


谷歌 Chromium 規模的項目在新硬件上的構建時間長達一小時,而在老硬件上的構建時間更是達到了六個小時。雖然也有海量的調整方案能加速構建速度,還有不少削減構建內容但極易出錯的捷徑供人選擇,再加上數千美元的云計算能力,Chromium 的構建時間仍是接近十分鐘。這點我完全無法接受,人們每天都是怎么干活的啊?
有人說 Rust 也是一樣,構建時間同樣令人頭疼。但事實就是如此,還是這僅僅是一種反 Rust 的宣傳手段?在構建時間方面 Rust 和 C++ 究竟誰能更勝一籌呢?
構建速度和運行時性能對我來說非常重要。構建測試的周期越短,我編程就越高效、越快樂。我會不遺余力地讓我的軟件速度更快,讓我的客戶也越快樂。因此,我決定親自試試 Rust 的構建速度到底怎么樣,計劃如下:
找一個 C++ 項目
把項目中的一部分單獨拿出來
逐行將 C++ 代碼重寫為 Rust
優化 C++ 和 Rust 項目的構建
對比兩個項目的構建測試時間
我的猜想如下(有理有據的猜測,但不是結論):
Rust 的代碼行數比 C++ 少。C++ 中多數函數和方法都需要聲明兩次:一次在 header 里,一次在實現文件里。但 Rust 不需要,因此代碼行數會更少。
C++ 的完整構建時間比 Rust 長(Rust 更勝一籌)。在每個.cpp 文件里,都需要重新編譯一次 C++ 的 #include 功能和模板,雖然都是并行運行,但并行不等于完美。
Rust 的增量構建時間比 C++ 長(C++ 更勝一籌)。Rust 一個 crate(獨立可編譯單元)一編譯,但 C++ 是按文件編譯。因此代碼每次變動,Rust 要讀取的比 C++ 多。·
對此,大家怎么看呢
42% 的人認為 C++ 會贏,35% 同意“看情況”,另外 17% 的則覺得 Rust 會讓我們大吃一驚。
那么結果到底如何呢?下面讓我們進入正題。
編寫 C++ 和 Rust 的測試對象 找個項目
考慮到我未來一個月都要花在重寫代碼上,什么樣的代碼最合適?我認為得滿足以下幾點:
很少或不用第三方依賴(標準庫可以使用);
能在 Linux 和 macOS 上運行(我不怎么管 Windows 上的構建時間);
大量測試套組(不然我沒法確定 Rust 代碼的正確性);
FFI(外部函數接口)、指針、標準或自定義容器、功能類和函數、I/O、并發、泛型、宏、SIMD(單指令多數據流)、繼承等等,多少都有使用。
其實答案也很簡單,直接找我前幾年一直在做的項目就行。我用的是一個 JavaScript 詞法分析器,quick-lint-js 項目。
quick-lint-js 的吉祥物 Dusty
截取 C++ 代碼
quick-lint-js 項目中 C++ 部分的代碼行數超過 10 萬,要把這些全改成 Rust 得花上我半年時間,不如只關注 JavaScript 詞法分析部分,其中涉及項目中的:
診斷系統
翻譯系統(用于診斷)
各種內存分配器和容器(如 bump 分配器、適用于 SIMD 的字符串)
各種功能類函數(如 UTF-8 解碼器、SIMD 內在包裝器)
測試的輔助代碼(如自定義斷言宏)
C 的 API
可惜這部分代碼里不涉及并發或 I/O,我測試不了 Rust 里 async/await 的編譯時間開銷,但這只是 quick-lint-js 項目里的一小部分,所以我還不用太擔心。
我首先把所有的 C++ 代碼都復制到新項目里,然后刪掉已知與詞法分析無關的部分,比如分析器和 LSP 服務器。我甚至一不小心刪多了代碼,最后不得不重新把這些代碼添了回去。在我不斷截代碼的過程中,C++ 的測試一直保持了通過狀態。
在徹底將 quick-lint-js 項目中涉及詞法分析的部分全截出來之后,項目中 C++ 的代碼大約有 1.7 萬行。

重寫代碼
至于要怎么重寫這上千行的 C++ 代碼,我選擇按部就班:
找一個適合轉換的模塊;
復制黏貼代碼、測試、搜索替換并修改部分語法、繼續運行 cargo(Rust 的構建系統和包管理器)測試直到構建測測試都通過;
如果這個模塊依賴另一個模塊,那就找到被依賴的模塊,繼續進行第二步,然后再回到現在這個模塊;
如果還有模塊沒轉換,再回到第一步。
主要影響 Rust 和 C++ 構建時間的問題在于,C++ 的診斷系統是通過大量代碼生成、宏、constexpr(常量表達式)實現的,而我在重寫 Rust 版時,則用了代碼生成、proc 宏、普通宏以及一點點 const 實現。傳聞 proc 宏速度很慢,也有說是因為代碼質量太差導致的 proc 宏速度慢。希望我寫的 proc 宏還可以(祈禱~)。
我寫完才發現,原來 Rust 項目比 C++ 項目還要大,Rust 代碼 17.1k 行,而 C++ 只有 16.6k 行。
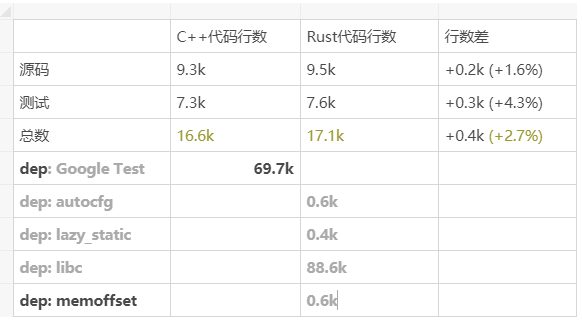
優化 Rust 構建
構建時間很重要,因為我在截取 C++ 代碼之前就已經做好了 C++ 項目構建時間的優化,所以我現在只需要對 Rust 項目的構建時間做同樣的優化即可。以下是我覺得可能會優化 Rust 構建時間的條目:
更快的鏈接器
Cranelift 后端
編譯器和鏈接器標志
工作區與測試布局區分
最小化依賴功能
cargo-nextest
使用 PGO 自定義工具鏈
更快的鏈接器
我第一步要做的是分析構建,我用的是 -Zself-profile rustc 標志。在這個標志所生成的兩個文件里,其中一個文件中的 run_linker 階段頗為突出:

第一輪 -Zself-profile 結果
之前我通過向 Mold 鏈接器的轉換成功優化了 C++ 的構建時間,那這套對 Rust 能否行得通?
