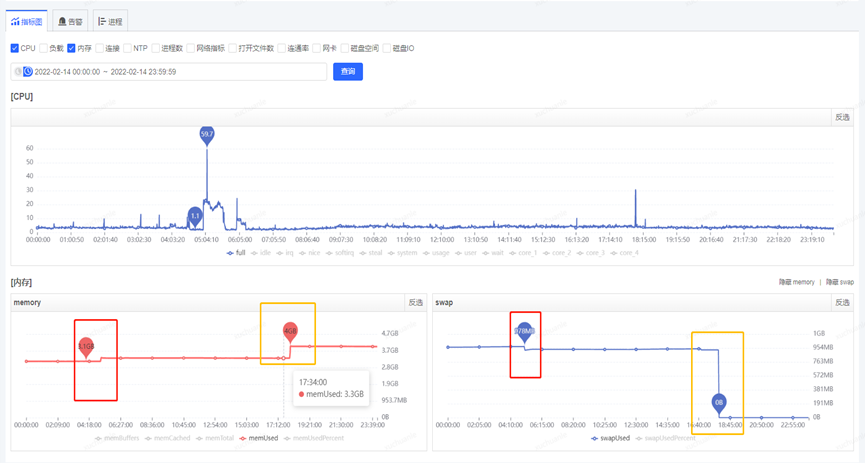
關閉 Swap 交換區后,于 2.23 再次發生 Full GC,耗時 190ms,問題得到解決。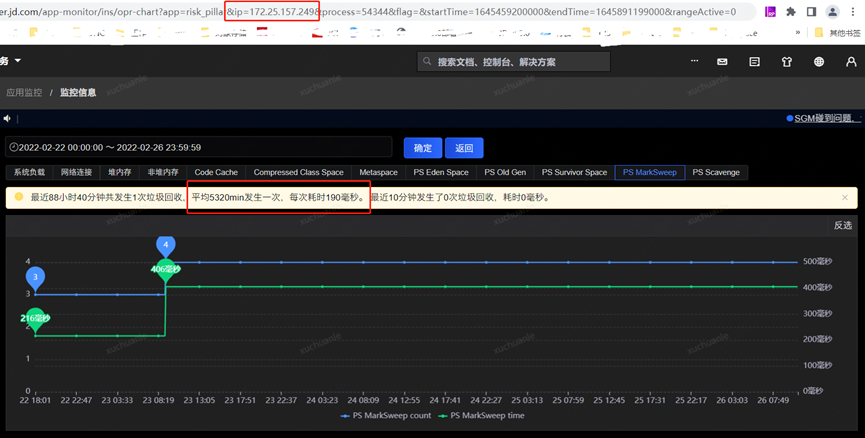
?疑惑
1、 是不是只要開啟了 swap 交換區的 JVM,在 GC 的時候都會耗時較長呢?
2、 既然 JVM 對 swap 如此不待見,為何 JVM 不明令禁止使用呢?
3、 swap 工作機制是怎樣的?這臺物理內存為 8g 的 server,使用了交換區內存(swap),說明物理內存不夠使用了,但是通過 free 命令查看內存使用情況,實際物理內存似乎并沒有占用那么多,反而 Swap 已占近 1G?
free:除了 buff/cache 剩余了多少內存
shared:共享內存
buff/cache:緩沖、緩存區內存數(使用過高通常是程序頻繁存取文件)
available:真實剩余的可用內存數
大家可以想想,關閉交換磁盤緩存意味著什么?
其實大可不必如此激進,要知道這個世界永遠不是非 0 即 1 的,大家都會或多或少選擇走在中間,不過有些偏向 0,有些偏向 1 而已。
很顯然,在 swap 這個問題上,JVM 可以選擇偏向盡量少用,從而降低 swap 影響,要降低 swap 影響有必要弄清楚 Linux 內存回收是怎么工作的,這樣才能不遺漏任何可能的疑點。
先來看看 swap 是如何觸發的?
