") 如何破解PCIe 6.0帶來的芯片設(shè)計(jì)新挑戰(zhàn)?
如何破解PCIe 6.0帶來的芯片設(shè)計(jì)新挑戰(zhàn)?

本文轉(zhuǎn)載自《半導(dǎo)體行業(yè)觀察》感謝《半導(dǎo)體行業(yè)觀察》對(duì)新思科技的關(guān)注 PCI Express (PCIe) 6.0規(guī)范實(shí)現(xiàn)了64GT/s鏈路速度,還帶來了包括帶寬翻倍在內(nèi)的多項(xiàng)重大改變,這也為SoC設(shè)計(jì)帶來了諸多新變化和挑戰(zhàn)。對(duì)于HPC、AI和存儲(chǔ)SoC開發(fā)者來說,如何理解并應(yīng)對(duì)這些變化帶來的設(shè)計(jì)挑戰(zhàn)變得至關(guān)重要。 本文將就上述問題和方案作詳細(xì)介紹及探討。 PCIe 6.0的重大新變化 變化一:PCIe 6.0電器性發(fā)生根本性的機(jī)制改變 為了實(shí)現(xiàn)64GT/s的鏈路速度,PCIe 6.0采用脈沖幅度調(diào)制4級(jí) (PAM4) 信號(hào),在與32GT/s PCIe相同的單元間隔(UI)中提供4個(gè)幅度級(jí)別(2 位)。圖1顯示了三眼眼圖與此前的單眼眼圖的對(duì)比。
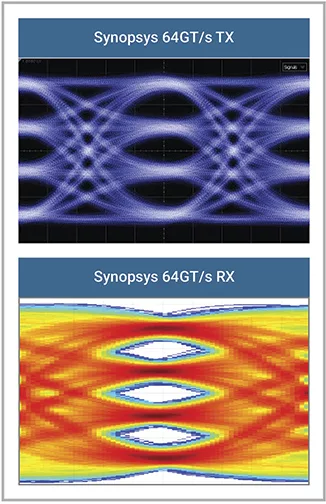 圖 1:與NRZ信號(hào)相比,PCIe 6.0 PAM-4信號(hào)是三眼眼圖
與NRZ相比,轉(zhuǎn)換到PAM4信號(hào)編碼引入了更高的誤碼率(BER)。為緩解這種情況,6.0規(guī)范在以 64GT/s 運(yùn)行時(shí)實(shí)現(xiàn)了許多新功能。例如,當(dāng)將新的4級(jí)電壓眼圖映射到數(shù)字值時(shí),格雷編碼可以最小化每個(gè) UI 內(nèi)的錯(cuò)誤,并且發(fā)送器應(yīng)用預(yù)編碼來最小化迸發(fā)錯(cuò)誤;PCIe 6.0還采用前向糾錯(cuò)(FEC)機(jī)制來降低較高的誤碼率。這些對(duì) PCIe 協(xié)議和控制器設(shè)計(jì)都具有重大影響。
變化二:新一代協(xié)議的引入
PCIe 6.0 引入了全新的“FLIT 模式”,其中數(shù)據(jù)包被組織在固定大小的流控制單元中,而不是過去規(guī)范版本中的可變大小。這種模式簡化了控制器級(jí)別的數(shù)據(jù)管理,帶來了更高的帶寬效率、更低的延遲和更小的控制器占用空間。當(dāng)以 64GT/s 的速率運(yùn)算時(shí),F(xiàn)LIT 模式使用未編碼數(shù)據(jù)(稱為“1b1b 編碼”),而 128/130 編碼用于 8GT/s 至 32GT/s 的鏈路速度,經(jīng)典8b10b編碼用于2.5GT/s 和 5GT/s 的鏈路速度。
與具有相同配置的 32GT/s PCIe 控制器相比,64GT/s PCIe 6.0 控制器所需的硅面積顯著增加;支持1b1b編碼不僅增加了第三物理層路徑(位于 8b10b 和 128b130b 頂部),還增加了數(shù)據(jù)鏈路層中的邏輯;FLIT模式中使用的新優(yōu)化標(biāo)頭,也進(jìn)一步增加了邏輯門數(shù),超過了 32GT/s 解決方案。
變化三:PIPE數(shù)據(jù)路徑寬度增加,每個(gè)時(shí)鐘周期有多個(gè)數(shù)據(jù)包
為了保持與上一代相同的最大時(shí)鐘頻率,64GT/s下PIPE數(shù)據(jù)路徑寬度增加了一倍,即需要1024位數(shù)據(jù)路徑的16通道設(shè)計(jì),這為芯片設(shè)計(jì)帶來了新的問題。