Linux:鏈接器性能幾乎一致。(數據越小越好)

可惜,Linux 上雖然確實有提升,但效果不明顯。那 macOS 上的優化又表現如何?在 macOS 上默認鏈接器的替代品有兩種,lld 和 zld,效果如下:
macOS:鏈接器性能幾乎不變。(數據越小越好)

可以看出,macOS 上替換默認鏈接器的效果同樣不明顯,我懷疑這可能是因為 Linux 和 macOS 上的默認鏈接器對我的小項目而言已經做到了最好,這些優化后的鏈接器(Mold、lld、zld)在大型項目上效果非常好。
Cranelift 后端
讓我們再回到 -Zself-profile 的另一篇報告上,LLVM_module_-codegen_emit_obj 和 LLVM_passes 階段頗為突出:
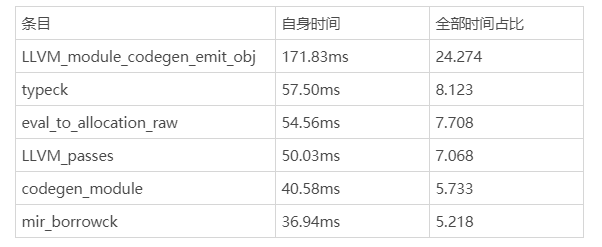
-Zself-profile 的第二輪結果
傳聞可以把 rustc 的后端從 LLVM 換成 Cranelift,于是我又用 rustc Cranelift 后端重新構建了一遍,-Zself-profile 結果看起來不錯:
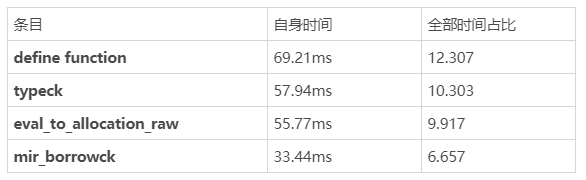
使用 Cranelife 的 -Zself-profile 第二輪結果
可惜,在實際的構建中 Cranelife 比 LLVM 慢。
Rust 后端:默認 LLVM 比 Cranelift 強。(測試于 Linux,數據越小越好)
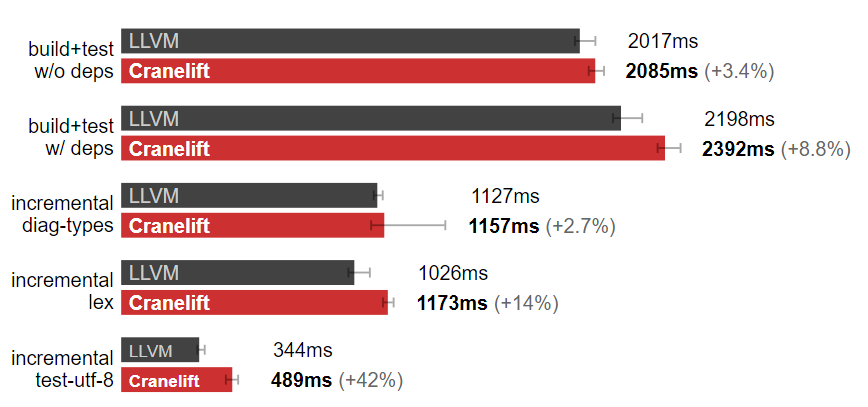
2023 年 1 月 7 日更新:rustc 的 Cranelift 后端維護者 bjorn3 幫我看了下為什么 Cranelift 在我的項目上效果不佳:可能是 rustup 的開銷導致的。如果繞過這部分 Cranelife 效果可能會有提升,上圖中的結果沒有采用任何措施。
編譯器和鏈接器標志
編譯器里有一堆可以加快(或減緩)構建速度的選項,讓我們一一試過:
-Zshare-generics=y (rustc) (Nightly only)
-Clink-args=-Wl,-s (rustc)
debug = false (Cargo)
debug-assertions = false (Cargo)
incremental = true 且 incremental = false (Cargo)
overflow-checks = false (Cargo)
panic = 'abort' (Cargo)
lib.doctest = false (Cargo)
lib.test = false (Cargo)
rustc 標志:快速構建優于調試構建。(測試于 Linux,數據越小越好)
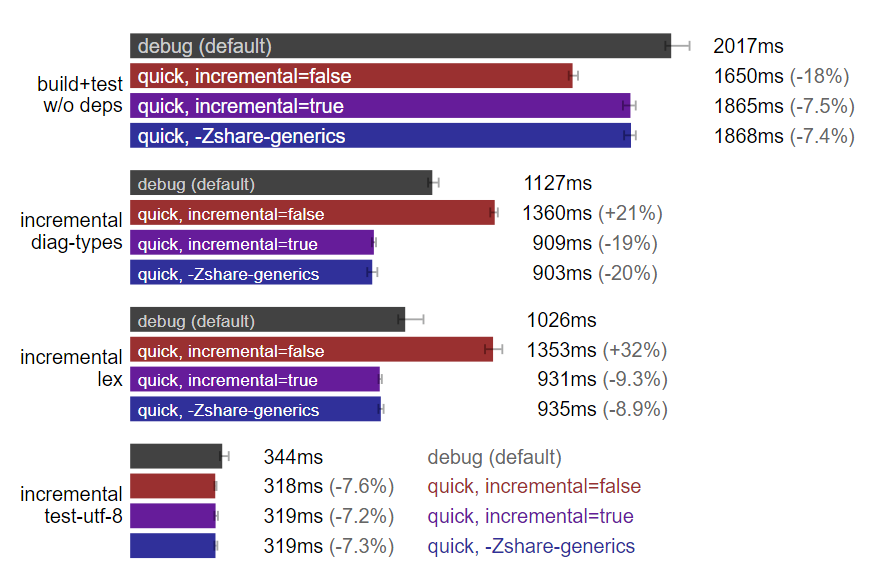
注:圖中的“quick, -Zshare-generics=y”與“quick, incremental=true”且啟用“-Zshare-generics=y”標志相等同,其余柱狀圖沒有標識“-Zshare-generics=y”是因為沒有啟用該標志,后者意味著需要 nightly rust 編譯器。
上圖中使用的多數選項都有文檔可查,但我還沒找到有人寫過加 -s 的鏈接。子命令 -s 將包括 Rust 標準庫靜態鏈接在內的所有調試信息全部剝離,讓鏈接器做更少的工作,從而減少鏈接時間。
工作區與測試布局
