

主要內(nèi)容: 論文研究了機(jī)器人和自動駕駛車輛應(yīng)用中的基于神經(jīng)網(wǎng)絡(luò)的相機(jī)重定位問題,其解決方案是一種基于CNN的算法直接從單個圖像預(yù)測相機(jī)姿態(tài)(3D平移和3D旋轉(zhuǎn)),同時網(wǎng)絡(luò)提供姿勢的不確定性估計,姿態(tài)和不確定性與單個損失函數(shù)一起訓(xùn)練,并在實際測試時與EKF融合,為此提出了一種新的全卷積架構(gòu),名為CoordiNet,其中嵌入了一些場景幾何結(jié)構(gòu)。
Contributions:
提出了一種聯(lián)合訓(xùn)練姿態(tài)估計和不確定性的方法,其具有可靠的不確定性估計和改進(jìn)的訓(xùn)練穩(wěn)定性。
提出一種新的全卷積架構(gòu),它集成了幾何線索,并在所有公共基準(zhǔn)上以較大的優(yōu)勢優(yōu)于單目最先進(jìn)的方法。
在幾個大規(guī)模數(shù)據(jù)集上對幾種深度姿態(tài)回歸器進(jìn)行了廣泛的評估,表明論文提出的CoordiNet可以實時(在RTX2080嵌入式GPU上實現(xiàn)ROS的18Hz)用于車輛定位。
論文表明在簡單的EKF中結(jié)合可靠的不確定性的姿態(tài)預(yù)測顯示出了平滑的軌跡并去除了異常值。
網(wǎng)絡(luò)架構(gòu):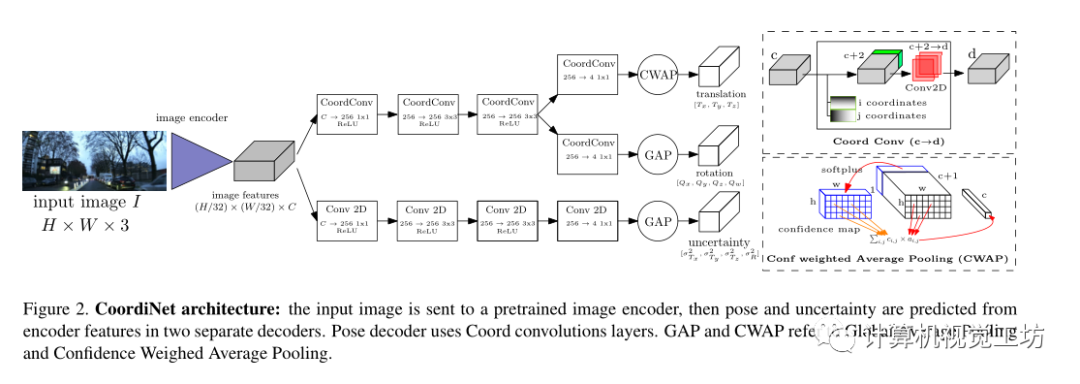
用Coord卷積代替標(biāo)準(zhǔn)2D卷積,Coord卷積是Rosanne Liu等人在NIPS 2018年的論文An intriguing failing of convolutional neural networks and the coordconv solution中提出,Coord卷積在應(yīng)用卷積之前將包含硬編碼像素坐標(biāo)的2個附加通道連接到輸入張量,如下圖所示: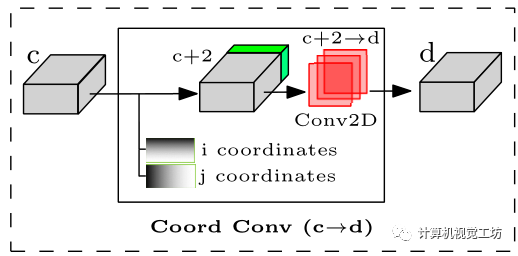
使用置信加權(quán)平均池(CWAP)而不是全局平均池(GAP),這是受到CWAP在其他應(yīng)用中成功的啟發(fā),為了將特征圖轉(zhuǎn)換為單個標(biāo)量,GAP只需計算特征圖的平均值,CWAP使用附加信道作為置信圖來計算加權(quán)平均值,為每個空間位置提供權(quán)重,這些權(quán)重是根據(jù)先前的層激活來預(yù)測的,因此可以將此計算與低成本的自注意力機(jī)制進(jìn)行比較。
置信圖的激活掩碼示例如下圖所示。觀察到在劍橋地標(biāo)的小場景中,無論攝像機(jī)的姿勢如何,池化總是突出顯示同一個物體;在較大的場景中,即所有場景中都沒有可見的公共對象,在這種情況下池化會屏蔽出現(xiàn)動態(tài)對象的區(qū)域。
模型的整個架構(gòu)如圖2所示,使用兩個解碼器頭從圖像編碼器獲得的潛在表示中預(yù)測姿態(tài)和不確定性,架構(gòu)是全卷積的,即解碼器的參數(shù)數(shù)量不取決于輸入圖像的大小,與使用完全連接層來回歸最終姿態(tài)的標(biāo)準(zhǔn)姿態(tài)回歸器相比,論文的解碼器包含的參數(shù)少了一個數(shù)量級。
姿態(tài)和異方差不確定性的聯(lián)合學(xué)習(xí):



