 細品AMD的3D緩存技術
細品AMD的3D緩存技術
今年PC行業的內卷還在持續,尤其AMD和Intel的技術與產品競爭仍處于膠著狀態。AMD這邊的Zen 4架構表現雖然未如預期,但這家公司的新年產品仍有不少亮點。
月初的CES上,AMD面向個人電腦發布的新款Ryzen 7000系列CPU中,繼續包含了采用3D V-Cache的型號,且相比去年多有強化。我們此前特別撰文談過3D V-Cache技術——簡而言之,這是一種增加處理器L3 cache的方案:將L3 cache單獨作為一片die(Extended L3 Die,以下簡稱L3D),以先進封裝的方式疊到原本的處理器die上方,大幅增加CPU的cache容量。
其實在去年的IEEE ISSCC上,AMD有進一步詳述3D V-Cache技術。這次我們也借著AMD的新品發布,來再度談談這項給CPU堆cache的技術。
這次堆了更多的L3 cache
處理器采用更大的、在垂直方向疊起來的L3 cache,在PC市場上,是AMD于游戲用戶的殺手锏——隔壁Intel沒有用這項技術。所以3D V-Cache現階段還真是AMD在市場上差異化競爭的組成部分。不過我們此前也特別撰文提到過,面向個人電腦市場的CPU,堆L3 cache的價值并沒有那么大:主要價值都在游戲上,對其他PC應用(比如生產力產經)甚至有負加成。
AMD本身也將這個系列的型號主要定位于游戲用戶,但這次發布的新品部分彌補了上代產品的不少短板。
 ?
?
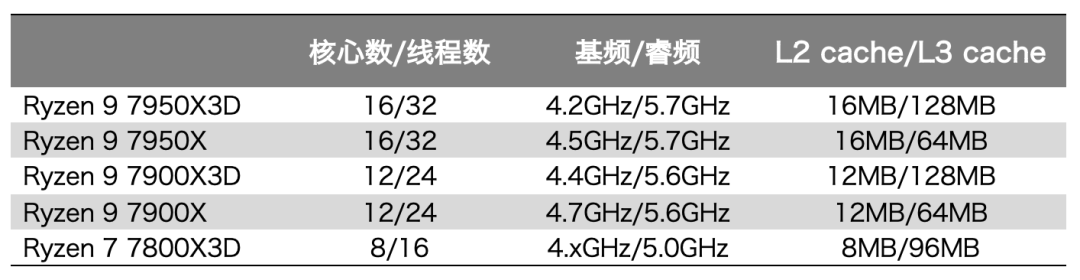
CES上AMD發布了3款采用3D V-Cache的處理器:Ryzen 9 7950X3D、7900X3D和Ryzen 7 7800X3D。初代采用3D V-Cache的處理器就只有一款;這次AMD顯然是在初代試水之后,更看好這項技術了。
其中最高配的Ryzen 9 7950X3D為16核心。由于3D堆疊能讓L3 cache增多64MB,所以7950X3D的L3 cache總容量為128MB。值得一提的是,7950X3D核心睿頻達到了5.7GHz,與原本沒有堆3D V-Cache的7950X一樣;只不過基頻相比7950X降低了300MHz。