在文件的物理位置問題上,Rust 和 Cargo 都提供了部分靈活性。對我的項目而言,以下是三種合理布局:

理論上來說,如果我們把代碼拆成多個 crate,cargo 就可以并行化 rustc 的調用。鑒于我的 Linux 機器上有一個 32 線程的 CPU,macOS 機器上有一個 10 線程的 CPU,并行化應該可以降低構建時間。
對一個 crate 而言,Rust 項目中的測試有很多可運行的地方:

由于依賴周期的存在,我沒辦法做“源碼文件內的測試”這個布局的基準,但其他布局組合里我都做了基準:
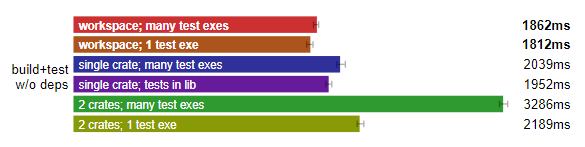
Rust 完整構建:工作區布局最快。(測試于 Linux,數據越小越好)
Rust 增量構建:最佳布局不明。(測試于 Linux,數據越小越好)
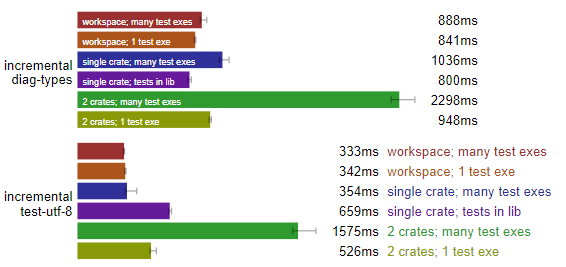
工作區設置中,無論是分成多個可執行測試(many test exes),還是合并成一個可執行測試,似乎都能斬獲頭籌。所以后續我們還是按照“工作區 + 多個可執行文件”的配置吧。
最小化依賴功能
多個 crate 的拆分支持可選功能,而部分可選功能都是默認啟用的,具體功能可以通過 cargo tree 命令查看:
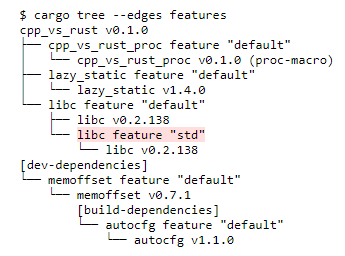
讓我們把 crate 之一,libc 中的 std 功能關掉,測試后再看看構建時間有沒有變化。
Cargo.toml
[dependencies]
+libc = { version = "0.2.138", default-features = false }
-libc = { version = "0.2.138" }
關掉libc功能后沒有任何變化。(測試于Linux,數據越小越好)

構建時間沒有任何變化,有可能 std 功能實際沒什么大影響。不管怎么說,讓我們進入下一個環節。
cargo-nextest
作為一款據說“比 cargo 測試快 60%”的工具,cargo-nextest 對于我這個代碼中 44% 都是測試的項目來說非常合適。讓我們來對比下構建和測試時間:
Linux:cargo-nextest 減慢了測試速度。(數據越小越好)
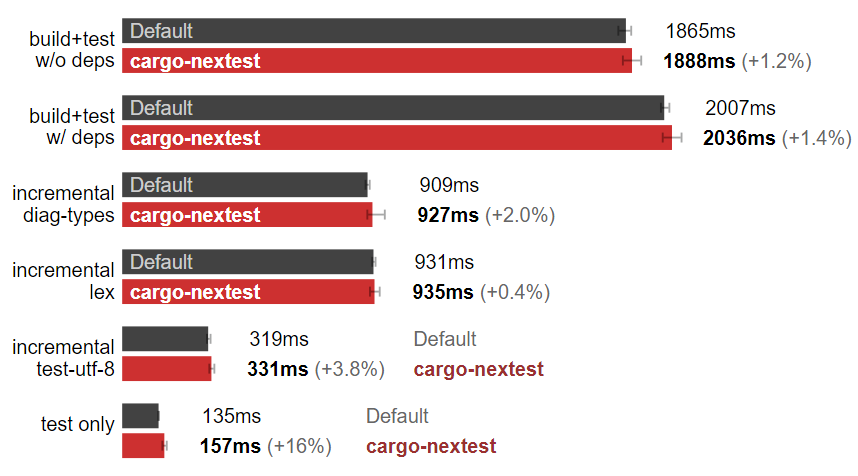
在我的 Linux 機器上,cargo-nextest 幫了倒忙,雖然輸出不錯,不過……
示例 cargo-nextest 測試輸出:
PASS [ 0.002s] cpp_vs_rust::test_locale no_match PASS [ 0.002s] cpp_vs_rust::test_offset_of fields_have_different_offsets PASS [ 0.002s] cpp_vs_rust::test_offset_of matches_memoffset_for_primitive_fields PASS [ 0.002s] cpp_vs_rust::test_padded_string as_slice_excludes_padding_bytes PASS [ 0.002s] cpp_vs_rust::test_offset_of matches_memoffset_for_reference_fields PASS [ 0.004s] cpp_vs_rust::test_linked_vector push_seven
那 macOS 上怎么說?
