 NVIDIA Triton 系列文章(11):模型類別與調度器-2
NVIDIA Triton 系列文章(11):模型類別與調度器-2
在上篇文章中,已經說明了有狀態(stateful)模型的“控制輸入”與“隱式狀態管理”的使用方式,本文內容接著就繼續說明“調度策略”的使用。
(續前一篇文章的編號)
(3) 調度策略(Scheduling Strategies)在決定如何對分發到同一模型實例的序列進行批處理時,序列批量處理器(sequence batcher)可以采用以下兩種調度策略的其中一種:
現在簡單說明以下配置的內容: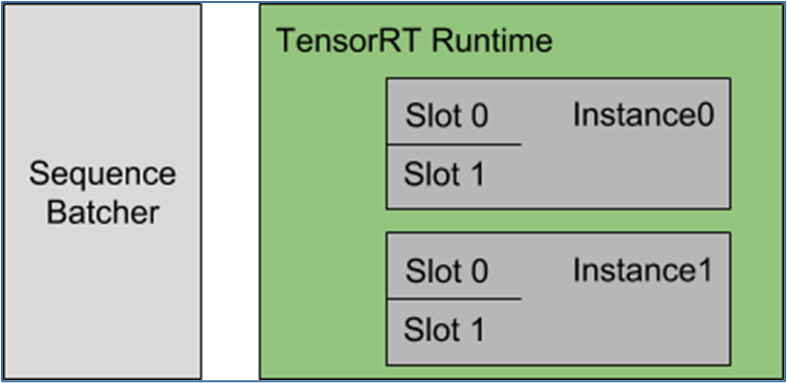 每個模型實例都在維護每個批處理槽的狀態,并期望將給定序列的所有推理請求分發到同一槽,以便正確更新狀態。對于本例,這意味著 Triton 可以同時 4 個序列進行推理。
使用直接調度策略,序列批處理程序會執行以下動作:
每個模型實例都在維護每個批處理槽的狀態,并期望將給定序列的所有推理請求分發到同一槽,以便正確更新狀態。對于本例,這意味著 Triton 可以同時 4 個序列進行推理。
使用直接調度策略,序列批處理程序會執行以下動作:
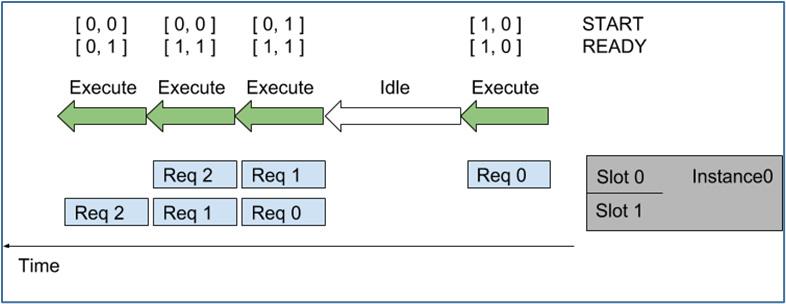
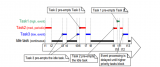
下圖顯示使用直接調度策略,將多個序列調度到模型實例上的執行:
 圖左顯示了到達 Triton 的 5 個請求序列,每個序列可以由任意數量的推理請求組成。圖右側顯示了推理請求序列是如何隨時間安排到模型實例上的,
圖左顯示了到達 Triton 的 5 個請求序列,每個序列可以由任意數量的推理請求組成。圖右側顯示了推理請求序列是如何隨時間安排到模型實例上的,
 ?隨著時間的推移(從右向左),會發生以下情況:
?隨著時間的推移(從右向左),會發生以下情況:
在本示例中,模型需要序列批量處理的開始、結束和相關 ID 控制輸入。下圖顯示了此配置指定的序列批處理程序和推理資源的表示。
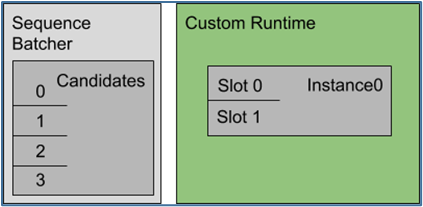 使用最舊的調度策略,序列批處理程序會執行以下工作:
使用最舊的調度策略,序列批處理程序會執行以下工作:
下圖顯示將多個序列調度到上述示例配置指定的模型實例上,左圖顯示 Triton 接收了四個請求序列,每個序列由多個推理請求組成:
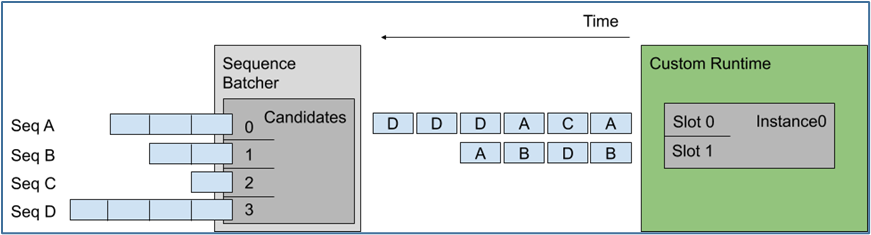 這里假設每個請求的長度是相同的,那么左邊候選序列中送進右邊批量處理槽的順序,就是上圖中間的排列順序。
最舊的策略從最舊的請求中形成一個動態批處理,但在一個批處理中從不包含來自給定序列的多個請求,例如上面序列 D 中的最后兩個推理不是一起批處理的。
以上是關于有狀態模型的“調度策略”主要內容,剩下的“集成模型”部分,會在下篇文章中提供完整的說明。
這里假設每個請求的長度是相同的,那么左邊候選序列中送進右邊批量處理槽的順序,就是上圖中間的排列順序。
最舊的策略從最舊的請求中形成一個動態批處理,但在一個批處理中從不包含來自給定序列的多個請求,例如上面序列 D 中的最后兩個推理不是一起批處理的。
以上是關于有狀態模型的“調度策略”主要內容,剩下的“集成模型”部分,會在下篇文章中提供完整的說明。
- 直接(direct)策略
| name: "direct_stateful_model"platform: "tensorrt_plan"max_batch_size: 2sequence_batching{ max_sequence_idle_microseconds: 5000000direct { } control_input [{name: "START" control [{ kind: CONTROL_SEQUENCE_START fp32_false_true: [ 0, 1 ]}]},{name: "READY" control [{ kind: CONTROL_SEQUENCE_READY fp32_false_true: [ 0, 1 ]}]}]}#續接右欄 | #上接左欄input [{name: "INPUT" data_type: TYPE_FP32dims: [ 100, 100 ]}]output [{name: "OUTPUT" data_type: TYPE_FP32dims: [ 10 ]}]instance_group [{ count: 2}] |
- sequence_batching 部分指示模型會使用序列調度器的 Direct 調度策略;
- 示例中模型只需要序列批處理程序的啟動和就緒控制輸入,因此只列出這些控制;
- instance_group 表示應該實例化模型的兩個實例;
- max_batch_size 表示這些實例中的每一個都應該執行批量大小為 2 的推理計算。
每個模型實例都在維護每個批處理槽的狀態,并期望將給定序列的所有推理請求分發到同一槽,以便正確更新狀態。對于本例,這意味著 Triton 可以同時 4 個序列進行推理。