這一點之所以重要是因為,上代的5800X3D睿頻只有4.5GHz——這就讓5800X3D,在除游戲之外的其他絕大部分負載中,性能弱于原版5800X。堆疊cache,還是要讓核心部分付出代價的。這次睿頻沒降,也就不至于讓更依賴核心峰值性能的負載受到太多不良影響——雖然基頻還是略有下降的。
與此同時7950X3D標定的TDP為120W,PPT(Package Power Tracking)162W。這兩個標稱值還低于原版7950X的170W/230W,可能是因為基頻下降、全核睿頻相對不帶L3D的7950X更低、以及新增cache die容許略高的運行溫度。有一點格外值得一提,7950X3D這個處理器16個核心,按照Zen 4架構是分成了兩個CCD(Core Complex Die)的——也就是兩片die,每片die有8個核心。
只有一片die是疊了L3D的:Lisa Su最早在發布會上展示的3D V-Cache處理器也是只在一片die上疊cache(上圖中左上的那片die),另一片仍然是普通的CCD die(右上那片die;下面較大的那片是I/O die)。沒有疊cache的CCD die上的核心才能用上最高頻率,而疊了3D V-Cache這邊的核心做不到全速運轉(或這片die的全核睿頻更受限制)。所以3D V-Cache依然對堆疊的那片L3D的處理器核心性能產生了少許影響。
基于這一點,AMD目前正在跟微軟合作進行Windows優化,AMD芯片組驅動能夠識別不同的游戲,選擇更傾向于堆疊了L3D的CCD,還是更傾向于沒有疊cache的CCD。
另外兩個型號7900X3D和7800X3D,分別是12核心+128MB L3 cache,以及8核心+96MB L3 cache。在7800這個型號上,AMD今年只推了帶L3D的7800X3D,而沒有出不帶L3D的版本,所以沒法做規格上的直接比較了。
再有就是上代5800X3D是無法對核心做超頻的,這代的三顆處理器開始支持自動超頻PBO,以及使用Curve Optimizer;只不過仍然無法直接進行超頻操作。  ?
?  ?
?
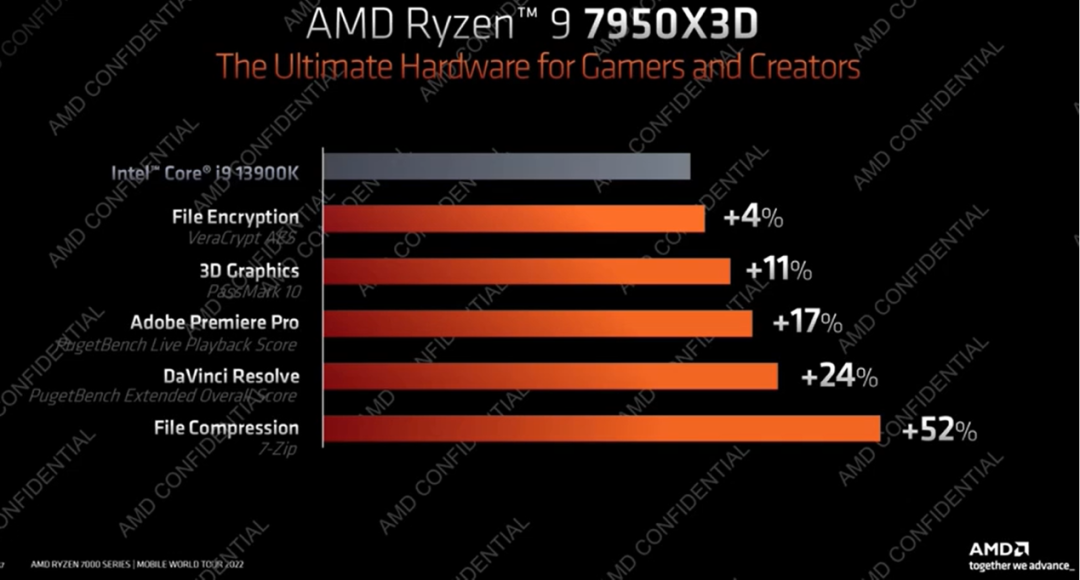
AMD宣稱,Ryzen 9 7950X3D相比于Intel酷睿i9-13900K,在游戲中的表現領先13-24%;部分生產力應用領先4-52%。不過從AMD此前給出第一方數據的可信度來說,這個數據還是僅供參考。而從此前5800X3D的游戲表現來看,這代處理器的1080p分辨率游戲表現應該的確會相當不錯——非常值得期待。