要知道,大于128位的數(shù)據(jù)路徑寬度,可能會(huì)導(dǎo)致SoC需要在每個(gè)時(shí)鐘周期處理多個(gè)PCIe 數(shù)據(jù)包。最小的PCIe事務(wù)層數(shù)據(jù)包 (TLP) 可以被視為 3 個(gè) DWORD(12 字節(jié))加上 4 字節(jié) LCRC,總共 16 個(gè)字節(jié)(128 位)。在 8GT/s 時(shí),使用PCIe PHY的 500MHz 16 位 PIPE 接口最為常見,這意味著8通道及以下(16 位/通道 * 8 通道 = 128 位)的鏈路寬度會(huì)在每個(gè)時(shí)鐘最多傳輸一個(gè)完整的數(shù)據(jù)包。但是,16通道(16位/通道 * 16通道 = 256位)在每個(gè)時(shí)鐘周期就需要傳輸兩個(gè)完整的數(shù)據(jù)包。
如表1顯示,隨著鏈路速度的提高,每個(gè)時(shí)鐘的完整數(shù)據(jù)包的數(shù)量相應(yīng)增加,從而影響越來越多的設(shè)計(jì)。
圖 1:與NRZ信號(hào)相比,PCIe 6.0 PAM-4信號(hào)是三眼眼圖
與NRZ相比,轉(zhuǎn)換到PAM4信號(hào)編碼引入了更高的誤碼率(BER)。為緩解這種情況,6.0規(guī)范在以 64GT/s 運(yùn)行時(shí)實(shí)現(xiàn)了許多新功能。例如,當(dāng)將新的4級(jí)電壓眼圖映射到數(shù)字值時(shí),格雷編碼可以最小化每個(gè) UI 內(nèi)的錯(cuò)誤,并且發(fā)送器應(yīng)用預(yù)編碼來最小化迸發(fā)錯(cuò)誤;PCIe 6.0還采用前向糾錯(cuò)(FEC)機(jī)制來降低較高的誤碼率。這些對(duì) PCIe 協(xié)議和控制器設(shè)計(jì)都具有重大影響。
變化二:新一代協(xié)議的引入
PCIe 6.0 引入了全新的“FLIT 模式”,其中數(shù)據(jù)包被組織在固定大小的流控制單元中,而不是過去規(guī)范版本中的可變大小。這種模式簡化了控制器級(jí)別的數(shù)據(jù)管理,帶來了更高的帶寬效率、更低的延遲和更小的控制器占用空間。當(dāng)以 64GT/s 的速率運(yùn)算時(shí),F(xiàn)LIT 模式使用未編碼數(shù)據(jù)(稱為“1b1b 編碼”),而 128/130 編碼用于 8GT/s 至 32GT/s 的鏈路速度,經(jīng)典8b10b編碼用于2.5GT/s 和 5GT/s 的鏈路速度。
與具有相同配置的 32GT/s PCIe 控制器相比,64GT/s PCIe 6.0 控制器所需的硅面積顯著增加;支持1b1b編碼不僅增加了第三物理層路徑(位于 8b10b 和 128b130b 頂部),還增加了數(shù)據(jù)鏈路層中的邏輯;FLIT模式中使用的新優(yōu)化標(biāo)頭,也進(jìn)一步增加了邏輯門數(shù),超過了 32GT/s 解決方案。
變化三:PIPE數(shù)據(jù)路徑寬度增加,每個(gè)時(shí)鐘周期有多個(gè)數(shù)據(jù)包
為了保持與上一代相同的最大時(shí)鐘頻率,64GT/s下PIPE數(shù)據(jù)路徑寬度增加了一倍,即需要1024位數(shù)據(jù)路徑的16通道設(shè)計(jì),這為芯片設(shè)計(jì)帶來了新的問題。
要知道,大于128位的數(shù)據(jù)路徑寬度,可能會(huì)導(dǎo)致SoC需要在每個(gè)時(shí)鐘周期處理多個(gè)PCIe 數(shù)據(jù)包。最小的PCIe事務(wù)層數(shù)據(jù)包 (TLP) 可以被視為 3 個(gè) DWORD(12 字節(jié))加上 4 字節(jié) LCRC,總共 16 個(gè)字節(jié)(128 位)。在 8GT/s 時(shí),使用PCIe PHY的 500MHz 16 位 PIPE 接口最為常見,這意味著8通道及以下(16 位/通道 * 8 通道 = 128 位)的鏈路寬度會(huì)在每個(gè)時(shí)鐘最多傳輸一個(gè)完整的數(shù)據(jù)包。但是,16通道(16位/通道 * 16通道 = 256位)在每個(gè)時(shí)鐘周期就需要傳輸兩個(gè)完整的數(shù)據(jù)包。
如表1顯示,隨著鏈路速度的提高,每個(gè)時(shí)鐘的完整數(shù)據(jù)包的數(shù)量相應(yīng)增加,從而影響越來越多的設(shè)計(jì)。