macOS:cargo-nextest 加快了構建測試。(數據越小越好)
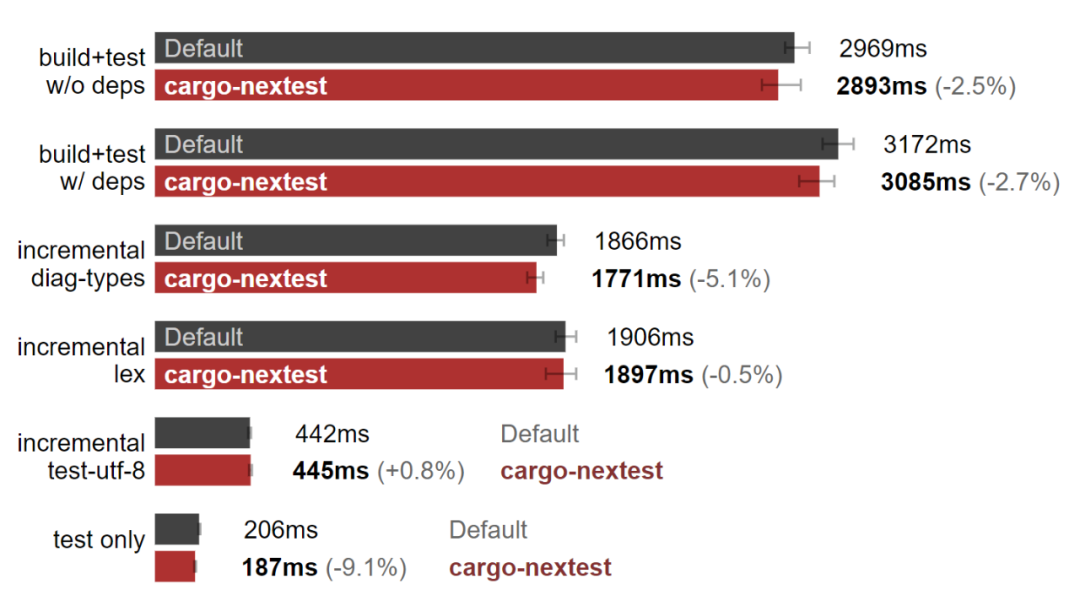
在我的 MacBook pro 上,cargo-nextest 確實提高了構建測試的速度。但為什么 Linux 上沒有呢?難道是和硬件有關?
在下面測試中,我會在 macOS 上使用 cargo-nextest,但 Linux 上的測試不用。
使用 PGO 自定義工具鏈
我發現 C++ 編譯器的構建如果用配置文件引導的優化(PGO,也稱作 FDO),會有明顯的性能提升。因此,讓我們試試用 PGO 優化 Rust 工具鏈的同時,也用 LLVM BOLT 加上 -Ctarget-cpu=native 進一步優化 rustc。
Rust 工具鏈:自定義工具鏈是最快的。(測試于 Linux,數據越小越好)
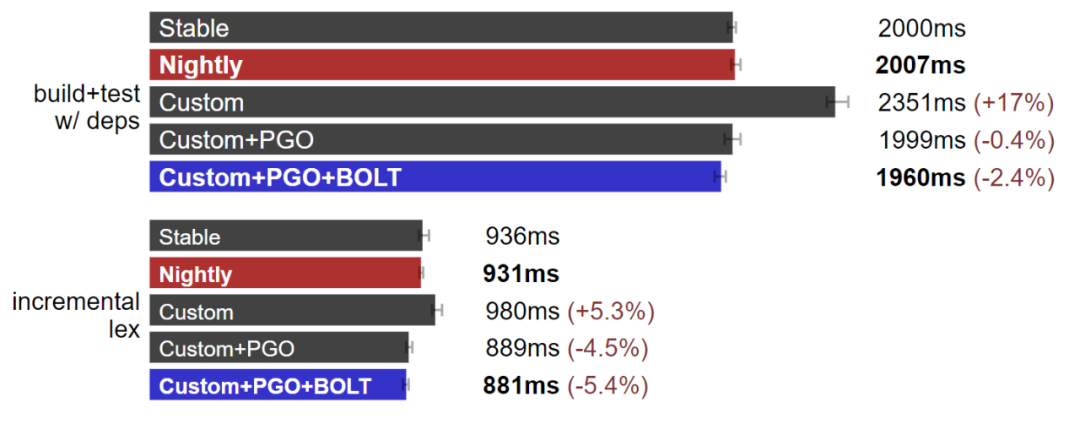
如果你好奇的話,可以看看這段工具鏈構建腳本。可能不適用于你的機器,但只要我能運行就行:https://github.com/quick-lint/cpp-vs-rust/blob/953429a4d92923ec030301e5b00face1c13bb92b/tools/build-toolchains.sh
與 C++ 編譯器相比,通過 rustup 發布的 Rust 工具鏈似乎已經是優化完成的結果。PGO 加上 BOLT 的組合只帶來了不到 10% 的性能提升。但有提升就是好的,所以在后續與 C++ 的競爭中我們會繼續使用這個速度最快的工具鏈。