結(jié)合不確定性估計的定位: 將回歸姿態(tài)與學(xué)習(xí)到的不確定性融合在一起,以過濾出誤差較大部分并獲得平滑且時間一致的軌跡。使用EKF,通過僅向濾波器提供由網(wǎng)絡(luò)給出的絕對姿態(tài)測量來完成積分,將簡化的對角協(xié)方差矩陣∑附加到每個測量值,定義如下:
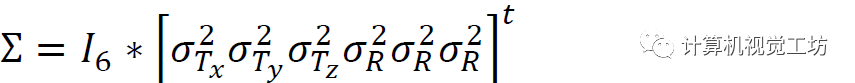
不確定性校準(zhǔn):在評估其方法時觀察到學(xué)習(xí)的不確定性往往低估了實際誤差,這是由過擬合造成的,在訓(xùn)練過程結(jié)束時,模型在訓(xùn)練圖像上表現(xiàn)得非常好,不確定性層學(xué)習(xí)到了不代表實際誤差的誤差分布,為了減輕這種影響提出了一個兩步訓(xùn)練程序:將可用的訓(xùn)練數(shù)據(jù)分成訓(xùn)練集和驗證/校準(zhǔn)集。首先使用訓(xùn)練集訓(xùn)練CoordiNet,然后在凍結(jié)所有其他層的同時微調(diào)校準(zhǔn)集上的不確定性層,這使得能夠校準(zhǔn)代表測試條件的示例的不確定性。
實驗: 在多個場景評估CoordiNet。 首先比較了公共數(shù)據(jù)集上的相關(guān)方法;還研究CoordiNet的性能如何隨著數(shù)據(jù)集的大小而變化,這些數(shù)據(jù)集比公共數(shù)據(jù)集大幾個數(shù)量級;還證明了一旦CoordiNet與EKF融合,它就可以被認(rèn)為是在實際任務(wù)中可靠定位的一個很好的選擇。 在Oxford Robotcar數(shù)據(jù)集上實驗結(jié)果: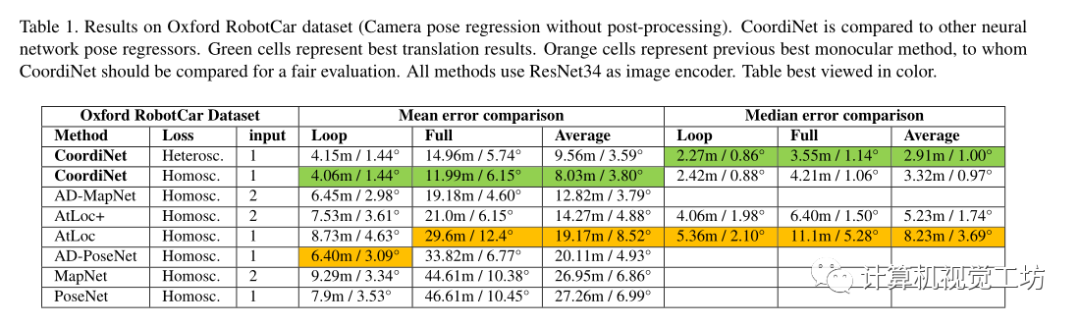