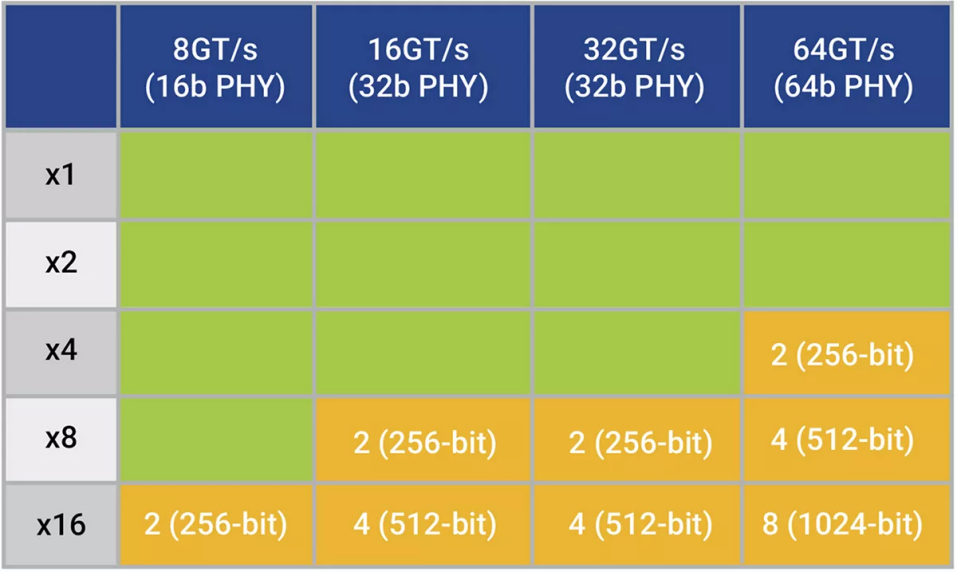 表 1:數(shù)據(jù)路徑寬度隨鏈路速度增加,導(dǎo)致更多配置超過128位閾值
PCIe 6.0的優(yōu)化設(shè)計(jì)
1.松弛排序
PCIe排序規(guī)則需要Posted事務(wù),例如內(nèi)存寫入保持有序,除非數(shù)據(jù)包標(biāo)頭中設(shè)置了松弛排序 (RO) 或 ID 排序 (IDO) 屬性。使用RO集的Posted事務(wù)可以傳遞任何先前 Posted 事務(wù),而使用IDO集的事務(wù)只能使用不同的請(qǐng)求者ID傳遞先前事務(wù)。
以下四個(gè)示例展示了這兩種屬性對(duì)于實(shí)現(xiàn)完整的PCIe 64GT/s 性能的重要性。他們均利用4個(gè)PCIe內(nèi)存的序列寫入256字節(jié)中的每一個(gè),表示將1KB 有效載荷遞送到地址1000,然后是4個(gè)字節(jié)的PCIe內(nèi)存寫入,表示將“成功完成”指示遞送到地址7500。表中的每一行代表一個(gè)時(shí)間段,而三列(從左到右)表示事務(wù)到達(dá)PCIe引腳、應(yīng)用程序接口和 SoC 內(nèi)存。在所有 4 次內(nèi)存寫入之前,“成功完成”指示到達(dá)內(nèi)存的任何場景都反映出失敗,因?yàn)檐浖谑盏街甘竞罅⒓纯蛇M(jìn)行數(shù)據(jù)處理,因此在交付正確的數(shù)據(jù)之前處理。
示例1:只要其中一個(gè)應(yīng)用程序接口的帶寬至少等于 PCIe 帶寬,該接口就可以正常工作。
表 1:數(shù)據(jù)路徑寬度隨鏈路速度增加,導(dǎo)致更多配置超過128位閾值
PCIe 6.0的優(yōu)化設(shè)計(jì)
1.松弛排序
PCIe排序規(guī)則需要Posted事務(wù),例如內(nèi)存寫入保持有序,除非數(shù)據(jù)包標(biāo)頭中設(shè)置了松弛排序 (RO) 或 ID 排序 (IDO) 屬性。使用RO集的Posted事務(wù)可以傳遞任何先前 Posted 事務(wù),而使用IDO集的事務(wù)只能使用不同的請(qǐng)求者ID傳遞先前事務(wù)。
以下四個(gè)示例展示了這兩種屬性對(duì)于實(shí)現(xiàn)完整的PCIe 64GT/s 性能的重要性。他們均利用4個(gè)PCIe內(nèi)存的序列寫入256字節(jié)中的每一個(gè),表示將1KB 有效載荷遞送到地址1000,然后是4個(gè)字節(jié)的PCIe內(nèi)存寫入,表示將“成功完成”指示遞送到地址7500。表中的每一行代表一個(gè)時(shí)間段,而三列(從左到右)表示事務(wù)到達(dá)PCIe引腳、應(yīng)用程序接口和 SoC 內(nèi)存。在所有 4 次內(nèi)存寫入之前,“成功完成”指示到達(dá)內(nèi)存的任何場景都反映出失敗,因?yàn)檐浖谑盏街甘竞罅⒓纯蛇M(jìn)行數(shù)據(jù)處理,因此在交付正確的數(shù)據(jù)之前處理。
示例1:只要其中一個(gè)應(yīng)用程序接口的帶寬至少等于 PCIe 帶寬,該接口就可以正常工作。
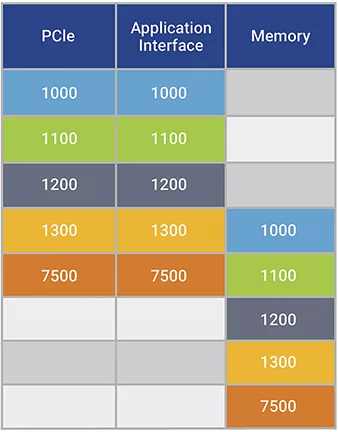 表 2:單一全速率應(yīng)用程序接口可正確傳輸數(shù)據(jù)
示例2:雙接口通常會(huì)出現(xiàn)故障,因?yàn)闊o法保證SoC中兩個(gè)通往內(nèi)存的獨(dú)立路徑之間的到達(dá)順序。
表 2:單一全速率應(yīng)用程序接口可正確傳輸數(shù)據(jù)
示例2:雙接口通常會(huì)出現(xiàn)故障,因?yàn)闊o法保證SoC中兩個(gè)通往內(nèi)存的獨(dú)立路徑之間的到達(dá)順序。
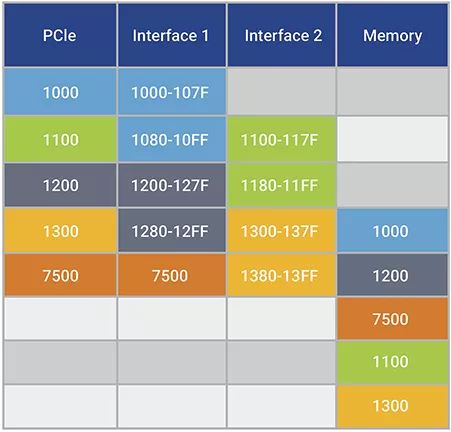 表 3:顯示雙半速率應(yīng)用程序接口失敗,原因是“成功完成”指示早于所有數(shù)據(jù)到達(dá)
