 NVIDIA 助力 DeepRec 為 vivo 推薦業務實現高性能 GPU 推理優化
NVIDIA 助力 DeepRec 為 vivo 推薦業務實現高性能 GPU 推理優化
本案例中,vivo 人工智能推薦算法組自研的推薦服務平臺,使用阿里巴巴開源大規模稀疏模型訓練和預測引擎 DeepRec,在稀疏模型訓練(稀疏功能、I/O 優化)和高性能推理框架層面,實現其搜廣推各類業務場景下,算法開發和上線的全鏈路優化。
其中,在 GPU 線上推理服務優化上,vivo 使用 DeepRec 提供的 Device Placement Optimization,以及 NVIDIA CUDA multi-stream,MPS (Multi-Process Service) / Multi-context 和 NVIDIA GPU 計算專家團隊在 multi-stream 基礎上開發的 MergeStream 功能,顯著提升了線上推理服務的 GPU 有效利用率。
vivo 人工智能推薦算法組的業務包含了信息流、視頻、音樂、廣告等搜索/廣告/推薦各類業務,基本涵蓋了搜廣推各類型的業務。
為了支撐上述場景的算法開發上線,vivo 自研了集特征數據、模型開發、模型推理等流程于一體的推薦服務平臺。通過成熟、規范的推薦組件及服務,該平臺為 vivo 內各推薦業務(廣告、信息流等)提供一站式的推薦解決方案,便于業務快速構建推薦服務及算法策略高效迭代。
圖片來源于 vivo
vivo 人工智能推薦算法組在深耕業務同時,在積極探索適用于搜索/廣告/推薦大規模性稀疏性算法訓練框架。分別探索了 TensorNet/XDL/TFRA 等框架及組件,這些框架組件在分布式、稀疏性功能上做了擴展,能夠彌補 TensorFlow 在搜索/廣告/推薦大規模性稀疏性場景不足,但是在通用性、易用性以及功能特點上,這些框架存在各種不足。
作為 DeepRec 最早的一批社區用戶,vivo 在 DeepRec 還是內部項目時,就與 DeepRec 開發者保持密切的合作。經過一年積累與打磨,vivo 見證了 DeepRec 從內部項目到開源再到后續多個 release 版本的發布。在合作中,DeepRec 賦能 vivo 各個業務增長,vivo 也作為 DeepRec 深度用戶,將業務中的需求以及使用中的問題積極回饋到 DeepRec 開源社區。
DeepRec (https://github.com/alibaba/DeepRec) 是阿里巴巴集團提供的針對搜索、推薦、廣告場景模型的訓練/預測引擎,在分布式、圖優化、算子、Runtime 等方面對稀疏模型進行了深度性能優化,提供了豐富的高維稀疏特征功能的支持。基于 DeepRec 進行模型迭代不僅能帶來更好的業務效果,同時在 Training/Inference 性能有明顯的性能提升。

圖片來源于阿里巴巴
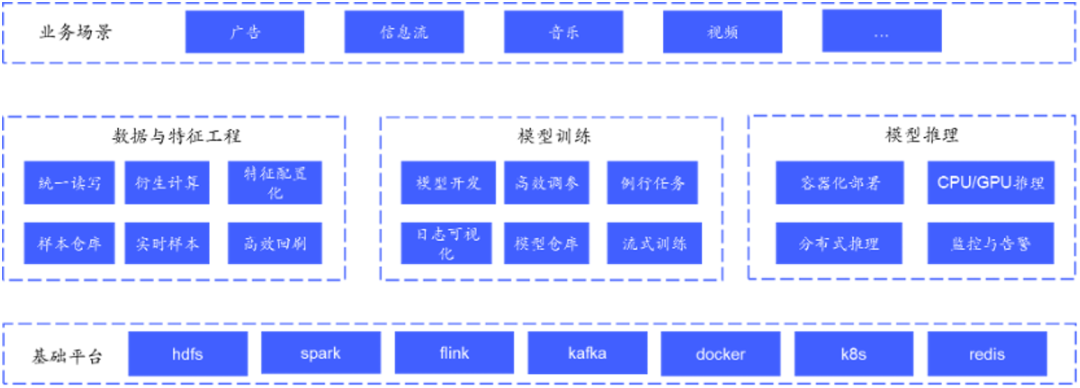