我第一次搭建的 Rust 自定義工具鏈比 Nightly 還要慢 2%,我在 Rust config.toml 的各種選項中反復調整,不斷交叉檢查 Rust 的 CI 構建腳本以及我自己的腳本,最終在好幾天的掙扎后才讓這二者性能持平。在我最終潤色這篇文章時,我進行了 rustup 更新,拉取 git 項目,并重頭又建了一遍工具鏈。結果這次我的自定義工具鏈速度更快了!有可能是我在 Rust 倉庫里提交錯了代碼……
優化 C++ 構建
在最初的 C++ 項目 quick-lint-js 中,我已經用常見的手段優化了編譯時間,比如用 PCH、禁用異常和 RTTI、調整編譯標志、刪除非必要 #include、將代碼從頭中移出、外置模板實例等方法。但此外還有一些 C++ 編譯器和鏈接器我沒試過,在我們進入 C++ 和 Rust 的對比之前,先從這些里面挑出最適合我們的。
Linux:自定義 Clang 是最快的工具鏈。(數據越小越好)
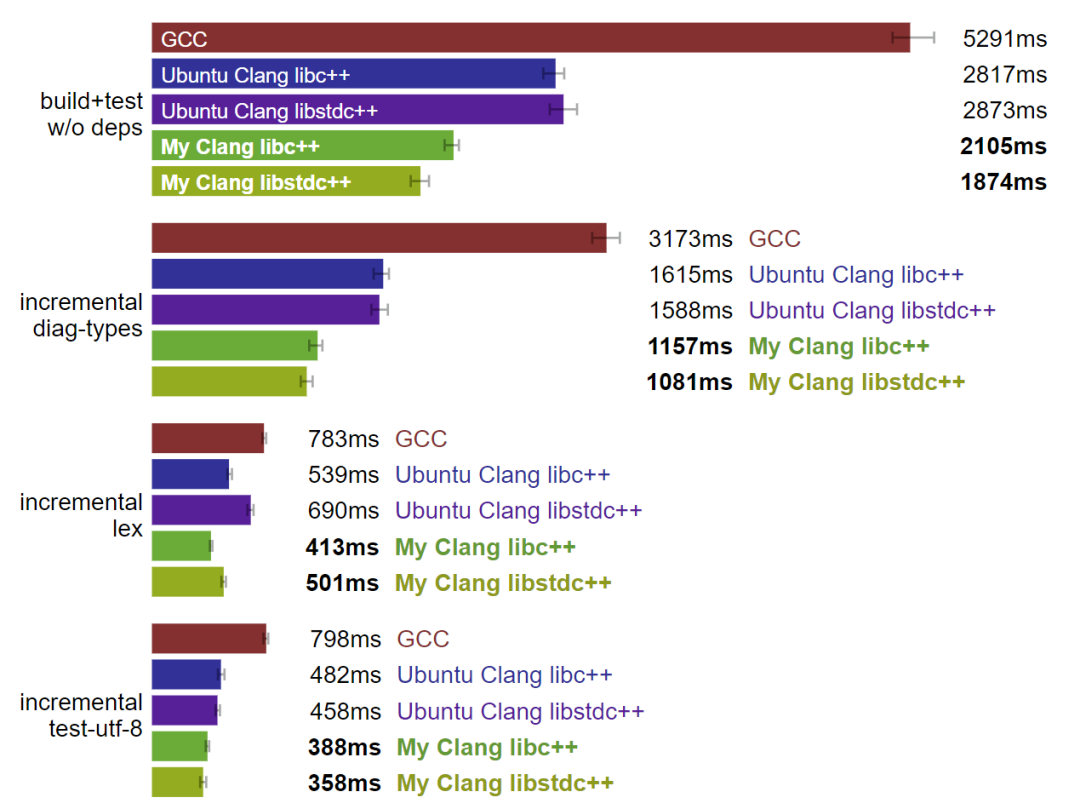
很明顯,Linux 上的 GCC 是個特例,而 Clang 的表現則要好上很多。我自定義構建的 Clang(和 Rust 工具鏈一樣,也是用 PGO 和 BOLT 構建的)相較于 Ubuntu 的 Clang,顯著優化了構建時間,而 libstdc++ 的構建略快于平均 libc++ 的速度。
那我的自定義 Clang 加上 libstdc++ 在 C++ 和 Rust 的對比中表現如何呢?
macOS:Xcode 是最快的工具鏈。(數據越小越好)
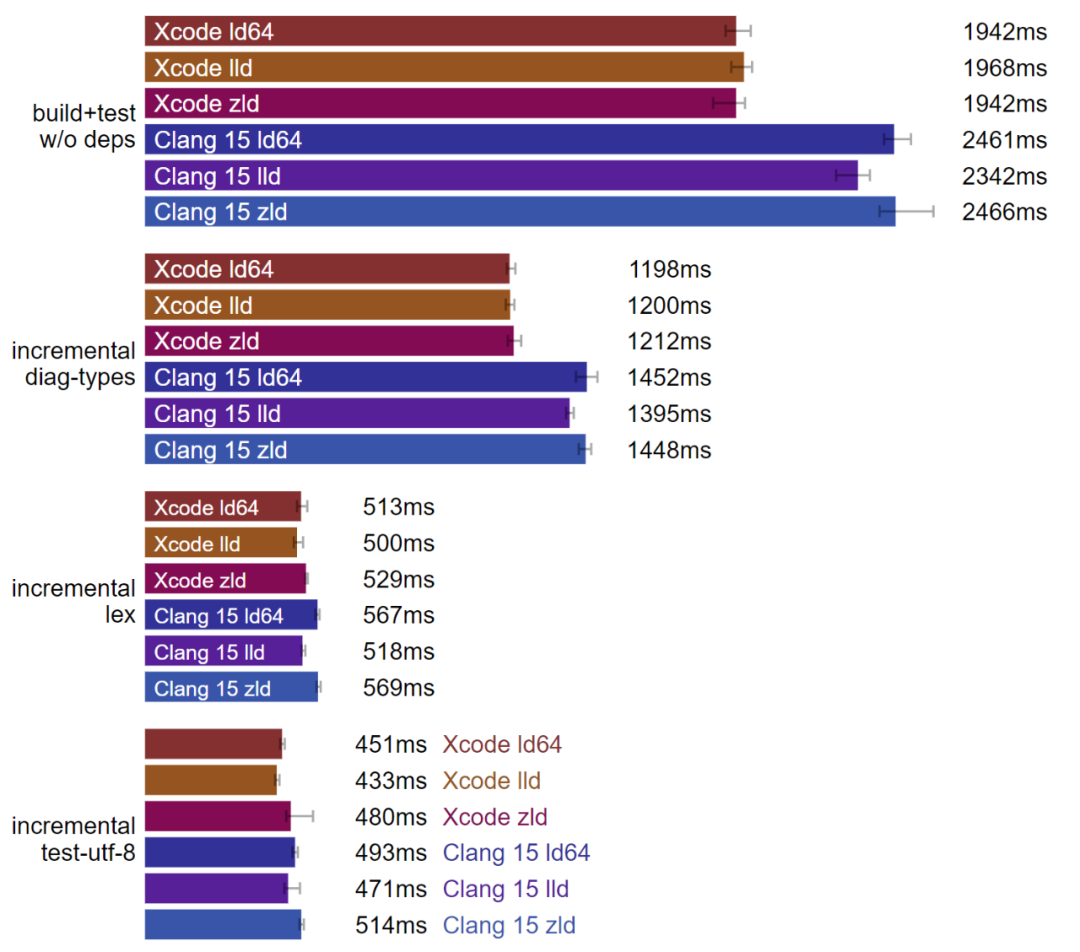
在 macOS 上,搭配 Xcode 的 Clang 工具鏈似乎要比 LLVM 網站上的 Clang 工具鏈優化得更好。
C++20 模塊
我的 C++ 代碼用的是 #include,但如果用 C++20 中新增加的 import 又會怎么樣呢?C++20 的模塊是不是理論上來說應該會讓編譯速度超級快?