示例3:將強(qiáng)排序流量強(qiáng)制到單個(gè)接口可避免出現(xiàn)無序到達(dá),但由于無法使用全部內(nèi)部帶寬,因此很快落后于 PCIe 鏈路。
表 3:顯示雙半速率應(yīng)用程序接口失敗,原因是“成功完成”指示早于所有數(shù)據(jù)到達(dá)
示例3:將強(qiáng)排序流量強(qiáng)制到單個(gè)接口可避免出現(xiàn)無序到達(dá),但由于無法使用全部內(nèi)部帶寬,因此很快落后于 PCIe 鏈路。
 表 4:由于無法全速傳輸數(shù)據(jù),所示的雙半速應(yīng)用程序接口失敗
示例4:當(dāng)鏈路伙伴把數(shù)據(jù)有效載荷數(shù)據(jù)包標(biāo)記為 RO 且把成功完成數(shù)據(jù)包標(biāo)記為強(qiáng)排序時(shí),兩個(gè)半速率接口可以成功傳輸。請(qǐng)注意,當(dāng) RO 有效載荷數(shù)據(jù)無序到達(dá)時(shí),非 RO 寫入 7500 不被允許傳遞有效載荷寫入,因此在發(fā)送所有先前寫入之前,不會(huì)將其發(fā)送到應(yīng)用接口。
表 4:由于無法全速傳輸數(shù)據(jù),所示的雙半速應(yīng)用程序接口失敗
示例4:當(dāng)鏈路伙伴把數(shù)據(jù)有效載荷數(shù)據(jù)包標(biāo)記為 RO 且把成功完成數(shù)據(jù)包標(biāo)記為強(qiáng)排序時(shí),兩個(gè)半速率接口可以成功傳輸。請(qǐng)注意,當(dāng) RO 有效載荷數(shù)據(jù)無序到達(dá)時(shí),非 RO 寫入 7500 不被允許傳遞有效載荷寫入,因此在發(fā)送所有先前寫入之前,不會(huì)將其發(fā)送到應(yīng)用接口。
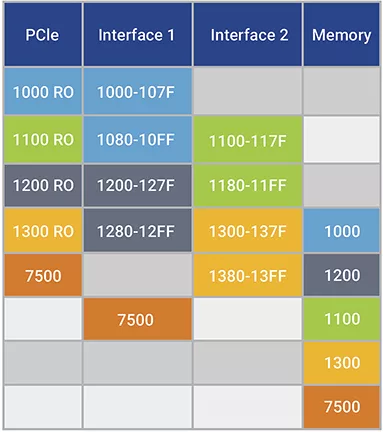 表 5:顯示雙半速應(yīng)用程序接口通過對(duì)有效載荷數(shù)據(jù)使用松弛排序成功
SoC 設(shè)計(jì)人員可以在其出站數(shù)據(jù)流中設(shè)置RO屬性,并顯著提高PCIe鏈路性能。IDO排序?qū)傩栽谠S多情況下都具有類似的優(yōu)勢,大多數(shù) PCIe 實(shí)現(xiàn)都可以將其應(yīng)用于其傳輸?shù)拿總€(gè)數(shù)據(jù)包。
具有IDO集的數(shù)據(jù)包僅被允許傳輸具有不同請(qǐng)求者 ID 的先前事務(wù),這意味著數(shù)據(jù)包來自 PCIe 鏈路上的不同邏輯代理。大多數(shù)端點(diǎn)實(shí)現(xiàn)(單功能和多功能)都對(duì)與往返于其他 PCIe 端點(diǎn)的流量相關(guān)的數(shù)據(jù)排序漠不關(guān)心,因?yàn)樗鼈兺ǔV慌cRC通信。同樣,大多數(shù)RC通常不會(huì)在多個(gè)端點(diǎn)之間混合相同的流量流,因此在這兩種情況下,都沒有與其他設(shè)備的請(qǐng)求者 ID 相關(guān)的排序問題。與此類似,大多數(shù)多功能端點(diǎn)對(duì)功能之間的數(shù)據(jù)排序也不關(guān)心,因此也不必?fù)?dān)心自己的請(qǐng)求者ID之間的排序。因此,大多數(shù)實(shí)施已經(jīng)可以為他們發(fā)起的所有事務(wù)設(shè)置IDO。
2.增加應(yīng)用程序接口
除了上文討論的因素外,當(dāng)數(shù)據(jù)包小于接口寬度時(shí),利用多個(gè)較窄的應(yīng)用程序接口可顯著提高整體性能。圖 2 顯示了新思科技 PCI Express 6.0 控制器IP上64GT/s Flit模式下在發(fā)送連續(xù)的 Posted TLP流方面的傳輸鏈路利用率。對(duì)于更大的數(shù)據(jù)路徑寬度,顯然需要更大的數(shù)據(jù)包來通過單個(gè)應(yīng)用程序接口保持完全的鏈路利用率,1024 位接口需要 128 字節(jié)的有效負(fù)載。