3D V-Cache技術更大的服務場景應該是面向服務器的Epyc處理器。去年AMD把3D V-Cache應用到了挺多Epyc處理器上,從16-64核處理器都有。8個CCD的Epyc處理器,如果每個都疊上L3D,則處理器總共能堆出768MB的L3 cache——這個數字以前還真是不可想象。
3D緩存是早有“預謀”的
AMD暫時還沒有公布這幾顆芯片的售價。從去年的情況來看,3D V-Cache版本會比原版貴一些——最終售價對于用戶來說,基本就是在更多的核心數和更大的cache容量之間做抉擇,看你更愿意為SRAM買單,還是為邏輯電路買單了——這還真得看用戶購買CPU的真實用途在哪兒了,因為增大L3 cache容量呈現出了顯著的邊際遞減效應:增加cache命中率帶來的那點紅利,很多時候無法抵消延遲增加造成的不良影響。
從去年IEEE的技術匯報來看,半導體制造工藝雖然還在進步,但器件微縮主要體現在邏輯電路方向上,SRAM bitcell尺寸的縮減速度急劇放緩,尤其從臺積電N5到N3工藝,SRAM單元面積微縮幅度是5%。而且很快要大規模量產的N3E工藝,SRAM單元面積還要增大。這其實是技術發展過程中的桎梏。
3D V-Cache是符合這樣的時代發展主旋律的,也就是把SRAM往垂直方向去堆。而且這也增加了產品SKU的靈活性,畢竟很多應用場景其實并不需要那么大的cache。AMD表示,在沒有增加橫向datapath距離的情況下就增加cache容量,保持動態低功耗和低延遲的同時,也縮減了封裝尺寸——節約的尺寸可以用來做其他事,比如說增加更多的核心。  ?
?
3D V-Cache處理器總體包含三個組成部分,CCD(上圖最下層)、L3D(上層中間部分)和結構支持die(兩側的die)。對AMD Zen架構處理器有了解的同學應該很清楚CCD是什么——現在的架構中,大體上8個核心構成一個CCD(如下圖),當然CCD內部本身也是有L3 cache的。比如說原版Ryzen 9 7950X,兩片CCD總共配有64MB L3 cache。 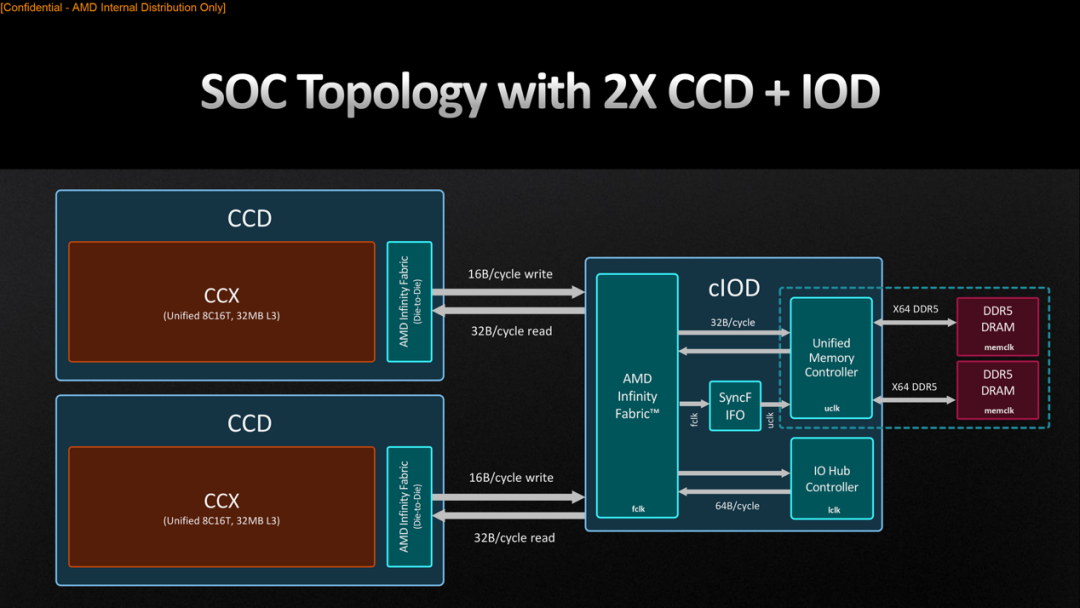 ?
?