我在項目了嘗試過 C++20 模塊,但直到 2023 年的 1 月 3 日,Linux 上的 CMake 模塊支持過于實驗性質了,我甚至連“hello world”都沒跑起來。
或許 2023 年中 C++20 模塊會大放異彩,對于我這種超級在意構建時間的人來說,真是這樣就太好了。但目前為止,我還是繼續用經典 C++ 的 #include 和 Rust 做對比吧。
對比 C++ 和 Rust 的構建時間
通過把 C++ 項目改寫成 Rust,并盡可能地優化 Rust 的構建時間后,問題來了:C++ 和 Rust 究竟誰更快呢?
很可惜,答案是“看情況”!
Linux:Rust 部分情況下構建速度超越 C++。(數據越小越好)
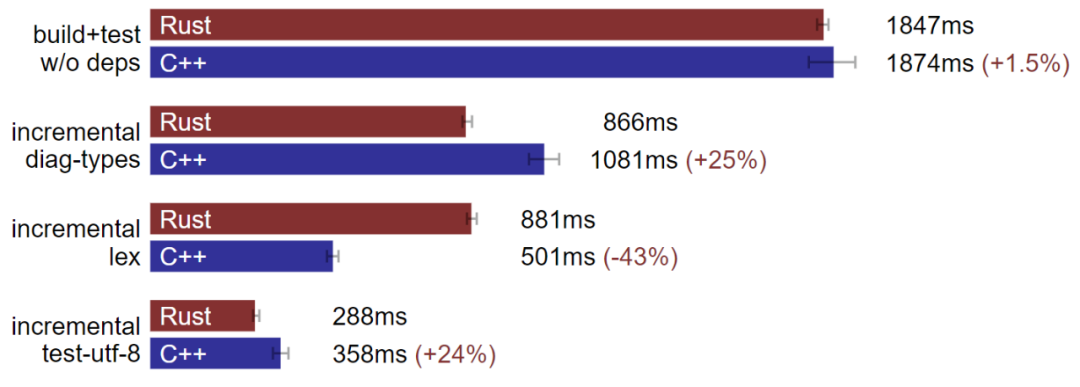
在我的 Linux 機器上,部分情況下 Rust 的構建速度確實優于 C++,但也有速度持平或遜于 C++ 的情況。在增量 lex 的基準上,我們修改了大量源碼,Clang 比 rustc 速度快,但在其他增量基準上,rustc 又會反超 Clang。
macOS:C++ 構建速度通常快于 Rust。(數據越小越好)
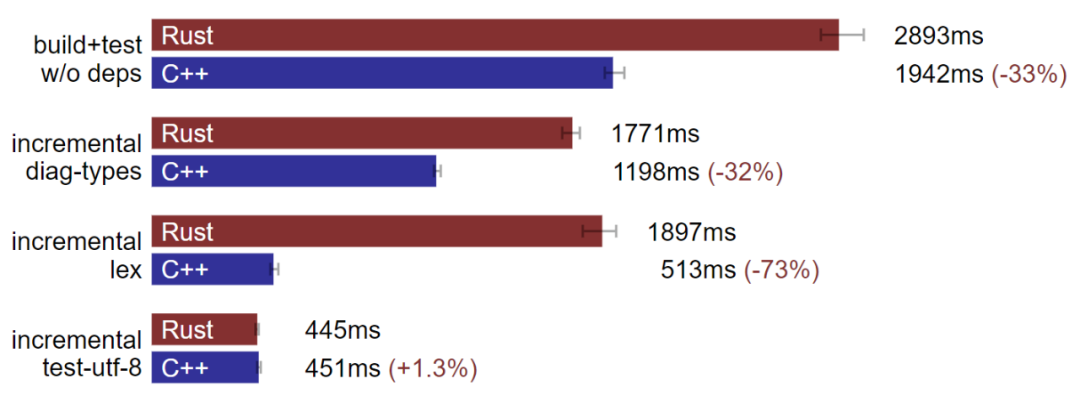
但我的 macOS 機器上情況卻截然不同。C++ 的構建速度常常快上 Rust 許多。在增量測試 utf-8 的基準,我們修改中等數量測試文件,rustc 編譯速度會略微超過 Clang,但在包括全量構建等其他基準上,Clang 很明顯效果要更好。
超過 17k 行代碼
我基準測試的項目只有 17k 行代碼,算是小型項目,那么對超過 10 萬行代碼的大型項目來說,又是什么情況呢?