表 5:顯示雙半速應(yīng)用程序接口通過對(duì)有效載荷數(shù)據(jù)使用松弛排序成功
SoC 設(shè)計(jì)人員可以在其出站數(shù)據(jù)流中設(shè)置RO屬性,并顯著提高PCIe鏈路性能。IDO排序?qū)傩栽谠S多情況下都具有類似的優(yōu)勢,大多數(shù) PCIe 實(shí)現(xiàn)都可以將其應(yīng)用于其傳輸?shù)拿總€(gè)數(shù)據(jù)包。
具有IDO集的數(shù)據(jù)包僅被允許傳輸具有不同請(qǐng)求者 ID 的先前事務(wù),這意味著數(shù)據(jù)包來自 PCIe 鏈路上的不同邏輯代理。大多數(shù)端點(diǎn)實(shí)現(xiàn)(單功能和多功能)都對(duì)與往返于其他 PCIe 端點(diǎn)的流量相關(guān)的數(shù)據(jù)排序漠不關(guān)心,因?yàn)樗鼈兺ǔV慌cRC通信。同樣,大多數(shù)RC通常不會(huì)在多個(gè)端點(diǎn)之間混合相同的流量流,因此在這兩種情況下,都沒有與其他設(shè)備的請(qǐng)求者 ID 相關(guān)的排序問題。與此類似,大多數(shù)多功能端點(diǎn)對(duì)功能之間的數(shù)據(jù)排序也不關(guān)心,因此也不必?fù)?dān)心自己的請(qǐng)求者ID之間的排序。因此,大多數(shù)實(shí)施已經(jīng)可以為他們發(fā)起的所有事務(wù)設(shè)置IDO。
2.增加應(yīng)用程序接口
除了上文討論的因素外,當(dāng)數(shù)據(jù)包小于接口寬度時(shí),利用多個(gè)較窄的應(yīng)用程序接口可顯著提高整體性能。圖 2 顯示了新思科技 PCI Express 6.0 控制器IP上64GT/s Flit模式下在發(fā)送連續(xù)的 Posted TLP流方面的傳輸鏈路利用率。對(duì)于更大的數(shù)據(jù)路徑寬度,顯然需要更大的數(shù)據(jù)包來通過單個(gè)應(yīng)用程序接口保持完全的鏈路利用率,1024 位接口需要 128 字節(jié)的有效負(fù)載。
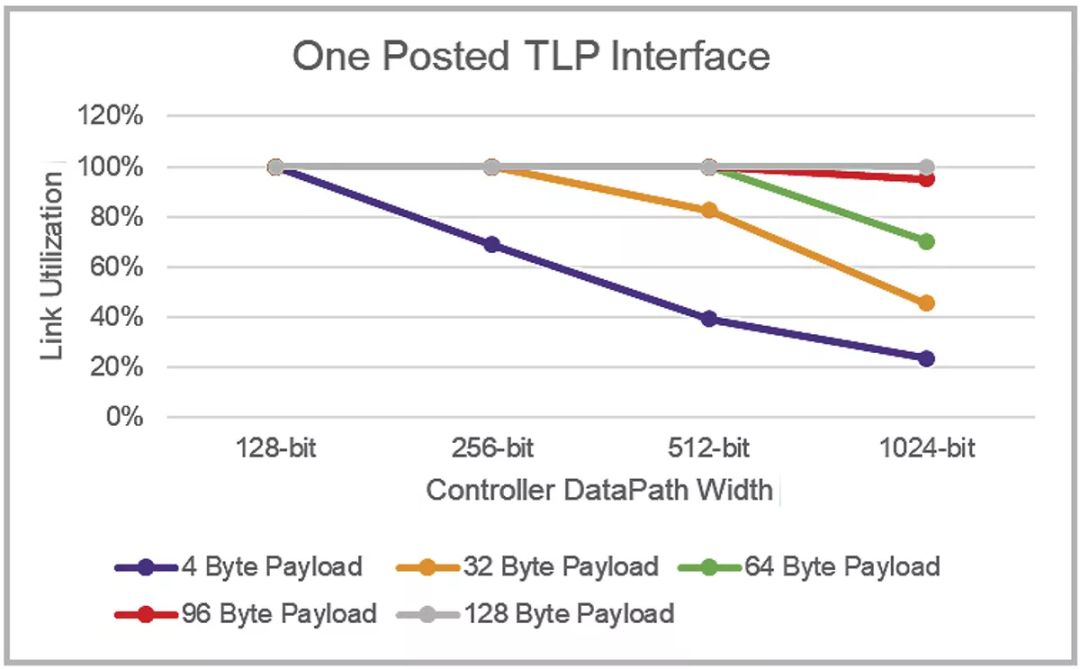 圖 2:在 64GT/s FLIT 模式下,利用單個(gè)應(yīng)用程序接口進(jìn)行傳輸?shù)母鞣N有效荷載大小和數(shù)據(jù)路徑寬度的鏈路利用率
3.解決小數(shù)據(jù)包效率低下
相反,當(dāng)新思科技控制器配置為兩個(gè)應(yīng)用接口并運(yùn)行相同的流量模式時(shí),就會(huì)有明顯的改進(jìn),現(xiàn)在64字節(jié)的有效負(fù)載即使在 1024 位數(shù)據(jù)路徑中也能產(chǎn)生完全的鏈路利用率,如圖 3 所示。
圖 3:在 64GT/s FLIT 模式下,通過兩個(gè)應(yīng)用接口配置進(jìn)行傳輸?shù)母鞣N有效載荷大小和數(shù)據(jù)路徑寬度的鏈路利用率
雖然大多數(shù)設(shè)備幾乎無法控制其流量模式,但小數(shù)據(jù)包可以實(shí)現(xiàn)更少帶寬。新思科技 CoreConsultant 使用最大有效負(fù)載大小和往返時(shí)間 (RTT) 等參數(shù)來配置 PCIe 6.0 控制器中的緩沖區(qū)大小、突出 PCIe 標(biāo)簽數(shù)量和其他關(guān)鍵參數(shù)。
圖4和圖5顯示了從新思科技的 64GT/s x4 控制器的仿真中獲得的數(shù)據(jù)。該控制器配置為 512 字節(jié)最大有效載荷大小和 1000nS RTT 掃描,覆蓋一系列有效載荷大小和 RTT 值。如果在同一范圍內(nèi)重復(fù)相同的掃描,但任意一個(gè)參數(shù)降低,則當(dāng)掃描通過優(yōu)化范圍后,性能會(huì)降低。
圖 2:在 64GT/s FLIT 模式下,利用單個(gè)應(yīng)用程序接口進(jìn)行傳輸?shù)母鞣N有效荷載大小和數(shù)據(jù)路徑寬度的鏈路利用率