Cambrige Landmarks數(shù)據(jù)集上實驗結(jié)果: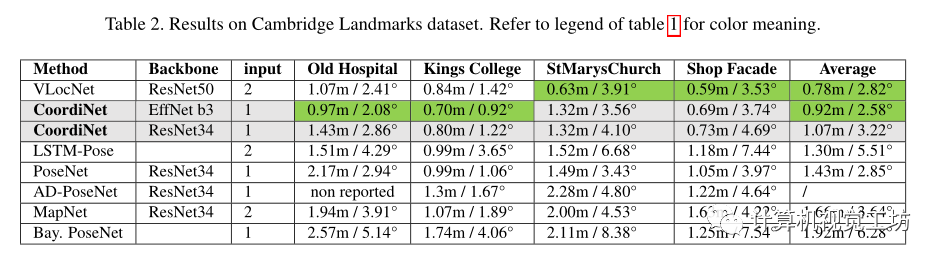
接下來探討CoordiNet在訓(xùn)練集的數(shù)據(jù)量與公共基準(zhǔn)相比高出一個數(shù)量級的情況下,其表現(xiàn)如何,使用dashcam相機(jī)在巴黎和上海地區(qū)收集了數(shù)據(jù)
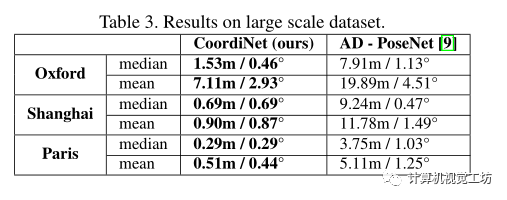
CoordiNet在大面積上優(yōu)于先前的SOTA姿態(tài)回歸器一個數(shù)量級,并觀察到使用更大的訓(xùn)練集后在測試數(shù)據(jù)上達(dá)到亞米精度。將Oxford訓(xùn)練集從2個序列擴(kuò)大到15個序列,可以在同一測試序列上將平均誤差從9.56m降低到1.94m,中值誤差從3.55m降低到1.25m。得出結(jié)論,通過收集大型圖像數(shù)據(jù)集并使用CoordiNet作為姿態(tài)回歸器,能夠為選定的實際應(yīng)用實現(xiàn)足夠可靠的定位精度。 接下來研究了將姿態(tài)和不確定性被融合到EKF中的實驗: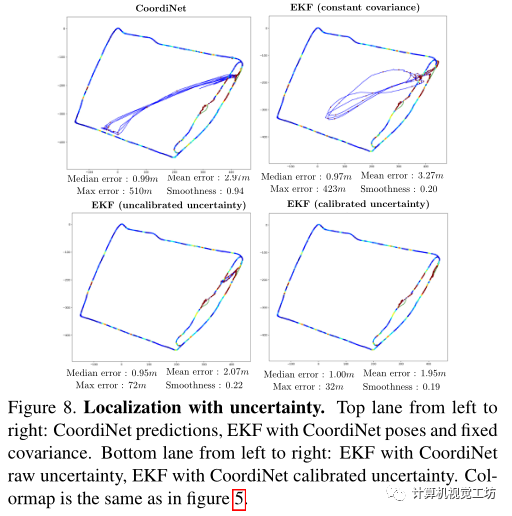

加上EKF后最終軌跡變得更平滑,運(yùn)行中的最大誤差也減少了。 通過剔除異常值,與原始姿態(tài)相比,EKF減少了大部分時間的平均誤差。結(jié)果還表明為了獲得準(zhǔn)確度和平滑度之間的最佳權(quán)衡,估計好的協(xié)方差值至關(guān)重要:與固定協(xié)方差值和基線版本相比,具有校準(zhǔn)協(xié)方差的Coordinet+EKF在本實驗中表現(xiàn)最好。
消融研究: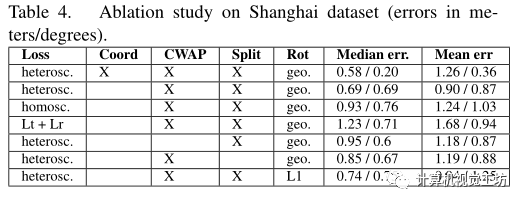
總結(jié): 提出了CoordiNet,一種新的深度神經(jīng)網(wǎng)絡(luò)方法,結(jié)合不確定性估計將直接相機(jī)姿態(tài)回歸模型的精度進(jìn)一步提高。此外由于不確定性量化和大型訓(xùn)練集,證明了其方法可以集成在實時車輛定位系統(tǒng)中以便在大型城市環(huán)境中進(jìn)行準(zhǔn)確的姿態(tài)估計。
審核編輯:劉清
-
解碼器
+關(guān)注
關(guān)注
9文章
1163瀏覽量
41709 -
機(jī)器人
+關(guān)注
關(guān)注
213文章
29506瀏覽量
211622 -
GAP
+關(guān)注
關(guān)注
0文章
15瀏覽量
8454 -
自動駕駛
+關(guān)注
關(guān)注
788文章
14209瀏覽量
169601 -
ROS
+關(guān)注
關(guān)注
1文章
285瀏覽量
17566
原文標(biāo)題:WACV 2022|CoordiNet:將不確定性感知和姿態(tài)回歸結(jié)合用于自動駕駛車輛定位
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
去嵌入和不確定性是否使用了正確的設(shè)置
E8364C PNA的不確定性和跟蹤是什么?
是否可以使用全雙端口校準(zhǔn)中的S11不確定性來覆蓋單端口校準(zhǔn)的不確定性?
N5531S TRFL不確定性
UWB定位可以用在自動駕駛嗎
基于RFID技術(shù)的供應(yīng)鏈管理項目存在哪些不確定性?
運(yùn)算放大器的開環(huán)電壓增益有哪些不確定性?
基于云模型可靠性數(shù)據(jù)不確定性評價
如何用不確定性解決模型問題
深部目標(biāo)姿態(tài)估計的不確定性量化研究
科技云報到:數(shù)字化轉(zhuǎn)型,從不確定性到確定性的關(guān)鍵路徑






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論