通過業務實踐,在稀疏模型訓練層面,vivo 使用 DeepRec 提供的基于 Embedding Variable (https://deeprec.readthedocs.io/zh/latest/Embedding-Variable.html) 的動態 Embedding 功能和特征準入 (https://deeprec.readthedocs.io/zh/latest/Feature-Filter.html)/淘汰功能(https://deeprec.readthedocs.io/zh/latest/Feature-Eviction.htm),解決了使用 TensorFlow 原生 Embedding Layer 的三個痛點,包括可拓展性差,hash 沖突導致模型訓練有損,無法處理冗余的稀疏特征;并在內部嘗試對訓練數據存儲格式做 I/O 優化。
圖片來源于阿里巴巴
使用動態 Embedding 和特征準入/淘汰功能實現的收益如下:
-
靜態 Embedding 升級到動態 Embedding:使用 DeepRec 的動態 Embedding 替換 TensorFlow 的靜態 Embedding 后,保證所有特征 Embedding 無沖突,離線 AUC 提升 0.5%,線上點擊率提升 1.2%,同時模型體積縮小 20%。
-
ID 特征的利用:在使用 TensorFlow 時,vivo 嘗試過對 ID 特征進行 hash 處理輸入模型,實驗表明這種操作對比基線具有負收益。這是由于 ID 特征過于稀疏,同時 ID 具有唯一指示性,hash 處理會帶來大量的 Embedding 沖突。基于動態 Embedding,使用 ID 特征離線 AUC 提升 0.4%,線上點擊率提升 0.6%。同時配合 global step 特征淘汰,離線 AUC 提升 0.1%,線上點擊率提升 0.5%。
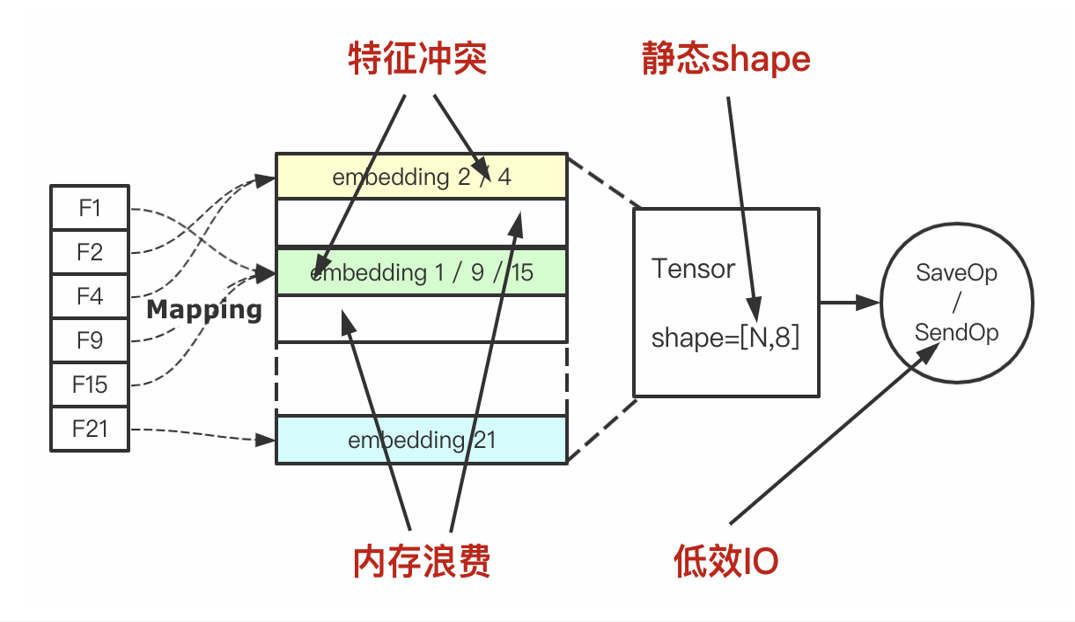
Embedding Variable 流程示意圖
圖片來源于阿里巴巴
在 I/O 優化上,目前 vivo 內部使用的是 TFRecord 數據格式存儲訓練數據,存在占用存儲空間大,非明文存儲的兩個缺陷。而 DeepRec 的 Parquet 是一種列式存儲的數據格式,能夠節省存儲資源,加快數據讀取速度。使用 Parquet Dataset 支持讀取 Parquet 文件,開箱即用,無需額外安裝第三庫,使用簡單方便。同時,Parquet Dataset 能夠加快數據讀取速度,提高模型訓練的 I/O 性能。
vivo 內部嘗試使用 Parquet Dataset 來替換現有 TFRecord,提高訓練速度 30%,減少樣本存儲成本 38%,降低帶寬成本。同時,vivo 內部支持 hive 查詢 Parquet 文件,算法工程師能夠高效快捷地分析樣本數據。
在高性能推理框架層面,由于在業務逐漸發展過程中,廣告召回量增長 3.5 倍,同時目標預估數增加兩倍,推理計算復雜度增加,超時率超過 5%,嚴重影響線上服務可用性以及業務指標。因此,vivo 嘗試探索升級改造現有推理服務,保證業務可持續發展。vivo 借助 DeepRec 開源的諸多推理優化功能,在 CPU 推理改造以及 GPU 推理升級方面進行探索,并取得一定收益。
