") 基于預訓練語言模型的行業(yè)搜索的應用和研究
基于預訓練語言模型的行業(yè)搜索的應用和研究
導讀:本文將分享行業(yè)搜索的相關技術和應用,主要包括三大部分:
行業(yè)搜索的背景
相關技術研究
行業(yè)搜索應用
01
行業(yè)搜索的背景
1. 達摩院自然語言智能大圖
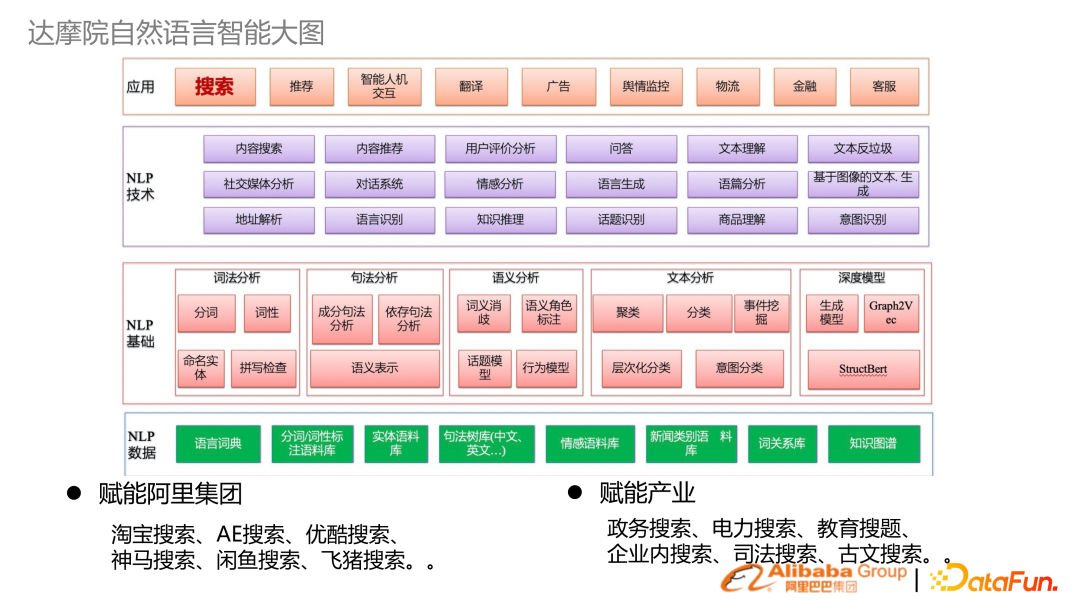
上圖是達摩院自然語言處理智能的技術框圖,從下到上包含:
NLP 數(shù)據、NLP 基礎的詞法、句法語義,分析的技術,以及上層 NLP 技術
行業(yè)應用:達摩院除了做基礎研究之外,還賦能阿里集團,以及結合阿里云去賦能行業(yè)產業(yè)。賦能的很多行業(yè)場景都是搜索。
2. 行業(yè)搜索本質
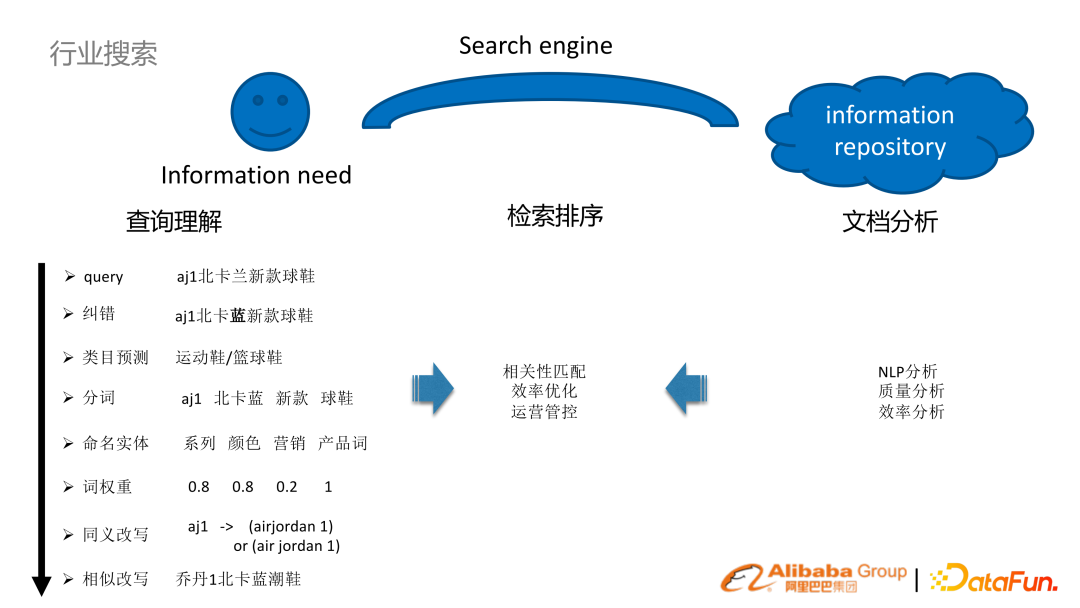
面向產業(yè)和消費互聯(lián)網的搜索本質都是一樣的:用戶有信息獲取需求,同時有信息資源庫,通過搜索引擎把兩者橋接起來。 以電商場景來舉例說明。比如用戶在電商里面搜索 aj1 北卡藍新款球鞋。為了更好地理解這樣一個用戶的 query,需要進行一系列任務:
查詢理解的分析:NLP 糾錯、分詞類目預測、實體識別詞權重、 query 改寫等技術
(離線)文檔分析:NLP分析,質量效率的分析
檢索排序:通過對 query 的分析以及文檔的分析,來結合搜索引擎本身一些檢索排序的機制,就能實現(xiàn)把兩者橋接的目標。
3. 行業(yè)搜索鏈路

如果按搜索的范式來分,一般分為 sparse retrieval 及 dense retrieval。
sparse retrieval:傳統(tǒng)的基于字或基于詞去建立倒排索引,同時基于此去構建很多查詢理解的一系列的能力,包括一些文本相關性排序等;
dense retrieval:隨著預訓練語言模型的興起,基于預訓練底座來實現(xiàn)單塔、雙塔模型,再結合向量引擎建立搜索機制。

一般將搜索做這樣一個鏈路性的劃分:召回、排序(粗排、精排、重排)。
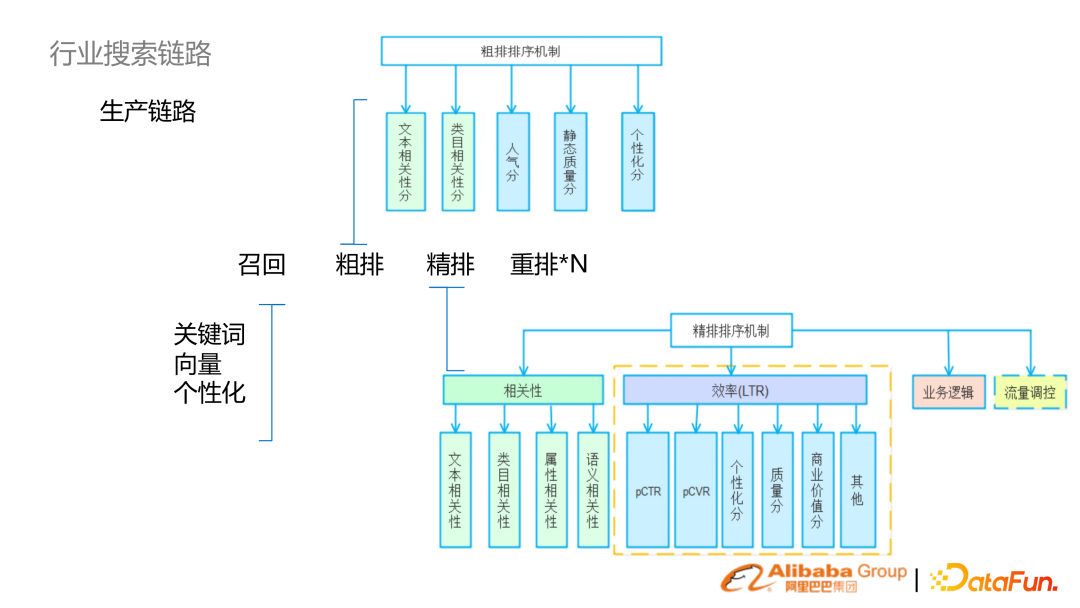
召回階段:
傳統(tǒng) sparse retrieval 的關鍵詞召回
dense retrieval 向量召回,個性化召回
粗排階段:使用文本相關性(靜態(tài))分數(shù)來做過濾
精排階段:相對復雜,會有相關性的模型,可能結合業(yè)務的效率模型(LTR)

從左到右,模型復雜度、效果精度變高。從右到左,處理 Doc 數(shù)變多。以淘寶電商為例,比如召回(幾十億),初排(幾十萬),到精排(幾百、上千),到重排(幾十)量級。 搜索生產鏈路是檢索效果跟工程效率 trade-off 的系統(tǒng)。隨著算力的增長,復雜模型開始往前置換。比如說精排的模型,現(xiàn)在慢慢會下沉到粗排、甚至召回這個階段。

搜索效果評估:
召回:recall 或無結果率
排序:相關性、轉化效率(貼近業(yè)務)
相關性:NDCG、MRR
轉化效率:點擊率、轉化率
4. 消費互聯(lián)網和產業(yè)互聯(lián)網的搜索
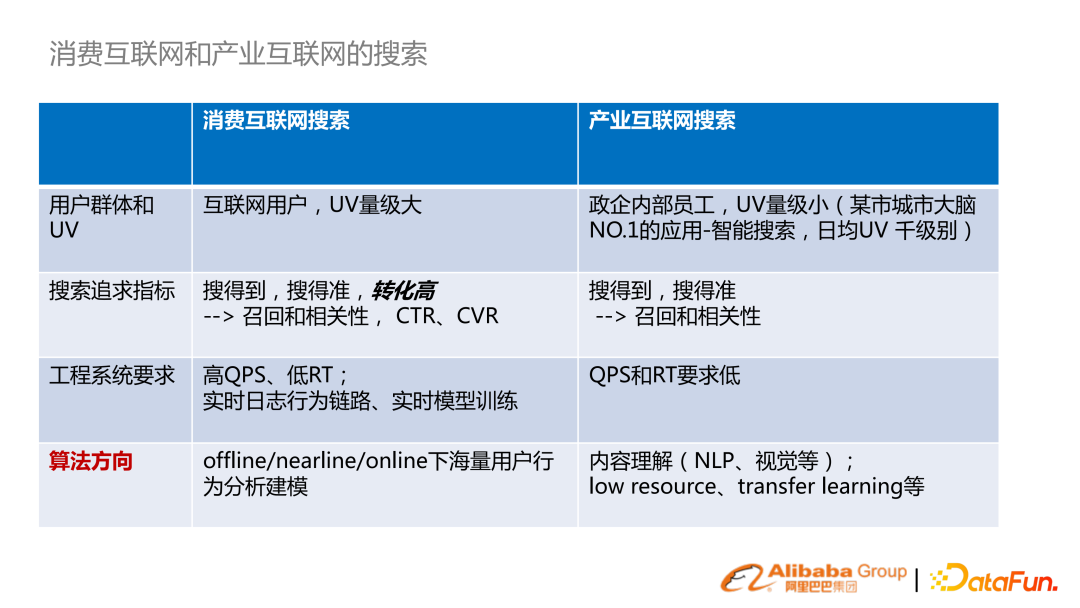
搜索在不同行業(yè)場景里區(qū)別是很大的,在此把它分為消費互聯(lián)網搜索與產業(yè)互聯(lián)網搜索
用戶群體和 UV:消費互聯(lián)網搜索 UV 非常大,產業(yè)互聯(lián)網面向政企內部的員工;
搜索追求指標:消費互聯(lián)網,除了追求搜得到、搜得準之外,還追求轉化率高。在產業(yè)互聯(lián)網,它更多是信息匹配的需求,所以關注召回跟相關性;
工程系統(tǒng)要求:消費互聯(lián)網 QPS 的要求會很高,沉淀大量的用戶行為,需要有實時日志分析、實時模型訓練。產業(yè)互聯(lián)網的要求會低一些;
算法方向:消費互聯(lián)網會從 offline、nearline、online 的海量用戶行為分析建模獲得更大收益。產業(yè)互聯(lián)網的用戶行為稀疏,所以會更注重內容理解,比如 NLP 或者視覺的理解,研究方向包括 low resource、transfer learning。
02
相關技術研究
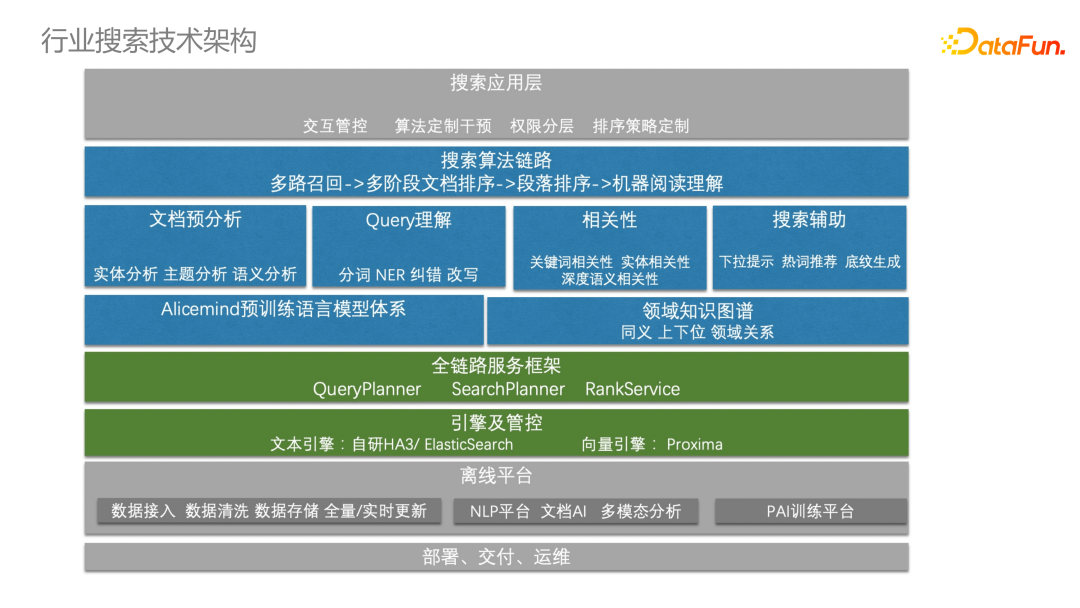