我把最大的模塊,也就是詞法分析器的代碼復制粘貼了 8、16 以及 24 遍,分別用來測試。因為我的基準里也包括了運行測試的時間,我覺得構建時間即使是對于那些能瞬間構建完的項目,也應該會線性增長。
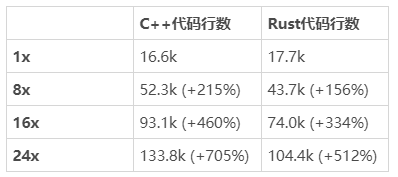
倍數擴大后 C++ 完整構建優于 Rust。(測試于 Linux,數據越小越好)
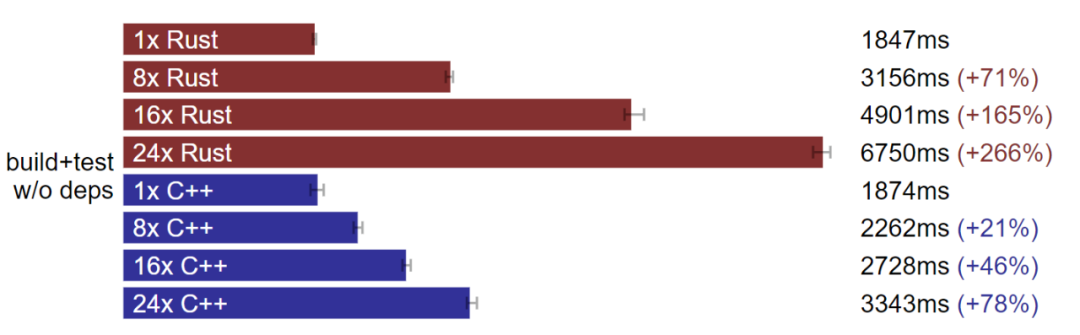
倍數擴大后 C++ 增量構建優于 Rust。(測試于 Linux,數據越小越好)
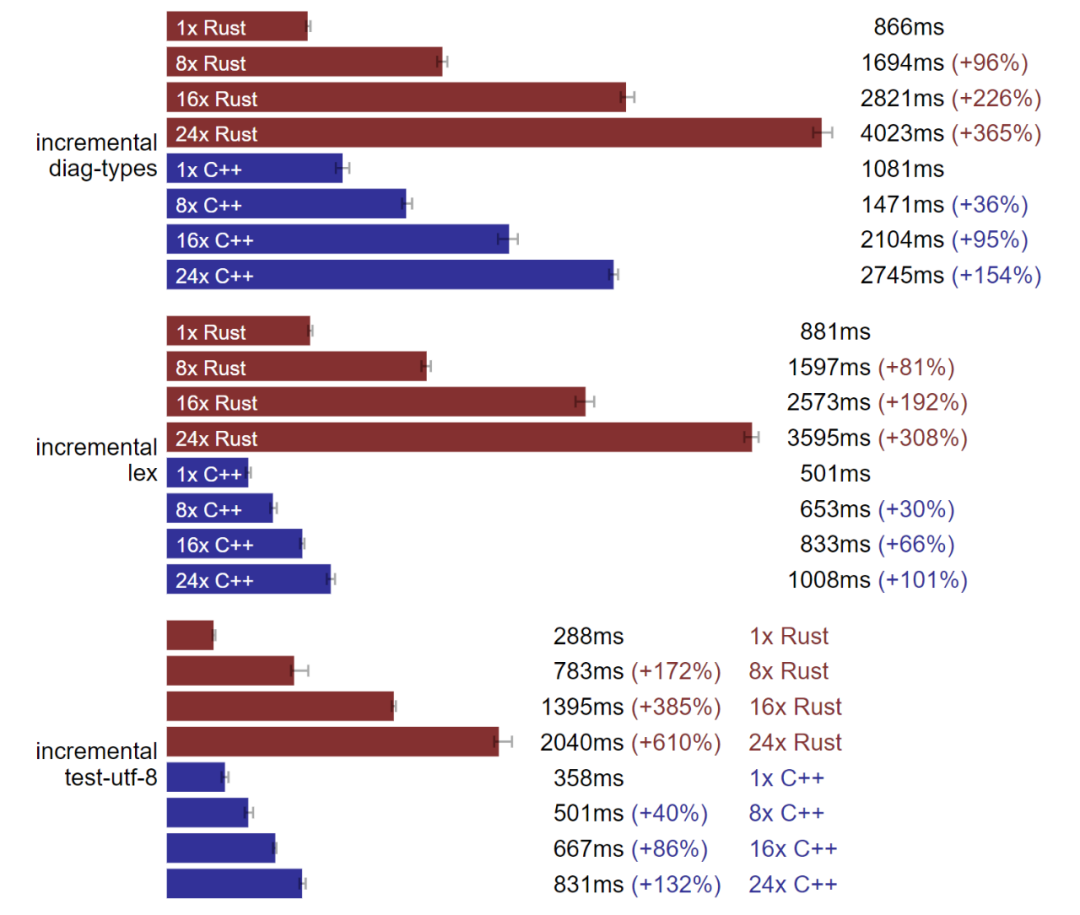
Rust 和 Clang 確實都是線性擴大,這點很好。
正如預期中一樣,修改 C++ 的頭文件,也就是增量 diag-type 會大幅影響構建時間。而由于 Mold 鏈接器的存在,其他增量基準中構建時間的擴展系數很低。
Rust 構建的擴展性讓我很失望,即使只是增量 utf-8 測試的基準,無關文件的加入也不應該讓它的構建時間如此受影響。測試所用的 crate 布局時“工作區且多個可執行測試”,因此 utf-8 測試應該能獨立編譯可執行文件。
結 論
編譯時間對 Rust 而言算是問題嗎?答案是肯定的。雖然也有一些可以加快編譯速度的提示和技巧,但卻沒有效果非常顯著的數量級改進,這讓我在開發 Rust 時非常高興。
Rust 的編譯時間和 C++ 相比呢?確實也很糟。至少對我的編碼風格來說,Rust 在大型項目上開發的編譯時間甚至更加遠比 C++ 還要糟糕。
再回過頭看看我當初的假設,幾乎全軍覆沒:
Rust 改寫版代碼行數比 C++ 多;
在全量構建上,C++ 相比 Rust 在 1.7 萬行代碼上構建時間相似,在 10 萬行代碼上構建時間要少;
在增量構建上,Rust 相比 C++ 在部分情況構建時間要短,在 1.7 萬行上構建時間要長,在 10 萬行代碼上構建時間甚至更長。
我不爽嗎?確實。在改寫過程中,我不斷學習著 Rust 相關的知識,比如 proc marco 能替代三個不同代碼生成器,簡化構建流水線,讓新開發者們日子更好過。但我完全不想念頭文件,以及 Rust 的工具類真的很好用,特別是 Cargo、rustup 以及 miri。
但我決定不把 quick-lint-js 項目中剩下的代碼也改成 Rust,但如果 Rust 的構建時間能有明顯優化,或許我會改變主意。當然,前提是我還沒被 Zig 迷走心神。
附注
源碼
刪減后的 C++ 項目源碼、移植版 Rust(包括不同的項目布局)、代碼生成腳本和基準測試腳本、GPL-3.0 及以上。
Linux 機器
名稱:strapurp
CPU:AMD Ryzen 9 5950X (PBO; stock clocks) (32 threads) (x86_64)
RAM:G.SKILL F4-4000C19-16GTZR 2x16 GiB (overclocked to 3800 MT/s)
操作系統:Linux Mint 21.1
內核:Linux strapurp 5.15.0-56-generic #62-Ubuntu SMP Tue Nov 22 1914 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux
Linux 性能治理器:schedutil
CMake:版本 3.19.1
Ninja:版本 1.10.2
GCC:版本 12.1.0-2ubuntu1~22.04
Clang(Ubuntu):版本 14.0.0-1ubuntu1
Clang (自定義):版本 15.0.6(Rust fork; 代碼提交 3dfd4d93fa013e1c0578-d3ceac5c8f4ebba4b6ec)libstdc++ for Clang:版本 11.3.0-1ubuntu1~22.04
Rust 穩定版:1.66.0 (69f9c33d7 2022-12-12)
Rust Nightly:版本 1.68.0-nightly (c7572670a 2023-01-03)
Rust(自定義):版本 1.68.0-dev (c7572670a 2023-01-03)