不過AMD在ISSCC上說,往CCD上面堆L3D并不是臨時起意。對于3D V-Cache的支持,無論是架構上還是物理電路上,都是從此前Zen 3處理器設計之初就做好了準備的。也就是說從最初設計CCD、還沒有向市場推出3D V-Cache版本的處理器之時,CCD上面就預留了必要的邏輯電路以及TSV(硅通孔)信號pad。這就極大地節省了NRE成本、減少了掩膜組數量,簡化了整體的chiplet設計。
換句話說,Zen 3架構的CCD原生就支持L3D擴展,包括TSV柱。AMD表示這種預留會對面積造成大約4%的影響——也就是需要額外4%的面積。
往上疊加的L3D這片die,制造工藝和CCD是一樣的。Wikichip在分析文章中提到,L3D內部有13層銅層,和1層鋁層。L3D的確就是純粹的cache die。在Zen 3架構那一代(即Ryzen 5000系列,臺積電N7工藝),L3D總共64MB SRAM,面積41mm2。
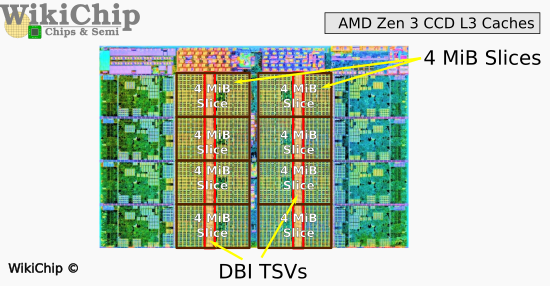
來源:Wikichip
L3D疊在上層,剛好覆蓋差不多一半的CCD;L3D僅位于CCD部分的L2/L3 cache區域上方——因為cache區域的功率密度相對更低,則 3D堆疊產生的散熱影響會相對更小一些。CCD上面的L3 cache設計為16-way set associative;總共8個切片,每片4MB。L3D也是這種設定。
所以L3D也是8個切片,每片包含8MB數據,和816KB的tags/LRU。上一代的5800X3D因此就有了總共96MB L3 cache。AMD提供的數據是,新增堆疊的L3 cache,只會有增多4個周期的延遲。
除了CCD和疊在上面的L3D之外,還有做結構支持的die——在L3D旁邊,也就是相對的位于下層CCD的處理器核心區域上方。這是一種物理結構上的輔助設計,主要是在鍵合(bonding)過程中;與此同時也作為CPU die的散熱通道:結構支持die需要在Z軸達成高度的匹配,畢竟最終封裝的散熱頂蓋也需要與die做到充分接觸。
還有機會再往上疊
AMD說L3D的設計是往高密度、低功耗的方向走的。實際在Zen 2走向Zen 3架構的時候,AMD就為處理器選擇了高密度SRAM bitcell(而非高電流單元)。如此一來,每個核心分配到的L3 cache切片容量就更大,同時保持die面積可控。
L3D則用了高密度的8T SRAM bitcell,有功耗方面的紅利。其他縮減功耗的特性還包括用更高Vt的器件、floating bitline,以及一些電源門控技術。
Zen 2到Zen 3架構變化過程中,每個CCX(core complex)的核心數翻番到8個,則核間通訊架構就需要重做。Zen 2時代,CCX內部的核心數還沒有這么多,所以采用crossbar型核間通訊。到了Zen 3,Wikichip在剖析文章里提到,由于核心數增多,所以核間通訊改用ring bus雙向環形總線。Zen 3每個CCD的L3 cache是32MB(不加L3D的情況下),分成8個切片(每核心4MB),也就是8 stops。
在新增L3D以后,每核心可分配到的L3 cache增大至12MB,仍然是雙向環形總線(64MB L3D,每個切片8MB——加上原本CCD上每個切片4MB,也就是每個stop 12MB)。
有關供電的詳情,由于篇幅原因不做贅述。有興趣的讀者可以去看一看Wikichip的分析。簡單來說,CCD有三種主要供電軌,RVdd——用于L3 cache logic;Vdd是為核心供電的;VddM針對L2和L3數據bitcell做門控供電。  ?