搜索是跟系統(tǒng)框架緊密耦合的:包括離線數(shù)據,搜索服務框架(綠色部分),搜索技術算法體系(藍色部分),其底座是 Alicemind 預訓練語言模型體系,同樣會匯聚做文檔分析、query 理解、相關性等。1. AliceMind 體系
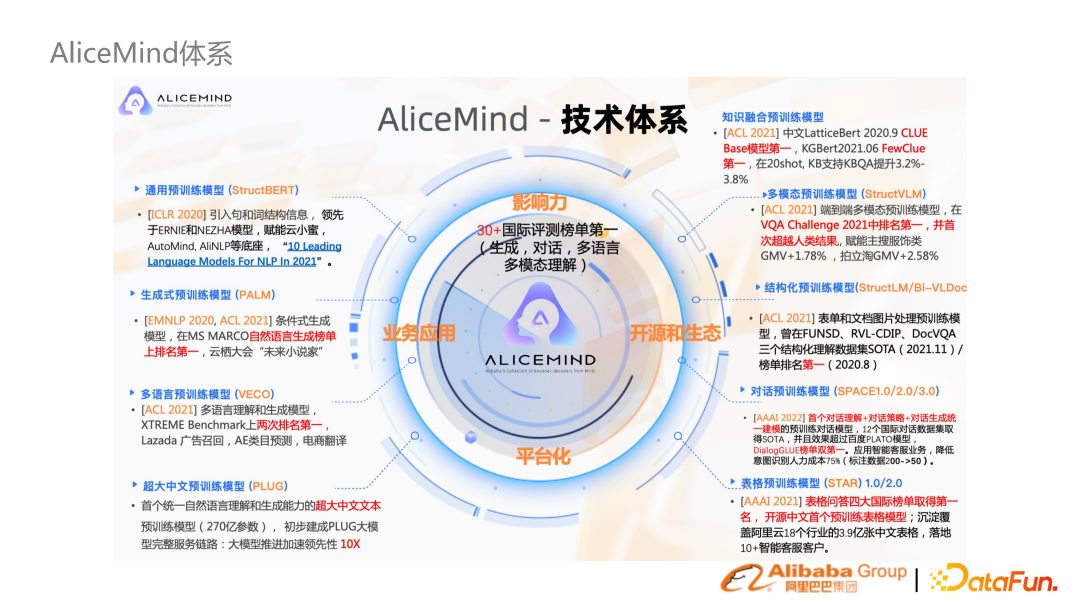
AliceMind 是達摩院構建的層次化預訓練語言模型體系。包含了通用預訓練模型,多語言、多模態(tài)、對話等,是 NLP 所有任務的底座。2. 分詞
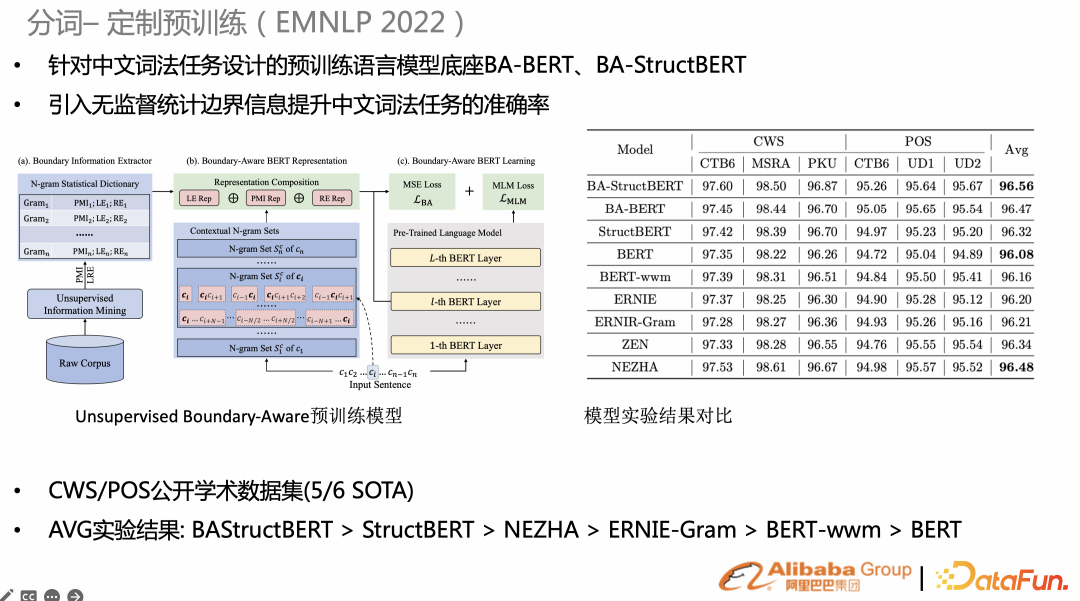
搜索的分詞(原子能力),決定了檢索索引粒度,同時也與后續(xù)相關性、BM25 粒度有關。針對 task specific 任務,如果去定制一些預訓練,能比通用的預訓練效果更好。比如最近研究希望在原生 BERT 預訓練任務上增加無監(jiān)督的統(tǒng)計信息的任務,比如統(tǒng)計字詞、Gram 粒度、或者邊界熵,然后以 mse-loss 增加到預訓練。在 CWS/POS、NER上(右圖),的諸多任務都達到 SOTA。
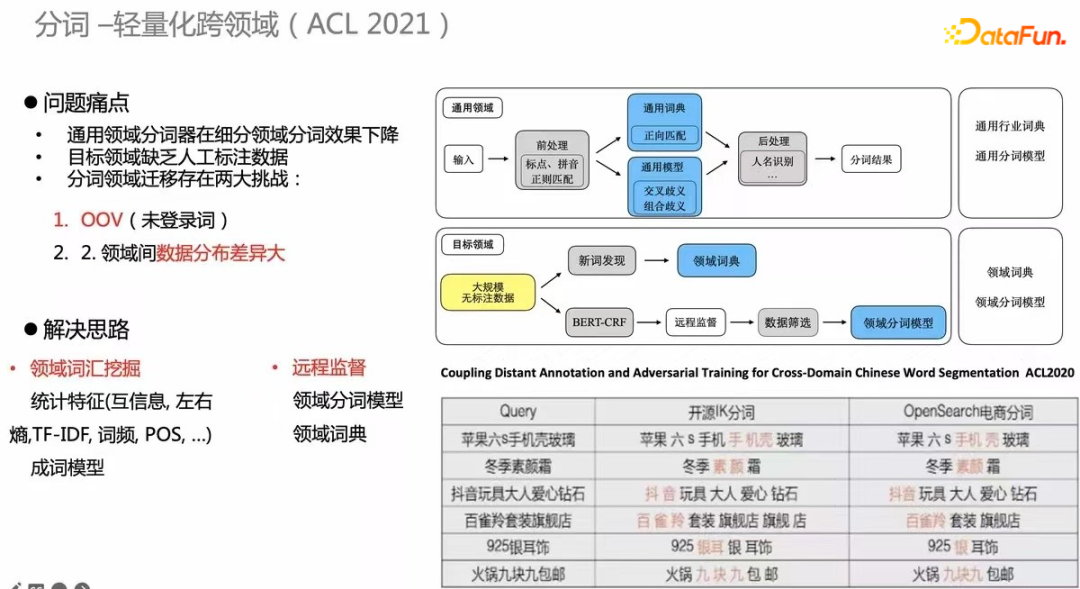
另一個研究是跨領域。每次需要標數(shù)據、構建監(jiān)督任務的成本很高,所以需構建跨領域無監(jiān)督分詞的機制。右下角的表格為例,電商分詞相比開源的分詞質量有明顯改善,這套方法也發(fā)布到 ACL2020。3. 命名實體識別
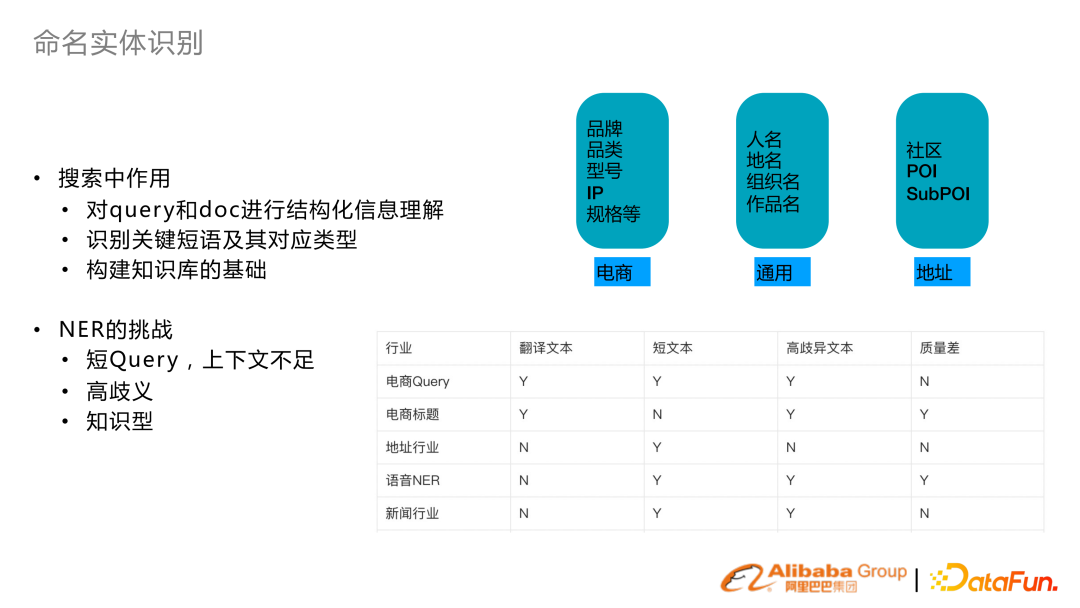
搜索命名實體識別主要是對 query 、Doc 進行結構化的理解,識別出關鍵短語及類型。同時搜索知識圖譜的構建也依賴 NER 功能。 搜索 NER 也面臨一些挑戰(zhàn)。主要是比如 query 常常是比較短的,上下文不足。比如說電商里面 query 實體的歧義性很高,知識性很強。所以這幾年在 NER 核心的優(yōu)化思路,就是通過上下文或者引入知識的方式來增強 NER 的表征。
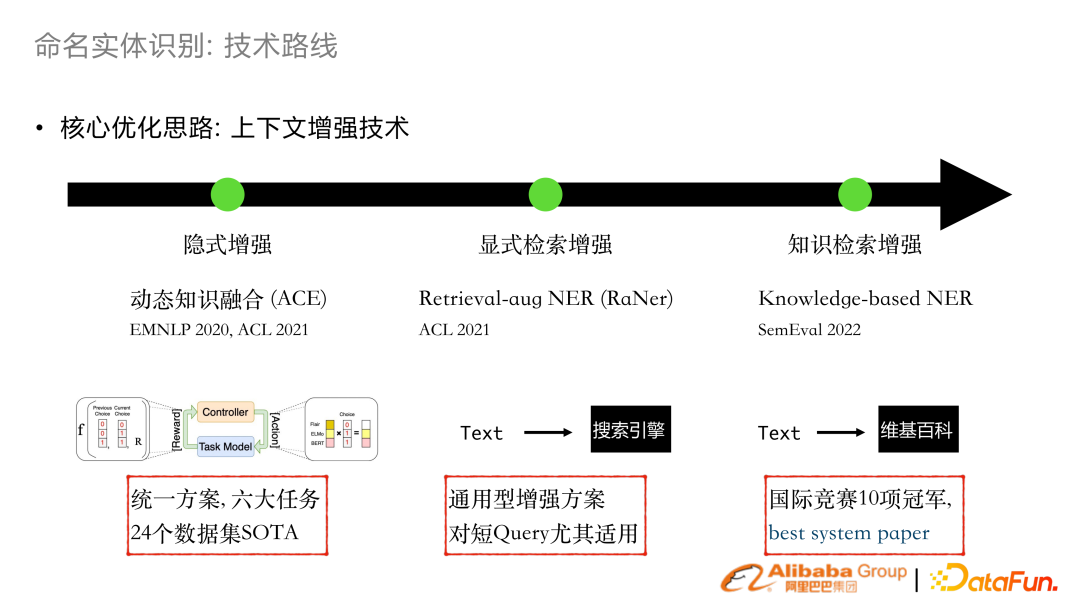