3.解決小數(shù)據(jù)包效率低下
相反,當(dāng)新思科技控制器配置為兩個(gè)應(yīng)用接口并運(yùn)行相同的流量模式時(shí),就會(huì)有明顯的改進(jìn),現(xiàn)在64字節(jié)的有效負(fù)載即使在 1024 位數(shù)據(jù)路徑中也能產(chǎn)生完全的鏈路利用率,如圖 3 所示。
圖 3:在 64GT/s FLIT 模式下,通過兩個(gè)應(yīng)用接口配置進(jìn)行傳輸?shù)母鞣N有效載荷大小和數(shù)據(jù)路徑寬度的鏈路利用率
雖然大多數(shù)設(shè)備幾乎無法控制其流量模式,但小數(shù)據(jù)包可以實(shí)現(xiàn)更少帶寬。新思科技 CoreConsultant 使用最大有效負(fù)載大小和往返時(shí)間 (RTT) 等參數(shù)來配置 PCIe 6.0 控制器中的緩沖區(qū)大小、突出 PCIe 標(biāo)簽數(shù)量和其他關(guān)鍵參數(shù)。
圖4和圖5顯示了從新思科技的 64GT/s x4 控制器的仿真中獲得的數(shù)據(jù)。該控制器配置為 512 字節(jié)最大有效載荷大小和 1000nS RTT 掃描,覆蓋一系列有效載荷大小和 RTT 值。如果在同一范圍內(nèi)重復(fù)相同的掃描,但任意一個(gè)參數(shù)降低,則當(dāng)掃描通過優(yōu)化范圍后,性能會(huì)降低。
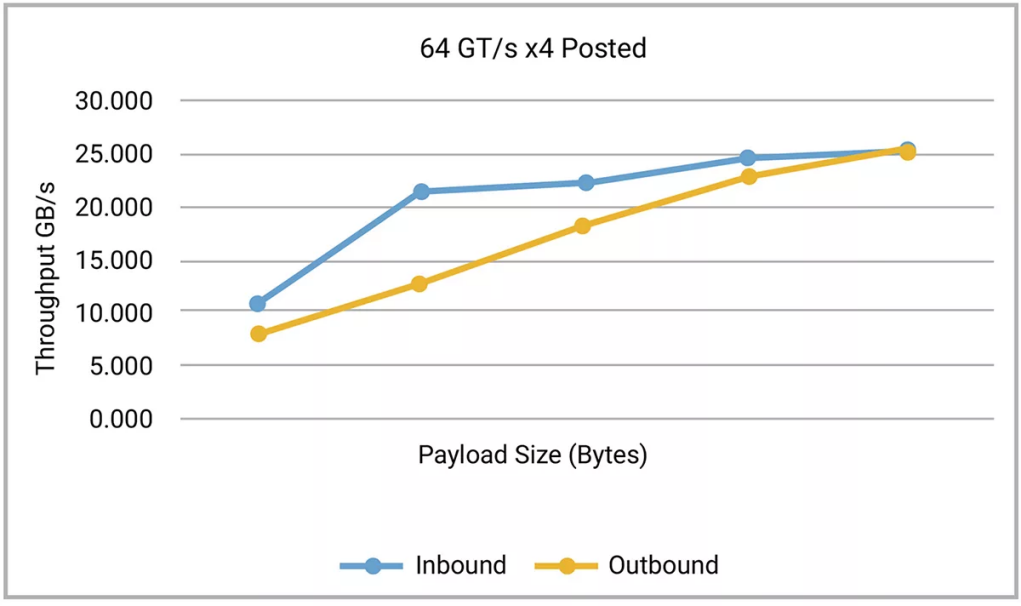 圖 4:小尺寸 Posted 數(shù)據(jù)包效率低下
圖 4:小尺寸 Posted 數(shù)據(jù)包效率低下
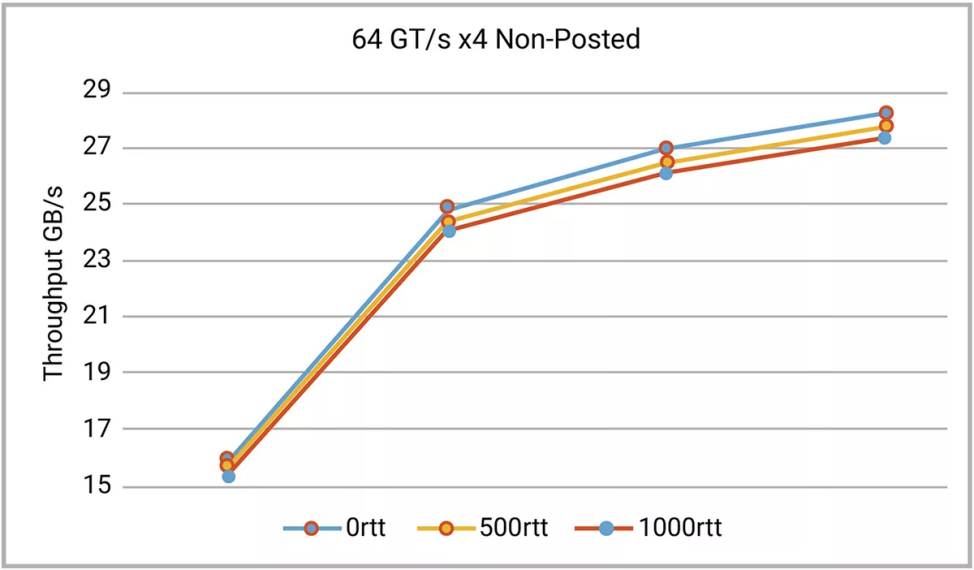 圖 5:小尺寸Non-Posted數(shù)據(jù)包效率低下,在一系列往返時(shí)間范圍內(nèi)掃描
總結(jié)
實(shí)施 64GT/s PCIe 接口的 SoC 設(shè)計(jì)人員應(yīng)確保其支持松弛排序?qū)傩裕从行лd荷而非相關(guān)控制上的RO,以及所有數(shù)據(jù)包上的IDO,除非應(yīng)用程序有異常要求。這是在整個(gè) 64GT/s 生態(tài)系統(tǒng)中實(shí)現(xiàn)高性能的關(guān)鍵部分。
為x4和更寬鏈路實(shí)施64GT/s PCIe的設(shè)計(jì)人員需要注意每個(gè)時(shí)鐘周期的多個(gè)數(shù)據(jù)包,并應(yīng)根據(jù)其典型流量大小考慮多個(gè)應(yīng)用接口。
所有64GT/s實(shí)施者都應(yīng)為1GHz(或更快)的設(shè)計(jì)實(shí)現(xiàn)做好準(zhǔn)備,并且應(yīng)確保通過硅前性能模擬檢查其假設(shè)。
對(duì)于上述這些優(yōu)化設(shè)計(jì)辦法,新思科技提供完整的PCIe 6.0解決方案(包括控制器、PHY 和 VIP)。這些解決方案支持松弛排序?qū)傩浴AM-4 信號(hào)、FLIT 模式、L0p 電源、高達(dá) 1024 位的架構(gòu)以及多個(gè)應(yīng)用程序接口選項(xiàng),有助于更輕松地過渡到64GT/s PCIe設(shè)計(jì)。
圖 5:小尺寸Non-Posted數(shù)據(jù)包效率低下,在一系列往返時(shí)間范圍內(nèi)掃描
總結(jié)
實(shí)施 64GT/s PCIe 接口的 SoC 設(shè)計(jì)人員應(yīng)確保其支持松弛排序?qū)傩裕从行лd荷而非相關(guān)控制上的RO,以及所有數(shù)據(jù)包上的IDO,除非應(yīng)用程序有異常要求。這是在整個(gè) 64GT/s 生態(tài)系統(tǒng)中實(shí)現(xiàn)高性能的關(guān)鍵部分。
為x4和更寬鏈路實(shí)施64GT/s PCIe的設(shè)計(jì)人員需要注意每個(gè)時(shí)鐘周期的多個(gè)數(shù)據(jù)包,并應(yīng)根據(jù)其典型流量大小考慮多個(gè)應(yīng)用接口。