客戶挑戰
在 CPU 推理優化層面,vivo 在使用 DeepRec 提供的基于 ShareNothing 架構的 SessionGroup 后,明顯緩解了直接使用 TensorFlow 的 C++ 接口調用 Session::Run 而導致的 CPU 使用率低的問題,在保證 latency 的前提下極大提高了 QPS,單機 QPS 提升高達 80%,單機 CPU 利用率提升 75%。
但是經過 SessionGroup 的優化,雖然 CPU 推理性能得到改善,超時率依舊無法得到緩解。鑒于多目標模型目標塔數較多、模型中使用 Attention、LayerNorm、GateNet 等復雜結構、特征多,存在大量稀疏特征三點原因,vivo 嘗試探索 GPU 推理來優化線上性能。
應用方案
Device Placement Optimization
通常,對于稀疏特征的處理一般是將其 Embedding 化,由于模型中存在大量的稀疏特征,因此 vivo 的廣告模型使用大量的 Embedding 算子。從推理的 timeline 可以看出,Embedding 算子分散在 timeline 的各個階段,導致大量的 GPU kernel launch 以及數據拷貝,因此圖計算非常耗時。
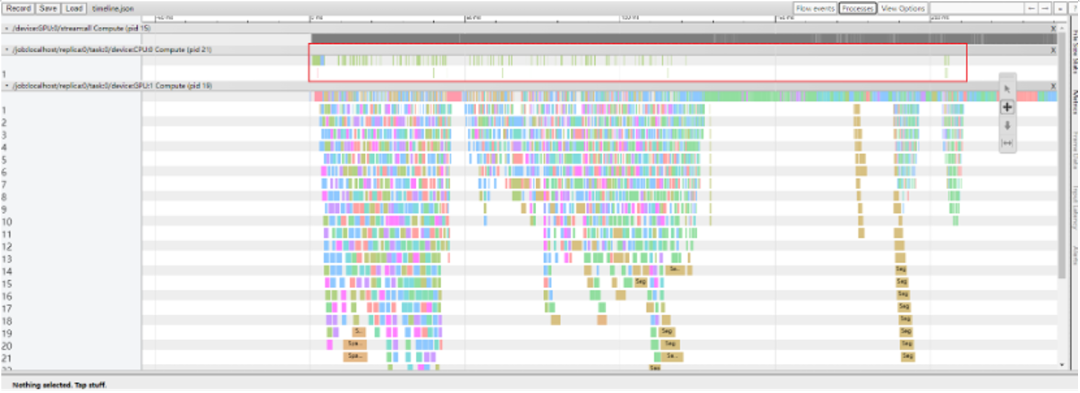
圖片來源于阿里巴巴
Device PlacementOptimization 完全將 Embedding Layer placed 到 CPU 上,解決了Embedding Layer 內部存在的 CPU 和 GPU 之間大量數據拷貝的問題。

圖片來源于阿里巴巴
Device Placement Optimization 性能優化明顯,CPU 算子(主要是 Embedding Layer)的計算集中在 timeline 的最開端,之后 GPU 主要負責網絡層的計算。相較于 CPU 推理,Device Placement Optimization P99 降低 35%。
NVIDIA CUDA Multi-Stream 功能
在推理過程中,vivo 發現單流執行導致 GPU 的利用率不高,無法充分挖掘 GPU 算力。DeepRec 支持用戶使用 multi-stream 功能,多 stream 并發計算,提升 GPU 利用率。多線程并發 launch kernel 時,存在較大的鎖開銷,極大影響了 kernel launch 的效率,這里的鎖與 CUDA Driver 中的 Context 相關。因此可以通過使用 MPS/Multi-context 來避免 launch 過程中鎖開銷,從而進一步提升 GPU 的有效利用率。
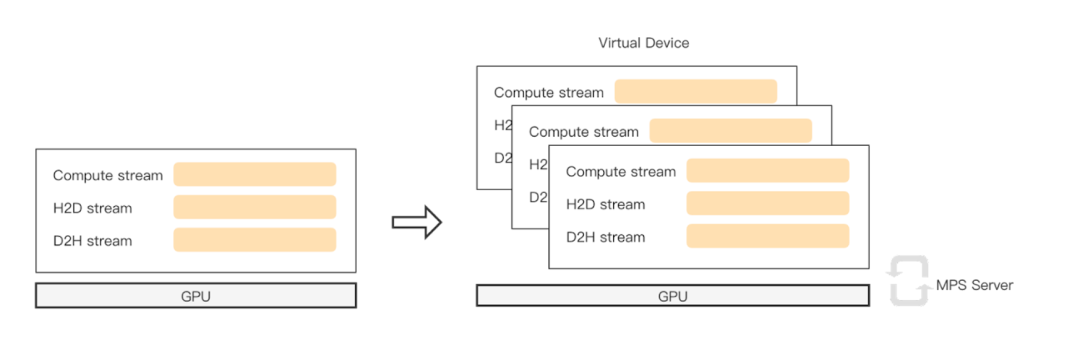
圖片來源于阿里巴巴