在 2020年、2021年做了隱式增強的工作 combo embedding。把已有 word extractor 或者 GLUE 的表征動態(tài)融合,能搭載在很多業(yè)務任務上面達到 SOTA。 2021年,研發(fā)基于顯式的檢索增強,對一條文本會通過搜索引擎得到增強的上下文,融合到 transformer結構。這個工作發(fā)表在 ACL 2021 上了。 基于這個工作,我們參加了 SemEval 2022 多語言 NER評測拿了 10 項冠軍,以及 best system paper 。

檢索增強:輸入句子本身之外,檢索得到額外 context 并 concat 到輸入,結合 KL 的 loss 來幫助學習。在很多開源數(shù)據集拿到 SOTA。4. 自適應多任務訓練
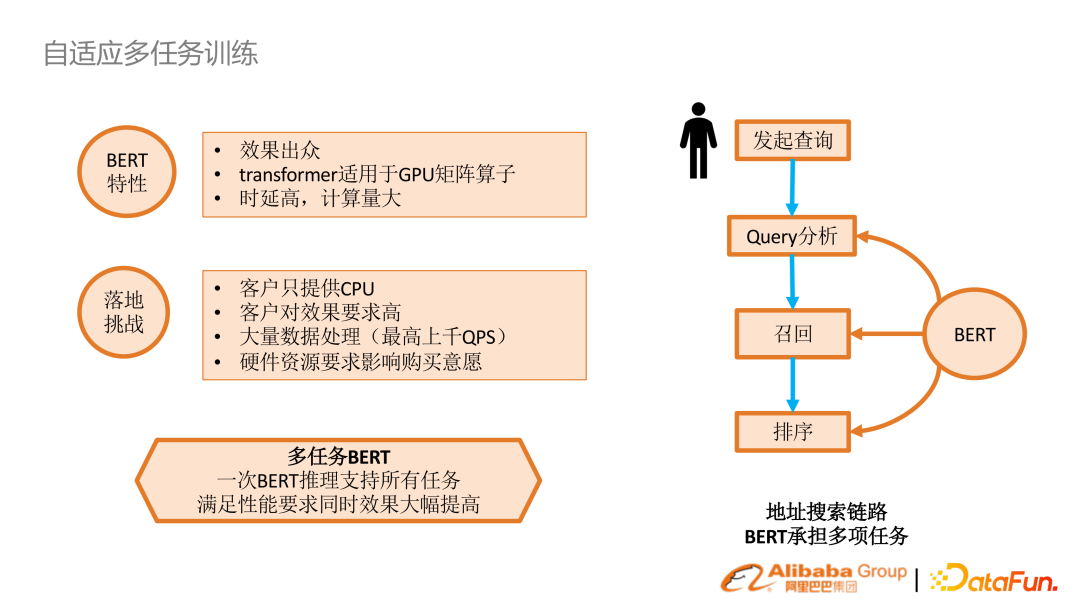
BERT 本身效果是很好的,但實際生產很少有 GPU 集群,每個任務都要去做 inference性能代價很大。我們思考能否只做一次 inference,在 encoder 之后每個任務自己再做適配,就能得到比較好的效果。
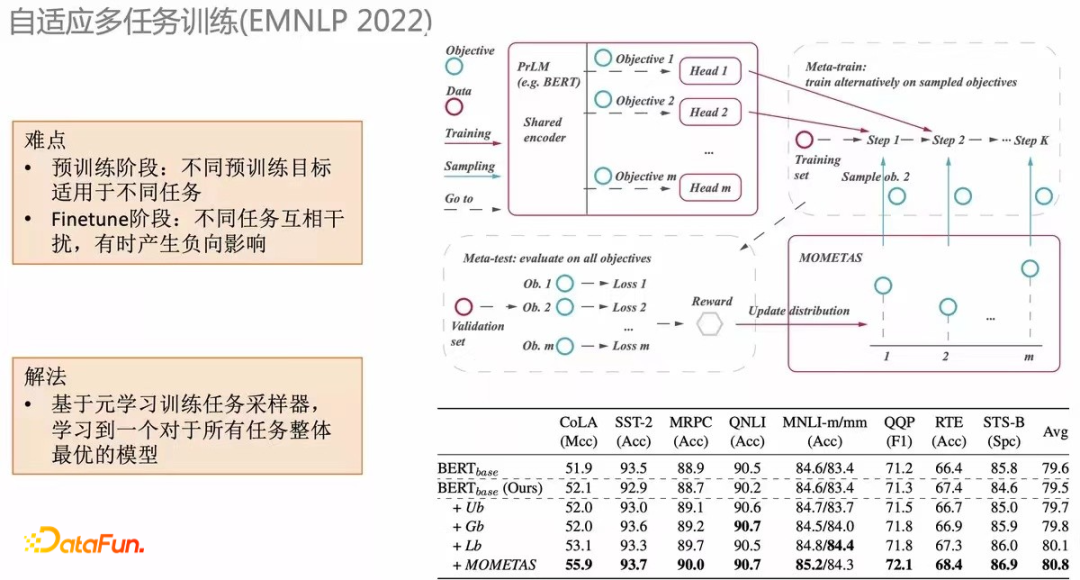
一個直觀的方法就是通過 meta-task 的框架納入 NLP query 分析任務。但傳統(tǒng)的 meta-task 是均勻采樣的分布。我們提出了 MOMETAS,一個自適應基于元學習的方法,來自適應不同任務的采樣。在多個任務去學習的過程中,我們會階段性用 validation data 做測試看不同任務學習的效果。reward 反過來指導前面訓練的采樣。(下方表格)在很多任務上結合這個機制,相比 UB(均勻分布)有不少提升。
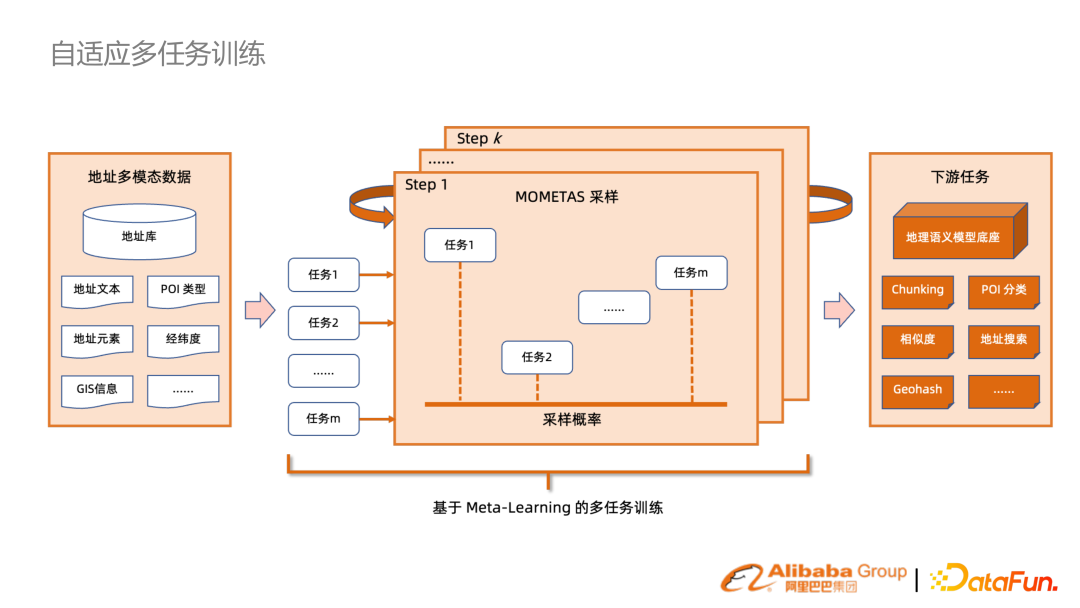
把上述機制應用在搜索很多行業(yè)的場景里去,帶來的收益是僅通過一次 BERT 的編碼并存儲,在很多的下游任務直接復用,能大幅提升性能。5. 搜索召回預訓練語言模型
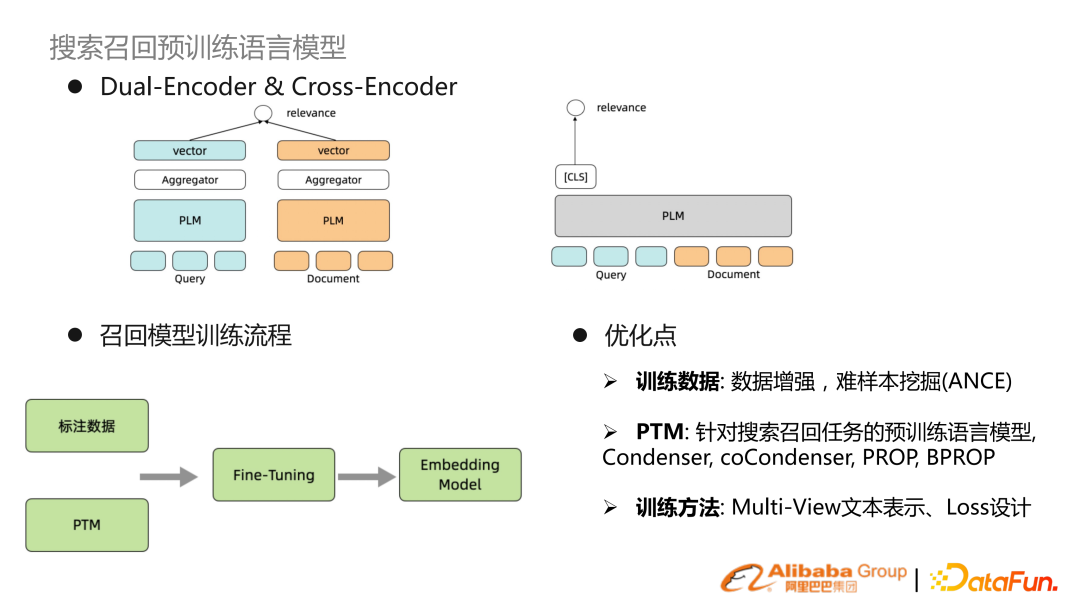