所有64GT/s實(shí)施者都應(yīng)為1GHz(或更快)的設(shè)計(jì)實(shí)現(xiàn)做好準(zhǔn)備,并且應(yīng)確保通過硅前性能模擬檢查其假設(shè)。
對(duì)于上述這些優(yōu)化設(shè)計(jì)辦法,新思科技提供完整的PCIe 6.0解決方案(包括控制器、PHY 和 VIP)。這些解決方案支持松弛排序?qū)傩浴AM-4 信號(hào)、FLIT 模式、L0p 電源、高達(dá) 1024 位的架構(gòu)以及多個(gè)應(yīng)用程序接口選項(xiàng),有助于更輕松地過渡到64GT/s PCIe設(shè)計(jì)。
立即掃碼了解更多PCIe 6.0 信息


 ? ?
? ?
原文標(biāo)題:如何破解PCIe 6.0帶來的芯片設(shè)計(jì)新挑戰(zhàn)?
文章出處:【微信公眾號(hào):新思科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
新思科技
+關(guān)注
關(guān)注
5文章
796瀏覽量
50334
原文標(biāo)題:如何破解PCIe 6.0帶來的芯片設(shè)計(jì)新挑戰(zhàn)?
文章出處:【微信號(hào):Synopsys_CN,微信公眾號(hào):新思科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
加密芯片的一種破解方法和對(duì)應(yīng)加密方案改進(jìn)設(shè)計(jì)
使用芯片ID和隨機(jī)數(shù),結(jié)合邏輯加密芯片的加密方案,如果設(shè)計(jì)不合理,貌似安全可靠的加密方案,在實(shí)際使用是可能會(huì)被輕易破解。本文通過實(shí)例詳細(xì)分析了這種加密方案的漏洞和破解方法,提出了對(duì)加密
發(fā)表于 12-23 16:36
?0次下載
PCIe的最新發(fā)展趨勢
1. PCIe 5.0和6.0的推出 PCIe 5.0和6.0是最新的PCIe標(biāo)準(zhǔn),它們提供了更高的數(shù)據(jù)傳輸速率。
PCIe光傳輸?shù)膬?yōu)勢與挑戰(zhàn)
PCIe向光傳輸接口的轉(zhuǎn)變,預(yù)示著低延遲傳輸將取得新的突破。作為PCI標(biāo)準(zhǔn)組織(PCI-SIG)的關(guān)鍵成員,新思科技不僅深度參與其中,并積極協(xié)助制定新的標(biāo)準(zhǔn)。外設(shè)組件高速互連(PCIe)標(biāo)準(zhǔn)正在經(jīng)歷變革,這將對(duì)芯片設(shè)計(jì)流程產(chǎn)生深
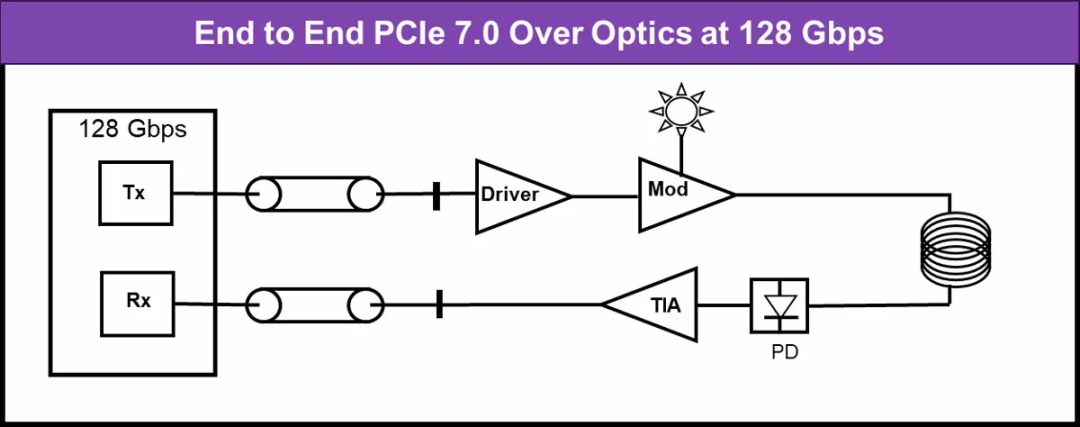

PCIe插槽竟然能玩出花樣?多個(gè)最新PCIe擴(kuò)展硬盤方式!#PCIe擴(kuò)展 #PCIe #硬盤盒
硬盤PCIe
ICY DOCK硬盤盒
發(fā)布于 :2024年07月11日 17:21:28
如何簡化PCIe 6.0交換機(jī)的設(shè)計(jì)
由于全球數(shù)據(jù)流量呈指數(shù)級(jí)增長,PCIe 6.0 交換機(jī)的市場需求也出現(xiàn)了激增。PCIe 6.0 交換機(jī)在高性能計(jì)算(HPC)系統(tǒng)(尤其是數(shù)據(jù)中心)中為需要大帶寬和超低延遲的應(yīng)用提供了重
FPGA的PCIE接口應(yīng)用需要注意哪些問題
FPGA上的PCIe接口應(yīng)用是一個(gè)復(fù)雜的任務(wù),需要考慮多個(gè)方面的問題以確保系統(tǒng)的穩(wěn)定性和性能。以下是在FPGA的PCIe接口應(yīng)用中需要注意的關(guān)鍵問題:
硬件資源和內(nèi)部架構(gòu) :
FPGA的型號(hào)和尺寸
發(fā)表于 05-27 16:17
PCIe 7.0規(guī)范何時(shí)最終確定?