使用直接調度策略,序列批處理程序會執行以下動作:
| 所識別的推理請求種類 | 執行動作 |
| 需要啟動新序列 | 1. 有可用處理槽時:就為該序列分配批處理槽2. 無可用處理槽時:就將推理請求放在積壓工作中 |
| 是已分配處理槽序列的一部分 | 將該請求分發到該配置好的批量處理槽 |
| 是積壓工作中序列的一部分 | 將請求放入積壓工作中 |
| 是最后一個推理請求 | 1. 有積壓工作時:將處理槽分配給積壓工作的序列2. 有積壓工作:釋放該序列處理槽給其他序列使用 |
圖左顯示了到達 Triton 的 5 個請求序列,每個序列可以由任意數量的推理請求組成。圖右側顯示了推理請求序列是如何隨時間安排到模型實例上的,
- 在實例 0 與實例 1 中各有兩個槽 0 與槽 1;
- 根據接收的順序,為序列 0 至序列 3 各分配一個批量處理槽,而序列 4 與序列 5 先處于排隊等候狀態;
- 當序列 3 的請求全部完成之后,將處理槽釋放出來給序列 4 使用;
- 當序列 1 的請求全部完成之后,將處理槽釋放出來給序列 5 使用;
?隨著時間的推移(從右向左),會發生以下情況:- 序列中第一個請求(Req 0)到達槽 0 時,因為模型實例尚未執行推理,則序列調度器會立即安排模型實例執行,因為推理請求可用;
- 由于這是序列中的第一個請求,因此 START 張量中的對應元素設置為 1,但槽 1 中沒有可用的請求,因此 READY 張量僅顯示槽 0 為就緒。
- 推理完成后,序列調度器會發現任何批處理槽中都沒有可用的請求,因此模型實例處于空閑狀態。
- 接下來,兩個推理請求(上面的 Req 1 與下面的 Req 0)差不多的時間到達,序列調度器看到兩個處理槽都是可用,就立即執行批量大小為 2 的推理模型實例,使用 READY 顯示兩個槽都有可用的推理請求,但只有槽 1 是新序列的開始(START)。
- 對于其他推理請求,處理以類似的方式繼續。
- 最舊的(oldest)策略
| 直接(direct)策略 | 最舊的(oldest)策略 |
|
direct {} |
oldest { max_candidate_sequences: 4 } |
使用最舊的調度策略,序列批處理程序會執行以下工作:
| 所識別的推理請求種類 | 執行動作 |
| 需要啟動新序列 | 嘗試查找具有候選序列空間的模型實例,如果沒有實例可以容納新的候選序列,就將請求放在一個積壓工作中 |
| 已經是候選序列的一部分 | 將該請求分發到該模型實例 |
| 是積壓工作中序列的一部分 | 將請求放入積壓工作中 |
| 是最后一個推理請求 | 模型實例立即從積壓工作中刪除一個序列,并將其作為模型實例中的候選序列,或者記錄如果沒有積壓工作,模型實例可以處理未來的序列。 |
這里假設每個請求的長度是相同的,那么左邊候選序列中送進右邊批量處理槽的順序,就是上圖中間的排列順序。
最舊的策略從最舊的請求中形成一個動態批處理,但在一個批處理中從不包含來自給定序列的多個請求,例如上面序列 D 中的最后兩個推理不是一起批處理的。
以上是關于有狀態模型的“調度策略”主要內容,剩下的“集成模型”部分,會在下篇文章中提供完整的說明。
原文標題:NVIDIA Triton 系列文章(11):模型類別與調度器-2
文章出處:【微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
英偉達
+關注
關注
22文章
3771瀏覽量
91000
原文標題:NVIDIA Triton 系列文章(11):模型類別與調度器-2
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA推出全新生成式AI模型Fugatto
NVIDIA 開發了一個全新的生成式 AI 模型。利用輸入的文本和音頻,該模型可以創作出包含任意的音樂、人聲和聲音組合的作品。
NVIDIA NIM助力企業高效部署生成式AI模型
Canonical、Nutanix 和 Red Hat 等廠商的開源 Kubernetes 平臺集成了 NVIDIA NIM,將允許用戶通過 API 調用來大規模地部署大語言模型。
NVIDIA新增生成式AI就緒系統認證類別
借助全新的 NVIDIA Spectrum-X Ready 和 NVIDIA IGX 認證,領先的制造業合作伙伴將提供高性能系統,幫助客戶輕松部署 AI。
NVIDIA助力提供多樣、靈活的模型選擇
在本案例中,Dify 以模型中立以及開源生態的優勢,為廣大 AI 創新者提供豐富的模型選擇。其集成的 NVIDIAAPI Catalog、NVIDIA NIM和Triton 推理服務
NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據
Nemotron-4 340B 是針對 NVIDIA NeMo 和 NVIDIA TensorRT-LLM 優化的模型系列,該系列包含最先進