Mold:版本 0.9.3 (ec3319b37f653dccfa4d-1a859a5c687565ab722d)
binutils:版本 2.38
macOS 機器
名稱:strammer
CPU:Apple M1 Max (10 threads) (AArch64)
RAM:Apple 64 GiB
操作系統:macOS Monterey 12.6
CMake:版本 3.19.1
Ninja:版本 1.10.2
Xcode Clang:Apple clang 版本 14.0.0 (clang-1400.0.29.202) (Xcode 14.2)
Clang 15:版本 15.0.6 (LLVM.org website)
Rust 穩定版:1.66.0 (69f9c33d7 2022-12-12)
Rust Nightly:版本 1.68.0-nightly (c7572670a 2023-01-03)
Rust(自定義):版本 1.68.0-dev (c7572670a 2023-01-03)
lld:版本 15.0.6
zld:代碼提交 d50a975a5fe6576ba0fd-2863897c6d016eaeac41
基準
用 deps 的構建和測試
C++:cmake -S build -B . -G Ninja && ninja -C build quick-lint-js-test && build/test/quick-lint-js-test 計時
Rust:cargo fetch 未計時,再用 cargo test 計時
不用 deps 的構建和測試
C++:cmake -S build -B . -G Ninja && ninja -C build gmock gmock_main gtest 未計時, 再用 ninja -C build quick-lint-js-test && build/test/quick-lint-js-test 計時
Rust:cargo build --package lazy_static --package libc --package memoffset" 未計時, 再用 cargo test 計時
增量 diag-types
C++:構建和測試未計時,隨后修改 diagnostic-types.h,再用 ninja -C build quick-lint-js-test && build/test/quick-lint-js-testRust:構建和測試未計時,修改 diagnostic_types.rs 后,cargo test
增量 lex
同增量 diag-types,但使用 lex.cpp/lex.rs
增量 utf-8 測試
同增量,但使用 test-utf-8.cpp/test_utf_8.rs
每個可執行基準均采用 12 個樣本,棄置前兩個,基準僅顯示最后十個樣本的平均性能。誤差區間展示最小與最大樣本間區別。
審核編輯:劉清
-
解碼器
+關注
關注
9文章
1185瀏覽量
42052 -
SIMD
+關注
關注
0文章
36瀏覽量
10562 -
UTF-8
+關注
關注
0文章
13瀏覽量
7983 -
LSP
+關注
關注
0文章
13瀏覽量
9986 -
rust語言
+關注
關注
0文章
57瀏覽量
3153
原文標題:我用 Rust 改寫了自己的C++項目:這兩個語言都很折磨人!
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Oculus Rift與PS VR:誰會更勝一籌?
射頻技術和射頻標識對比分析誰更勝一籌?
公共云與私有云大比拼 成本計算誰更勝一籌?
華為P10上線預售!華為P10對比iPhone7,誰將更勝一籌?

努比亞M2今日發布,對比小米6s,誰能更勝一籌?
小米電視4 55吋與雷鳥I55參數對比,誰能更勝一籌?
微軟、谷歌、英特爾都發力AI,3巨頭誰更勝一籌?
在各項生物識別技術中,哪種識別技術更勝一籌?
MelNet 捕捉“高層結構”更勝一籌
安規電容與薄膜電容大比拼,究竟誰更勝一籌?
UVLED面光源與傳統光源對比:誰更勝一籌?






 工商網監
工商網監

評論