深度檢索,無外乎是雙塔或單塔,通用的訓練范式是有監(jiān)督信號以及預訓練模型,進行 finetune 獲得 embedding,對 query 和 doc 進行表征。近期的優(yōu)化路線主要是數(shù)據增強或難樣本挖掘,另外是優(yōu)化預訓練語言模型。原生 BERT 不是特別適合搜索的文本表示,所以有針對搜索文本表示的預訓練語言模型。其他優(yōu)化是在于做 multi-view 文本表示,以及特別的 loss 設計。
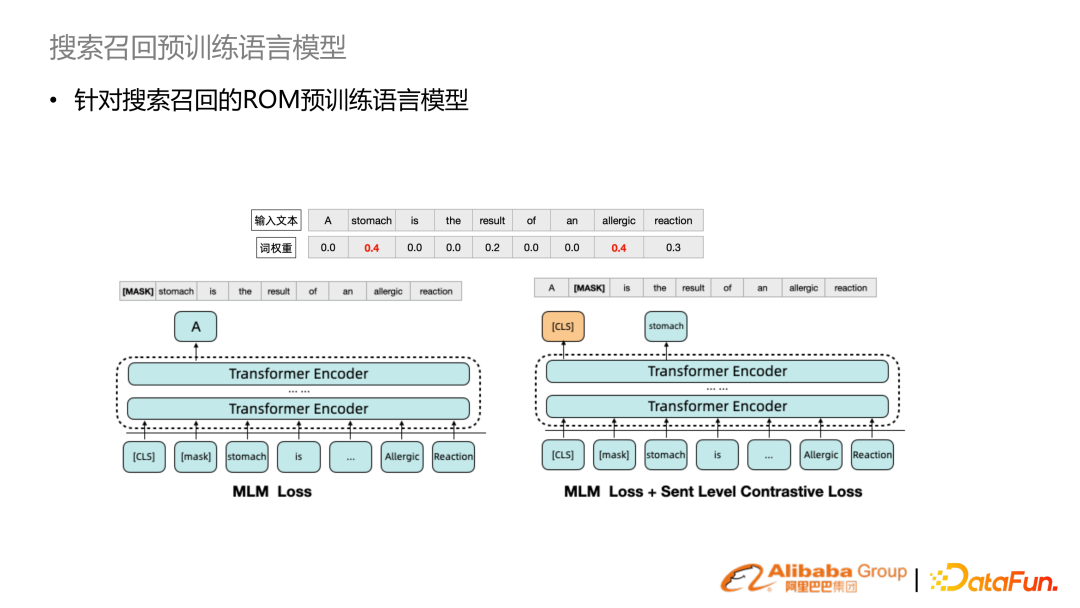
相比原生 BERT 的隨機采樣,我們結合搜索詞權重提升詞權重比較高的詞來提升采樣概率,學習到的表征更適合搜索召回。除此之外,增加 sentence level 對比學習。結合這兩個機制,提出了 ROM 的預訓練語言模型。
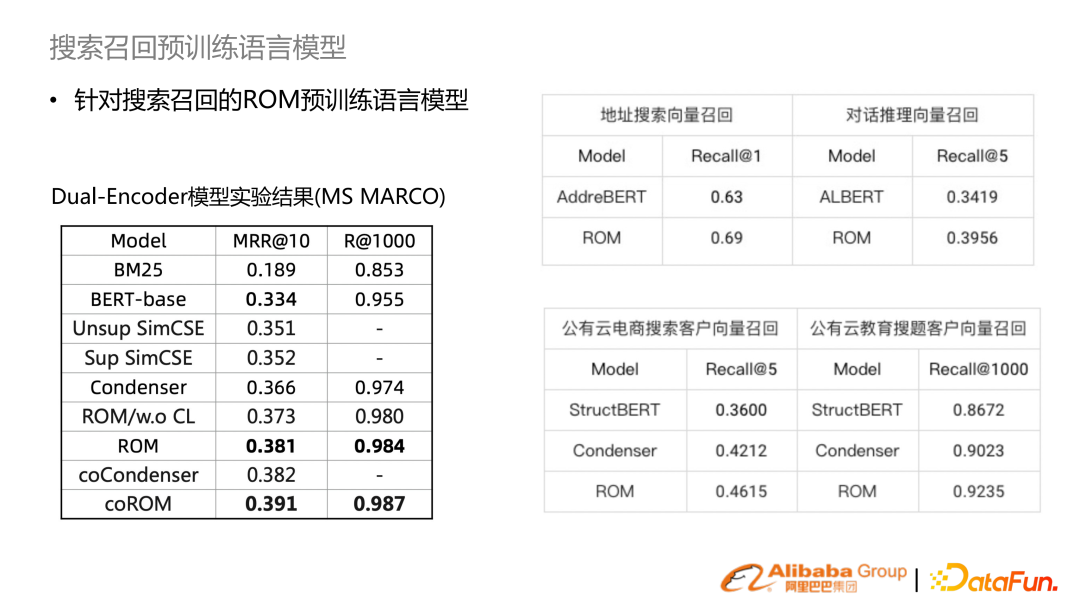
在 MS MARCO 做實驗,對比先前做法能夠達到最好的效果。在實際的場景搜索任務中,也能帶來較大的提升。同時該模型也參與了 MS 刷榜。6. HLATR 重排模型
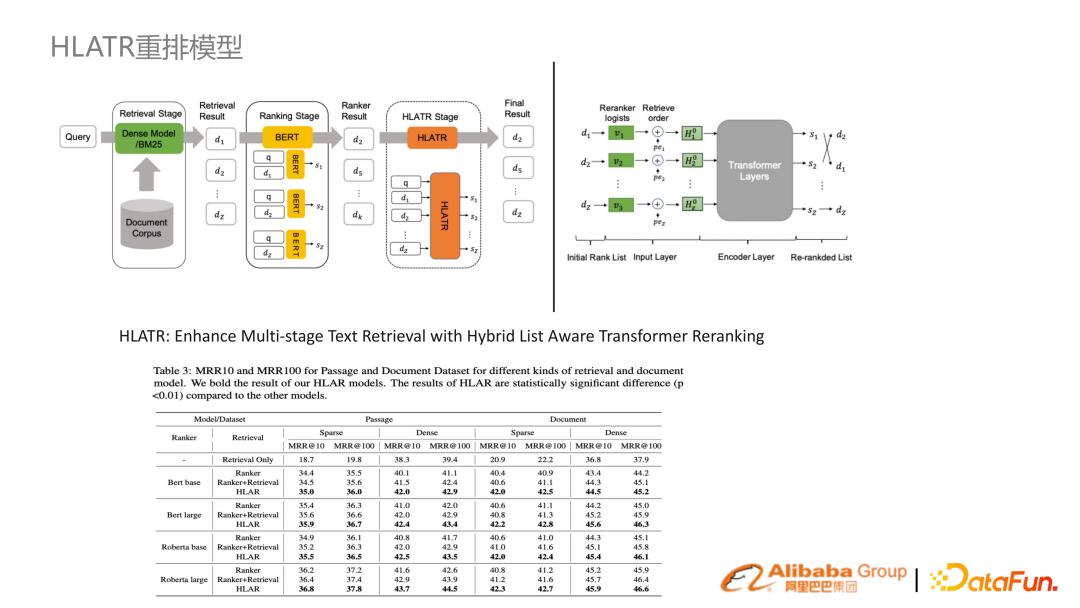
除了 ROM 這個召回階段之外,在精排、重排階段,提出了一套 list aware 的 Transformer reranking,即將精排很多分類器的結果通過 Transformer 有機的融合在一起,有比較大的提升。
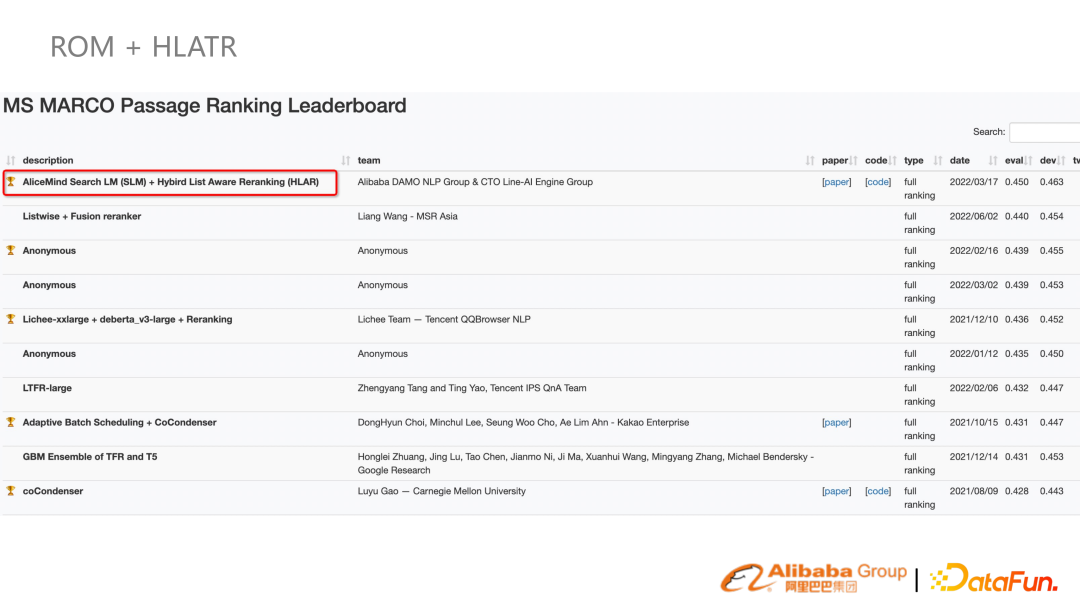
結合 ROM 和 HLATR 兩個方案,3 月份至今(7 月份)仍舊是 SOTA 結果。
03
行業(yè)搜索應用
1. 地址分析產品
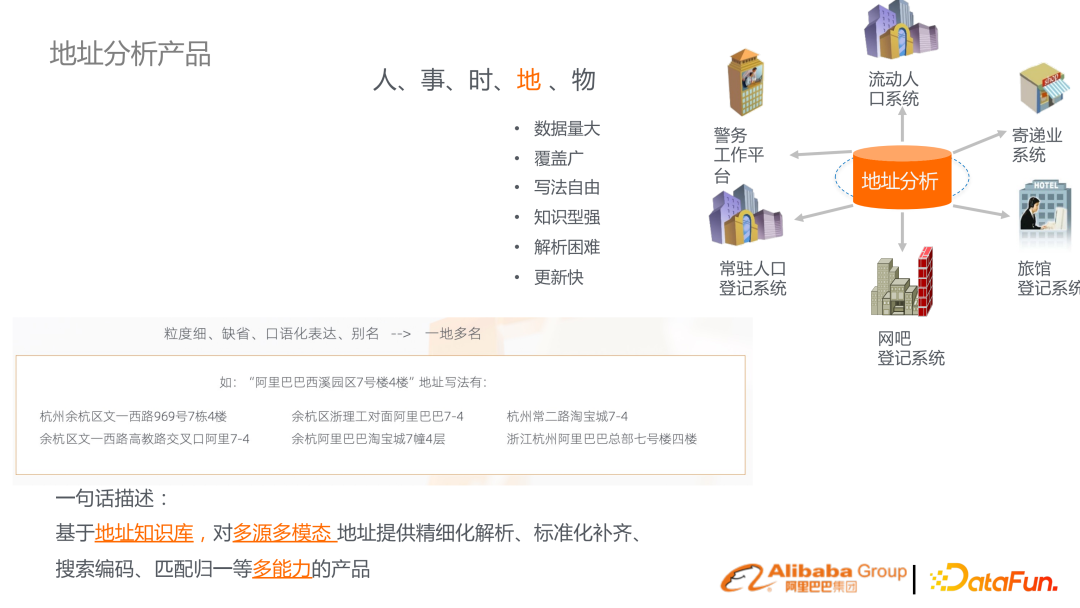
達摩院研發(fā)的地址分析產品,背景是各行各業(yè)有很多通訊地址。中文的通訊地址有很多特點,比如口語化表達有很多缺省。同時地址本身是人事實物,是客觀世界很多實體橋接的一個重要實體單位。所以基于此建立了一套地址知識圖譜,提供解析、補齊、搜索、地址分析。
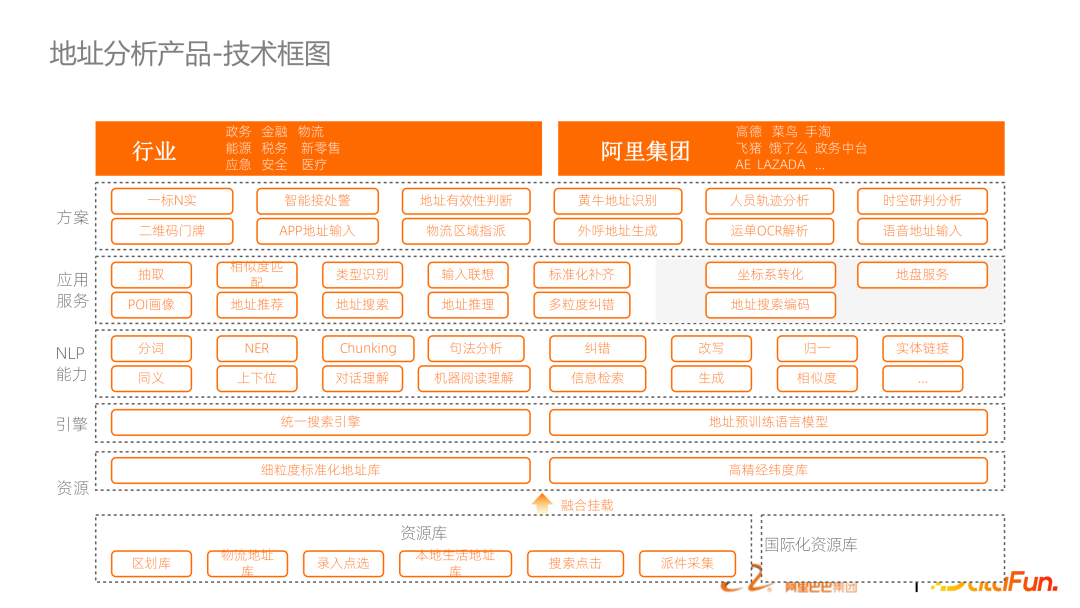