Linux 會在兩種場景下觸發內存回收,一種是在內存分配時發現沒有足夠空閑內存時會立刻觸發內存回收;另一種是開啟了一個守護進程(kswapd 進程)周期性對系統內存進行檢查,在可用內存降低到特定閾值之后主動觸發內存回收。
通過如下圖示可以很容易理解,詳細信息參見。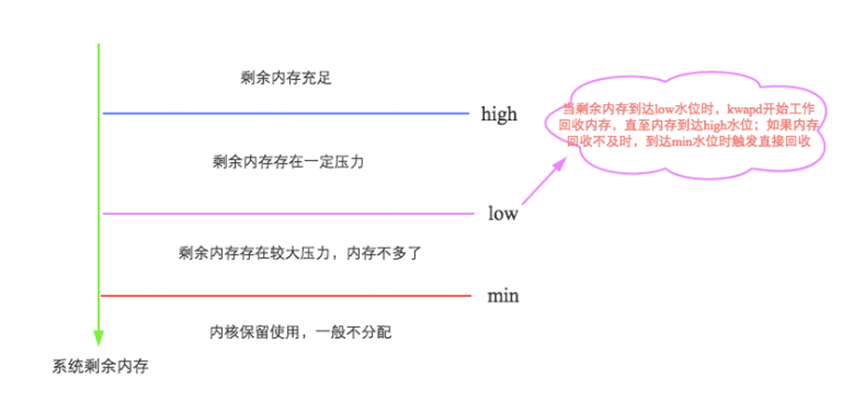
解答是不是只要開啟了 swap 交換區的 JVM,在 GC 的時候都會耗時較長
筆者去查了一下另外的一個應用,相關指標信息請見下圖。
實名服務的 QPS 是非常高的,同樣能看到應用了 swap,GC 平均耗時 576ms,這是為什么呢?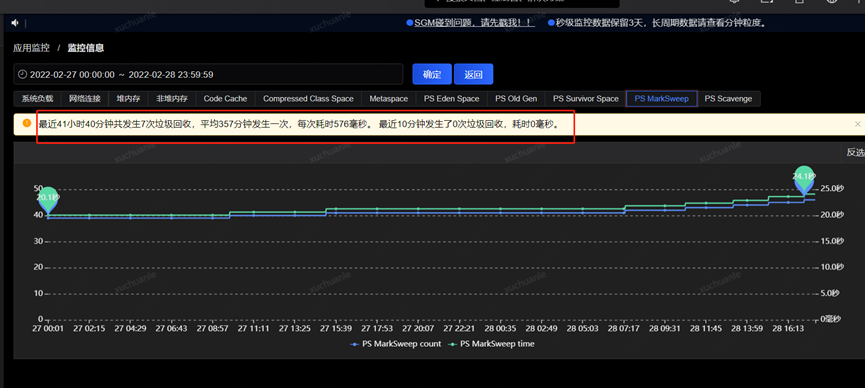
通過把時間范圍聚焦到發生 GC 的某一時間段,從監控指標圖可以看到 swapUsed 沒有任何變化,也就是說沒有 swap 活動,進而沒有影響到垃級回收的總耗時。 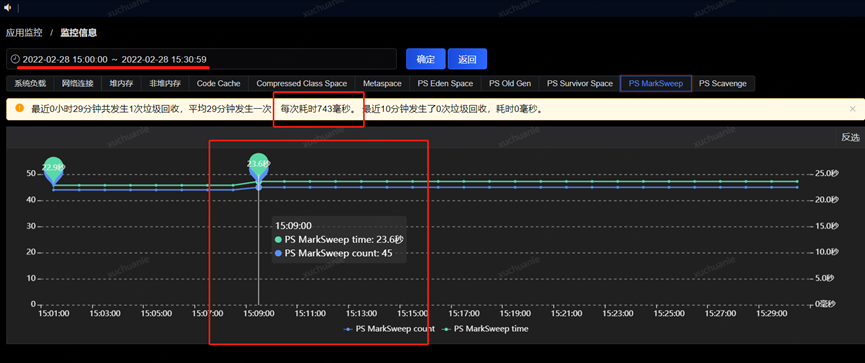
通過如下命令列舉出各進程 swap 空間占用情況,很清楚的看到實名這個服務 swap 空間占用的較少(僅 54.2MB) 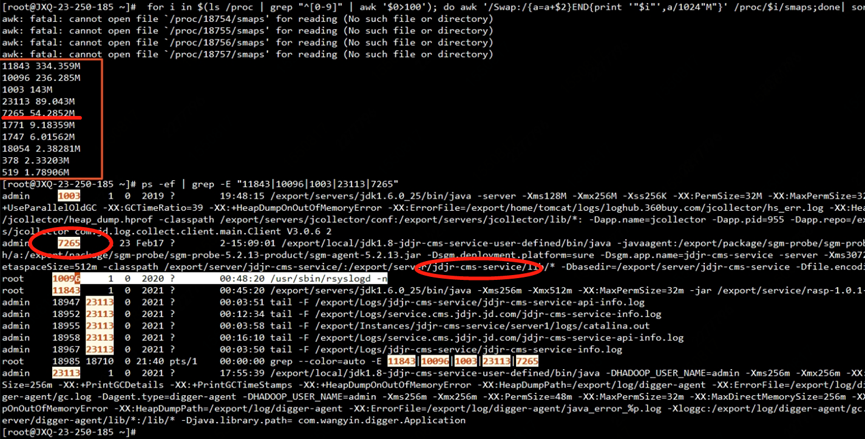
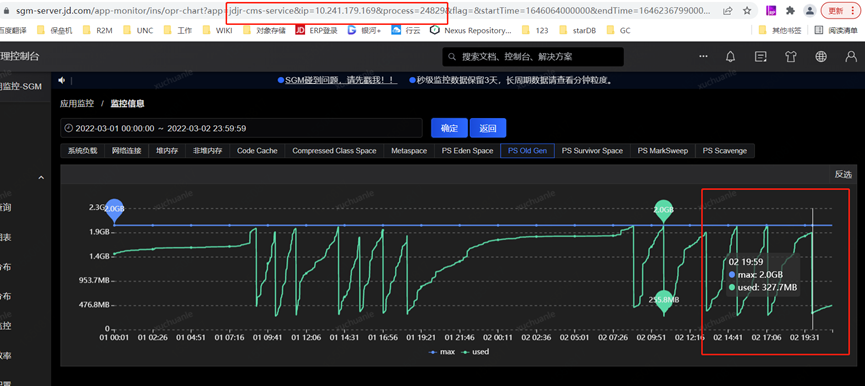
另一個顯著的現象是實名服務 Full GC 間隔較短(幾個小時一次),而我的服務平均間隔 2 周一次 Full GC 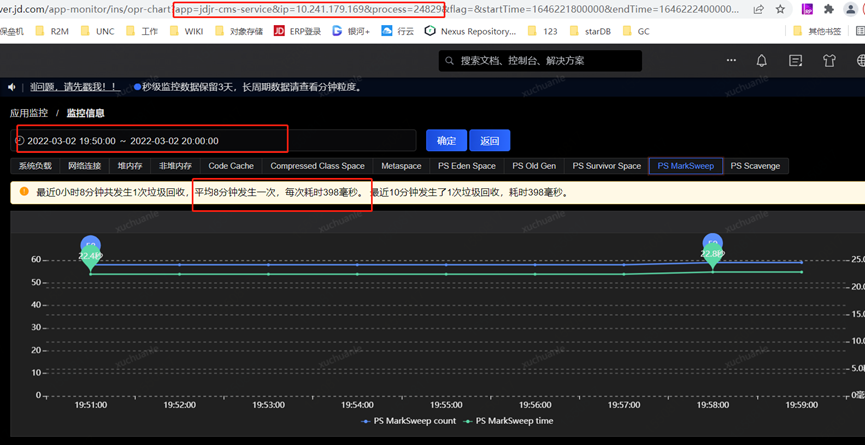
基于以上推測
1、 實名服務由于 GC 間隔較短,內存中的東西根本沒有機會置換到 swap 中就被回收了,GC 的時候不需要將 swap 分區中的數據交換回物理內存中,完全基于內存計算,所以要快很多
2、 將哪些內存數據置換進 swap 交換區的篩選策略應該是類似于 LRU 算法(最近最少使用原則)
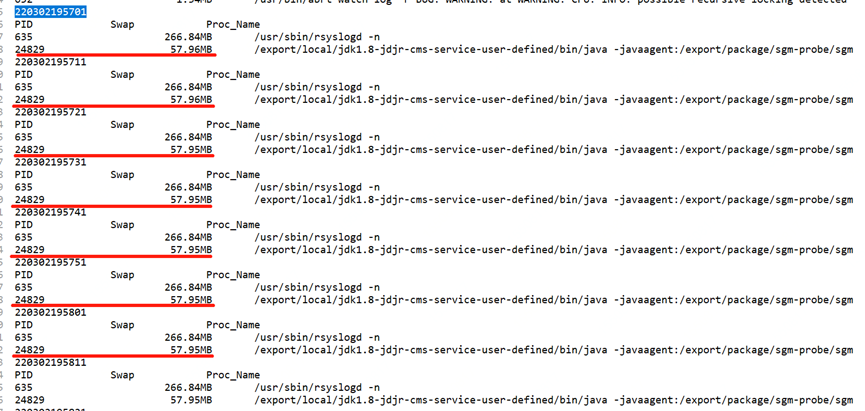
為了證實上述猜測,我們只需跟蹤 swap 變更日志,監控數據變化即可得到答案,這里采用一段 shell 腳本實現
#!/bin/bash
echo -e `date +%y%m%d%H%M%S`
echo -e "PID Swap Proc_Name"