?
這里再談一下Hybrid Bonding混合鍵合。3D V-Cache的3D堆疊采用的是Hybrid Bonding方案,此前初代產品在做宣傳的時候,很多同學就應該已經知道了。這在高性能處理器上應該是Hybrid Bonding的首個應用。這種混合鍵合能夠把兩片wafer或者兩片die鍵合到一起,而且是直接的銅到銅——電介質到電介質的互聯,而不用microbump。 
來源:GlobalFoundries
具體到臺積電的技術,用的SoIC工藝的F2B(face-to-back)鍵合。封裝時,CCD本身面朝下,以C4介面面向substrate;CCD的背面通過薄化(thinned down)露出TSV;然后L3D die同樣面朝下,混合鍵合到CCD上;最后把結構支持die鍵合上去。就微觀層面來看,L3D的M13金屬層通過BPV(Bond Pad Via)連接到BPM(Bond Pad Metal)上。
AMD說,3D V-Cache應用的SoIC封裝能夠做到最小9μm的TSV間距。這種較小的間距,本來也就是Hybrid Bonding的優勢所在,此前電子工程專輯談先進封裝工藝的文章詳細闡述過。不過TechInsights的逆向工程顯示,Zen 3架構的這代產品TSV間距是17μm。理論上最新發布且采用了新制造工藝的Ryzen 7000系列3D V-Cache新品應該進一步讓這個間距下降了。
Hybrid Bonding本身包括低電阻之類的優勢就不多談了,畢竟也還算知名;顯著更小的互聯間距才是其相比其他方案的真正優勢。
最后值得一說的是,臺積電的F2B SoIC這套方案是完全可重復操作的。也就是說L3D本身的背面可以再做一次這樣的鍵合。那么理論上就能再往上堆L3D了。而且Wikichip認為,操作上所需的改動并不大——只不過需要供電方面的一些調整,供電到疊層上方,以及一些Die-to-Die信號的額外邏輯電路。
還是那句話,雖說就個人電腦來說,再增大L3 cache對于絕大部分非游戲類應用而言并沒有太大價值,甚至產生副作用;但當應用方向明確為存儲敏感型的,那么大cache就會非常有價值。
想必新發布的三款采用了3D V-Cache的處理器,能夠在新一年的游戲應用上大殺四方了。等產品發布時,可以看看它們與酷睿i9-13900K的對比結果,畢竟這代酷睿處理器也大幅增加了cache容量,而且核心數和頻率都提高了。而且在游戲設定更高分辨率時,3D V-Cache的優勢可能逐漸消失。當然對Epyc客戶而言,關注點可能又不同了。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19265瀏覽量
229672 -
CCD
+關注
關注
32文章
880瀏覽量
142227 -
amd
+關注
關注
25文章
5466瀏覽量
134105 -
cpu
+關注
關注
68文章
10855瀏覽量
211606 -
cache技術
+關注
關注
0文章
41瀏覽量
1062
原文標題:當CPU三級緩存堆到768MB時:細品AMD的3D緩存
文章出處:【微信號:IC大家談,微信公眾號:IC大家談】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
技術資訊 | 2.5D 與 3D 封裝

3D封裝玻璃通孔技術的開發

UV光固化技術在3D打印中的應用
3D掃描技術醫療領域創新實踐,積木易搭3D掃描儀Mole助力定制個性化手臂康復輔具
3D打印技術應用的未來
AMD官宣銳龍9000X3D系列發布計劃
物聯網行業中的模具定制方案_3D打印技術分享

裸眼3D筆記本電腦——先進的光場裸眼3D技術
蘇州吳中區多色PCB板元器件3D視覺檢測技術

潮流科技單品推薦——英倫科技裸眼3D智能數碼相框云相冊

VIVERSE 推行實時3D渲染: 探索Polygon Streaming技術力量與應用
AMD 3D V-Cache技術帶來更高密度和能效






 工商網監
工商網監
評論