這是產品的技術框圖。從下到上包含了地址知識圖譜的構建,以及地址預訓練語言模型,包括基于搜索引擎的框架串接整個鏈路。上述提到的基準能力,以 API 的方式提供出來包裝成行業(yè)方案。
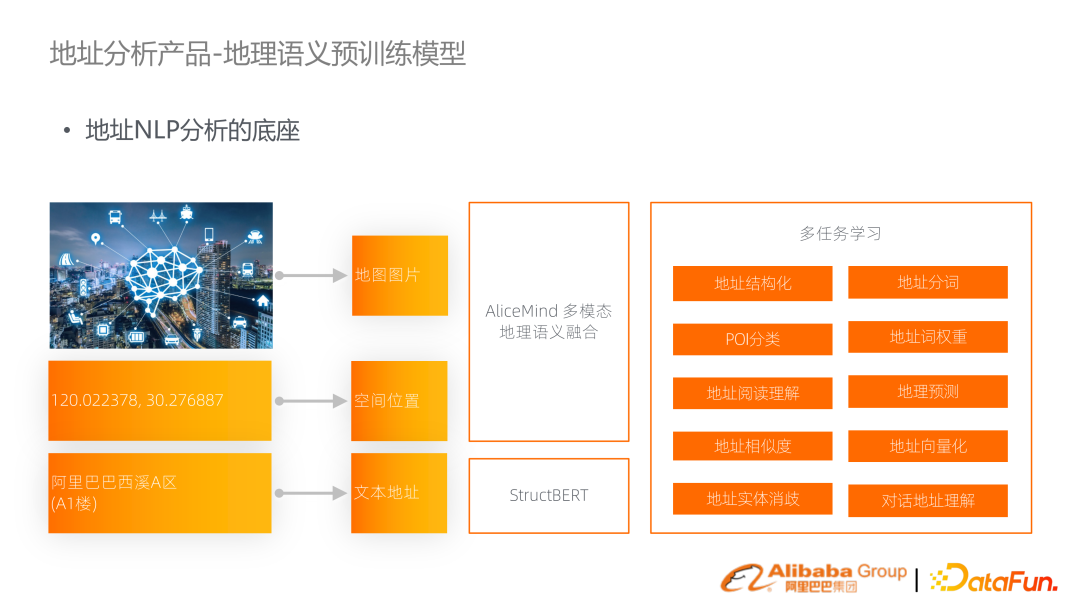
這套技術里面比較重要的一個點是地理語義的預訓練語言模型。一個地址在文本表示會是字符串,其實在空間里面它往往是表征成經緯度,在地圖中還有對應的圖片。所以這三種模態(tài)的信息是把它有機融合成一個多模態(tài)的地理語義的語言模型,以此來支持在定址里的任務。
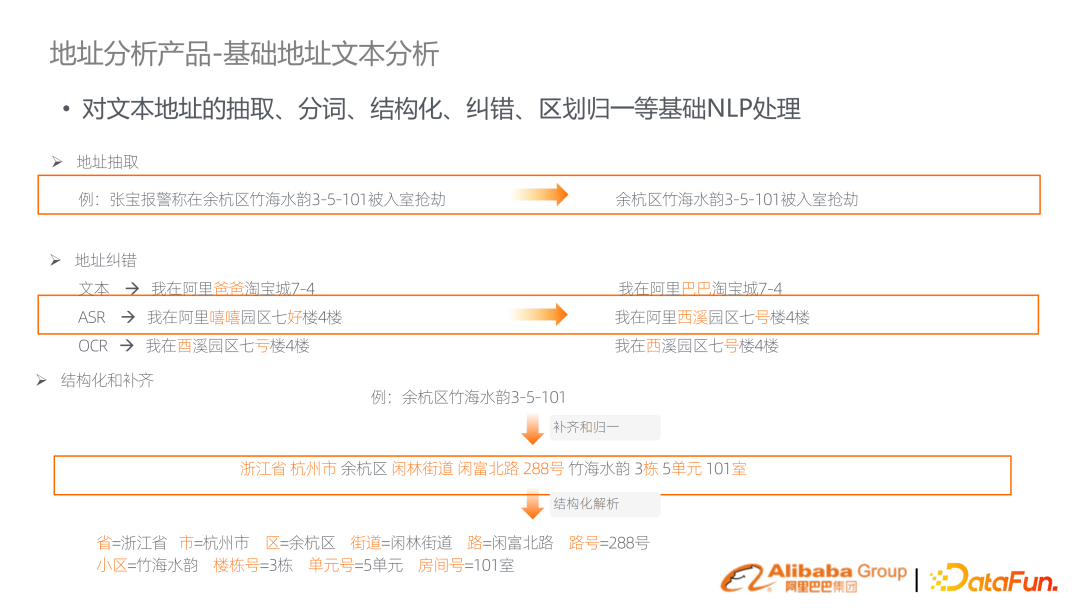
上述提到需要做地址相關的很多基礎能力,比如分詞、糾錯、結構化等分析。
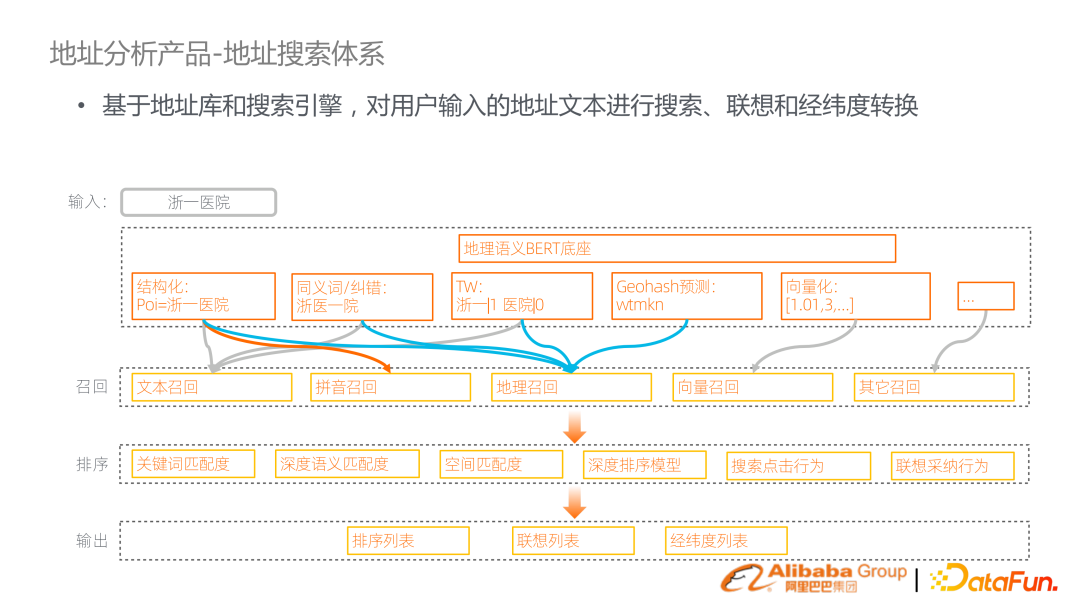
最核心的鏈路是將地理預訓練語言模型、地址基礎任務、引發(fā)搜索引擎的方式將它們橋接起來。比如說搜索浙一醫(yī)院,可能會對它去做結構化、同義詞糾錯、term weighting 做向量化、Geohash 的預測。基于分析結果做召回。這個鏈路是標準的搜索鏈路,進行文本召回、拼音召回、向量召回,還增加地理召回。召回之后是多階段的排序,包括多粒度的 feature 融合。
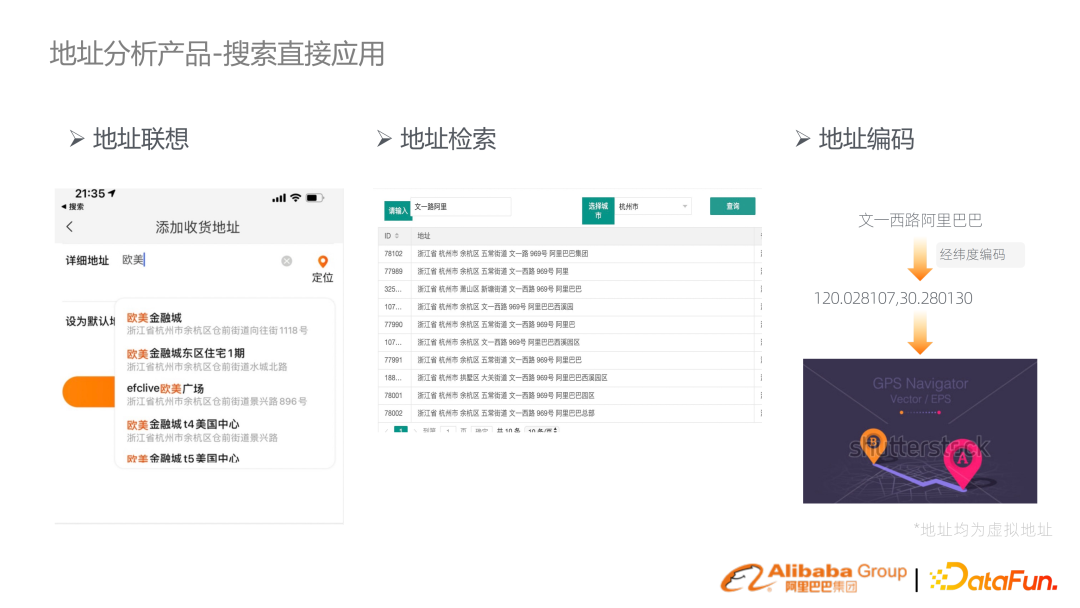
地址搜索體系直觀的應用,就是填地址后 suggestion 場景,或者高德地圖里面去做搜索,需要把它映射到空間一個點位上。
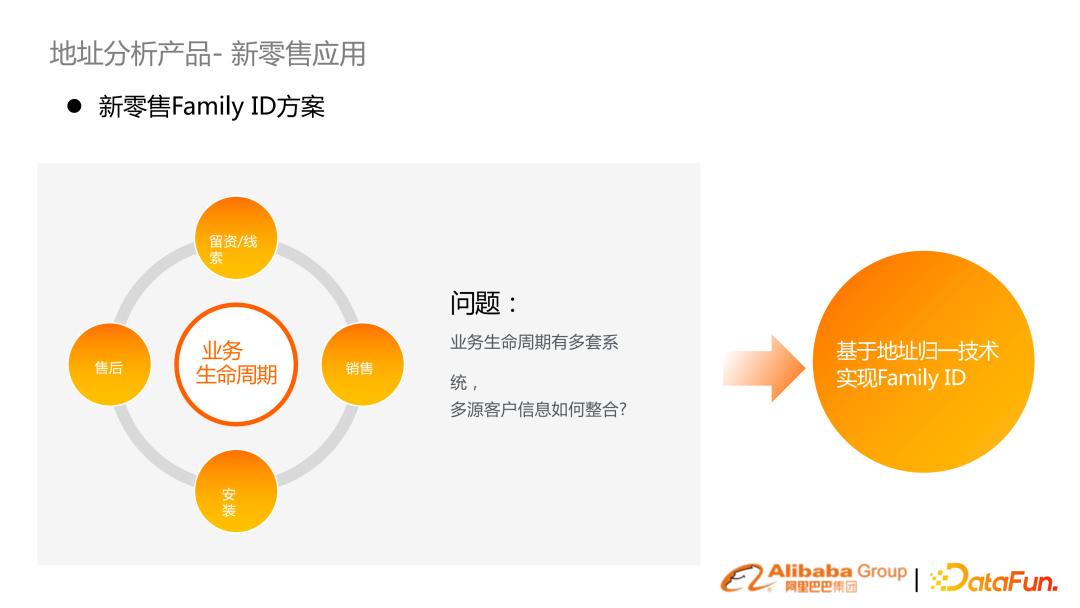
接下來介紹兩個比較行業(yè)化的應用方案。第一個是新零售 Family ID,核心訴求是維護一套客戶的管理系統(tǒng),然而各個系統(tǒng)用戶信息沒有打通,無法實現(xiàn)有效的整合。
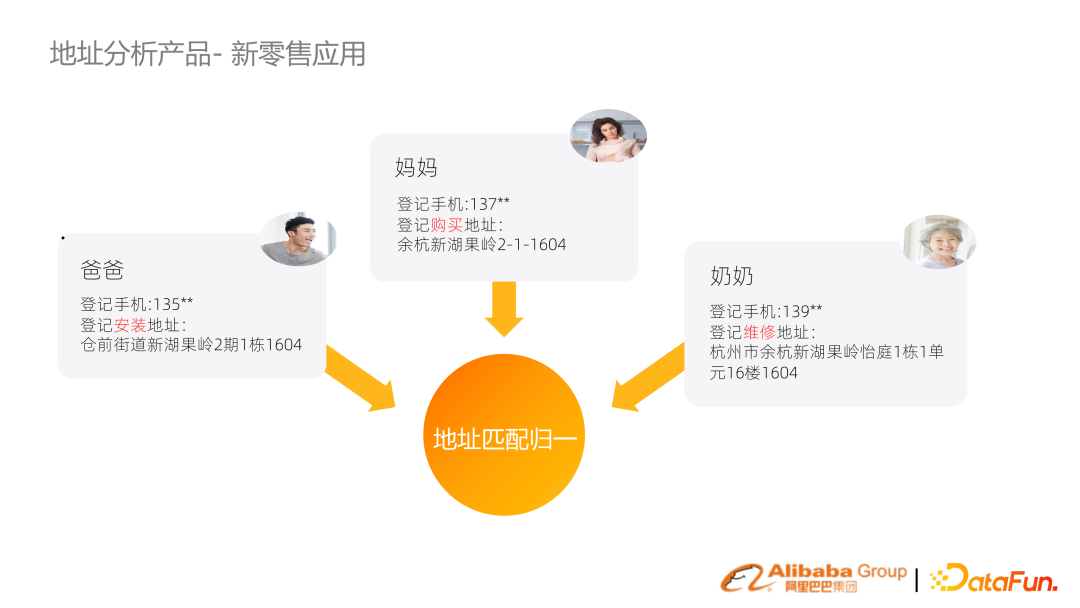
比如品牌廠商賣了一個空調,家人由于購買、安裝、維修而登記了各種地址、手機號,但對應的實際上是同一個地址。建立的地址搜索歸一技術,把不同表示的地址進行歸一,生成指紋,將不同用戶 ID 聚合到 Family 概念中。