#拿出/proc目錄下所有以數字為名的目錄(進程名是數字才是進程,其他如sys,net等存放的是其他信息)
for pid in `ls -l /proc | grep ^d | awk '{ print $9 }'| grep -v [^0-9]`
do
if [ $pid -eq 1 ];then continue;fi
grep -q "Swap" /proc/$pid/smaps 2>/dev/null
if [ $? -eq 0 ];then
swap=$(gawk '/Swap/{ sum+=$2;} END{ print sum }' /proc/$pid/smaps) #統計占用的swap分區的 大小 單位是KB
proc_name=$(ps aux | grep -w "$pid" | awk '!/grep/{ for(i=11;i<=NF;i++){ printf("%s ",$i); }}') #取出進程的名字
if [ $swap -gt 0 ];then #判斷是否占用swap 只有占用才會輸出
echo -e "${pid} ${swap} ${proc_name100}"
fi
fi
done | sort -k2nr | head -10 | gawk -F' ' '{ #排序取前 10
pid[NR]=$1;
size[NR]=$2;
name[NR]=$3;
}
END{
for(id=1;id<=length(pid);id++)
{
if(size[id]<1024)
printf("%-10s %15sKB %s
",pid[id],size[id],name[id]);
else if(size[id]<1048576)
printf("%-10s %15.2fMB %s
",pid[id],size[id]/1024,name[id]);
else
printf("%-10s %15.2fGB %s
",pid[id],size[id]/1048576,name[id]);
}
}'
由于上面圖中 2022.3.2 1900 至 2022.3.2 1900 發生了一次 Full GC,我們重點關注下這一分鐘內 swap 交換區的變化即可,我這里每 10s 做一次信息采集,可以看到在 GC 時點前后,swap 確實沒有變化
通過上述分析,回歸本文核心問題上,現在看來我的處理方式過于激進了,其實也可以不用關閉 swap,通過適當降低堆大小,也是能夠解決問題的。