此外,模型中存在大量的 H2D 以及 D2H 的數據拷貝,在原生代碼中,計算 stream 和拷貝 stream 是獨立的,這會導致 stream 之間存在大量同步開銷,同時對于在 Recv 算子之后的計算算子,必須等到 MemCopy 完成之后才能被 launch 執行,MemCopy 和 launch 難以 overlap 執行。基于以上問題,NVIDIA GPU 計算專家團隊在 multi-stream 功能基礎上進一步優化,開發了 MergeStream 功能,允許 MemCopy 和計算使用相同的 stream,從而減少上述的同步開銷以及允許 Recv 之后計算算子 launch 開銷被 overlap。

圖片來源于阿里巴巴
vivo 在線上推理服務中使用了 multi-stream 功能,P99 降低 18%。更進一步地,在使用 MergeStream 功能后,P99 降低 11%。
編譯優化 - BladeDISC
BladeDISC(https://github.com/alibaba/BladeDISC)是阿里集團自主研發的、原生支持存在動態尺寸模型的深度學習編譯器。DeepRec 中集成了 BladeDISC,通過使用 BladeDISC 內置的 aStitch 大尺度算子融合技術對于存在較多訪存密集型算子的模型有顯著的效果。利用 BladeDISC 對模型進行編譯優化,推理性能得到大幅度提升。
BladeDISC 將大量訪存密集型算子編譯成一個大的融合算子,可以大大減少框架調度和 kernel launch 的開銷。區別于其他深度學習編譯器的是,BladeDISC 還會通過優化 GPU 不同層次存儲(特別是 SharedMemory)的使用來提升了訪存操作和 Op 間數據交換的性能。圖中可以看到,綠色是 Blade DISC優化合并的算子替代了原圖中大量的算子。
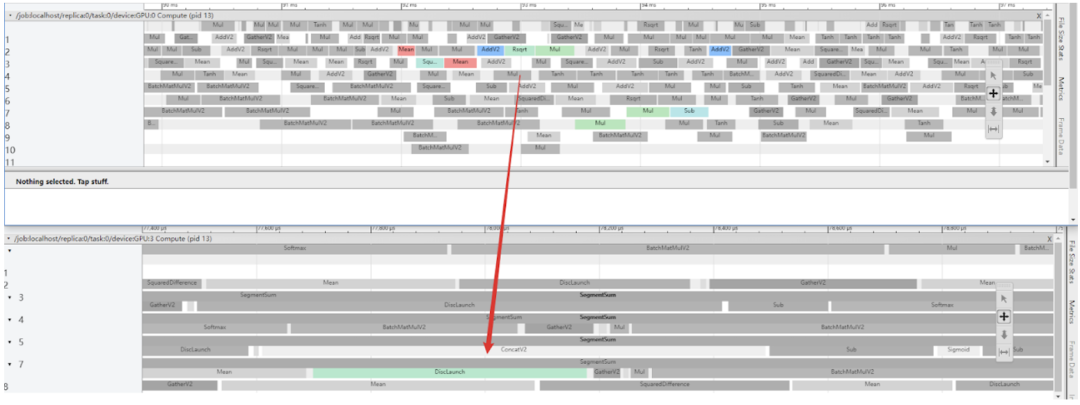
圖片來源于阿里巴巴

圖片來源于阿里巴巴
另外,由于線上模型比較復雜,為了進一步減少編譯耗時、提升部署效率,vivo 啟用了 BladeDISC 的編譯緩存功能。開啟此功能時,BladeDISC 僅會在新舊版本模型的 Graph 結構發生改變時觸發編譯,如果新舊模型僅有權重變更則復用之前的編譯結果。經過驗證,編譯緩存在保證正確性的同時,幾乎掩蓋了編譯模型的開銷,模型更新速度與之前幾乎相同。在使用 BladeDISC 功能后,線上服務 P99 降低 21%。
使用效果及影響
DeepRec 提供大量的解決方案可以幫助用戶快速實施 GPU 推理。經過一系列優化,相較于 CPU 推理,GPU 推理 P99 降低 50%,GPU 利用率平均在 60% 以上。此外,線上一張 NVIDIA T4 Tensor Core GPU 的推理性能超過兩臺 Xeon 6330 112Core 的 CPU 機器,節省了大量的機器資源。
基于 CPU 的分布式異步訓練存在兩個問題:一是異步訓練會損失訓練精度,模型難以收斂到最佳;二是隨著模型結構逐漸復雜,訓練性能會急劇下降。未來,vivo 打算嘗試基于 GPU 的同步訓練來加速復雜模型訓練。DeepRec 支持兩種 GPU 同步框架:NVIDIA Merlin Sparse Operation Kit (SOK) 和 HybridBackend。后續 vivo 將嘗試這兩種 GPU 同步訓練來加速模型訓練。