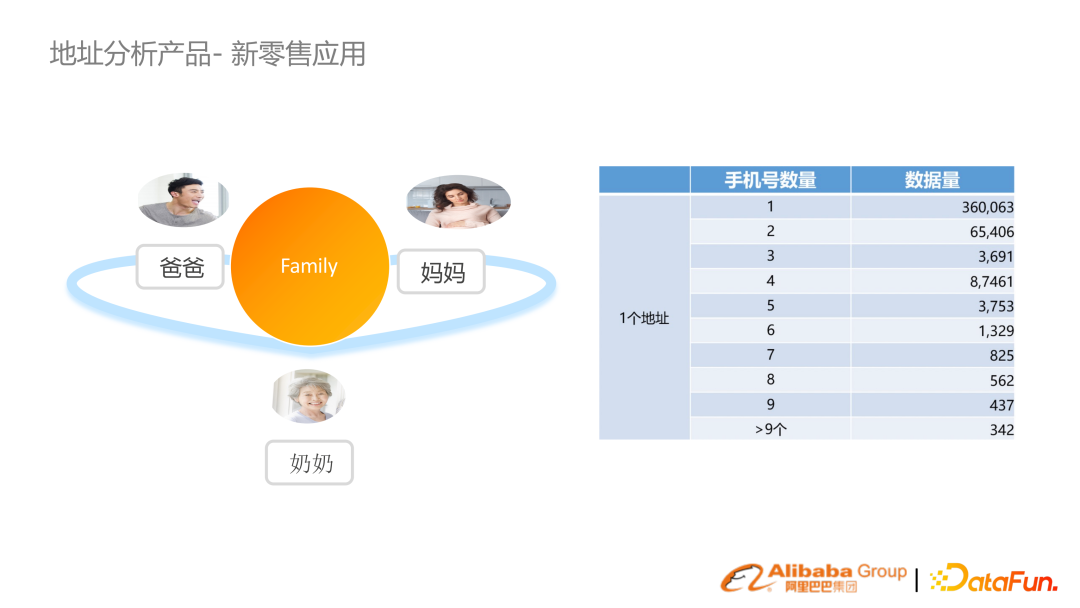
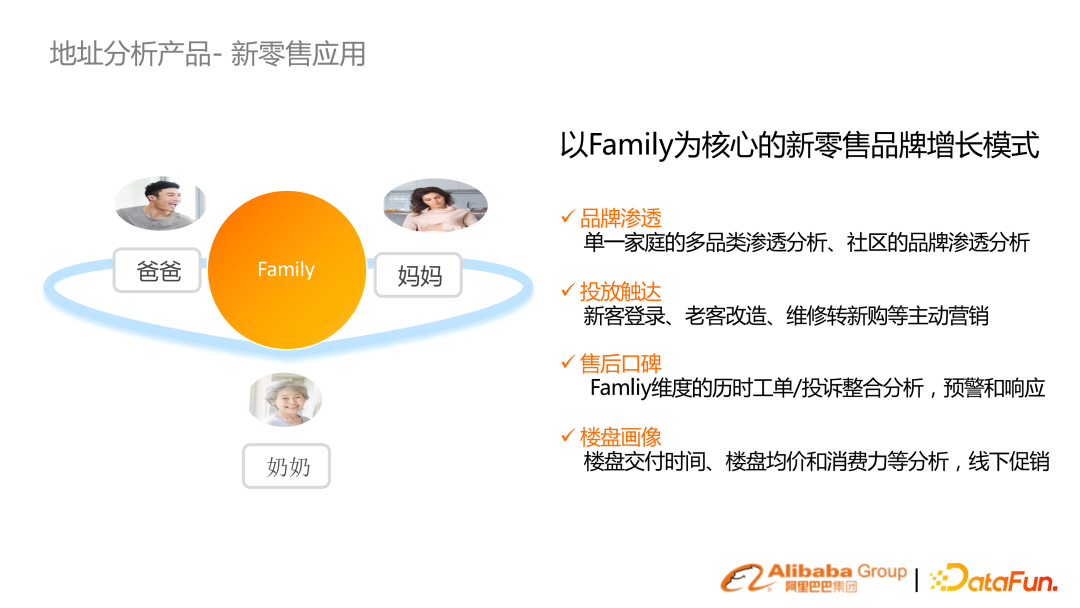
通過家庭聚合的概念,可以做到更好的滲透分析、廣告投放觸達等新零售下的營銷活動。

另外一種應用場景,是 119、129、應急等智能接警應用。因為涉及到老百姓的人身財產安全,所以分秒必爭。希望結合語音識別、文本語義理解技術把這個效率提升。
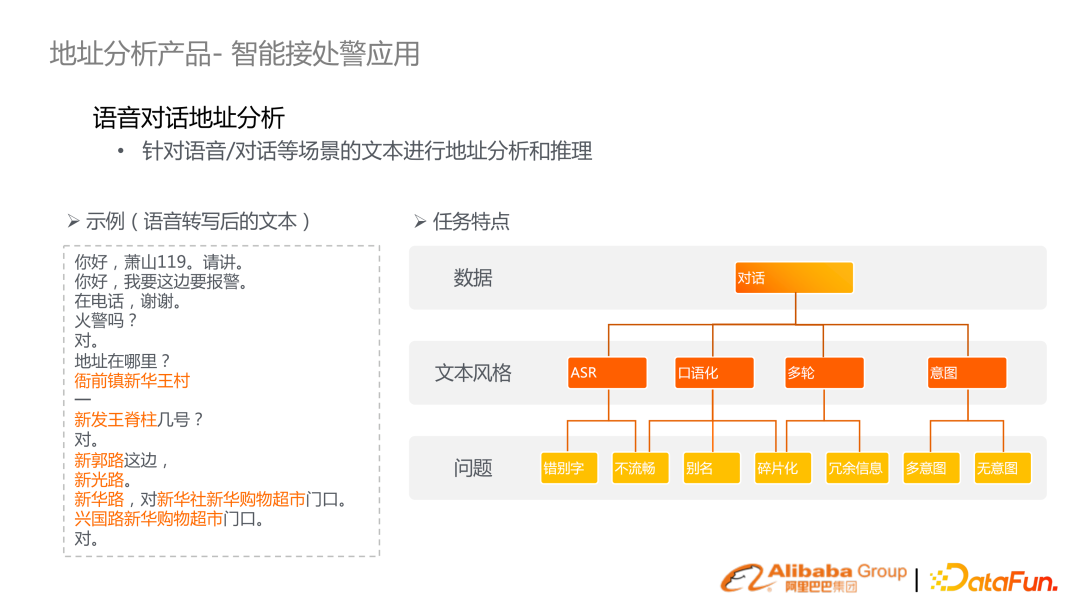
(左邊例子)場景有很多特點,比如 ASR 轉寫的錯別字、不流暢、口語化等問題。目標是希望基于自動語音轉寫分析推斷報警地點。
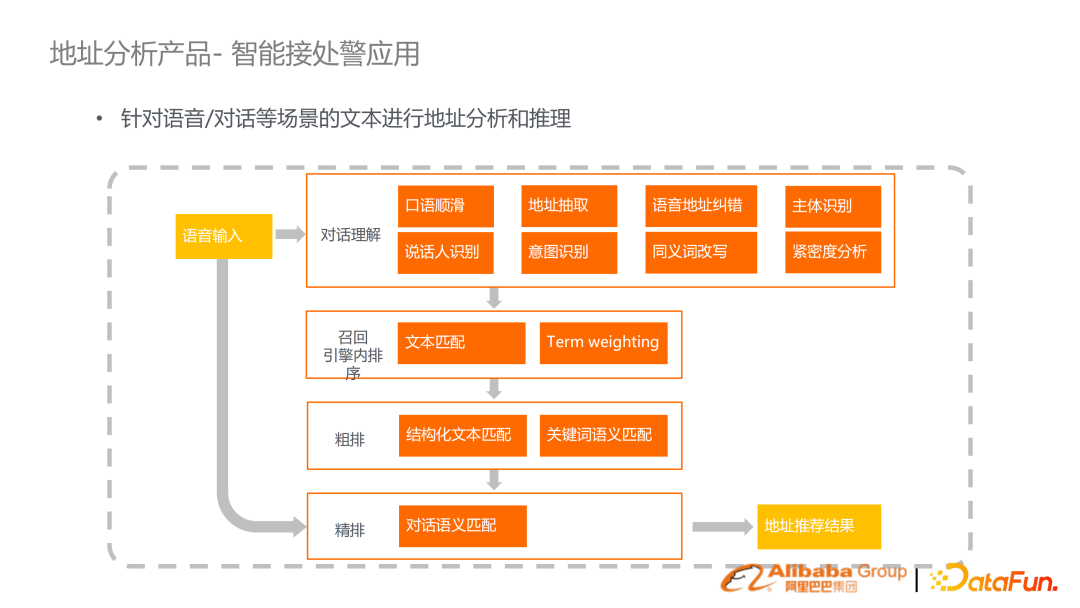

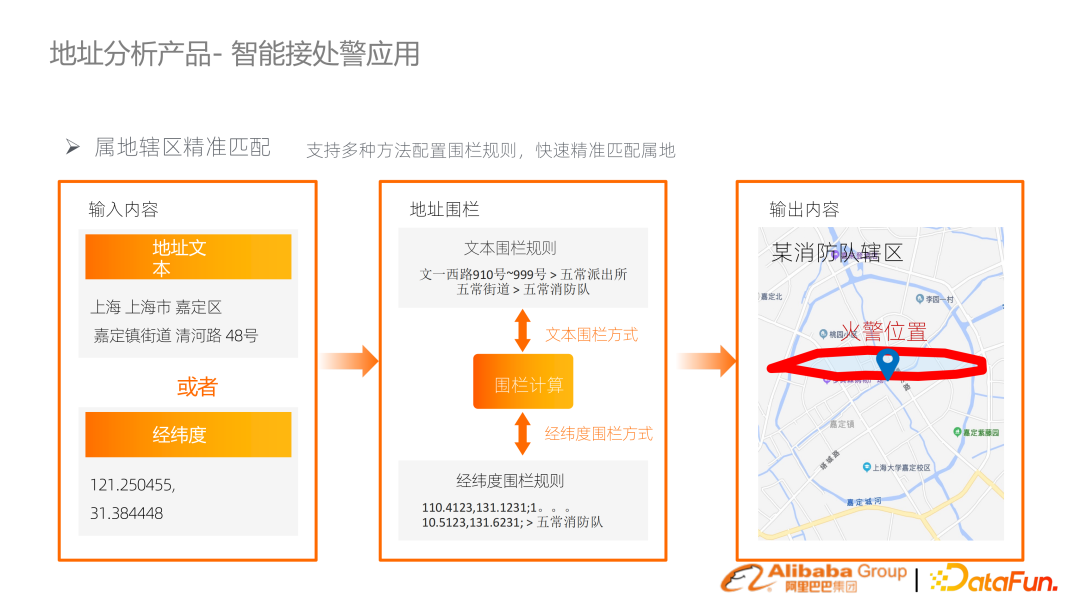
我們提出了一整套系統(tǒng)方案,包括對話理解的口語順滑糾錯、意圖識別,以及結合一套搜索從召回粗排精排的機制來最終實現(xiàn)地址推薦。鏈路已經比較成熟,在中國上百個城市的消防系統(tǒng)落地;消防從報警對話識別出具體的地點,結合推薦、匹配、地址圍欄判斷具體地點,對應出警。2. 教育拍照搜題
接下來介紹教育行業(yè)的拍照收集業(yè)務,在 To C、面向老師端也有不少需求。

拍照搜題有幾個特點,本身有增量更新的題庫,用戶群體較大。另外,不同學科、年齡段對應的領域知識性很強。同時是一個多模態(tài)的算法,從 OCR 到后續(xù)語義理解、搜索等一套鏈路。
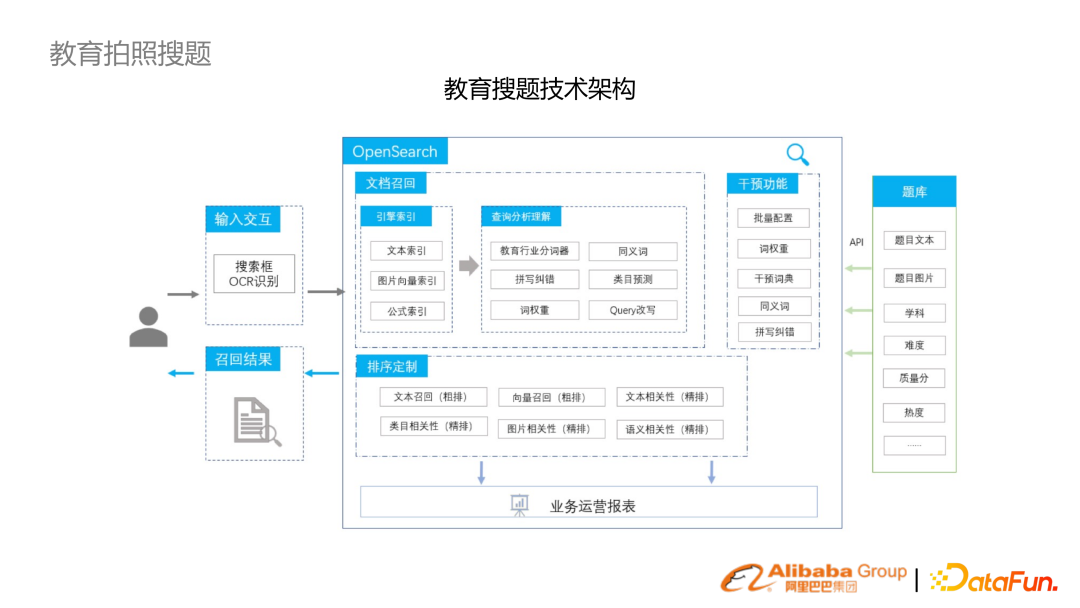
近幾年針對拍照收集構建了一整套從算法到系統(tǒng)的鏈路。
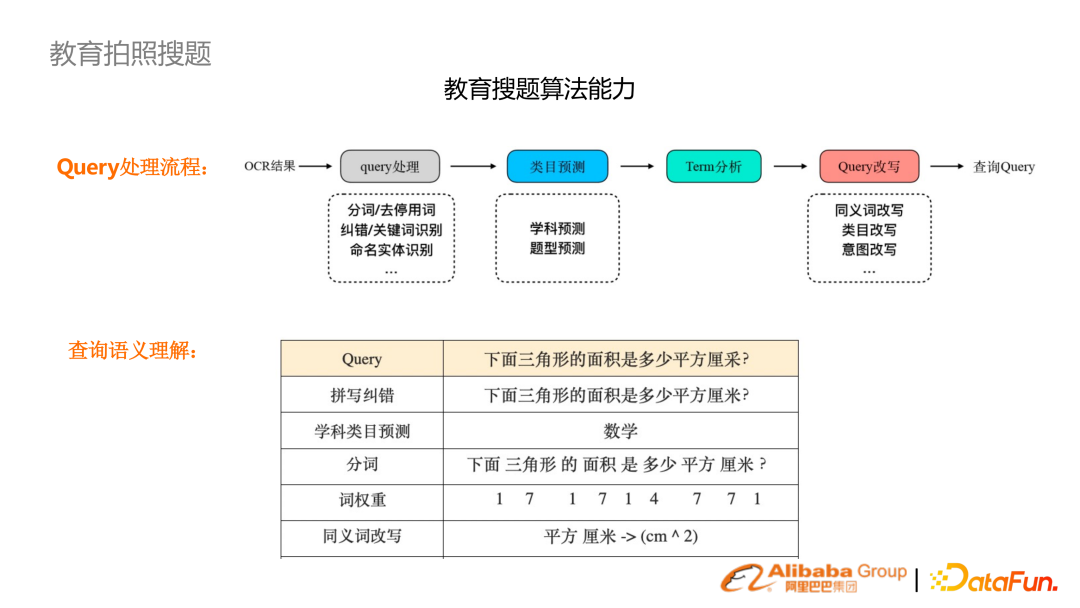
比如,在手機拍照以及 OCR 識別后,會進行拼寫糾錯、學科預測、分詞、詞權重等一系列工作,幫助做到檢索。

由于 OCR 對英文識別沒有空格,訓練了一套 K12 英文的預訓練算法模型,進行英文的切分。
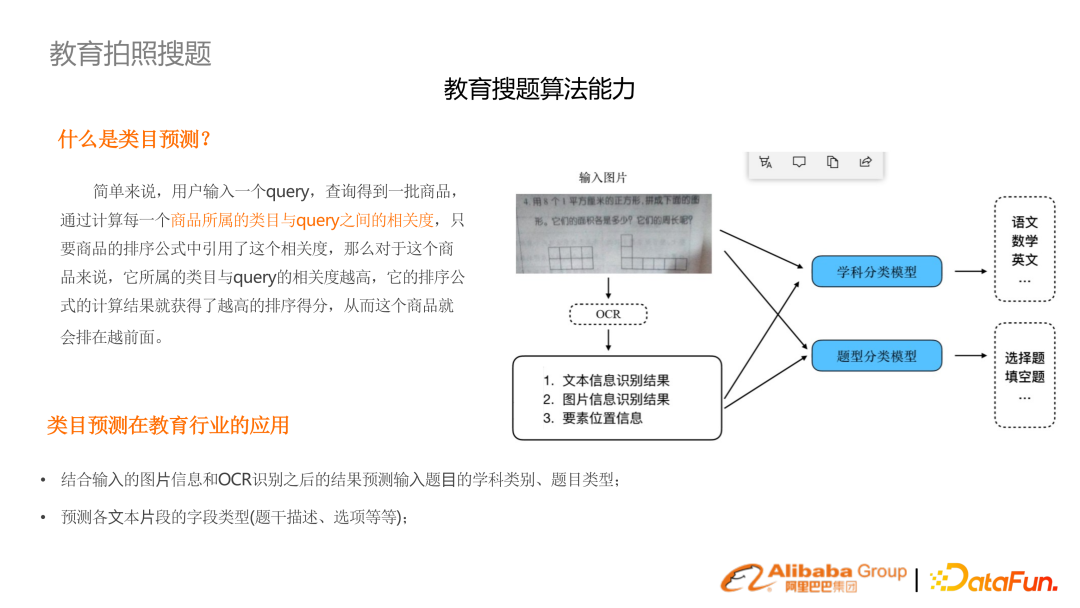