英偉達推出全新NVIDIA AI Foundry服務和NVIDIA NIM推理微服務
NVIDIA 宣布推出全新 NVIDIA AI Foundry 服務和 NVIDIA NIM 推理微服務,與同樣剛推出的 Llama 3.1 系列開源
NVIDIA AI Foundry 為全球企業打造自定義 Llama 3.1 生成式 AI 模型
借助 NVIDIA AI Foundry,企業和各國現在能夠使用自有數據與 Llama 3.1 405B 和 NVIDIA Nemotron 模型配對,來構建“超級模型”
發表于 07-24 09:39
?706次閱讀

如何在tx2部署模型
在本文中,我們將詳細介紹如何在NVIDIA Jetson TX2上部署深度學習模型。NVIDIA Jetson TX2是一款專為邊緣計算和人
NVIDIA與Google DeepMind合作推動大語言模型創新
支持 NVIDIA NIM 推理微服務的谷歌最新開源模型 PaliGemma 首次亮相。
淺析FreeRTOS任務調度器的三種調度算法和應用
FreeRTOS在MCU領域應用非常廣泛,今天就給大家講解一下FreeRTOS調度器中的三種調度算法,以及在瑞薩RZ/T2L MPU中的應用。
NVIDIA加速微軟最新的Phi-3 Mini開源語言模型
NVIDIA 宣布使用 NVIDIA TensorRT-LLM 加速微軟最新的 Phi-3 Mini 開源語言模型。TensorRT-LLM 是一個開源庫,用于優化從 PC 到云端的 NVID
使用NVIDIA Triton推理服務器來加速AI預測
這家云計算巨頭的計算機視覺和數據科學服務使用 NVIDIA Triton 推理服務器來加速 AI 預測。
在AMD GPU上如何安裝和配置triton?
最近在整理python-based的benchmark代碼,反過來在NV的GPU上又把Triton裝了一遍,發現Triton的github repo已經給出了對應的llvm的commit id以及對應的編譯細節,然后跟著走了一遍,也順利的安裝成功,只需要按照如下方式即可完

【BBuf的CUDA筆記】OpenAI Triton入門筆記一
這里來看官方的介紹:https://openai.com/research/triton ,從官方的介紹中我們可以看到OpenAI Triton的產生動機以及它的目標是什么,還可以看到一些經典算法的實現例子展示。

利用NVIDIA產品技術組合提升用戶體驗
本案例通過利用NVIDIA TensorRT-LLM加速指令識別深度學習模型,并借助NVIDIA Triton推理服務器在





 工商網監
工商網監
評論