NVIDIA 計算專家團隊也與 DeepRec 技術團隊深入合作,為在稀疏功能層面的 Embedding Variable GPU 支持、在同步訓練層面的 Merlin SOK 集成,以及圖優化層面的 Embedding 子圖 Fusion 功能開發提供技術支持。
Embedding Variable GPU 支持介紹 (https://deeprec.readthedocs.io/zh/latest/Embedding-Variable-GPU.html)
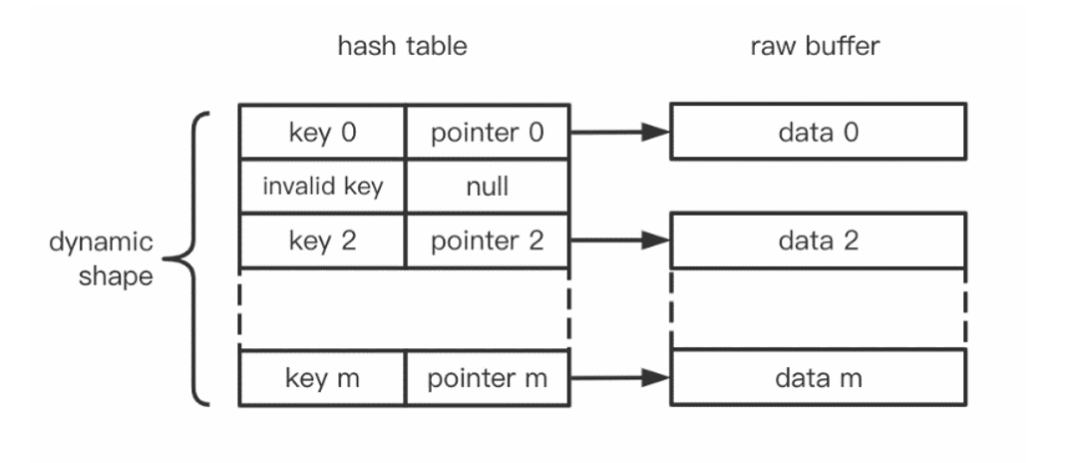
DeepRec 設計并提供了一套支持動態 Embedding 語義的 Embedding Variable,在特征無損訓練的同時以最經濟的方式使用內存資源,使得超大規模特征的模型更容易增量上線。進一步地,因為 GPU 具有強大的并行計算能力,對于 Embedding Variable 底層的 Hash Table 查找、插入等操作也具有明顯的加速作用。同時,對于模型計算部分若使用 GPU,則使用 GPU 上的 Embedding Variable 也可避免 Host 和 Device 上的數據拷貝,提高整體性能。因此增加了 Embedding Variable 的 GPU 支持。
GPU 版本的 Embedding Variable 通過 NVIDIA cuCollection 作為底層 Hash Table 的實現,可以明顯加速 Embedding 相關的操作,而且使用方便,在具有 NVIDIA GPU 的環境中會自動啟用,也可以手動放置在合適的 GPU 設備上。性能測試顯示 GPU 版本相比于 CPU 版本,Embedding 部分會有 2 倍以上的加速。
分布式訓練集成 Merlin SOK 介紹 (https://deeprec.readthedocs.io/zh/latest/SOK.html)
DeepMerlin SOK 是 NVIDIA Merlin 團隊基于 Merlin SOK 提供的針對神經網絡中稀疏操作的加速插件庫,使用 DeepMerlin SOK 可對 DeepRec 中相關的 Embedding 操作進行加速和分布式訓練的支持。
該 SOK 的設計理念就是希望同時兼容靈活性和高性能。在靈活性方面,使用 SOK 不會對用戶使用 DeepRec 本身的功能有影響,可以和 DeepRec 提供的 Embedding Variable 完全兼容,也會集成到 DeepRec 的高級接口方便用戶的使用。在高性能方面,SOK 主要從兩方面去考慮,一方面,在算法設計上,通過 reduce 操作來減少搬運的數據量,另一方面,在實現上,主要通過算子融合技術,融合多表的查詢和通信,提供稀疏操作的性能。性能測試顯示 SOK 能夠提供接近于線性的擴展能力,在 8 GPU 下相比 1 GPU 能夠達到 6.5 倍的加速效果。
Embedding 子圖 Fusion 功能介紹 (https://deeprec.readthedocs.io/zh/latest/Fused-Embedding.html)