這也側面的說明,部署 Java 服務的 Linux 系統,在內存分配上并不是無腦大而全,需要綜合考慮不同場景下 JVM 對 Java 永久代 、Java 堆 (新生代和老年代)、線程棧、Java NIO 所使用內存的需求。
總結
綜上,我們得出結論,swap 和 GC 同一時候發生會導致 GC 時間非常長,JVM 嚴重卡頓,極端的情況下會導致服務崩潰。
主要原因是:JVM 進行 GC 時,需要對對應堆分區的已用內存進行遍歷,假如 GC 的時候,有堆的一部分內容被交換到 swap 中,遍歷到這部分的時候就須要將其交換回內存;更極端情況同一時刻因為內存空間不足,就需要把內存中堆的另外一部分換到 SWAP 中去,于是在遍歷堆分區的過程中,會把整個堆分區輪流往 SWAP 寫一遍,導致 GC 時間超長。線上應該限制 swap 區的大小,如果 swap 占用比例較高應該進行排查和解決,適當的時候可以通過降低堆大小,或者添加物理內存。
因此,部署 Java 服務的 Linux 系統,在內存分配上要慎重。
以上內容希望可以起到拋轉引玉的作用,如有理解不到位的地方煩請指出。
-
Linux
+關注
關注
87文章
11292瀏覽量
209335 -
服務器
+關注
關注
12文章
9123瀏覽量
85329 -
JAVA
+關注
關注
19文章
2966瀏覽量
104702 -
JVM
+關注
關注
0文章
158瀏覽量
12220 -
日志
+關注
關注
0文章
138瀏覽量
10639
原文標題:一次JVM GC長暫停的排查過程
文章出處:【微信號:OSC開源社區,微信公眾號:OSC開源社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
波特率漂移導致通信異常的故障排查過程
labview如何做到一次觸發采集一次
看看基于JDK中自帶JVM工具的用法
Native Memory Tracking 詳解(4):使用 NMT 協助排查內存問題案例
一次呼叫典型流程
DC-DC電源故障排查過程和總結,珍貴的經驗!資料下載

JVM CPU使用率飆高問題的排查分析過程

JVM的一些重要參數
jvm內存溢出故障排查
記錄一次使用easypoi時與源碼博弈的過程

記一次JSF異步調用引起的接口可用率降低





 工商網監
工商網監
評論