同時,學科、題目類型都是未知的,需要做一個提前預測。使用多模態(tài),結合圖片和文本進行意圖理解。
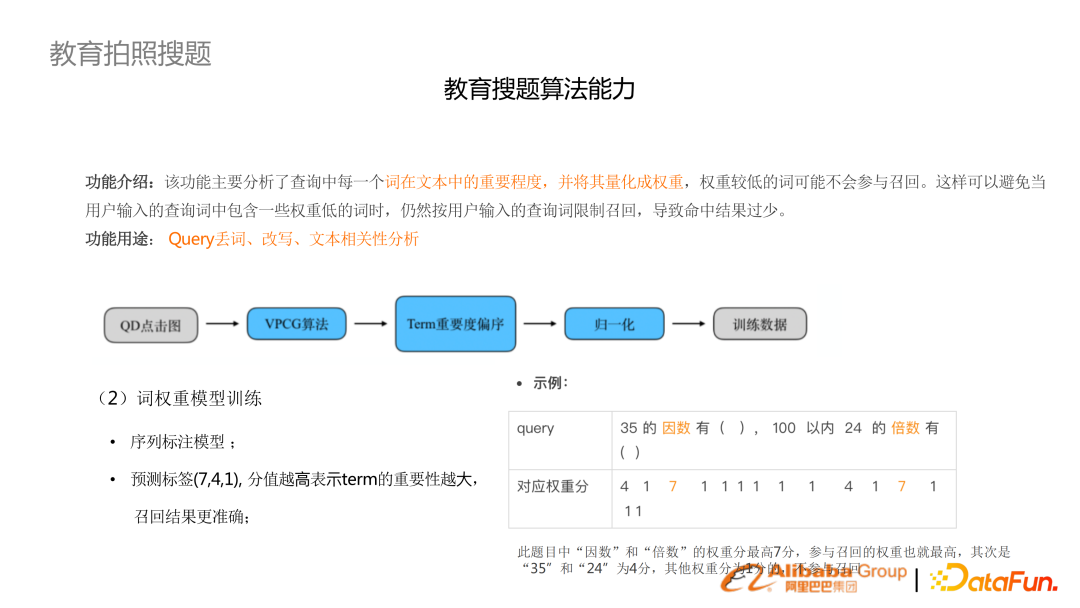
拍照搜題跟普通的用戶搜索不太一樣,用戶搜索往往 query 是比較短,拍照搜題往往是一道完整的題目。題目里面很多詞是不重要的,需要做詞權重分析,丟棄不重要的詞或者排序予以降權。

在拍照搜題場景中優(yōu)化效果最明顯的是向量召回。性能上的要求不太能用 OR 的召回機制,需要用 AND 邏輯,對應特點是召回比較少。去提升 recall 的話,需要做 term weighting、糾錯等較冗余的模塊。(右圖)通過文本加向量的多路召回效果,超過純 or 邏輯,在 latency 降低 10 倍。
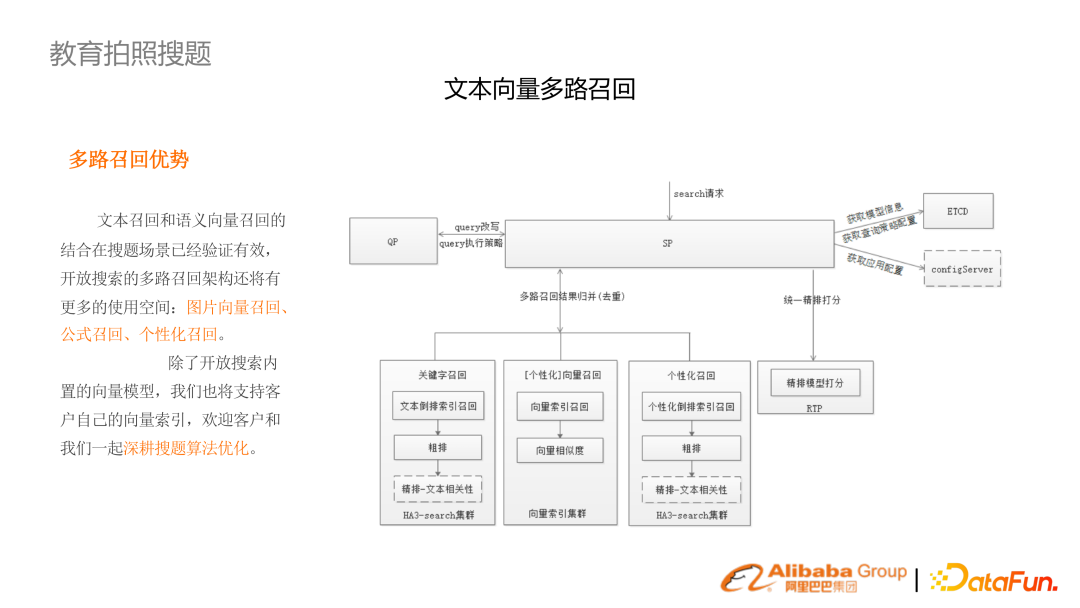
拍照搜索的鏈路包括了圖像向量召回、公式召回、個性化召回。

提供兩個例子。第一個是純文本的 OCR 結果,(左列)舊結果是基于 ES,簡單的 OR 召回,加上 BM25 的結果,(右列)經過多路召回以及相關性召回的鏈路有較大提升。 第二個是拍照含有圖形,多路中是必須結合圖片召回。3. 電力知識庫統(tǒng)一搜索
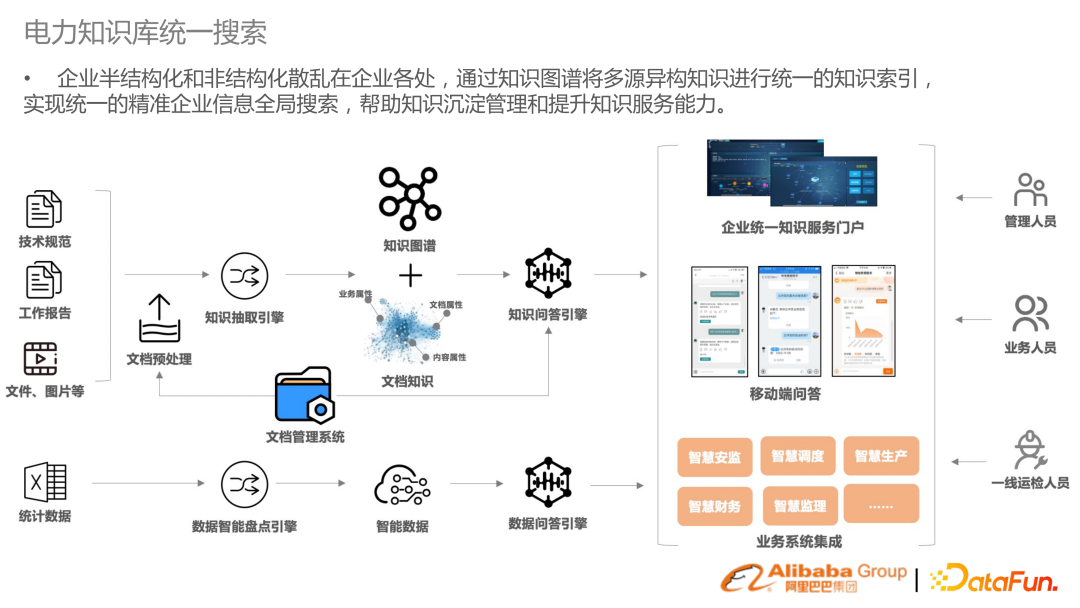
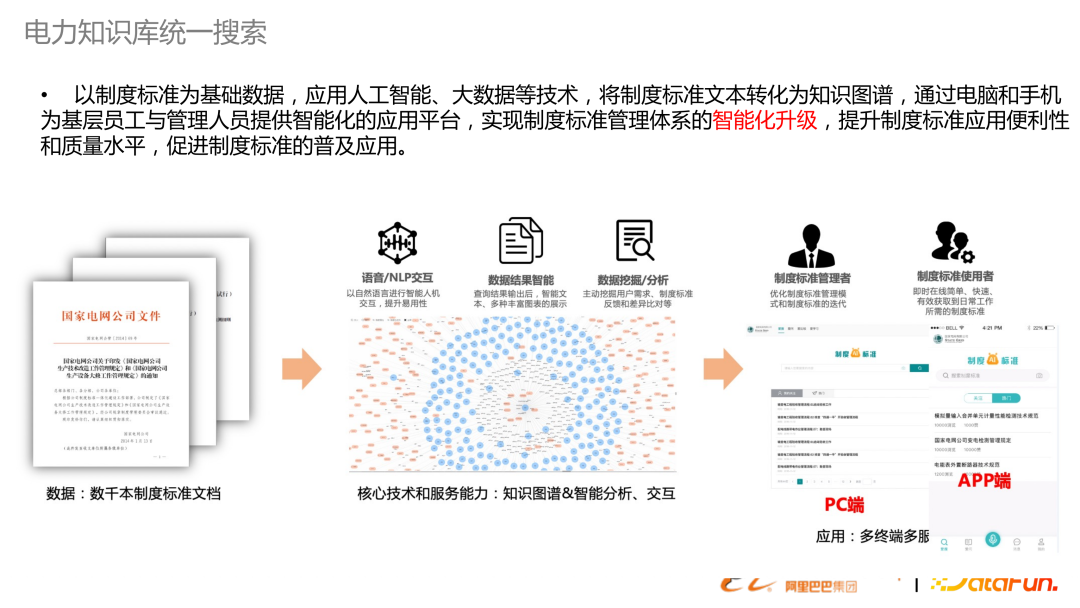
在企業(yè)搜索中有很多半結構化和非結構化數(shù)據,提供統(tǒng)一搜索,幫助企業(yè)整合數(shù)據資源。不僅在電力,其他行業(yè)也有類似需求。這里的搜索不再是狹義的搜索,還包含了對文檔的預處理文檔的AI和知識圖譜的構建,還包括后續(xù)橋接問答的能力。以上是在電力知識庫里,去做一套制度標準文本,從結構化到檢索,到應用端的示意圖。 審核編輯 :李倩
-
語言模型
+關注
關注
0文章
527瀏覽量
10285 -
自然語言
+關注
關注
1文章
288瀏覽量
13355 -
知識圖譜
+關注
關注
2文章
132瀏覽量
7711
發(fā)布評論請先 登錄
相關推薦






 工商網監(jiān)
工商網監(jiān)
評論