PCIe 7.0 規(guī)范的目標(biāo)是將 PCIe 6.0 規(guī)范(64 GT/s)的數(shù)據(jù)速率提高一倍,達(dá)到 128 GT/s。
PCIe交換芯片的簡單介紹
PCIe交換芯片是用于實(shí)現(xiàn)高速、低延遲的設(shè)備互聯(lián)的關(guān)鍵組件。它們在現(xiàn)代計(jì)算機(jī)系統(tǒng),尤其是高性能服務(wù)器、數(shù)據(jù)中心、存儲(chǔ)解決方案和高速通信系統(tǒng)中扮演著重要角色。
PCIe交換芯片的作用、選型和價(jià)格
PCIe(Peripheral Component Interconnect Express)交換芯片是高速、低延遲的互連技術(shù),用于連接計(jì)算機(jī)內(nèi)部的各種硬件設(shè)備,如顯卡、網(wǎng)絡(luò)卡、存儲(chǔ)設(shè)備等。
pcie交換芯片的發(fā)展前景
PCIe交換芯片的發(fā)展前景看起來相當(dāng)積極,這主要得益于大數(shù)據(jù)、物聯(lián)網(wǎng)、人工智能等信息技術(shù)的快速發(fā)展以及傳統(tǒng)產(chǎn)業(yè)數(shù)字化的轉(zhuǎn)型。這些趨勢都推動(dòng)了PCIe交換芯片的需求不斷增加,進(jìn)而為其
PCIE交換芯片是什么
PCIE交換芯片,全稱為Peripheral Component Interconnect Express交換芯片,是一種高速串行總線標(biāo)準(zhǔn)的核心組件。在現(xiàn)代計(jì)算機(jī)架構(gòu)中,它扮演了連接各種內(nèi)部硬件設(shè)備的橋梁角色,特別是在主板、顯卡
FMS2023固態(tài)存儲(chǔ)技術(shù)前沿:PCIe 5.0、PCIe 6.0和大容量SSD的挑戰(zhàn)與發(fā)展
2023FMS已經(jīng)結(jié)束,但帶給行業(yè)的技術(shù)思考還在持續(xù)。得瑞領(lǐng)新將繼續(xù)與行業(yè)合作伙伴緊密配合,不斷推動(dòng)固態(tài)存儲(chǔ)技術(shù)的進(jìn)步,為客戶提供更優(yōu)質(zhì)、更高效的數(shù)據(jù)存儲(chǔ)體驗(yàn),助力各行各業(yè)應(yīng)對(duì)數(shù)字化時(shí)代帶來的挑戰(zhàn)與機(jī)遇。
下一代PCIe5.0 /6.0技術(shù)熱潮趨勢與測試挑戰(zhàn)
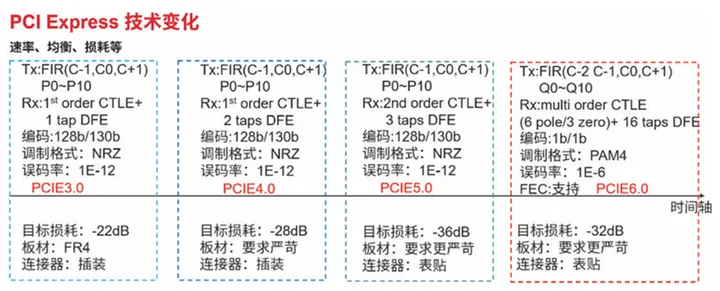
迫切。 一、PCIe 5.0 /6.0技術(shù)升級(jí) 1)信號(hào)速率方面 從PCIe 3.0、4.0、5.0 到 6.0,數(shù)據(jù)速率翻倍遞增,6.0支
PCIe 6.0元年,AI與HPC迎來新速度
電子發(fā)燒友網(wǎng)報(bào)道(文/周凱揚(yáng))2022年1月,PCI-SIG發(fā)布了PCIe 6.0規(guī)范,正式拉開了接口帶寬大幅升級(jí)的序幕。然而,在規(guī)范公布的兩年時(shí)間里,也已經(jīng)更新了6.0.1和6.1版本,PCIe
為什么PCIe向前邁出了一大步?
硅 IP 提供商和合約芯片設(shè)計(jì)商 Alphawave 本月與測試和驗(yàn)證設(shè)備制造商是德科技合作,展示了其 PCIe 6.0 控制器和物理接口與是德科技測試設(shè)備的互操作性






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論