DeepRec 及 TensorFlow 原生的 embedding lookup 相關 API,如 safe_embedding_lookup_sparse,會創建比較多細碎的算子,且部分算子只有 CPU 實現。因此在 GPU 上執行時容易出現 kernel launch bound 的問題以及額外 H2D & D2H 拷貝,造成低 GPU 利用率,降低執行速度。
針對此場景,NVIDIA 計算專家團隊與 DeepRec 合作,共同定制開發了支持在 NVIDIA GPU 上執行的 Embedding 子圖 Fusion 功能,并對 GPU 高算力高吞吐的特點進行了針對性優化:提供一組接口以及相關 Fusion 算子,通過算子融合,減少需要 launch 的 kernel 數量,優化訪存,提供高性能的實現,達到加速執行的目的。
Embedding Fusion 功能易用,從 Python 層面提供接口及開關,用戶無需修改代碼即可快速使用。加速效果方面,單獨從 Embedding 模塊看,GPU Embedding Fusion 可以提供 2 倍左右的加速。從整體模型來看,加速效果取決于 Embedding 模塊的耗時占比。在幾個測試模型上,此功能可以提供 1.2 倍左右的整體性能加速。
點擊“閱讀原文”或掃描下方海報二維碼,即可免費注冊 GTC 23,切莫錯過這場 AI 和元宇宙時代的技術大會!
原文標題:NVIDIA 助力 DeepRec 為 vivo 推薦業務實現高性能 GPU 推理優化
文章出處:【微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3771瀏覽量
90995
原文標題:NVIDIA 助力 DeepRec 為 vivo 推薦業務實現高性能 GPU 推理優化
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
解鎖NVIDIA TensorRT-LLM的卓越性能
助力AIoT應用:在米爾FPGA開發板上實現Tiny YOLO V4
全新NVIDIA NIM微服務實現突破性進展
AMD與NVIDIA GPU優缺點
NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案

GPU高性能服務器配置
澎峰科技高性能大模型推理引擎PerfXLM解析

IaaS+on+DPU(IoD)+下一代高性能算力底座技術白皮書
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
NVIDIA全面加快Meta Llama 3的推理速度
利用NVIDIA組件提升GPU推理的吞吐
降本增效:NVIDIA路徑優化引擎創下多項世界紀錄!
NVIDIA 發布全新交換機,全面優化萬億參數級 GPU 計算和 AI 基礎設施

Torch TensorRT是一個優化PyTorch模型推理性能的工具






 工商網監
工商網監
評論