") 利用Python讀取多份Excel的小技巧
利用Python讀取多份Excel的小技巧
在使用 Python 批量處理 Excel 時(shí)經(jīng)常需要批量讀取數(shù)據(jù),常見的方式是結(jié)合glob模塊,可以實(shí)現(xiàn)將當(dāng)前文件夾下的所有csv批量讀取,并且合并到一個(gè)大的DataFrame中
df_list = [] for file in glob.glob("*.csv"): df_list.append(pd.read_excel(file)) df = pd.concat(df_list)
但是這樣要求讀取的每一個(gè)csv文件格式、列名都是一樣的。
如果想要將每一個(gè)csv獨(dú)立的進(jìn)行讀取,可以使用os模塊來(lái)循環(huán)遍歷當(dāng)前文件夾中的 CSV 文件,然后使用 Pandas 的read_csv函數(shù)來(lái)讀取每個(gè)文件
import os
import pandas as pd
df_list = []
for file in os.listdir():
if file.endswith(".csv"):
df_list.append(pd.read_csv(file))
現(xiàn)在,df_list中的每個(gè)元素都是一個(gè)DataFrame,但是這樣依舊不夠完美,調(diào)用的時(shí)候依舊需要手動(dòng)從列表中提取。
那如何自動(dòng)讀取當(dāng)前文件夾下全部CSV數(shù)據(jù),并將每個(gè)CSV賦給不同的變量
可以使用Python中的globals()函數(shù),它返回一個(gè)字典,其中包含當(dāng)前程序的所有全局變量,例如我們可以使用如下語(yǔ)法來(lái)為字典中的某個(gè)鍵賦值:
globals()[key] = value
所以,使用下面的代碼可以實(shí)現(xiàn)自動(dòng)讀取當(dāng)前文件夾下全部CSV數(shù)據(jù),并將每個(gè)CSV賦給不同的變量
df_list = [] for i, file in enumerate(os.listdir()): if file.endswith(".csv"): df_list.append(pd.read_csv(file)) for i, df in enumerate(df_list): globals()[f'df{i+1}'] = df
當(dāng)然,類似的方法還可以應(yīng)用于讀取Excel的不同sheet,例如假設(shè)data.xlsx有10個(gè)sheet
df_list = [pd.read_excel("data.xlsx", sheet_name=i) for i in range(10)]
for i, df in enumerate(df_list):
globals()[f"df{i+1}"] = df
如果你不清楚數(shù)據(jù)有多少Sheet,也可以使用sheet_name=None,然后根據(jù)返回的字典自動(dòng)讀取
df_list = pd.read_excel("data.xlsx", sheet_name=None)
for i, (name, df) in enumerate(df_list.items()):
globals()[f"df_{name}"] = df
審核編輯:劉清
-
python
+關(guān)注
關(guān)注
56文章
4792瀏覽量
84628 -
csv
+關(guān)注
關(guān)注
0文章
38瀏覽量
5819
原文標(biāo)題:如何用 Python 批量循環(huán)讀取 Excel ?
文章出處:【微信號(hào):DBDevs,微信公眾號(hào):數(shù)據(jù)分析與開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
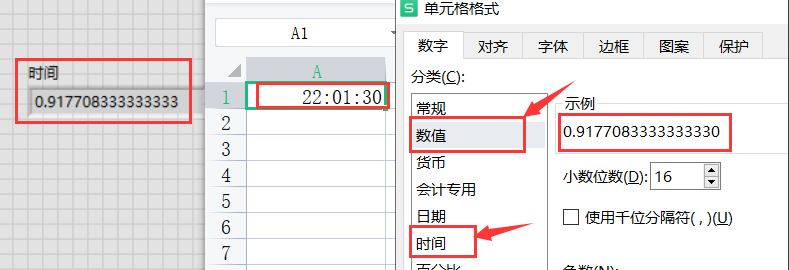
LabVIEW讀取Excel數(shù)據(jù)時(shí)間轉(zhuǎn)換設(shè)計(jì)
Python利用pandas讀寫Excel文件

如何使用python實(shí)現(xiàn)截圖自動(dòng)存入Excel表
python導(dǎo)出excel格式的oracle數(shù)據(jù)報(bào)表講解

Labview讀取EXCEL
Excel新功能要逆天 微軟把Python加入Excel
微軟正在將Python引入Excel
如何使用Python和pandas庫(kù)讀取、寫入文件
如何使用Python讀取寫入Word文件
Python中Excel轉(zhuǎn)PDF的實(shí)現(xiàn)步驟





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論